El 8 de noviembre, en el salón principal de la conferencia
HighLoad ++ 2018 , en el marco de la sección DevOps y Operaciones, se realizó un informe titulado Bases de datos y Kubernetes. Habla sobre la alta disponibilidad de bases de datos y enfoques de tolerancia a fallas para Kubernetes y con él, así como opciones prácticas para colocar DBMS en clústeres de Kubernetes y soluciones existentes para esto (incluido Stolon para PostgreSQL).

Por tradición, nos complace presentar un
video con un informe (aproximadamente una hora,
mucho más informativo
que el artículo) y la compresión principal en forma de texto. Vamos!
Teoría
Este informe apareció como respuesta a una de las preguntas más populares que en los últimos años nos han hecho incansablemente en diferentes lugares: comentarios en Habr o YouTube, redes sociales, etc. Suena simple: "¿Es posible ejecutar la base de datos en Kubernetes?", Y si generalmente respondíamos "generalmente sí, pero ...", entonces claramente no había suficiente explicación para estos "en general" y "pero", pero para encajarlos en un mensaje corto no tuvo éxito.
Sin embargo, para empezar, resumo el problema desde la "base de datos [datos]" hasta el estado completo. Un DBMS es solo un caso especial de decisiones con estado, cuya lista más completa se puede representar de la siguiente manera:
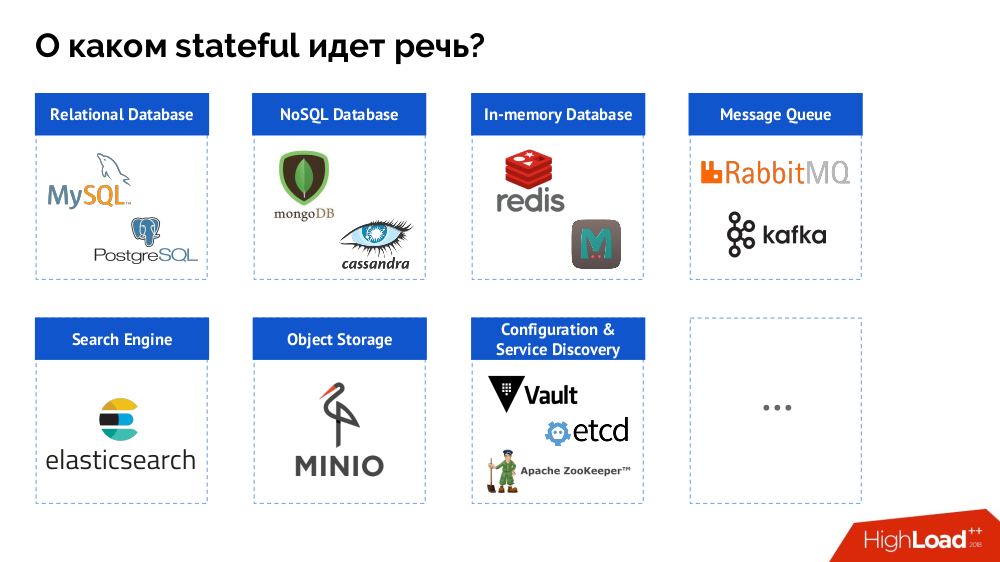
Antes de ver casos específicos, hablaré sobre tres características importantes del trabajo / uso de Kubernetes.
1. Filosofía de alta disponibilidad de Kubernetes
Todos conocen la analogía de “mascotas
contra ganado ” y entienden que si Kubernetes es una historia del mundo de la manada, los DBMS clásicos son solo mascotas.
¿Y cómo era la arquitectura de las "mascotas" en la versión "tradicional"? Un ejemplo clásico de instalación de MySQL es la replicación en dos servidores de hierro con alimentación redundante, un disco, una red ... y todo lo demás (incluido un ingeniero y varias herramientas auxiliares), lo que nos ayudará a asegurarnos de que el proceso de MySQL no fallará, y si hay un problema con alguno de los críticos Para sus componentes, se respetará la tolerancia a fallos:
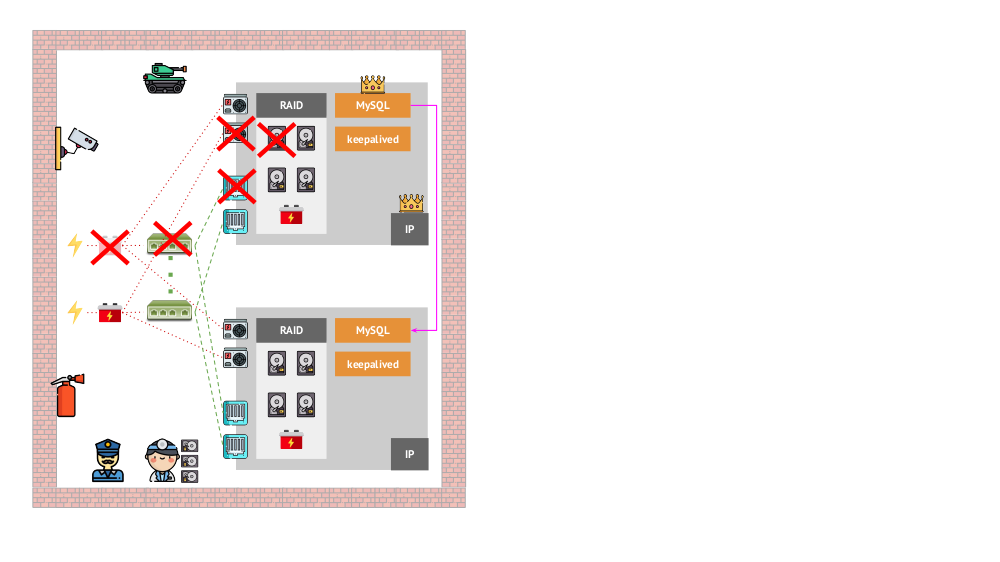
¿Cómo se verá lo mismo en Kubernetes? Aquí, generalmente hay muchos más servidores de hierro, son más simples y no tienen energía y red redundantes (en el sentido de que la pérdida de una máquina no afecta nada): todo esto se combina en un clúster. El software proporciona su tolerancia a fallos: si algo le sucede al nodo, Kubernetes detecta e inicia las instancias necesarias en el otro nodo.
¿Cuáles son los mecanismos de alta disponibilidad en K8?
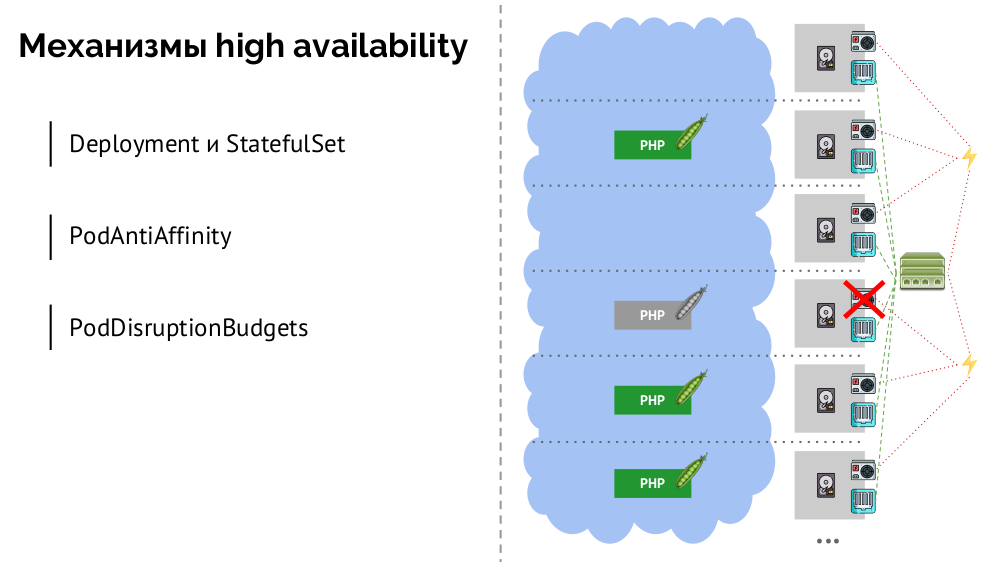
- Controladores Hay muchos, pero dos principales:
Deployment (para aplicaciones sin estado) y StatefulSet (para aplicaciones con estado). Almacenan toda la lógica de las acciones tomadas en caso de un bloqueo de nodo (inaccesibilidad de pod). PodAntiAffinity : la capacidad de especificar pods específicos para que no estén en el mismo nodo.PodDisruptionBudgets : limite el número de instancias de pod que se pueden desactivar al mismo tiempo en caso de trabajo programado.
2. Garantías de consistencia de Kubernetes
¿Cómo funciona el conocido esquema de tolerancia de fallas de maestro único? Dos servidores (maestro y en espera), uno de los cuales es accedido constantemente por la aplicación, que a su vez se utiliza a través del equilibrador de carga. ¿Qué sucede en caso de un problema de red?
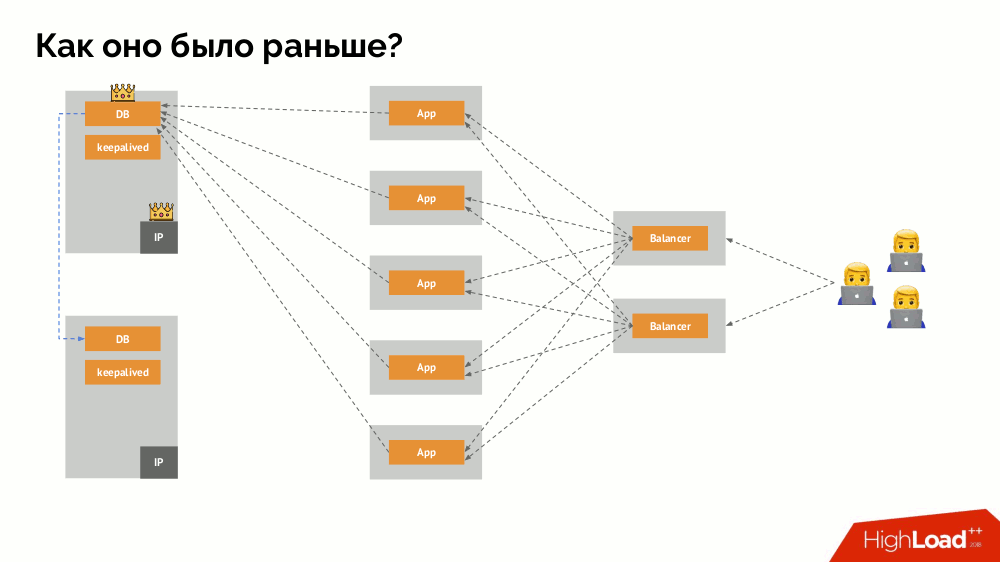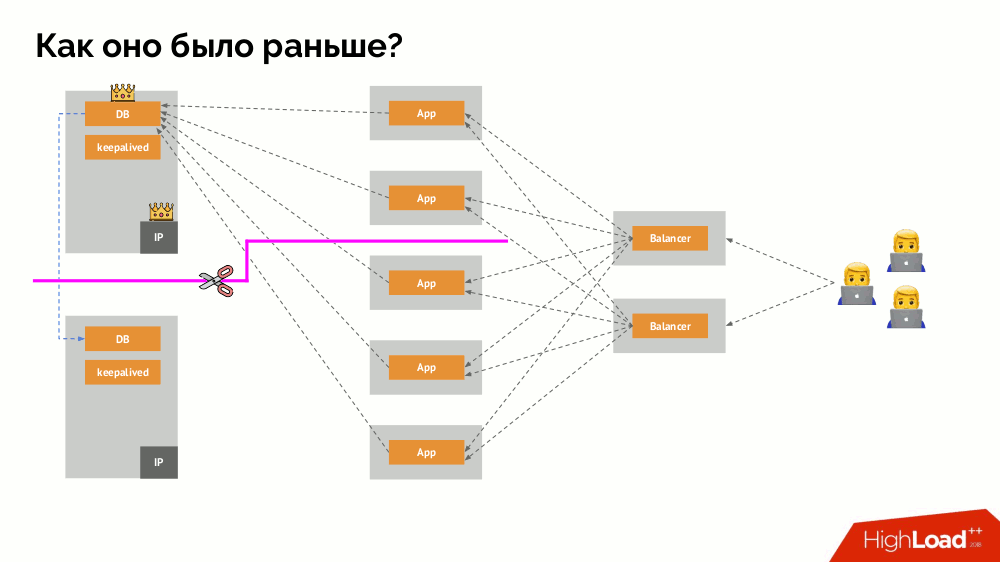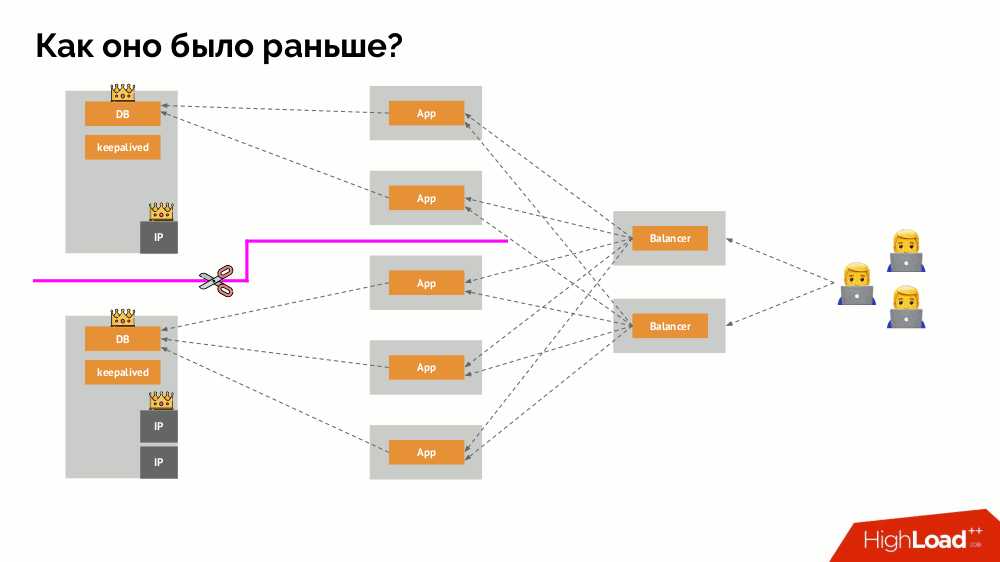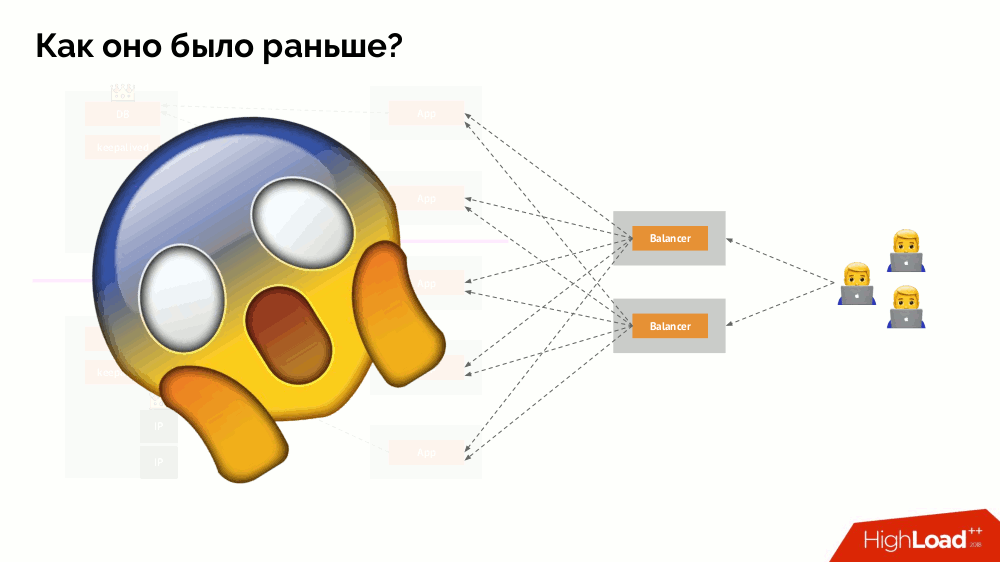 Cerebro dividido
Cerebro dividido clásico: la aplicación comienza a acceder a ambas instancias de DBMS, cada una de las cuales se considera la principal. Para evitar esto, keepalived fue reemplazado por corosync con ya tres instancias para lograr un quórum al votar por el maestro. Sin embargo, incluso en este caso hay problemas: si una instancia de DBMS caída intenta "suicidarse" de todas las formas posibles (elimine la dirección IP, traduzca la base de datos a solo lectura ...), entonces la otra parte del clúster no sabe qué le sucedió al maestro; podría suceder, que ese nodo todavía funciona y las solicitudes llegan a él, lo que significa que todavía no podemos cambiar el asistente.
Para resolver esta situación, existe un mecanismo para aislar el nodo con el fin de proteger a todo el clúster de una operación incorrecta; este proceso se llama
cercado . La esencia práctica se reduce al hecho de que estamos intentando por algún medio externo "matar" al auto caído. Los enfoques pueden ser diferentes: desde apagar la máquina a través de IPMI y bloquear el puerto en el conmutador hasta acceder a la API del proveedor de la nube, etc. Y solo después de esta operación puede cambiar el asistente. Esto garantiza una garantía como
máximo que nos garantiza la
coherencia .
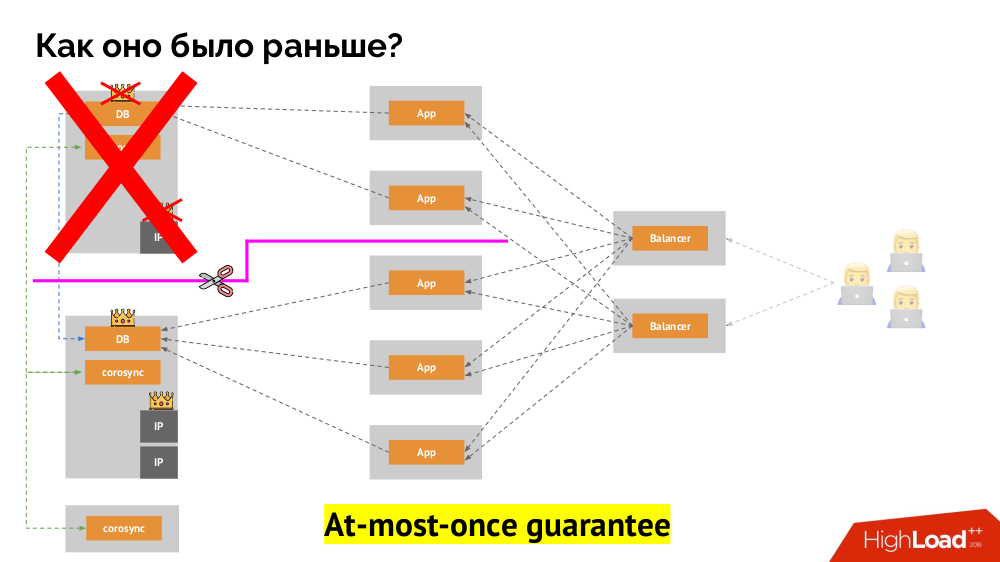
¿Cómo lograr lo mismo en Kubernetes? Para hacer esto, ya hay controladores mencionados, cuyo comportamiento en caso de inaccesibilidad de un nodo es diferente:
Deployment : "Me dijeron que debería haber 3 pods, y ahora solo hay 2 pods, crearé uno nuevo";StatefulSet : "Pod podías ir?" Esperaré: o este nodo volverá o nos dirán que lo matemos " los contenedores en sí (sin la acción del operador) no se recrean. Así es como se logra la misma garantía como máximo una vez.
Sin embargo, aquí, en el último caso, se requiere un cercado: necesitamos un mecanismo que confirme que este nodo definitivamente desapareció. Hacerlo automático es, en primer lugar, muy difícil (se requieren muchas implementaciones) y, en segundo lugar, lo que es peor, generalmente mata los nodos lentamente (acceder a IPMI puede tomar segundos o decenas de segundos, o incluso minutos). Pocas personas están satisfechas con la espera por minuto para cambiar la base al nuevo maestro. Pero hay otro enfoque que no requiere un mecanismo de cercado ...
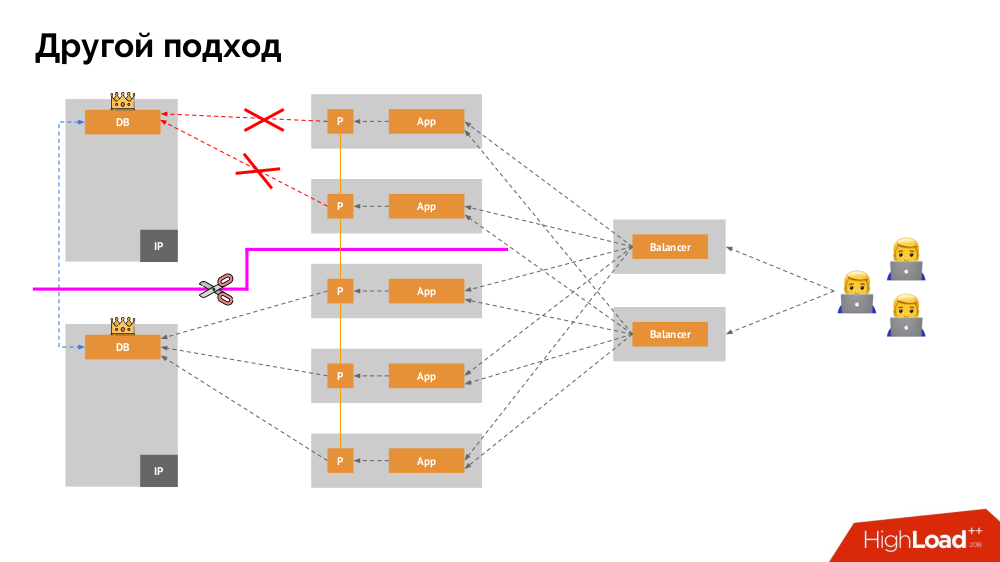
Comenzaré su descripción fuera de Kubernetes. Utiliza un equilibrador de carga especial a través del cual los backends acceden al DBMS. Su especificidad radica en el hecho de que tiene la propiedad de consistencia, es decir, protección contra fallas de red y cerebro dividido, ya que le permite eliminar todas las conexiones al maestro actual, esperar la sincronización (réplica) en otro nodo y cambiar a él. No encontré un término establecido para este enfoque y lo llamé
Cambio constante .
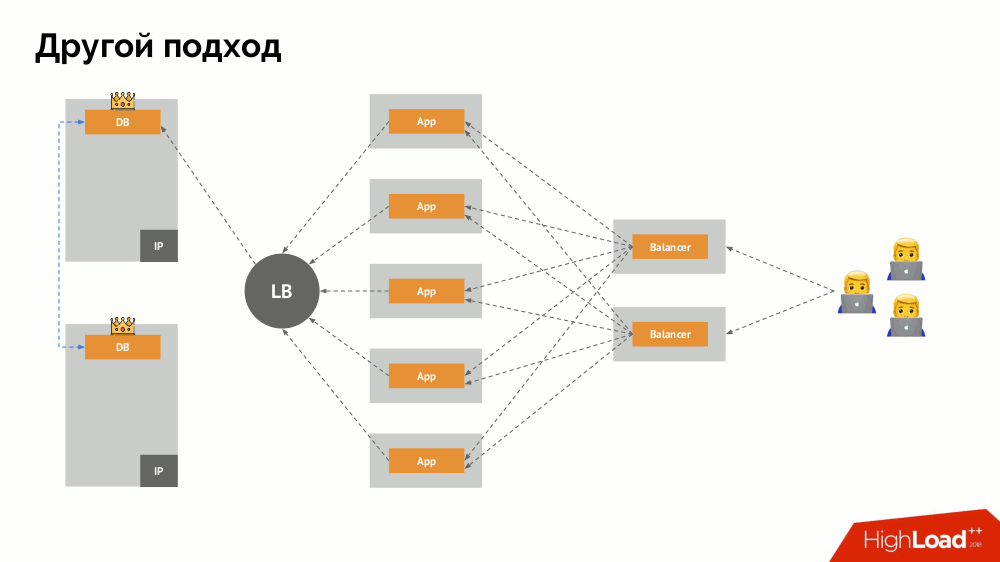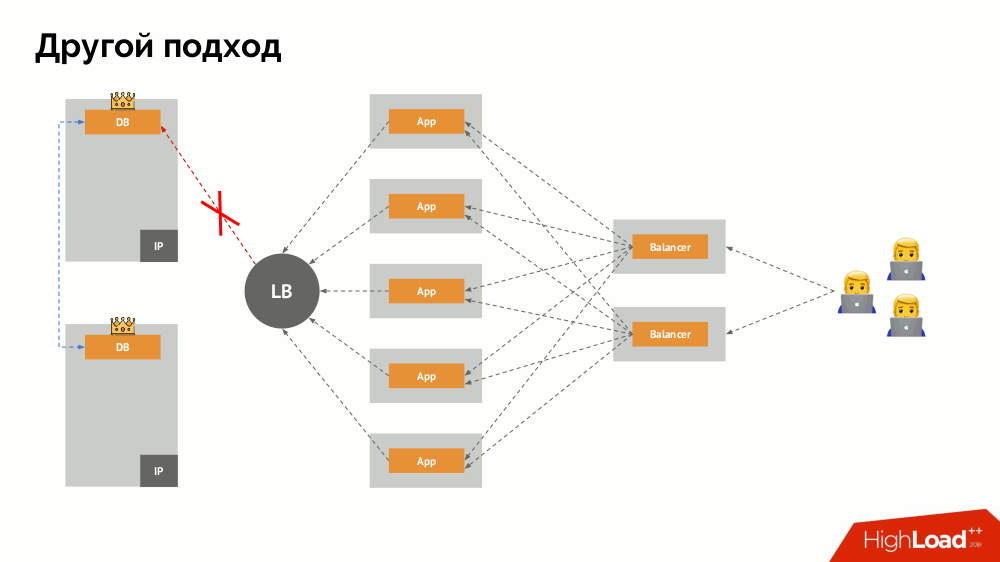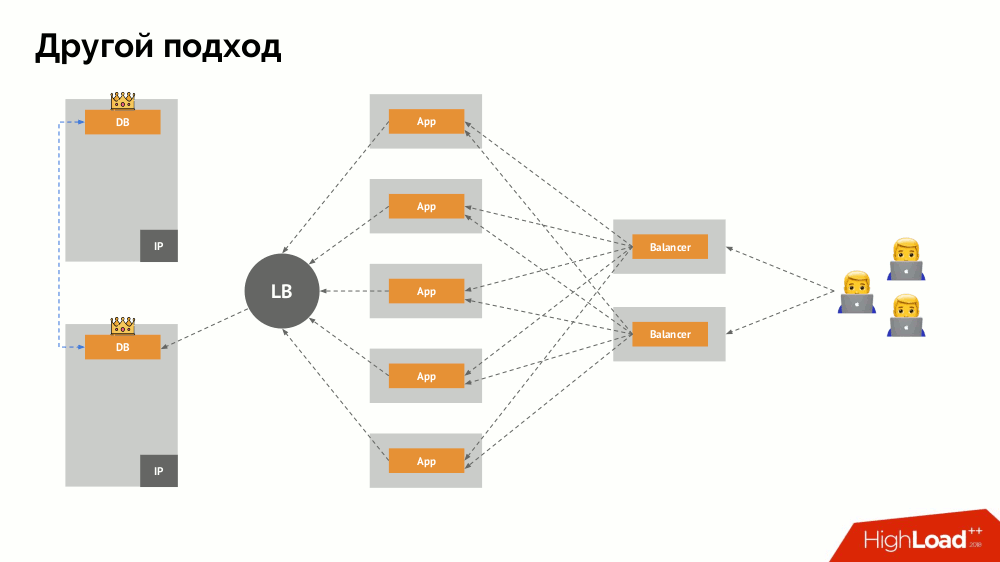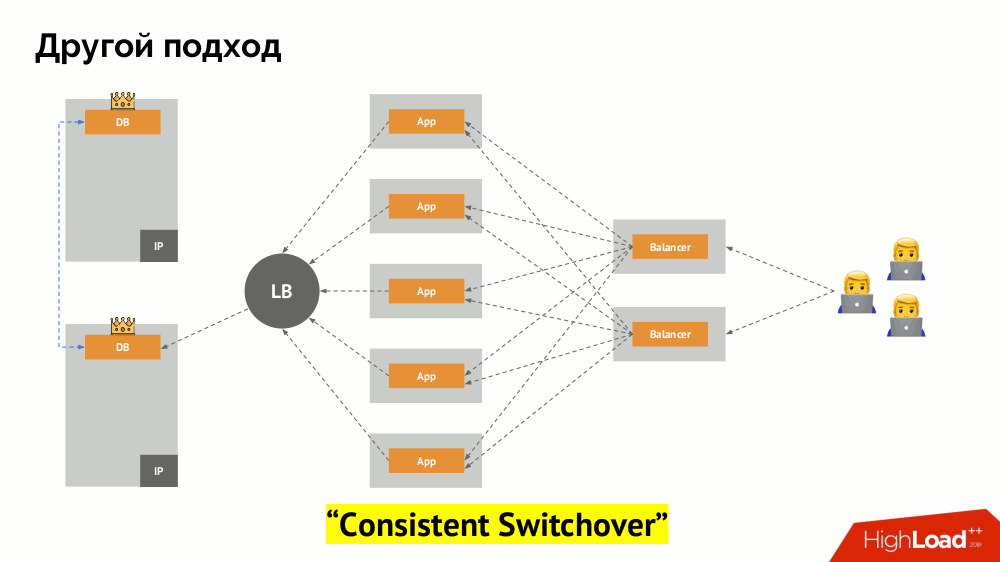
La pregunta principal con él es cómo hacerlo universal, brindando soporte tanto para proveedores en la nube como para instalaciones privadas. Para esto, se agregan servidores proxy a las aplicaciones. Cada uno de ellos aceptará solicitudes de su aplicación (y las reenviará al DBMS), y se reunirá un quórum de todas ellas. Tan pronto como falla una parte del clúster, los servidores proxy que han perdido el quórum eliminan inmediatamente sus conexiones al DBMS.
3. Almacenamiento de datos y Kubernetes
El mecanismo principal es la unidad de red del
Dispositivo de Bloqueo de Red (también conocido como SAN) en varias implementaciones para las opciones de nube deseadas o metal desnudo. Sin embargo, poner una base de datos cargada (por ejemplo, MySQL, que requiere 50 mil IOPS) en la nube (AWS EBS) no funcionará debido a la
latencia .
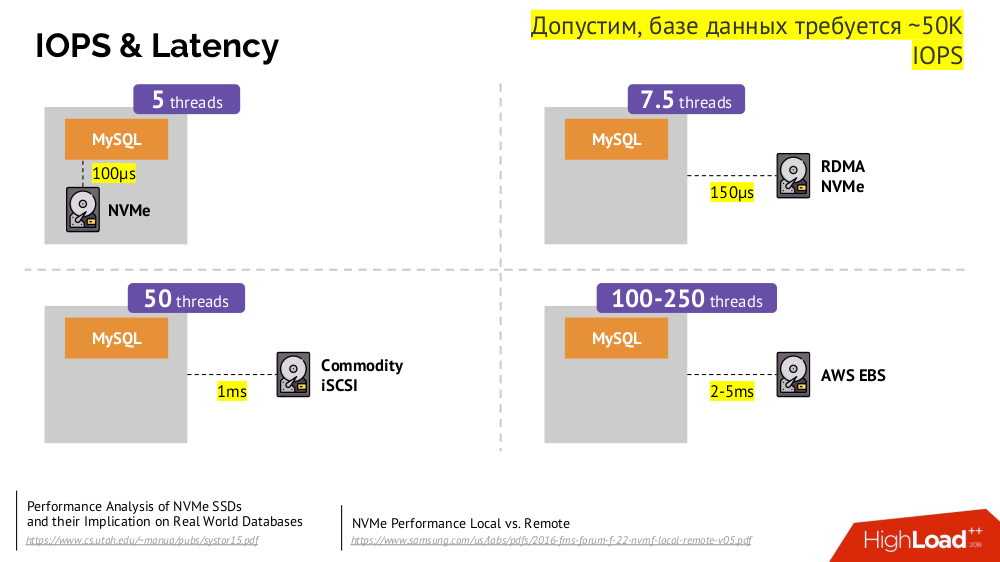
Kubernetes para tales casos tiene la capacidad de conectar un disco duro
local: almacenamiento local . Si ocurre una falla (el disco ya no está disponible en el pod), entonces nos vemos obligados a reparar esta máquina, similar al esquema clásico en caso de falla de un servidor confiable.
Ambas opciones (
Dispositivo de bloqueo de red y
Almacenamiento local ) pertenecen a la categoría
ReadWriteOnce : el almacenamiento no se puede montar en dos lugares (pods): para esta escala, deberá crear un nuevo disco y conectarlo a un nuevo pod (hay un mecanismo K8 incorporado para esto) , y luego rellene con los datos necesarios (ya realizados por nuestras fuerzas).
Si necesitamos el modo
ReadWriteMany , entonces las implementaciones de
Network File System (o NAS) están disponibles: para la nube pública, estas son
AzureFile y
AWSElasticFileSystem , y para sus instalaciones CephFS y Glusterfs para fanáticos de sistemas distribuidos, así como NFS.

Practica
1. Independiente
Esta opción es sobre el caso cuando nada le impide iniciar el DBMS en modo de servidor separado con almacenamiento local. No hay duda de alta disponibilidad ... aunque puede ser implementada en cierta medida (es decir, suficiente para esta aplicación) a nivel de hierro. Hay muchos casos para esta aplicación. En primer lugar, estos son todo tipo de entornos de preparación y desarrollo, pero no solo: los servicios secundarios también caen aquí, deshabilitarlos durante 15 minutos no es crítico. En Kubernetes, StatefulSet lo implementa con un pod:
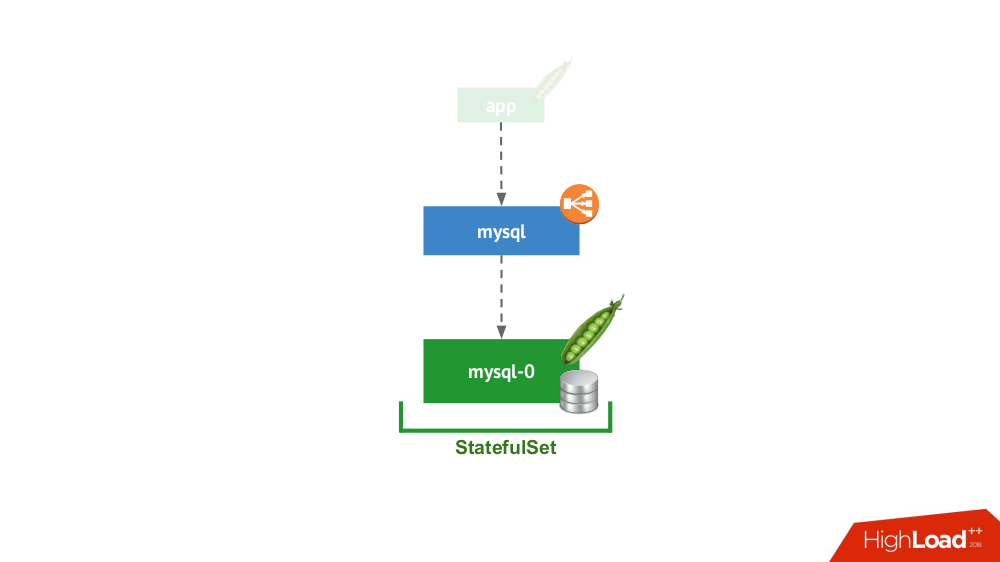
En general, esta es una opción viable que, desde mi punto de vista, no tiene inconvenientes en comparación con la instalación de un DBMS en una máquina virtual separada.
2. Par replicado con cambio manual
StatefulSet usa nuevamente, pero el esquema general se ve así:
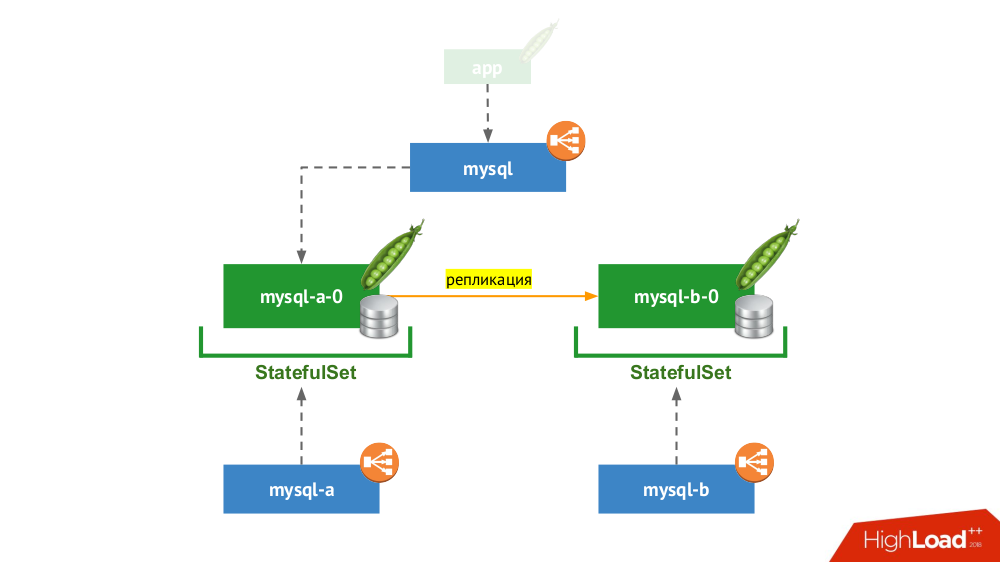
Si uno de los nodos falla (
mysql-a-0 ), no ocurre un milagro, pero tenemos una réplica (
mysql-b-0 ) a la que podemos cambiar el tráfico. En este caso, incluso antes de cambiar el tráfico, es importante no olvidar no solo eliminar las solicitudes DBMS del servicio
mysql , sino también iniciar sesión en el DBMS manualmente y asegurarse de que se completen todas las conexiones (eliminarlas), y también ir al segundo nodo desde el DBMS y volver a configurar la réplica en la dirección opuesta
Si actualmente está utilizando la versión clásica con dos servidores (maestro + en espera) sin
conmutación por error automática, esta solución es equivalente en Kubernetes. Adecuado para MySQL, PostgreSQL, Redis y otros productos.
3. Escala de carga de lectura
De hecho, este caso no tiene estado, porque estamos hablando solo de lectura. Aquí el servidor DBMS principal está fuera del esquema considerado, y dentro del marco de Kubernetes, se crea una "granja de servidores esclavos", que son de solo lectura. El mecanismo general, el uso de contenedores init para llenar los datos de DBMS en cada nuevo pod de esta granja (usando un volcado en caliente o el habitual con acciones adicionales, etc.) depende del DBMS utilizado. Para asegurarse de que cada instancia no se quede muy lejos del maestro, puede usar pruebas de vida.

4. Cliente inteligente
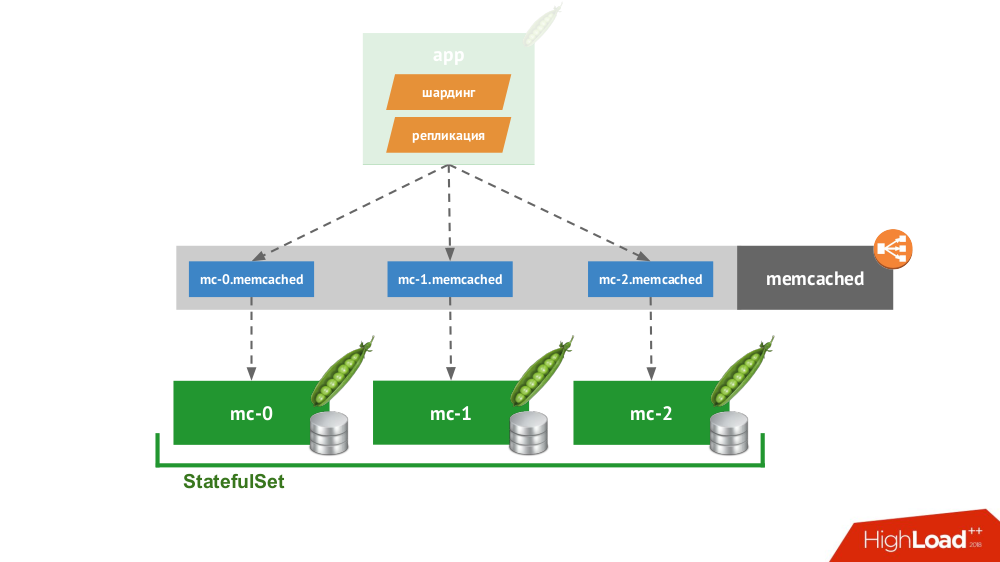
Si realiza un
StatefulSet de tres memcached, Kubernetes proporciona un servicio especial que no equilibrará las solicitudes, pero creará cada pod para su propio dominio. El cliente podrá trabajar con ellos si él mismo es capaz de fragmentar y replicar.
No tiene que ir muy lejos por un ejemplo: así es como funciona el almacenamiento de sesión en PHP de forma inmediata. Para cada solicitud de sesión, las solicitudes se realizan simultáneamente a todos los servidores, después de lo cual se selecciona la respuesta más relevante de ellos (de manera similar a un registro).
5. Soluciones nativas de la nube
Hay muchas soluciones que se centran inicialmente en la falla de los nodos, es decir, ellos mismos pueden realizar
failover y recuperación de nodos, proporcionar garantías de
consistencia . Esta no es una lista completa de ellos, sino solo parte de ejemplos populares:

Todos ellos se colocan simplemente en
StatefulSet , después de lo cual los nodos se encuentran y forman un clúster. Los productos en sí mismos difieren en cómo implementan tres cosas:
- ¿Cómo aprenden los nodos unos de otros? Existen métodos como API de Kubernetes, registros DNS, configuración estática, nodos especializados (semilla), descubrimiento de servicios de terceros ...
- ¿Cómo se conecta el cliente? A través de un equilibrador de carga que se distribuye a los hosts, o el cliente necesita saber acerca de todos los hosts, y él decidirá cómo proceder.
- ¿Cómo se realiza el escalado horizontal? De ninguna manera, completo o difícil / con restricciones.
Independientemente de las soluciones elegidas para estos problemas, todos estos productos funcionan bien con Kubernetes, porque fueron creados originalmente como un "rebaño"
(ganado) .
6. Stolon PostgreSQL
Stolon en realidad te permite convertir PostgreSQL, creado como
mascota , en
ganado . ¿Cómo se logra esto?
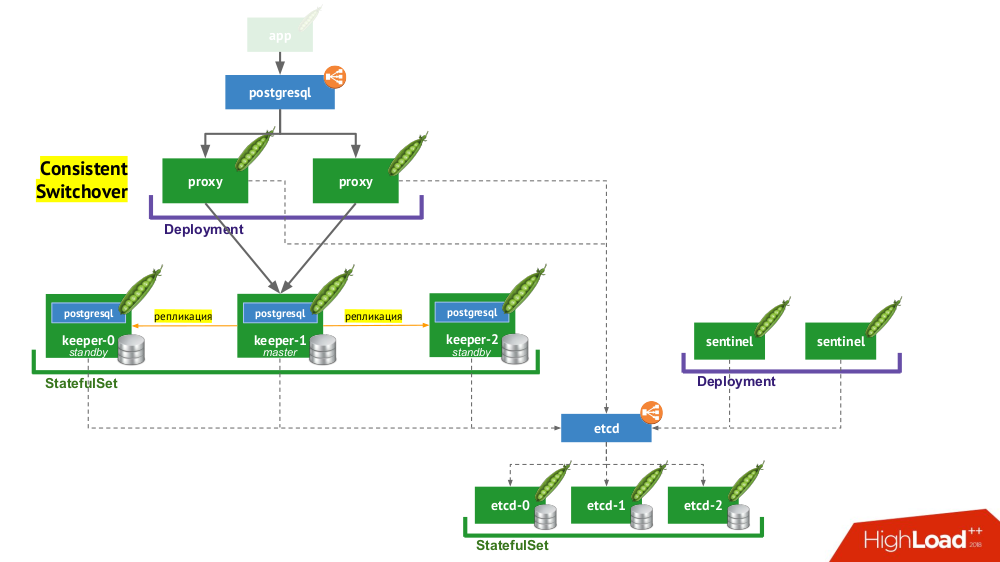
- En primer lugar, necesitamos un descubrimiento de servicio, cuya función puede ser etcd (hay otras opciones disponibles): un grupo de ellas se coloca en un
StatefulSet . - Otra parte de la infraestructura es
StatefulSet con instancias de PostgreSQL. Además del DBMS apropiado, al lado de cada instalación también hay un componente llamado keeper , que realiza la configuración de DBMS. - Otro componente, centinela, se implementa como
Deployment y supervisa la configuración del clúster. Es él quien decide quién será el maestro y el en espera, escribe esta información en etcd. Y keeper lee datos de etcd y realiza acciones correspondientes al estado actual con una instancia de PostgreSQL. - Otro componente implementado en
Deployment y que enfrenta instancias de PostgreSQL, el proxy, es una implementación del patrón de Conmutación consistente ya mencionado. Estos componentes están conectados a etcd, y si se pierde esta conexión, el proxy elimina inmediatamente las conexiones salientes, porque desde ese momento no conoce la función de su servidor (¿ahora es maestro o en espera?). - Finalmente, las instancias de proxy se enfrentan al habitual
LoadBalancer LoadBalancer.
Conclusiones
Entonces, ¿es posible basarse en Kubernetes? Sí, por supuesto, es posible, en algunos casos ... Y si es apropiado, se hace así (ver el flujo de trabajo de Stolon) ...
Todos saben que la tecnología está evolucionando en oleadas. Inicialmente, cualquier dispositivo nuevo puede ser muy difícil de usar, pero con el tiempo, todo cambia: la tecnología está disponible. A donde vamos Sí, permanecerá así por dentro, pero no sabremos cómo funcionará. Kubernetes está desarrollando activamente
operadores . Hasta ahora no hay tantos y no son tan buenos, pero hay movimiento en esta dirección.
Videos y diapositivas
Video de la actuación (aproximadamente una hora):
Presentación del informe:
PD: También encontramos en la red un breve (!) Breve resumen
textual de este informe, gracias a Nikolai Volynkin.
PPS
Otros informes en nuestro blog:
También te pueden interesar las siguientes publicaciones: