Sobre el juego La venganza de Montezuma en Habré no se escribió tanto. Este es un juego clásico complejo que anteriormente era muy popular, pero ahora es jugado por aquellos con quienes evoca sentimientos de nostalgia o por investigadores que desarrollan IA.
Este verano, se
informó que DeepMind pudo enseñarle a su IA cómo jugar juegos para Atari, incluida la venganza de Montezuma. Usando el ejemplo del mismo juego, los creadores de OpenAI también
enseñaron su desarrollo. Ahora Uber ha emprendido un proyecto similar.
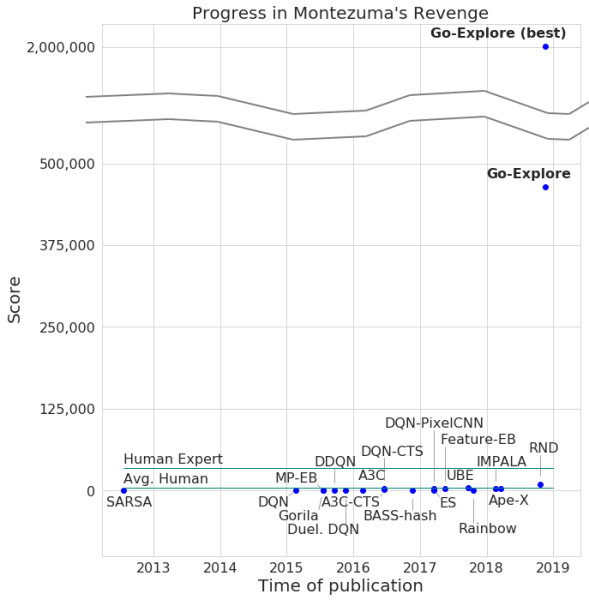
Los desarrolladores anunciaron el paso del juego por su red neuronal, con un número máximo de puntos de 2 millones. Es cierto que, en promedio, el sistema no ganó más de 400,000 por cada intento. En cuanto al pasaje, la computadora alcanzó el nivel 159.
Además, Go-Explore aprendió a pasar por Pitfall, con un resultado excelente que es superior al jugador promedio, sin mencionar a otros agentes de IA. El número de puntos anotados por Go-Explore en este juego es de 21,000.
La diferencia entre Go-Explore y sus "colegas" es que las redes neuronales no necesitan demostrar que pasan diferentes niveles para el entrenamiento. El sistema aprende todo durante el juego, mostrando resultados mucho más altos que los demostrados por las redes neuronales que requieren entrenamiento visual. Según los desarrolladores de Go-Explore, la tecnología es significativamente diferente de todas las demás, y sus capacidades permiten el uso de una red neuronal en varias áreas, incluida la robótica.
A la mayoría de los algoritmos les resulta difícil lidiar con la venganza de Montezuma porque el juego no tiene comentarios muy explícitos. Por ejemplo, una red neuronal que se "agudiza" para recibir recompensas en el proceso de pasar un nivel en lugar de luchar contra el enemigo que saltar a una escalera que conduce a la salida y le permite avanzar más rápido. Otros sistemas de IA prefieren recibir una recompensa aquí y ahora, y no seguir adelante con la "esperanza" de más.
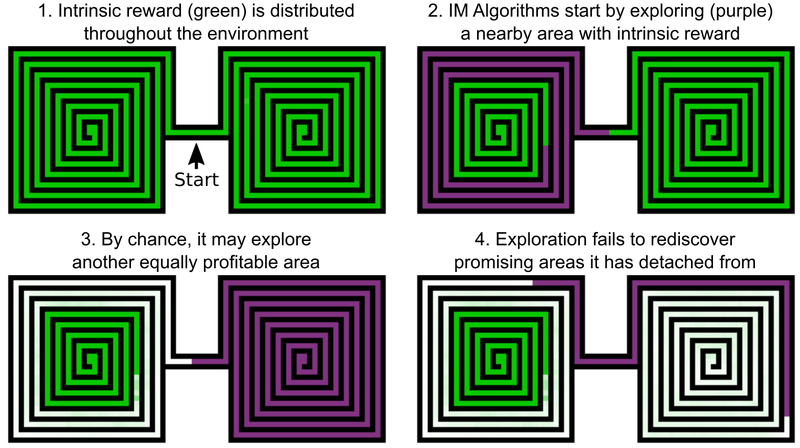
Una de las decisiones de los ingenieros de Uber es agregar bonos para explorar el mundo del juego, esto se puede llamar la motivación interna de la IA. Pero incluso los elementos de IA con motivación intrínseca añadida no funcionan bien con la venganza y la trampa de Montezuma. El problema es que la IA "olvida" las ubicaciones prometedoras después de pasarlas. Como resultado, el agente de IA se atasca en un nivel en el que todo parece haber sido investigado.
Un ejemplo es el agente de IA, que necesita estudiar dos laberintos: este y oeste. Él comienza a pasar por uno de ellos, pero de repente decide que sería posible pasar por el segundo. El primero permanece estudiado al 50%, el segundo al 100%. Y el agente no regresa al primer laberinto, simplemente porque "olvidó" que no se ha completado hasta el final. Y dado que el paso entre el laberinto oriental y occidental ya se ha estudiado, la IA no tiene motivación para regresar.
La solución a este problema, según los desarrolladores de Uber, incluye dos etapas: investigación y amplificación. En cuanto a la primera parte, aquí la IA crea un archivo de varios estados del juego (células (células)) y varias trayectorias que conducen a ellos. AI elige la oportunidad de obtener el máximo número de puntos al detectar la trayectoria óptima.
Las celdas son marcos de juego simplificados: imágenes de 11 por 8 en tonos de gris con una intensidad de 8 píxeles, con marcos que difieren lo suficiente, para no impedir el paso posterior del juego.

Como resultado, AI recuerda lugares prometedores y regresa a ellos después de examinar otras partes del mundo del juego. El "deseo" de explorar el mundo del juego y las ubicaciones prometedoras en Go-Explore es más fuerte que el deseo de recibir un premio aquí y ahora. Go-Explore también utiliza información sobre las células en las que se capacita al agente de IA. Para la venganza de Montezuma, se trata de datos de píxeles como sus coordenadas X e Y, la habitación actual y la cantidad de teclas encontradas.
La etapa de amplificación funciona como una protección contra el "ruido". Si las soluciones de IA son inestables al "ruido", entonces la IA las fortalece con la ayuda de una red neuronal multinivel, que funciona según el ejemplo de las neuronas cerebrales humanas.

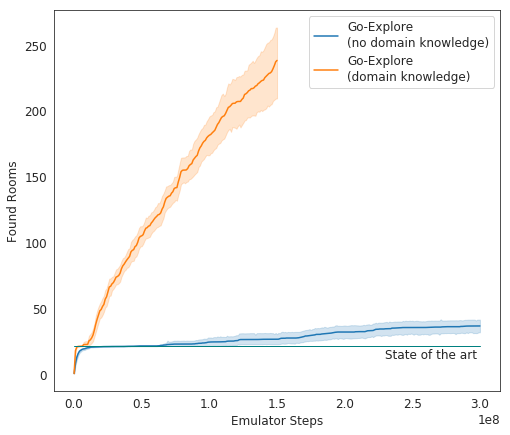
En las pruebas, Go-Explore funciona muy bien: en promedio, AI estudia 37 habitaciones y resuelve el 65% de los rompecabezas de primer nivel. Esto es mucho mejor que los intentos anteriores de conquistar el juego; luego, la IA estudió en promedio 22 habitaciones del primer nivel.

Al agregar ganancia al algoritmo existente, la IA comenzó a completarse con éxito en promedio 29 niveles (no habitaciones) con un puntaje promedio de 469.209.
La encarnación final de la IA de Uber comenzó a ejecutar el juego mucho mejor que otros agentes de IA, y mejor que los humanos. Ahora los desarrolladores están mejorando su sistema para que muestre un resultado aún más impresionante.