Ceph es un almacenamiento de objetos diseñado para ayudar a construir un clúster de conmutación por error. Aún así, las fallas suceden. Todos los que trabajan con Ceph conocen la leyenda sobre CloudMouse o Rosreestr. Desafortunadamente, no se acostumbra compartir experiencias negativas con nosotros, las causas de los fracasos a menudo se silencian y no permiten que las generaciones futuras aprendan de los errores de los demás.
Bueno, configuremos un grupo de prueba, pero cercano al real, y analicemos el desastre por huesos. Mediremos todas las reducciones de rendimiento, encontraremos pérdidas de memoria y analizaremos el proceso de recuperación del servicio. Y todo esto bajo el liderazgo de Artemy Kapitula, quien pasó casi un año estudiando las trampas, hizo que el rendimiento del clúster fallara a cero y la latencia no saltara a valores indecentes. Y obtuve un gráfico rojo, que es mucho mejor.
A continuación, encontrará una versión en video y texto de uno de los mejores informes de
DevOpsConf Russia 2018.
Sobre el orador: Artemy Kapitula, arquitecto del sistema RCNTEC. La compañía ofrece soluciones de telefonía IP (colaboración, organización de una oficina remota, sistemas de almacenamiento definidos por software y sistemas de administración / distribución de energía). La compañía trabaja principalmente en el sector empresarial, por lo tanto, no es muy conocida en el mercado DevOps. Sin embargo, se ha acumulado cierta experiencia con Ceph, que en muchos proyectos se utiliza como elemento básico de la infraestructura de almacenamiento.
Ceph es un repositorio definido por software con muchos componentes de software.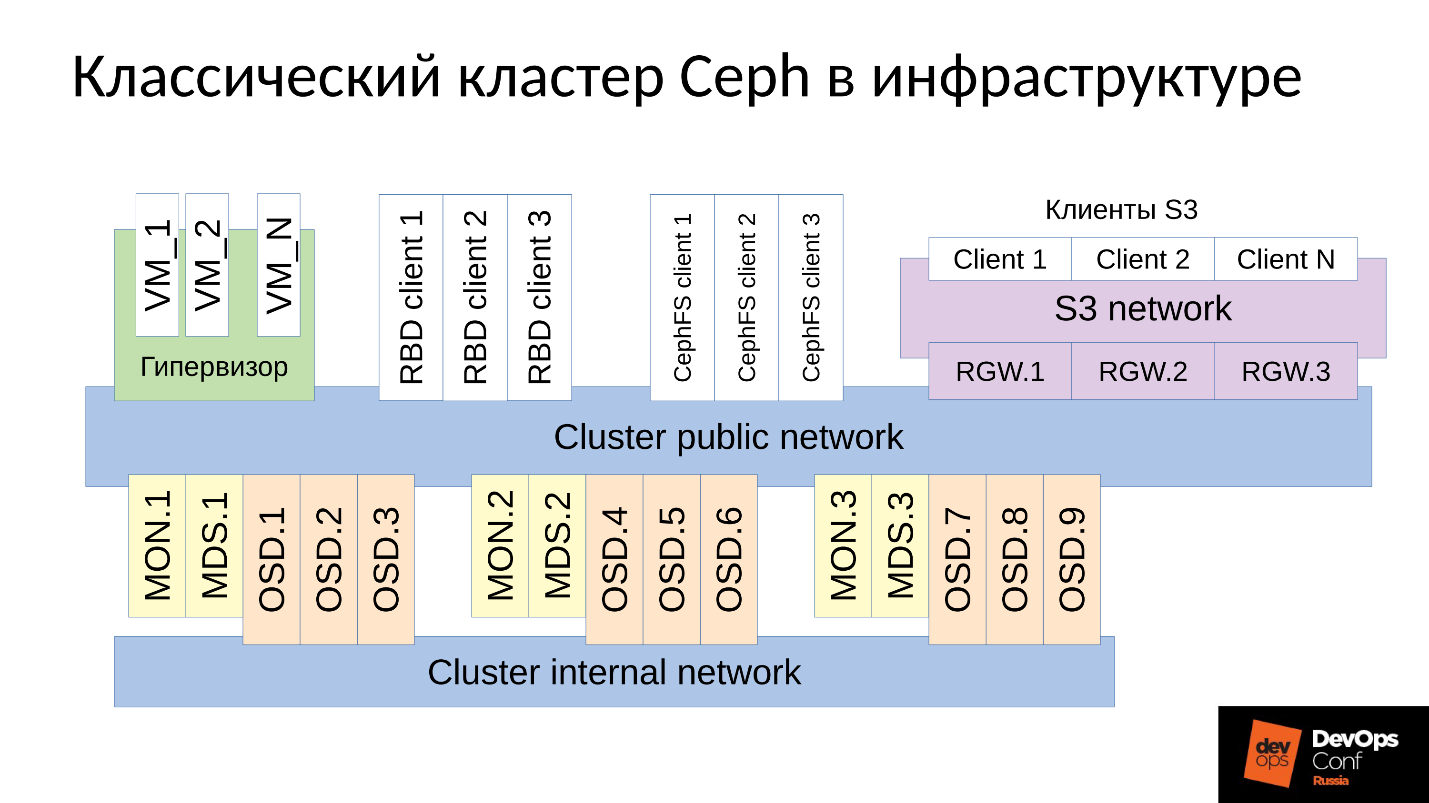
En el diagrama:
- El nivel superior es la red interna del clúster a través de la cual se comunica el clúster;
- El nivel inferior, en realidad Ceph, es un conjunto de demonios internos de Ceph (MON, MDS y OSD) que almacenan datos.
Como regla general, todos los datos se replican. En el diagrama, seleccioné deliberadamente tres grupos, cada uno con tres OSD, y cada uno de estos grupos generalmente contiene una réplica de datos. Como resultado, los datos se almacenan en tres copias.
Una red de clúster de nivel superior es la red a través de la cual los clientes Ceph acceden a los datos. A través de él, los clientes se comunican con el monitor, con MDS (quién lo necesita) y con OSD. Cada cliente trabaja con cada OSD y con cada monitor de forma independiente. Por lo tanto, el
sistema carece de un solo punto de falla , lo cual es muy agradable.
Los clientes
● clientes S3
S3 es una API para HTTP. Los clientes S3 trabajan a través de HTTP y se conectan a los componentes de Ceph Rados Gateway (RGW). Casi siempre se comunican con un componente a través de una red dedicada. Esta red (la llamé red S3) usa solo HTTP, las excepciones son raras.
● Hipervisor con máquinas virtuales.
Este grupo de clientes es de uso frecuente. Trabajan con monitores y con OSD, de los cuales reciben información general sobre el estado del clúster y la distribución de datos. Para obtener datos, estos clientes van directamente a los demonios OSD a través de la red pública Cluster.
● clientes RBD
También hay hosts físicos de metales BR, que generalmente son Linux. Son clientes RBD y obtienen acceso a imágenes almacenadas dentro de un clúster Ceph (imágenes de disco de máquina virtual).
● clientes CephFS
El cuarto grupo de clientes, que no muchos aún tienen, pero que son de creciente interés, son los clientes del sistema de archivos de clúster CephFS. El sistema de clúster CephFS se puede montar simultáneamente desde muchos nodos, y todos los nodos obtienen acceso a los mismos datos, trabajando con cada OSD. Es decir, no hay Gateways como tales (Samba, NFS y otros). El problema es que dicho cliente solo puede ser Linux y una versión bastante moderna.

Nuestra empresa trabaja en el mercado corporativo, y allí la bola está regida por ESXi, HyperV y otros. En consecuencia, el clúster Ceph, que de alguna manera se usa en el sector corporativo, debe soportar las técnicas apropiadas. Esto no fue suficiente para nosotros en Ceph, por lo que tuvimos que refinar y expandir el clúster Ceph con nuestros componentes, de hecho, construimos algo más que Ceph, nuestra propia plataforma para almacenar datos.
Además, los clientes del sector corporativo no están en Linux, pero la mayoría de ellos Windows, ocasionalmente Mac OS, no pueden ir al clúster Ceph. Tienen que atravesar algún tipo de puertas de enlace, que en este caso se convierten en cuellos de botella.
Tuvimos que agregar todos estos componentes y obtuvimos un clúster ligeramente más ancho.

Tenemos dos componentes centrales: el
grupo SCSI Gateways , que proporciona acceso a datos en un clúster Ceph a través de FibreChannel o iSCSI. Estos componentes se utilizan para conectar HyperV y ESXi a un clúster Ceph. Los clientes de PROXMOX todavía trabajan a su manera, a través de RBD.
No permitimos que los clientes de archivos ingresen directamente a la red del clúster; se les asignan varios Gateways tolerantes a fallas. Cada puerta de enlace proporciona acceso al sistema de clúster de archivos a través de NFS, AFP o SMB. En consecuencia, casi cualquier cliente, ya sea Linux, FreeBSD o no solo un cliente, servidor (OS X, Windows), obtiene acceso a CephFS.
Para gestionar todo esto, tuvimos que desarrollar nuestra propia orquesta Ceph y todos nuestros componentes, que son numerosos allí. Pero hablar de eso ahora no tiene sentido, ya que este es nuestro desarrollo. La mayoría probablemente estará interesada en el propio Ceph "desnudo".
Ceph se usa mucho donde, y ocasionalmente ocurren fallas. Seguramente todos los que trabajan con Ceph conocen la leyenda sobre CloudMouse. Esta es una leyenda urbana terrible, pero no todo es tan malo como parece. Hay un nuevo cuento de hadas sobre Rosreestr. Ceph estaba girando en todas partes, y en todas partes estaba fallando. En algún lugar terminó fatalmente, en algún lugar logró eliminar rápidamente las consecuencias.
Desafortunadamente, no es habitual que compartamos experiencias negativas, todos están tratando de ocultar la información relevante. Las empresas extranjeras son un poco más abiertas, en particular, DigitalOcean (un conocido proveedor que distribuye máquinas virtuales) también sufrió una falla de Ceph durante casi un día, fue el 1 de abril, ¡un día maravilloso! Publicaron algunos de los informes, un breve registro a continuación.

Los problemas comenzaron a las 7 de la mañana, a las 11 entendieron lo que estaba sucediendo y comenzaron a eliminar la falla. Para hacer esto, asignaron dos comandos: uno por alguna razón corrió alrededor de los servidores e instaló memoria allí, y el segundo por alguna razón inició manualmente un servidor tras otro y monitoreó cuidadosamente todos los servidores. Por qué Todos estamos acostumbrados a todo lo que se enciende con un solo clic.
¿Qué sucede básicamente en un sistema distribuido cuando se construye de manera efectiva y funciona casi al límite de sus capacidades?Para responder a esta pregunta, debemos analizar cómo funciona el clúster Ceph y cómo se produce la falla.

Escenario de falla cefálica
Al principio, el clúster funciona bien, todo va bien. Entonces sucede algo, después de lo cual los demonios OSD, donde se almacenan los datos, pierden contacto con los componentes centrales del clúster (monitores). En este punto, se produce un tiempo de espera y todo el clúster obtiene una apuesta. El clúster permanece en pie por un tiempo hasta que se da cuenta de que algo anda mal y luego corrige su conocimiento interno. Después de eso, el servicio al cliente se restaura hasta cierto punto y el clúster vuelve a funcionar en modo degradado. Y lo curioso es que funciona más rápido que en el modo normal; este es un hecho sorprendente.
Luego eliminamos el fracaso. Supongamos que perdimos energía, el bastidor se cortó por completo. Los electricistas llegaron corriendo, todos restauraron, suministraron energía, los servidores se encendieron y luego
comenzó la diversión .
Todos están acostumbrados al hecho de que cuando un servidor falla, todo se vuelve malo, y cuando lo encendemos, todo se vuelve bueno. Todo está completamente mal aquí.
El clúster prácticamente se detiene, realiza la sincronización primaria y luego comienza una recuperación suave y lenta, volviendo gradualmente al modo normal.

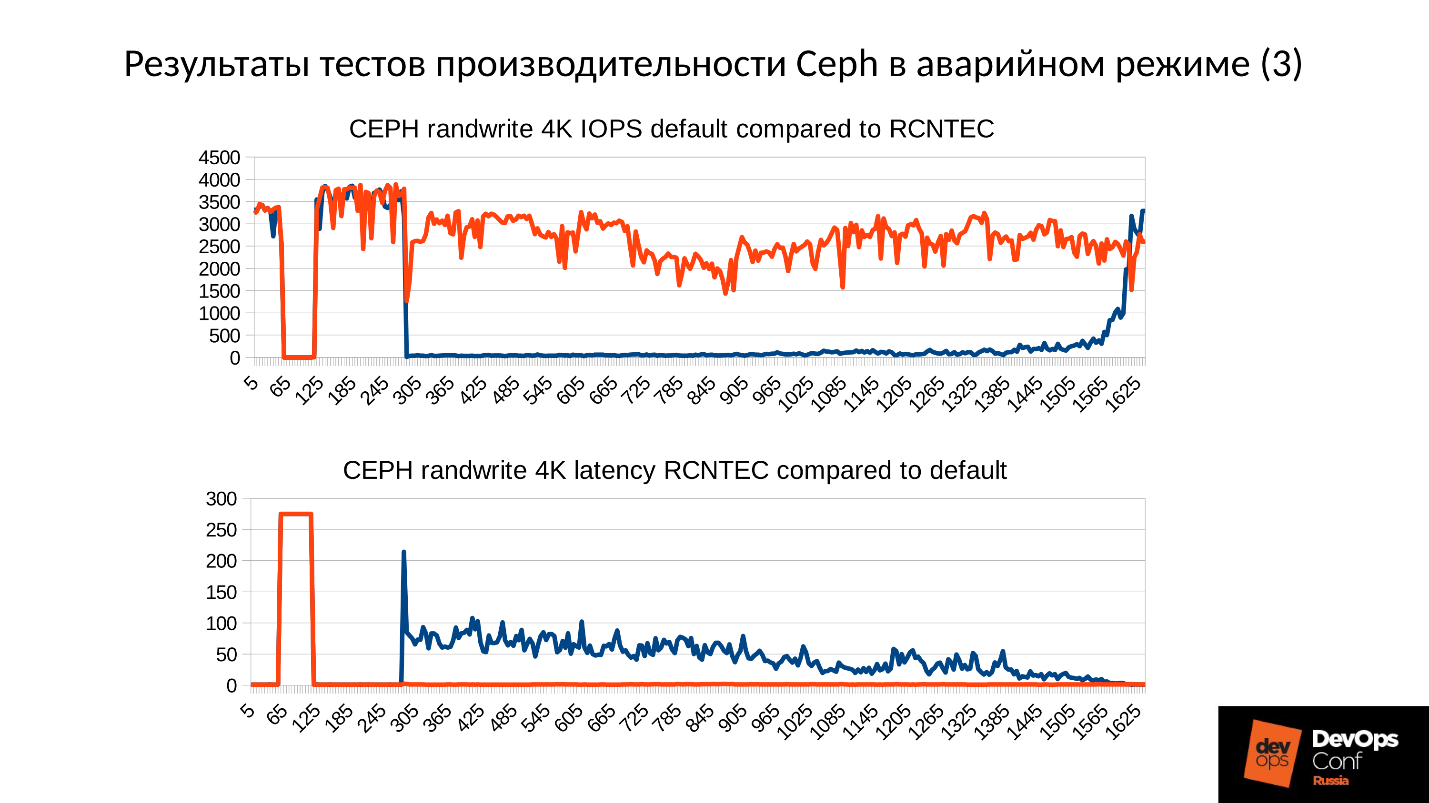
Arriba hay un gráfico del rendimiento del clúster Ceph a medida que se desarrolla una falla. Tenga en cuenta que aquí los intervalos de los que hablamos están claramente trazados:
- Operación normal hasta aproximadamente 70 segundos;
- Falla por un minuto a aproximadamente 130 segundos;
- Una meseta que es notablemente más alta que la operación normal es el trabajo de grupos degradados;
- Luego activamos el nodo faltante: este es un clúster de entrenamiento, solo hay 3 servidores y 15 SSD. Iniciamos el servidor en algún lugar alrededor de 260 segundos.
- El servidor se encendió, ingresó al clúster, IOPS se cayó.
Tratemos de descubrir qué sucedió realmente allí. Lo primero que nos interesa es una caída al comienzo del gráfico.
Falla de OSD
Considere un ejemplo de un clúster con tres bastidores, varios nodos en cada uno. Si falla el rack izquierdo, todos los demonios OSD (¡no los hosts!) Se hacen ping con mensajes Ceph en un intervalo determinado. Si hay una pérdida de varios mensajes, se envía un mensaje al monitor: "Yo, OSD tal y tal, no puedo llegar a OSD tal y tal".

En este caso, los mensajes generalmente se agrupan por hosts, es decir, si dos mensajes de diferentes OSD llegan al mismo host, se combinan en un solo mensaje. En consecuencia, si OSD 11 y OSD 12 informan que no pueden alcanzar OSD 1, esto se interpretará como el Host 11 se quejó de OSD 1. Cuando se informaron OSD 21 y OSD 22, se interpreta como Host 21 insatisfecho con OSD 1 Después de lo cual el monitor considera que OSD 1 está en estado inactivo y notifica a todos los miembros del clúster (al cambiar el mapa OSD), el trabajo continúa en modo degradado.
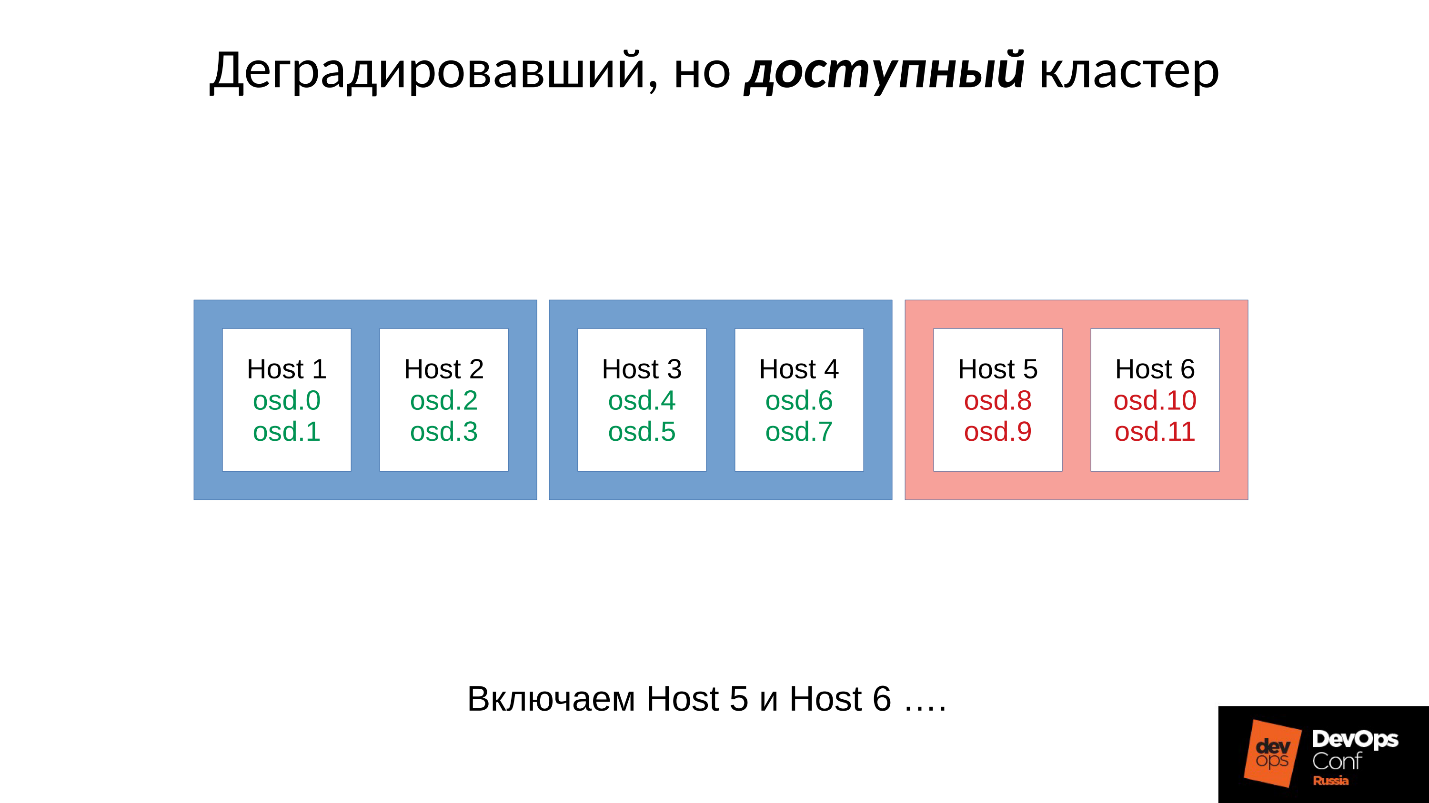
Entonces, aquí está nuestro clúster y rack fallido (Host 5 y Host 6). Encendemos Host 5 y Host 6, cuando apareció el poder, y ...
Comportamiento interno de Ceph
Y ahora la parte más interesante es que estamos comenzando la
sincronización de datos inicial . Como hay muchas réplicas, deben ser sincrónicas y estar en la misma versión. En el proceso de iniciar el inicio de OSD:
- OSD lee las versiones disponibles, el historial disponible (pg_log - para determinar las versiones actuales de los objetos).
- Después de lo cual determina qué OSD están activadas las últimas versiones de objetos degradados (missing_loc) y cuáles están detrás.
- Cuando se almacenan las versiones anteriores, es necesaria la sincronización y se pueden utilizar nuevas versiones como referencia para leer y escribir datos.
Se utiliza una historia que se recopila de todos los OSD, y esta historia puede ser bastante; Se determina la ubicación real del conjunto de objetos en el clúster donde se encuentran las versiones correspondientes. Cuántos objetos hay en el grupo, cuántos registros se obtienen, si el grupo ha permanecido durante mucho tiempo en modo degradado, entonces la historia es larga.
A modo de comparación: el tamaño típico de un objeto cuando trabajamos con una imagen RBD es de 4 MB. Cuando trabajamos en código de borrado - 1 MB. Si tenemos un disco de 10 TB, obtenemos un millón de objetos de megabyte en el disco. Si tenemos 10 discos en el servidor, entonces ya hay 10 millones de objetos, si hay 32 discos (estamos creando un clúster eficiente, tenemos una asignación ajustada), entonces 32 millones de objetos deben mantenerse en la memoria. Además, de hecho, la información sobre cada objeto se almacena en varias copias, porque cada copia indica que en este lugar se encuentra en esta versión, y en esta, en esta.
Resulta una gran cantidad de datos, que se encuentra en la RAM:
- cuantos más objetos, mayor es la historia de missing_loc;
- cuanto más PG, más pg_log y mapa OSD;
además:
- cuanto mayor sea el tamaño del disco;
- cuanto mayor sea la densidad (el número de discos en cada servidor);
- cuanto mayor sea la carga en el clúster y más rápido sea su clúster;
- cuanto más tiempo esté inactivo el OSD (en estado sin conexión);
en otras palabras, cuanto
más empinado sea el clúster que construimos, y cuanto más tiempo no responda la parte del clúster, más RAM se necesitará al inicio .
Las optimizaciones extremas son la raíz de todo mal
"... y el OOM negro llega a los niños y niñas malos por la noche y mata todos los procesos de izquierda a derecha"
Leyenda del administrador de la ciudad
Entonces, la RAM requiere mucho, el consumo de memoria está creciendo (comenzamos de inmediato en un tercio del clúster) y el sistema en teoría puede entrar en SWAP, si lo creó, por supuesto. Creo que hay muchas personas que piensan que SWAP es malo y no lo crean: "¿Por qué? ¡Tenemos mucha memoria! Pero este es el enfoque equivocado.
Si el archivo SWAP no se ha creado de antemano, ya que se decidió que Linux funcionaría de manera más eficiente, tarde o temprano sucederá sin memoria (OOM-killer). Y no el hecho de que matará al que se comió toda la memoria, no el que primero tuvo mala suerte. Sabemos qué es una ubicación optimista: pedimos un recuerdo, nos lo prometen y decimos: "Ahora danos uno", en respuesta: "¡Pero no!" - Y sin memoria asesino.
Este es un trabajo normal de Linux, a menos que esté configurado en el área de memoria virtual.
El proceso se queda sin memoria y se cae rápidamente y sin piedad. Además, no se conocen otros procesos que él haya muerto. No tuvo tiempo de notificar nada a nadie, simplemente lo despidieron.
Luego, el proceso, por supuesto, se reiniciará: tenemos systemd, también lanza, si es necesario, OSD que han caído. Los OSD caídos comienzan y ... comienza una reacción en cadena.
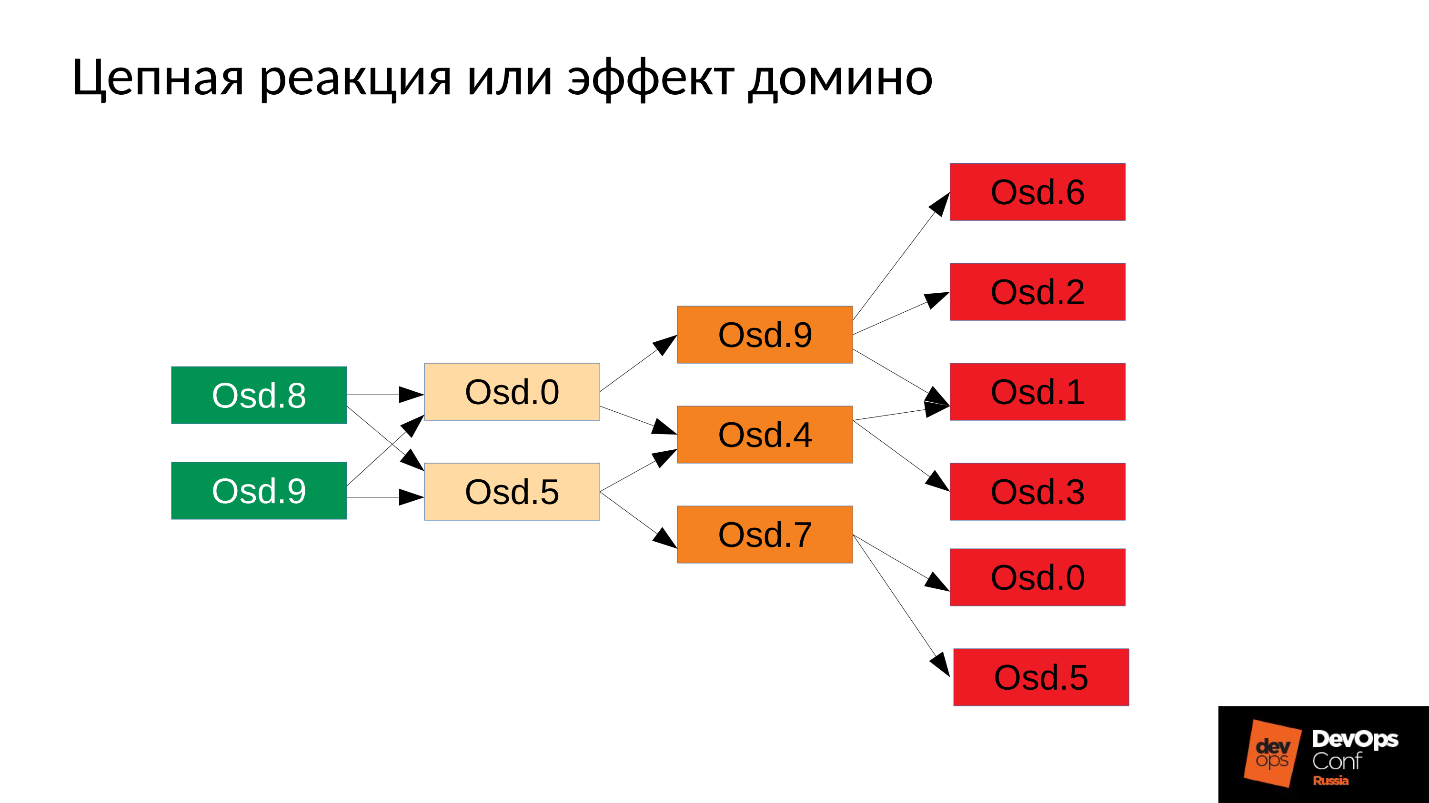
En nuestro caso, comenzamos OSD 8 y OSD 9, comenzaron a aplastar todo, pero no hubo suerte OSD 0 y OSD 5. Un asesino sin memoria voló hacia ellos y los terminó. Reiniciaron: leyeron sus datos, comenzaron a sincronizarse y aplastar al resto. Tres más desafortunados (OSD 9, OSD 4 y OSD 7). Estos tres reiniciaron, comenzaron a presionar a todo el grupo, el siguiente paquete no tuvo suerte.
El grupo comienza a desmoronarse literalmente ante nuestros ojos . La degradación ocurre muy rápidamente, y este "muy rápido" generalmente se expresa en minutos, máximo decenas de minutos. Si tiene 30 nodos (10 nodos por bastidor) y corta el bastidor debido a una falla de energía, después de 6 minutos, la mitad del clúster yace.
Entonces, obtenemos algo como lo siguiente.
En casi todos los servidores, tenemos un OSD fallido. Y si en cada servidor lo es, es decir, en cada dominio de falla que tenemos para el OSD fallido, entonces la
mayoría de nuestros datos son inaccesibles . Cualquier solicitud está bloqueada, para escribir, para leer, no hay diferencia. Eso es todo! Nos levantamos
¿Qué hacer en tal situación? Más precisamente,
¿qué había que hacer ?
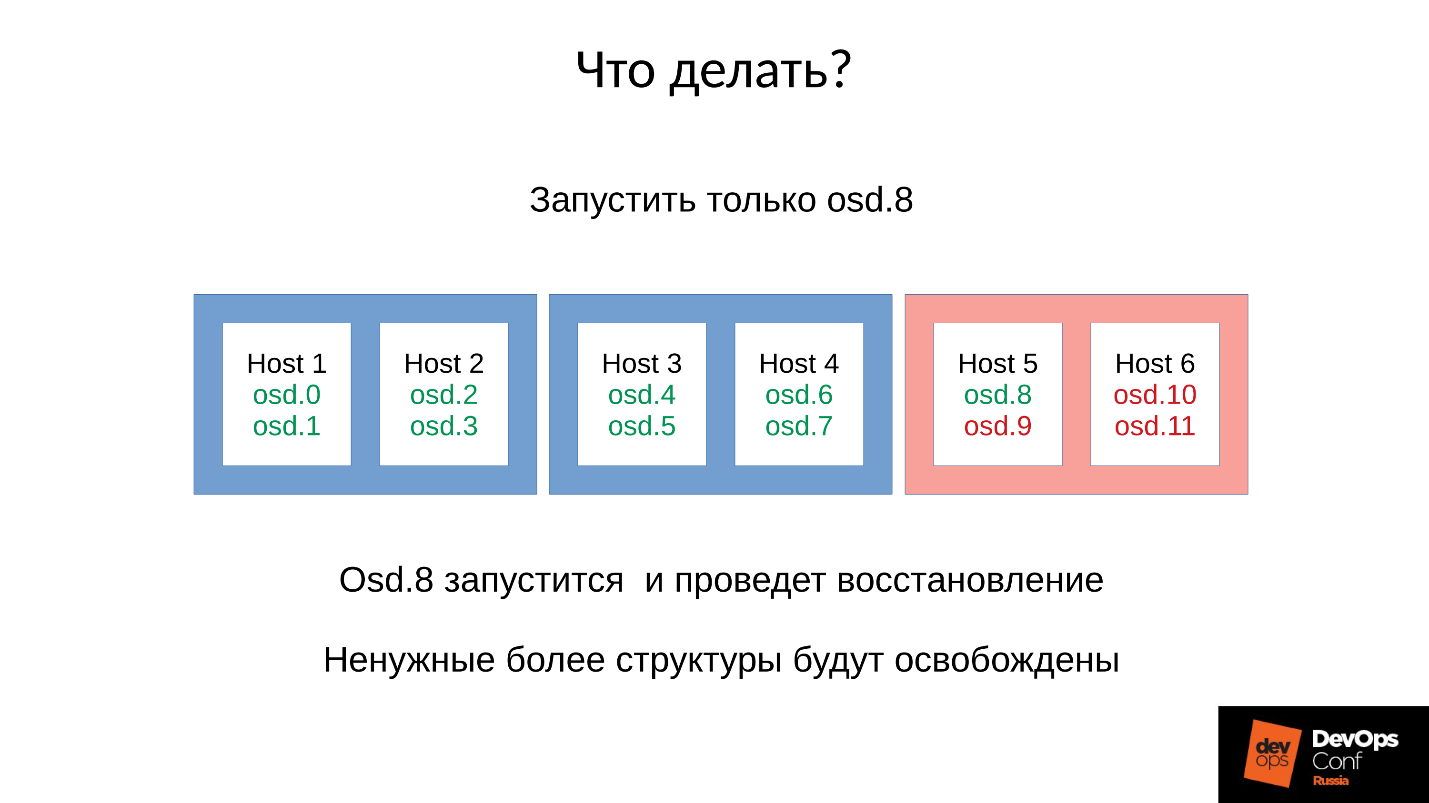
Respuesta: No inicies el grupo de inmediato, es decir, todo el estante, pero levanta cuidadosamente un demonio cada uno.
Pero no lo sabíamos. Comenzamos de inmediato y obtuvimos lo que obtuvimos. En este caso, lanzamos uno de los cuatro demonios (8, 9, 10, 11), el consumo de memoria aumentará en aproximadamente un 20%. Como regla, damos un gran salto. Luego, el consumo de memoria comienza a disminuir, porque algunas de las estructuras que se usaron para contener información sobre cómo se degradó el clúster se están yendo. Es decir, parte de los Grupos de Colocación ha vuelto a su estado normal, y todo lo que se necesita para mantener el estado degradado se libera,
en teoría se libera .
Veamos un ejemplo. El código C a la izquierda y a la derecha es casi idéntico, la diferencia es solo en constantes.

Estos dos ejemplos solicitan una cantidad diferente de memoria del sistema:
- izquierda - 2048 piezas de 1 MB cada una;
- derecha - 2097152 piezas de 1 Kbyte.
Luego, ambos ejemplos esperan que los fotografiemos en la parte superior. Y después de presionar ENTER, liberan memoria, todo excepto la última pieza. Esto es muy importante: queda la última pieza. Y nuevamente están esperando que los fotografiemos.
A continuación se muestra lo que realmente sucedió.

- Primero, ambos procesos comenzaron y se comieron la memoria. Suena como la verdad - 2 GB RSS.
- Presione ENTER y se sorprenderá. El primer programa que se destacó en grandes fragmentos devolvió la memoria. Pero el segundo programa no regresó.
La respuesta a por qué sucedió esto radica en el malloc de Linux.
Si solicitamos memoria en trozos grandes, se emite utilizando el mecanismo anónimo mmap, que se entrega al espacio de direcciones del procesador, desde donde se nos corta la memoria. Cuando hacemos free (), la memoria se libera y las páginas se devuelven al caché de páginas (sistema).
Si asignamos memoria en partes pequeñas, hacemos sbrk (). sbrk () desplaza el puntero a la cola del montón; en teoría, la cola desplazada puede devolverse devolviendo páginas de memoria al sistema si no se utiliza la memoria.
Ahora mira la ilustración. Teníamos muchos registros en la historia de la ubicación de los objetos degradados, y luego vino la sesión del usuario, un objeto de larga duración. Nos sincronizamos y todas las estructuras adicionales desaparecieron, pero el objeto de larga vida permaneció y no podemos mover sbrk () hacia atrás.

Todavía tenemos mucho espacio sin usar que podría liberarse si tuviéramos SWAP. Pero somos inteligentes: deshabilitamos SWAP.
Por supuesto, se utilizará una parte de la memoria desde el principio del montón, pero esto es solo una parte, y un resto muy significativo se mantendrá ocupado.
¿Qué hacer en tal situación? La respuesta está abajo.
Lanzamiento controlado
- Comenzamos un demonio OSD.
- Esperamos mientras está sincronizado, verificamos los presupuestos de memoria.
- Si entendemos que sobreviviremos al comienzo del próximo demonio, comenzaremos al siguiente.
- De lo contrario, reinicie rápidamente el demonio que ocupa la mayor cantidad de memoria. Pudo bajar por un corto tiempo, no tiene mucha historia, faltan locomotoras y otras cosas, por lo que comerá menos memoria, el presupuesto de memoria aumentará ligeramente.
- Corremos alrededor del clúster, lo controlamos y gradualmente lo elevamos todo.
- Verificamos si es posible continuar con el siguiente OSD, ve a él.
DigitalOcean realmente logró esto:
"Nuestro equipo de Datacenter realiza aumentos de memoria mientras que otro equipo continúa lentamente activando nodos mientras administra manualmente el presupuesto de memoria de cada host".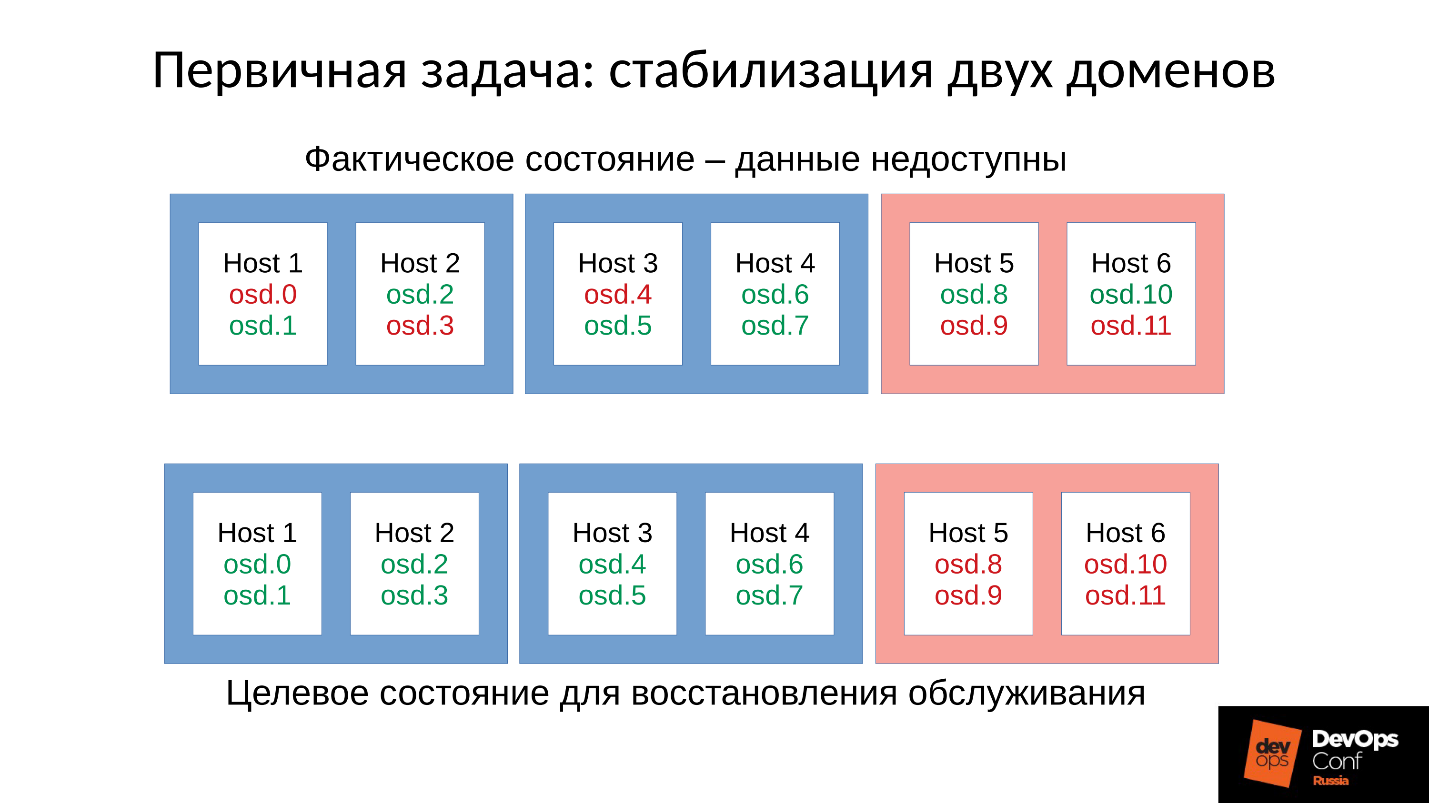
Volvamos a nuestra configuración y situación actual. Ahora tenemos un clúster colapsado después de una reacción en cadena de un asesino sin memoria. Prohibimos el reinicio automático de OSD en el dominio rojo, y uno por uno comenzamos los nodos desde los dominios azules. Porque
nuestra primera tarea es siempre restaurar el servicio , sin entender por qué sucedió esto. Lo entenderemos más tarde, cuando restauremos el servicio. En funcionamiento, este es siempre el caso.
Llevamos el clúster al estado de destino para restaurar el servicio y luego comenzamos a ejecutar un OSD después de otro de acuerdo con nuestra metodología. Observamos el primero, si es necesario, reinicie los otros para ajustar el presupuesto de memoria, el siguiente, 9, 10, 11, y el clúster parece estar sincronizado y listo para comenzar el mantenimiento.
El problema es cómo se realiza el
mantenimiento de escritura en Ceph .
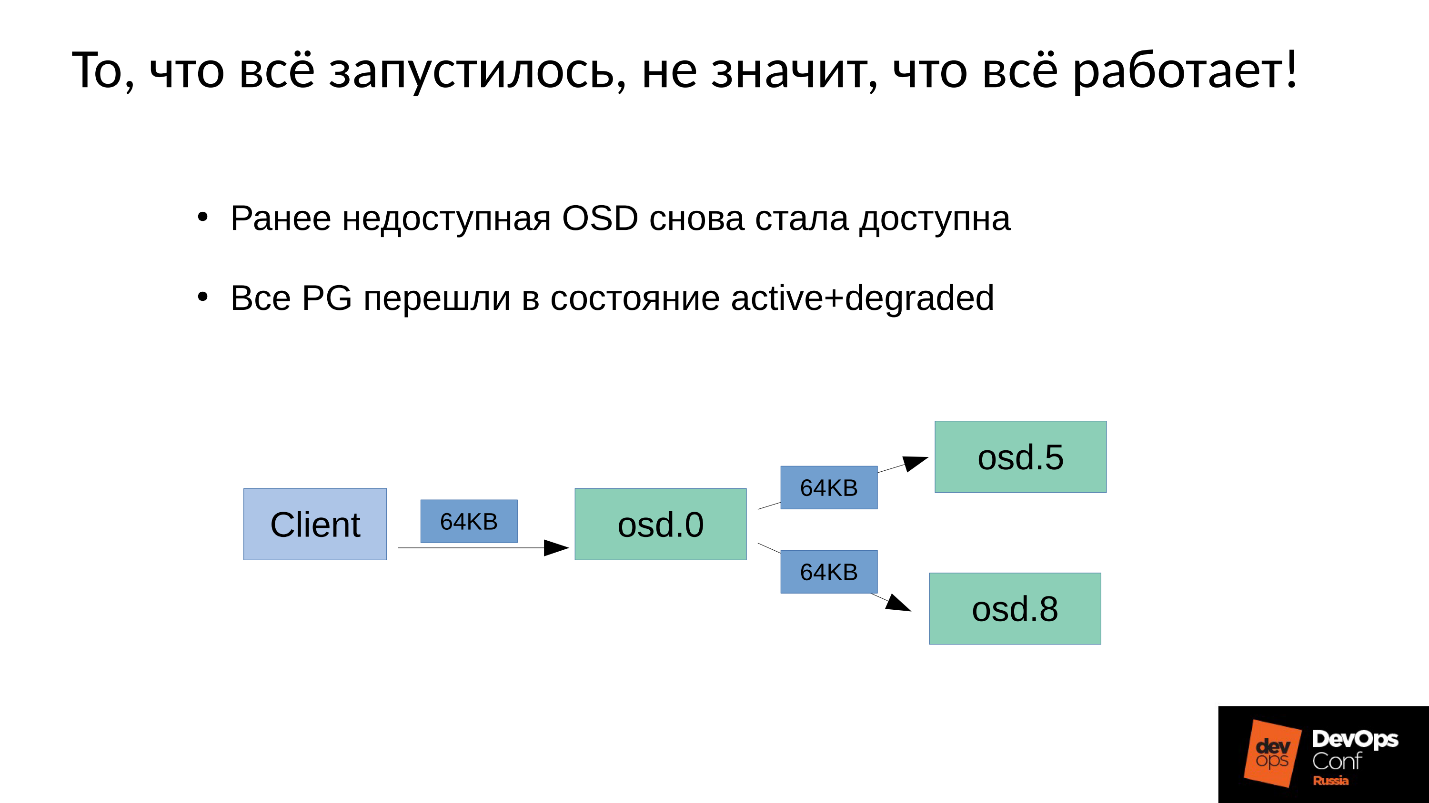
Tenemos 3 réplicas: una OSD maestra y dos esclavas para ella. Aclararemos que el maestro / esclavo en cada grupo de ubicación tiene el suyo propio, pero cada uno tiene un maestro y dos esclavos.
La operación de escritura o lectura recae en el maestro. Al leer, si el maestro tiene la versión correcta, se la dará al cliente. La grabación es un poco más complicada, la grabación debe repetirse en todas las réplicas. En consecuencia, cuando el cliente escribe 64 KB en OSD 0, los mismos 64 KB en nuestro ejemplo van a OSD 5 y OSD 8.
Pero el hecho es que nuestro OSD 8 está muy degradado, porque reiniciamos muchos procesos.

Dado que en Ceph cualquier cambio es una transición de versión a versión, en OSD 0 y OSD 5 tendremos una nueva versión, en OSD 8, la anterior. , , ( 64 ) OSD 8 — 4 ( ). 4 OSD 0, OSD 8, , . , 64 .
— .

:
- 4 1 , 1000 / 1 .
- 4 ( ) 22 , 45 /.
, , , , .
— .

4 22 , 22 , 1 4 . 45 SSD, 1 —
45 .
, .
- , — (45+1) / 2 = 23 .
- 75% , (45 * 3 + 1) / 4 = 34 .
- 90% —(45 * 9 + 1) / 10 = 41 — 40 , .
Ceph, . , , , .
Ceph .

- — : , , , , .
- — latency. latency , . 100% ( , ). Latency 60 , .

, . 10 , 1 200 /, 300 , , . 10 SSD — 300 , — , - 300 .
, .
, . 900 / ( SSD). 2 500 128 ( , ESXi HyperV 128 ). degraded, 225 . file store, object store, ( ), 110 , - .
SSD 110 — !
?1: —
.

: ; PG;
.
:
- , 45 — .
- ( . ), 14 .
- , 8 ( 10% PG).
, , , , , .
2: —
(order, objectsize) .
, , , 4 2 1 . , , . :
:
(32 ) — !
3: —
Ceph .
, -,
Ceph . , , . .
, — Latency. — , — . Latency 30% , , .
Community , preproduction . , . , .
Conclusión
- , . , Ceph - , , .
●
- .
, . ,
. . , , production. , , , DigitalOcean , . , , , .
, , . , : « ! ?!» , , . , : , , down time.
●
(OSD)., , — , , - , .
OSD — — . , .
●
.OSD .
, . , , , .
●
RAM OSD.●
SWAP.SWAP Ceph' , Linux' . .
●
.100%, 10%. , , , .
●
RBD Rados Getway., .
SWAP — . , SWAP — , , , , .
— DevOpsConf Russia. . , youtube , DevOps-.