Hola Esta es una historia sobre las novedades en nuestro complemento de base de datos. Lo lanzamos como un producto
DataGrip separado y lo enviamos a casi todos nuestros otros IDE. Habrá muchas fotos y gifs. Para aquellos que son demasiado flojos para verlos:
- Soporte Cassandra
- Crear archivos SQL a partir de objetos de esquema
- Nuevas inspecciones
- Muchas piezas nuevas de autocompletar
- Trabajar con una fuente de datos a través de una conexión
- Nueva busqueda
- Esquema de color de alto contraste
Gracias a quienes prueban la versión EAP e informan problemas a nuestro rastreador: esto ayuda a no arrastrarlos al lanzamiento :) Los usuarios activos ya han recibido suscripciones gratuitas durante un año.

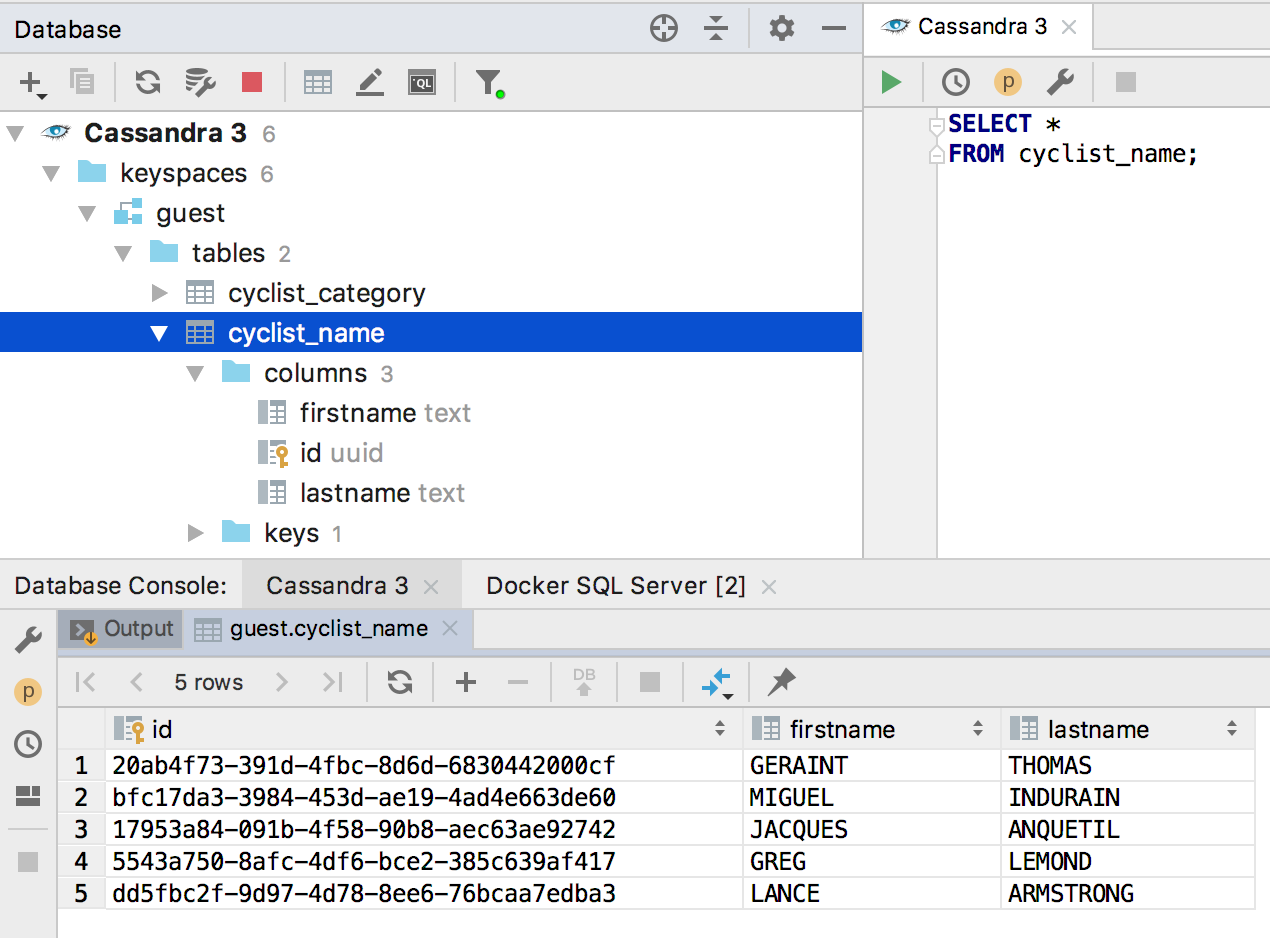
Soporte Cassandra
Estamos dominando lentamente las bases de datos NoSQL. Hasta ahora, solo aquellos que usan lenguajes similares a SQL para consultas. Apoyamos Clickhouse en
2018.2.2 , y en esta versión agregamos Cassandra.
Autocompletar
Hay muchas novedades en este subsistema.
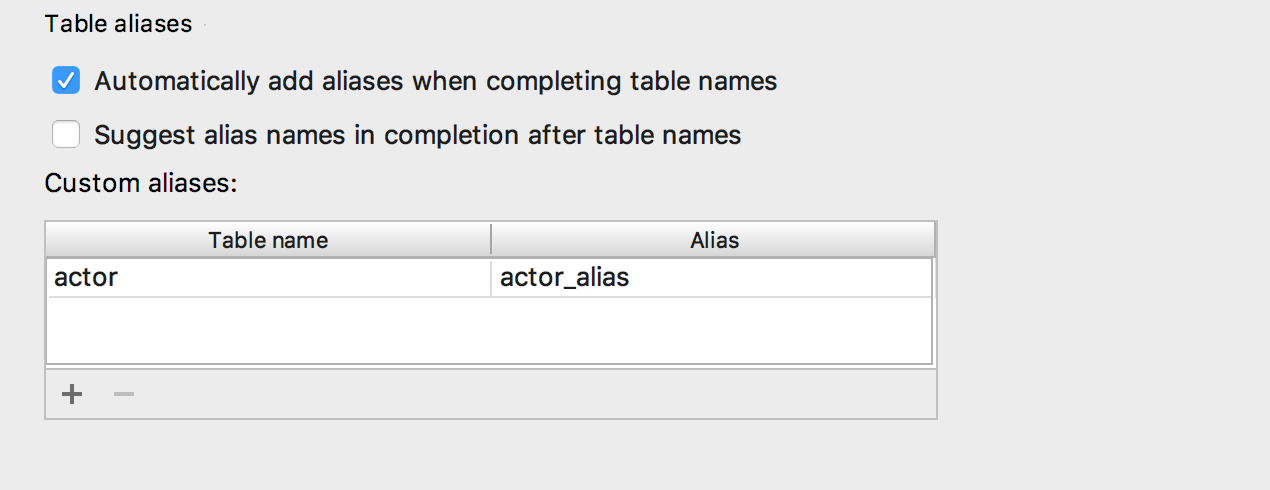
Se agregó la capacidad de insertar
alias automáticamente después de los nombres de las tablas. Si el seudónimo propuesto por nosotros no le conviene, indique qué seudónimos usar para nombres específicos.
Como resultado, funciona así:
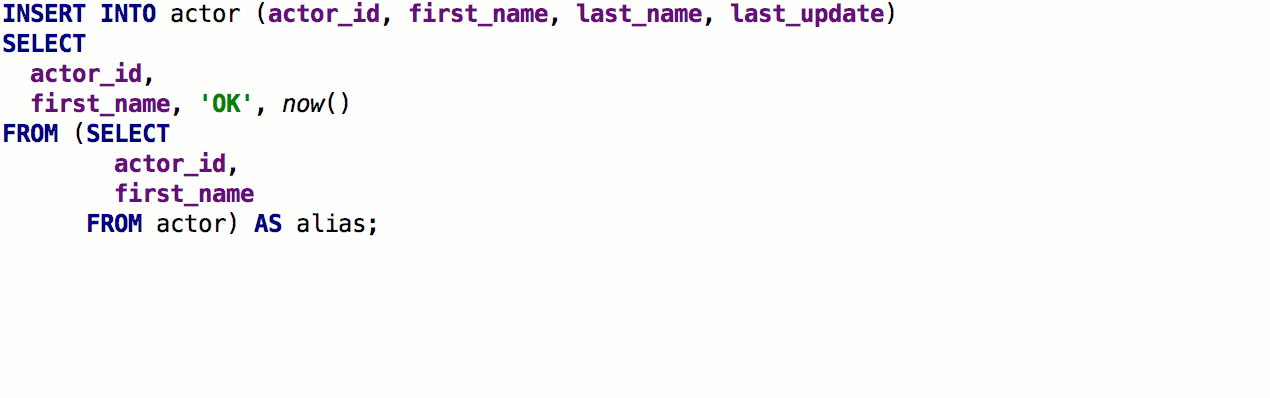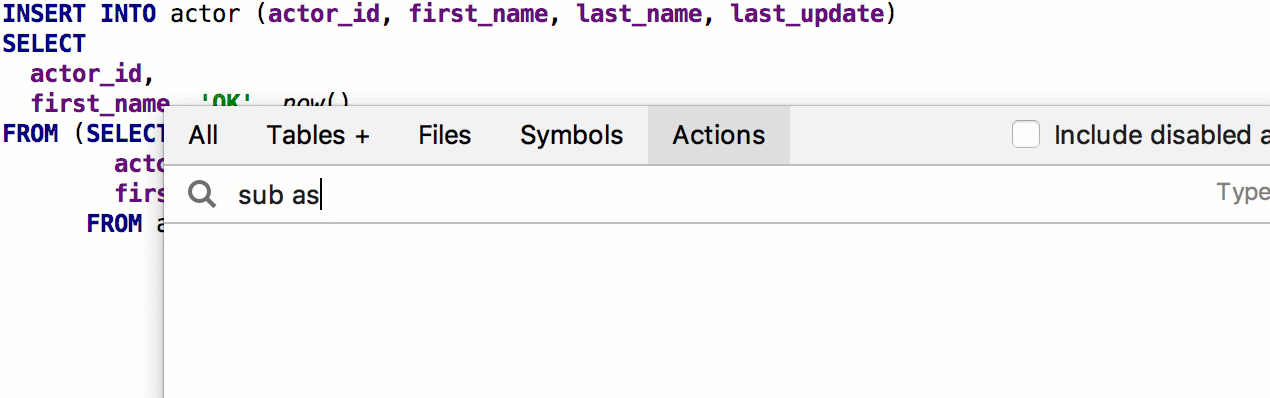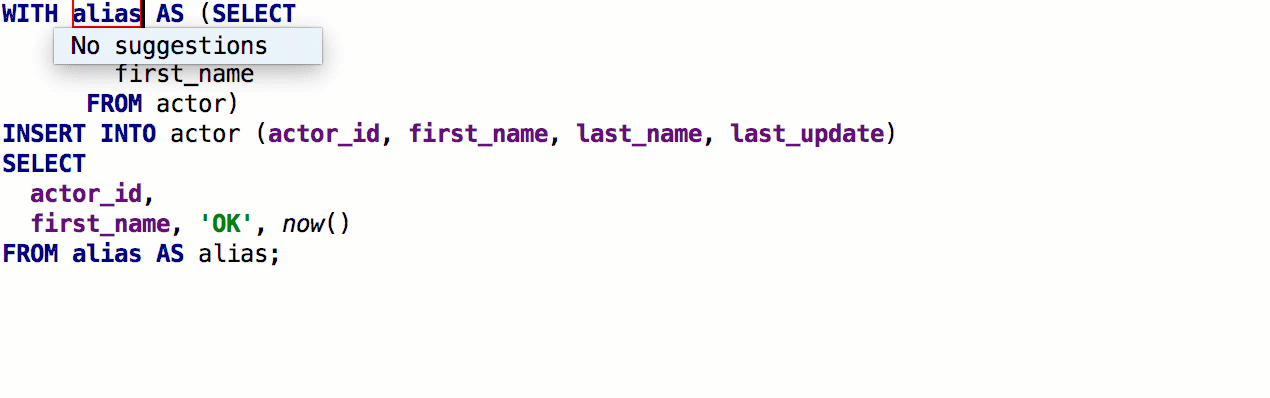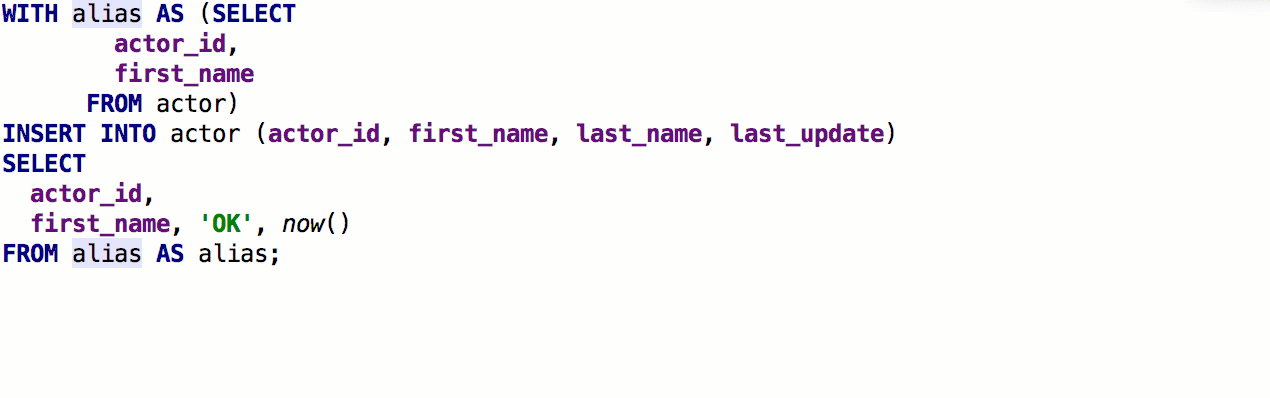
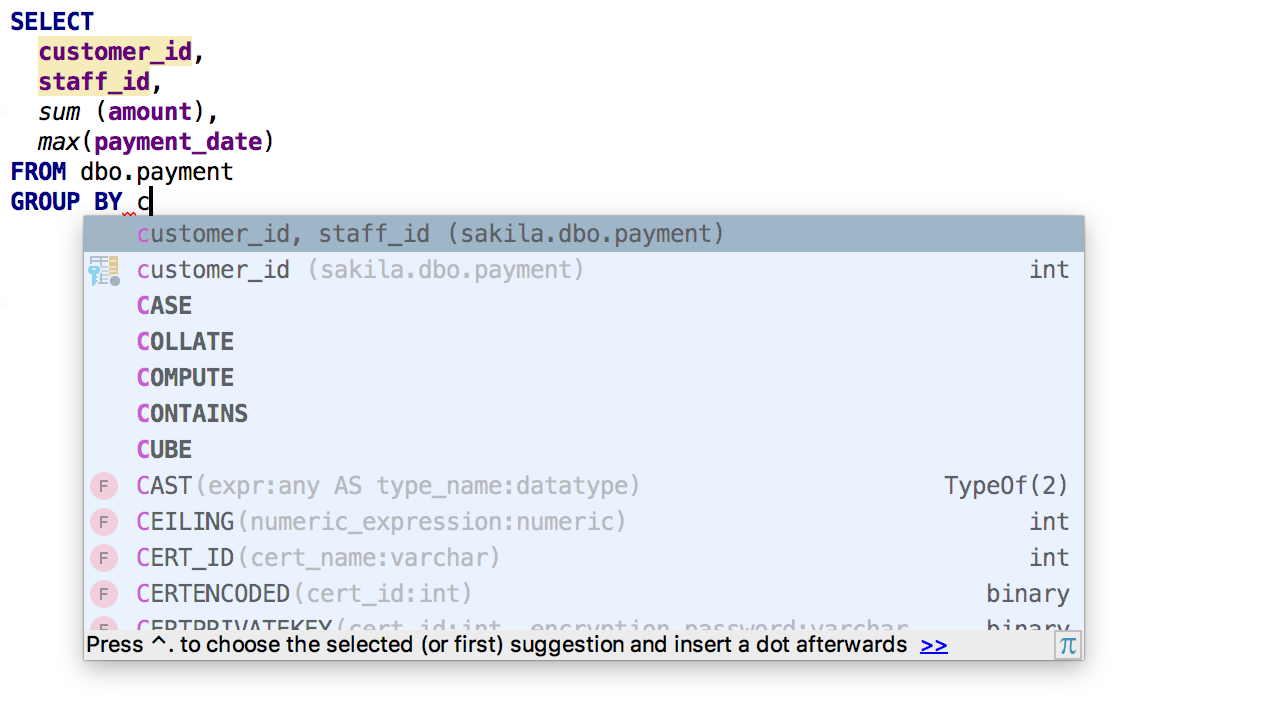
Al usar
GROUP BY DataGrip ofrecerá una lista de
columnas no agregadas .
La cláusula SELECT ofrece una
lista de todas las columnas .
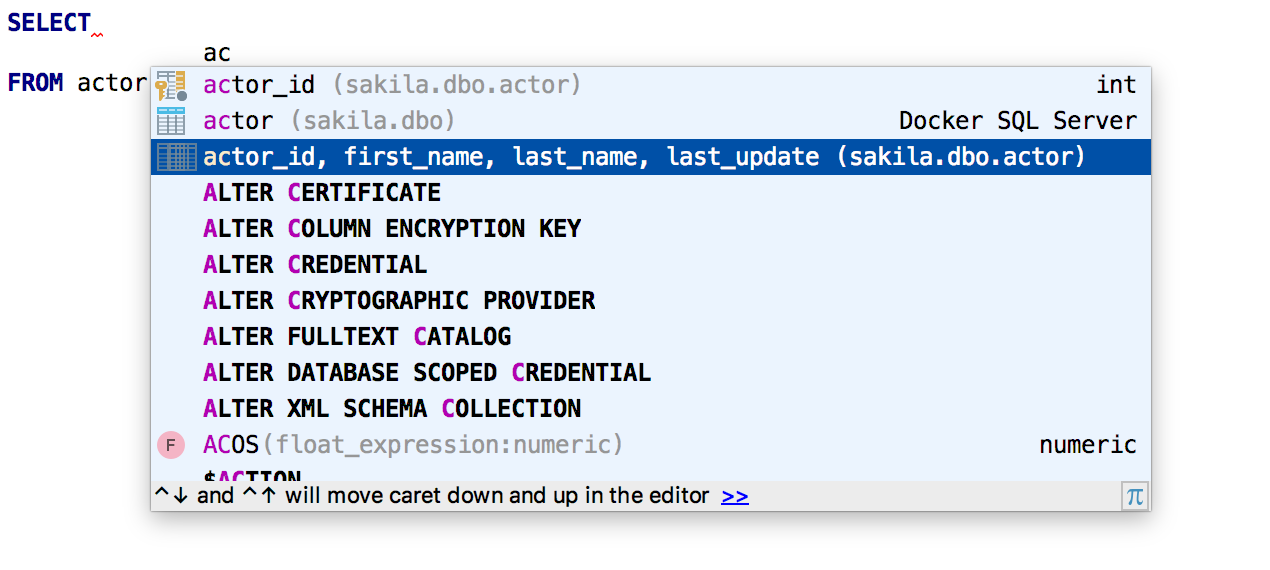
La finalización automática funciona para
parámetros con nombre .
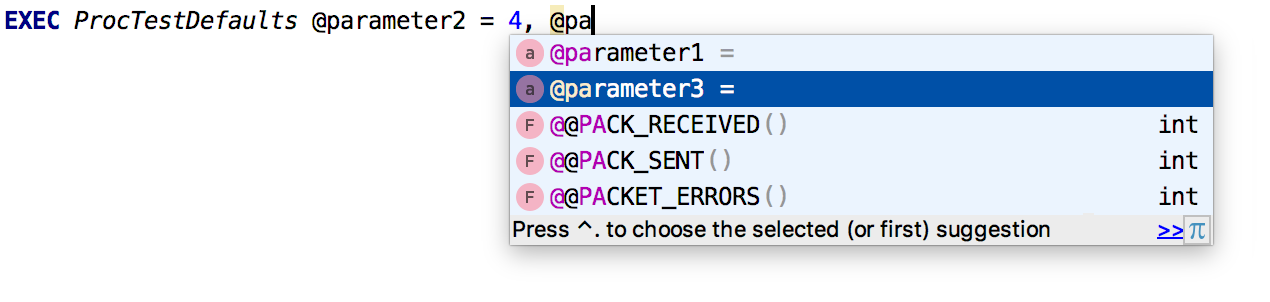
También agregamos información de
contexto para nombres idénticos.
Finalmente
finalizado el postfix : esto es cuando a través del punto escriben algo relacionado con el objeto.

Por ejemplo, si después de
SELECCIONAR escribe el nombre de Table.afrom, la
cláusula FROM se expande en la lista de columnas. O, en nuestra opinión, lo más conveniente, puede agregar .cast a una columna o variable.
Mejor ver una vez:

La finalización automática ha mejorado para
las funciones de ventana : OVER () se agrega automáticamente y el carro se coloca en el lugar correcto.

Refactorización
Una cosa importante que ya era hora de hacer
: usar un alias en lugar de una tabla. Haga clic en la tabla Alt + Intro → Introducir alias. Las tablas de uso serán reemplazadas por alias.

Después del lanzamiento anterior, recibimos un comentario detallado de
speshuric . Por ejemplo, encontró muchas secuencias de comandos no obvias para la
subconsulta Extract como CTE. Esta refactorización se llama a través del menú
Refactor → Extraer → Subconsulta como CTE , pero recomendamos acostumbrarse a
Buscar acción (Ctrl + Shift + A).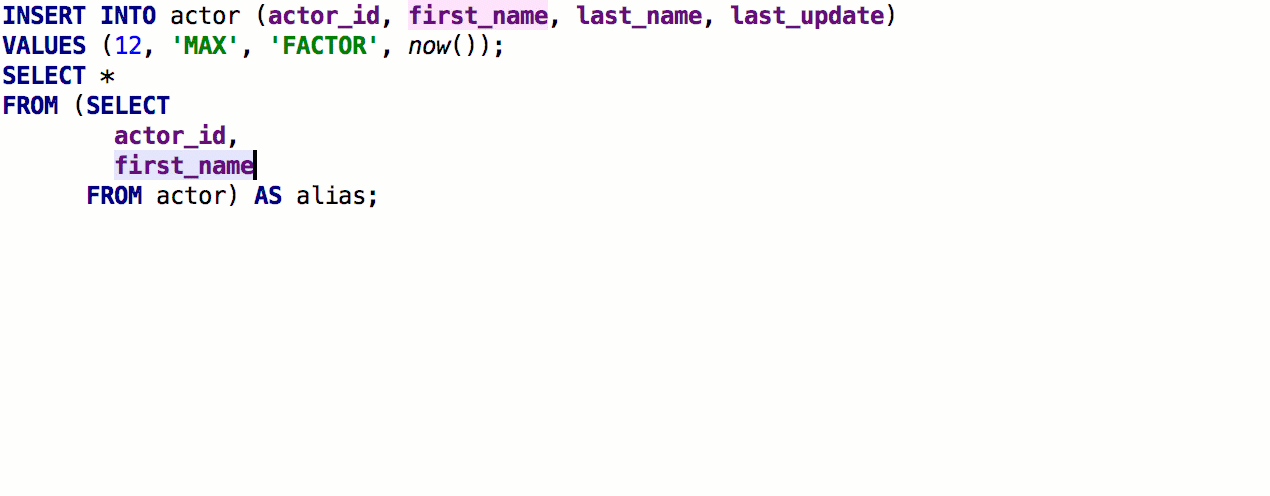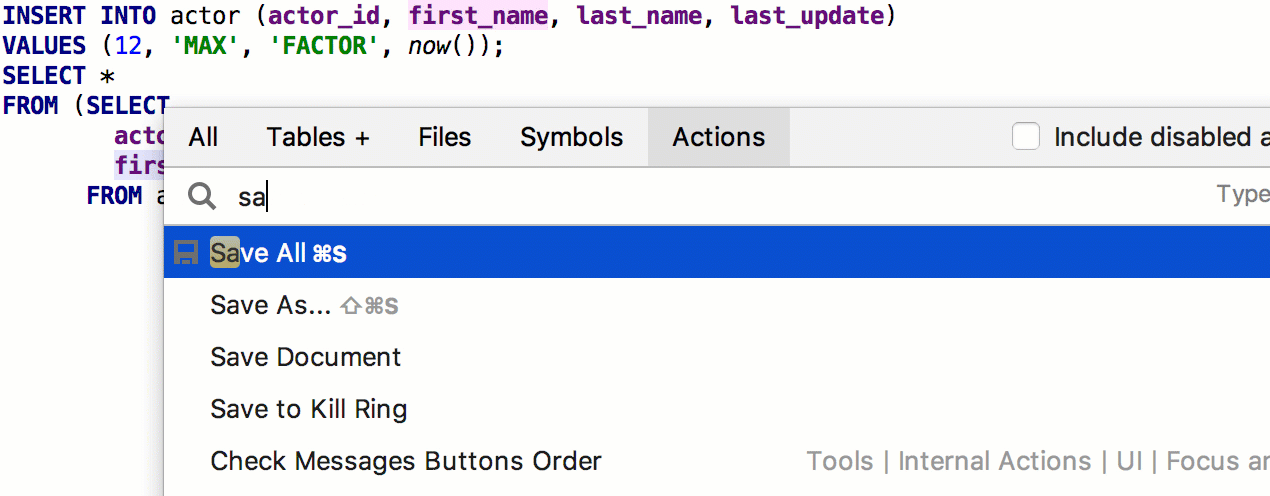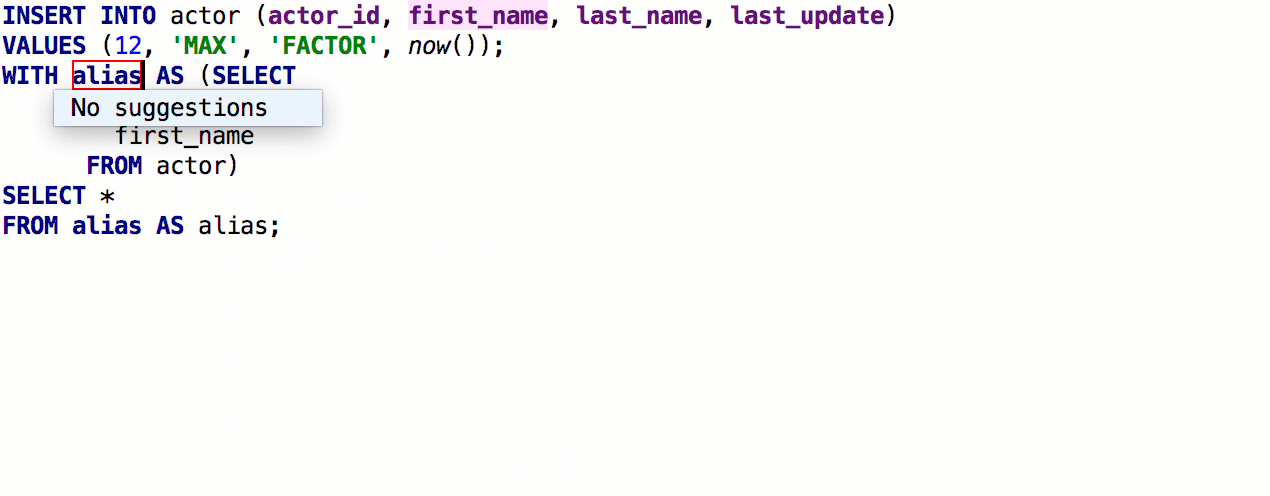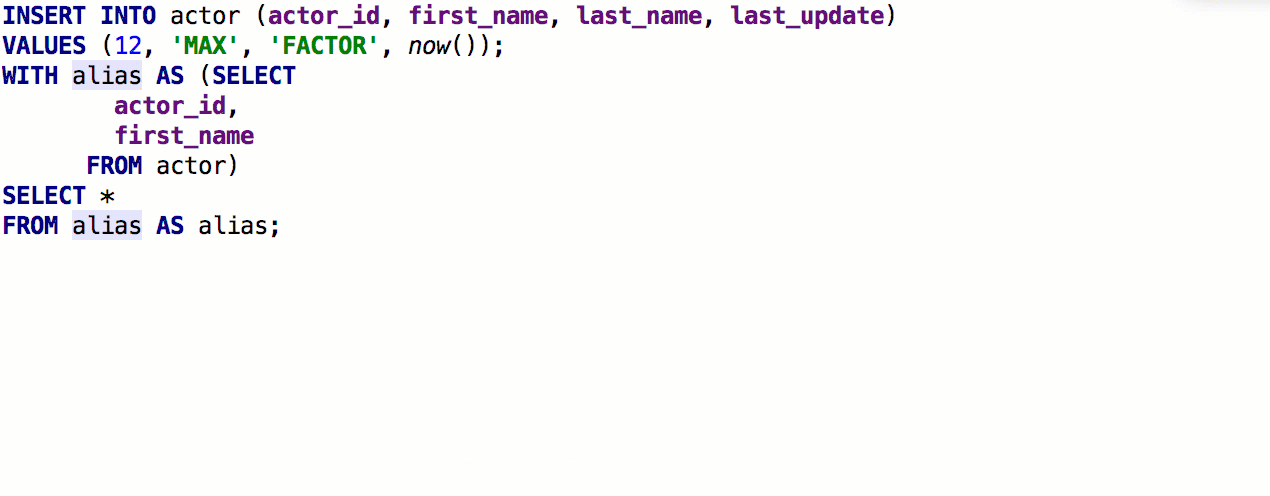
Que hemos hecho:
- El nuevo nombre para CTE no está en conflicto con el existente:
DBE-6496- Definimos correctamente el contexto si la solicitud está envuelta en otra expresión:
DBE-6503 ,
DBE-6517- No ofrecemos refactorización en el caso de
AS TableName :
DBE-6490- Compatible con MySQL 8.
- Funciona como debería con subconsultas profundas.
DBE-7332 ,
DBE-7333Generación de código
Las plantillas de código se pueden
adjuntar a dialectos : una plantilla puede funcionar para algunas bases y no para otras.
Más importante: la misma plantilla puede generar un código diferente para diferentes bases de datos. Para hacer esto, cree grupos de plantillas para cada dialecto, porque los mismos nombres de plantilla no son compatibles dentro del mismo grupo (de forma predeterminada, almacenamos plantillas en el grupo SQL).
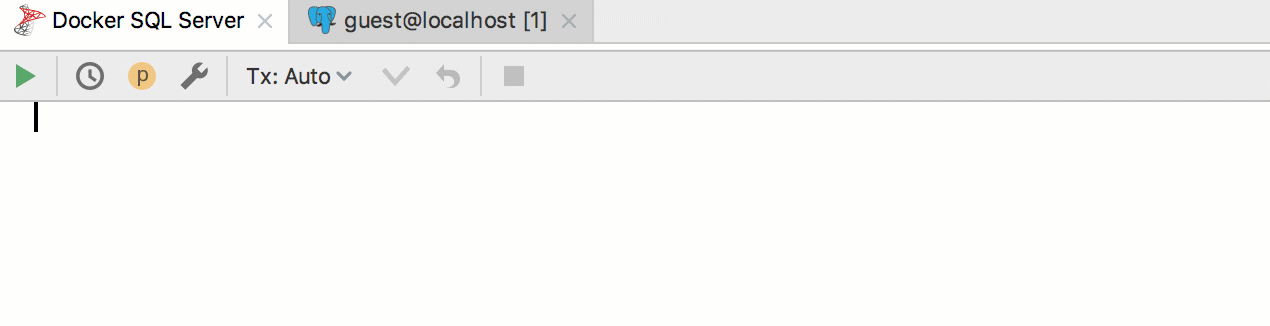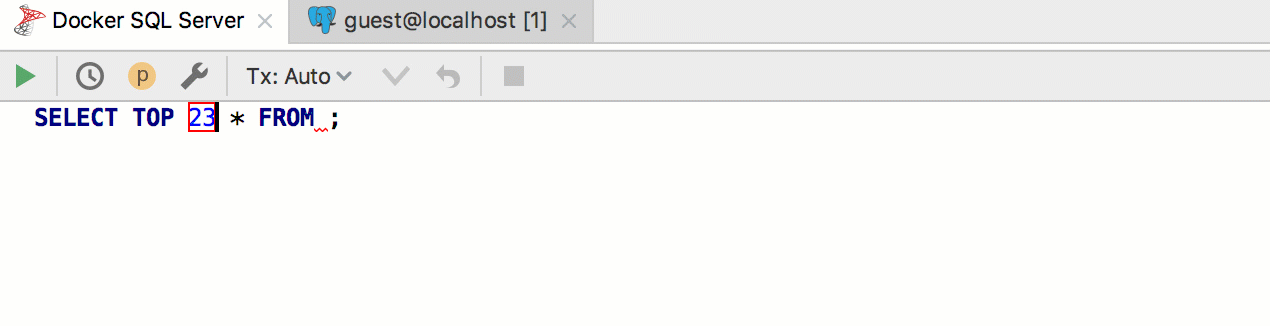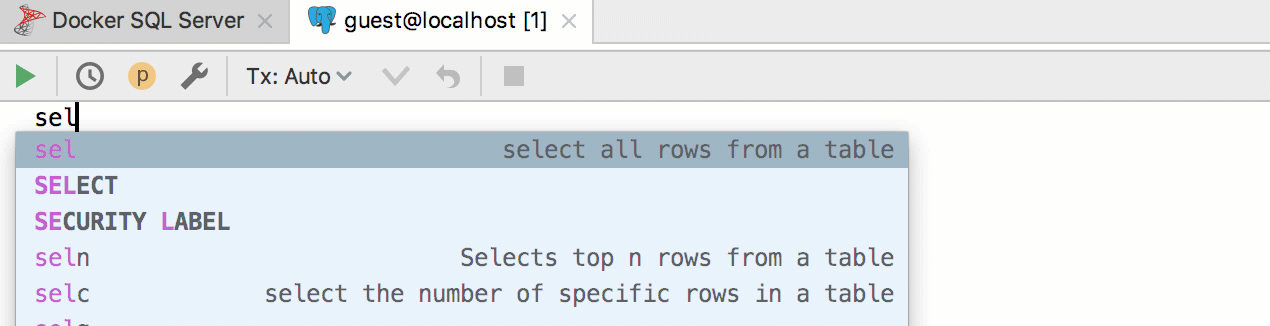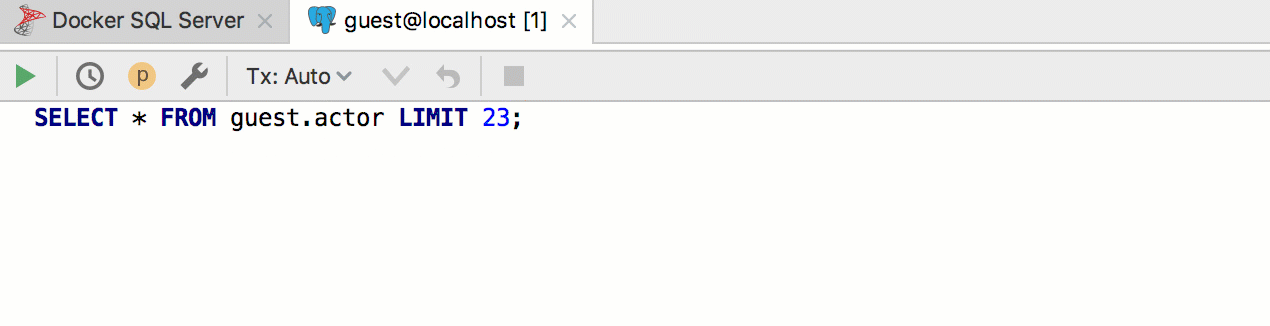
Por ejemplo, queremos crear una plantilla para extraer las primeras n filas de una tabla. PostgreSQL y SQL Server usan una sintaxis diferente para esto, y siempre usaremos la plantilla
seln . Por consiguiente, implemente dos patrones en dos grupos diferentes y asígneles los dialectos correspondientes.

Resulta así:
Desde la cláusula SELECT, ahora puede
generar una tabla con la misma firma. Para hacer esto, presione
Alt + Intro -> Crear definición de tabla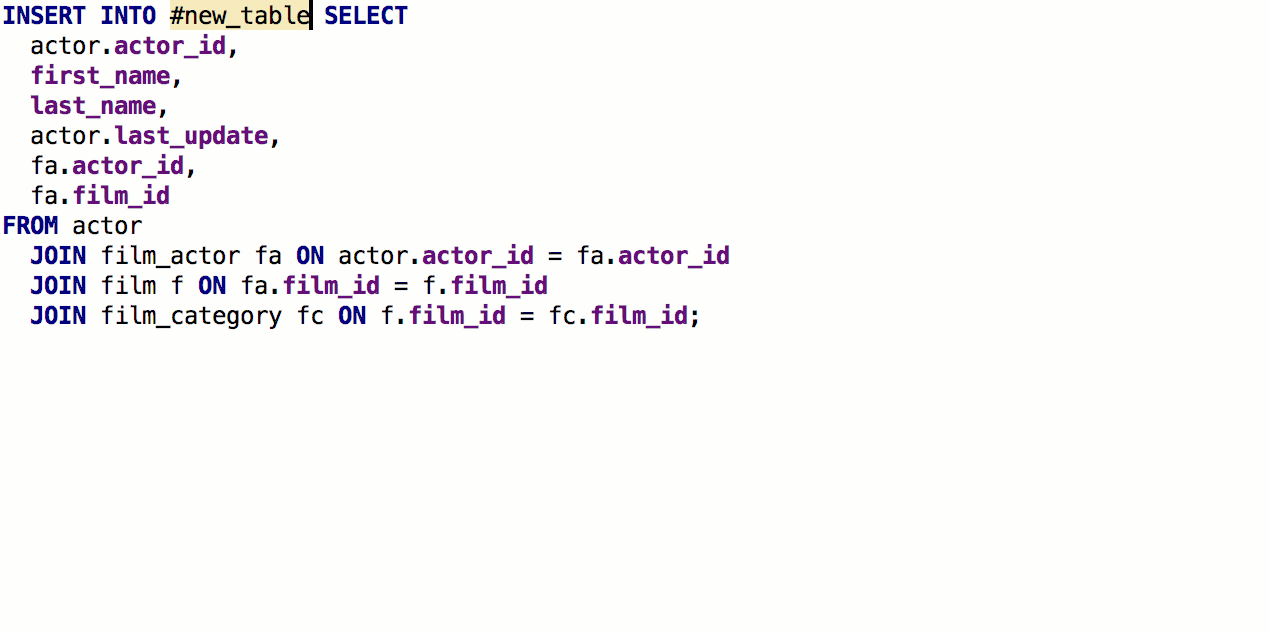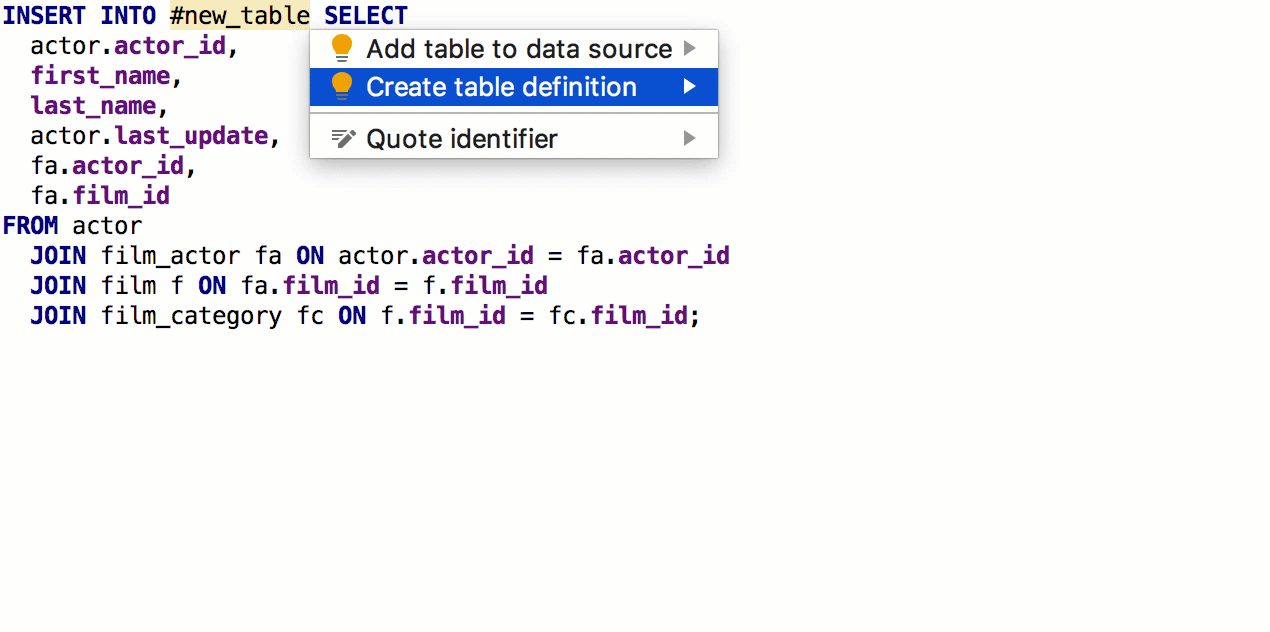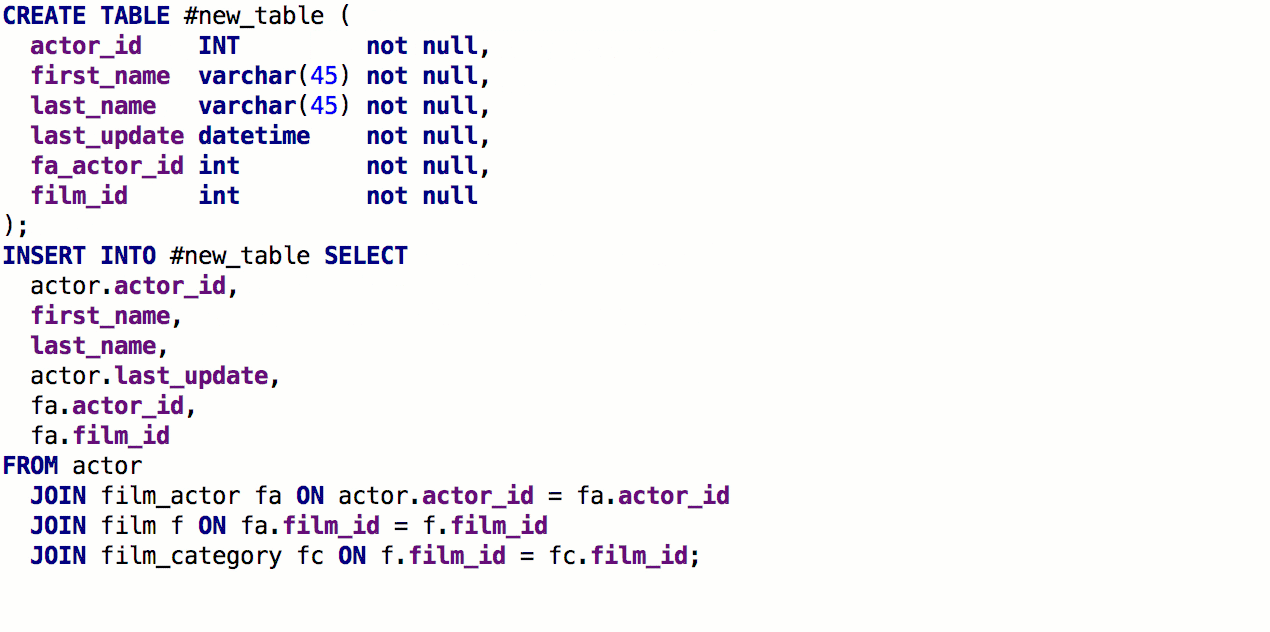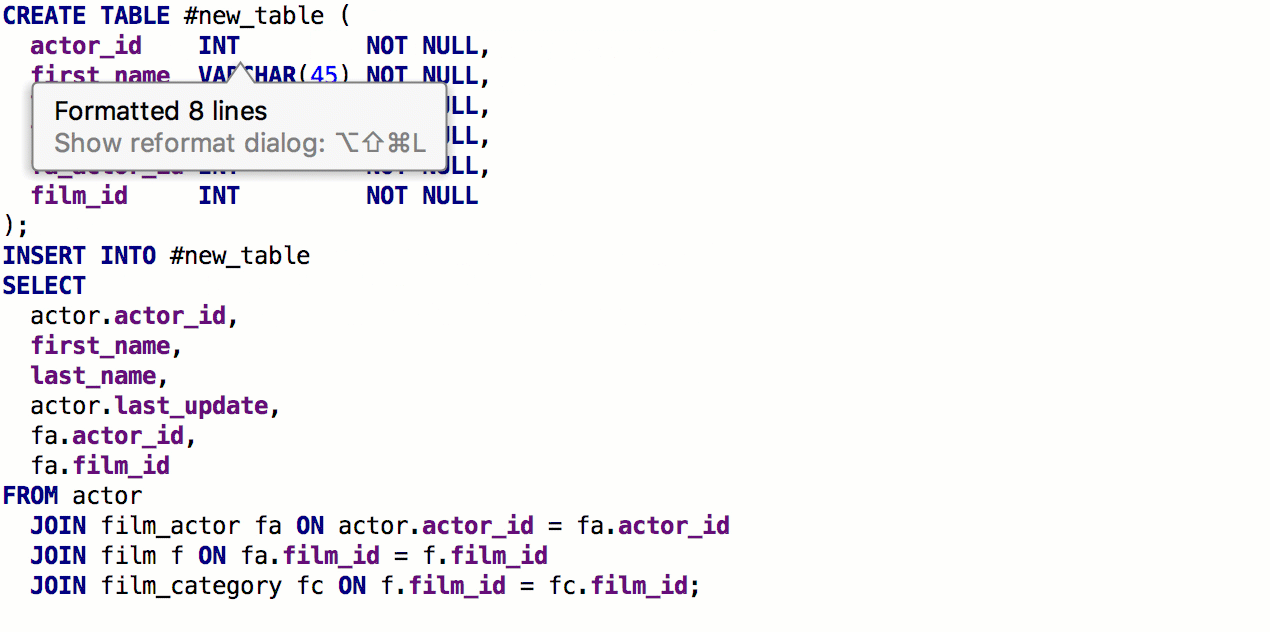
Y una pequeña solución para la plantilla
INS : la información sobre
herramientas para los nombres de columna se muestra automáticamente.

Análisis de código
Agregamos inspecciones sobre
ELIMINAR y
ACTUALIZAR inseguros : le advertiremos que perderá datos.


Y si corres, te aclararemos :)

Otra inspección encontrará las
columnas no utilizadas
de la subconsulta .
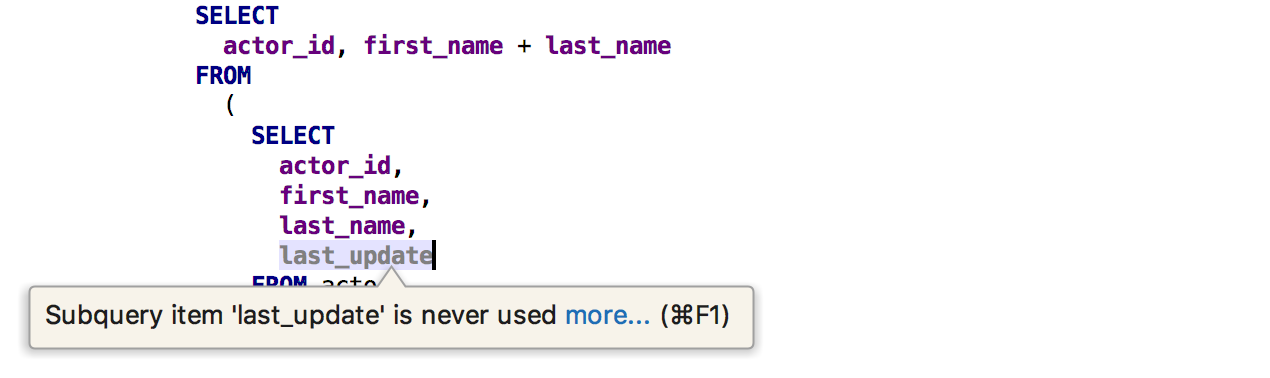
Y el otro es el
código no utilizado.
Objetos de base de datos
SQL Generator (
Ctrl / Cmd + Alt + G ) aprendió
a escribir los resultados en un archivo : para esto, haga clic en el botón
Guardar .
De manera predeterminada, hay dos métodos disponibles para organizar archivos, pero si necesita más, escriba los comentarios.
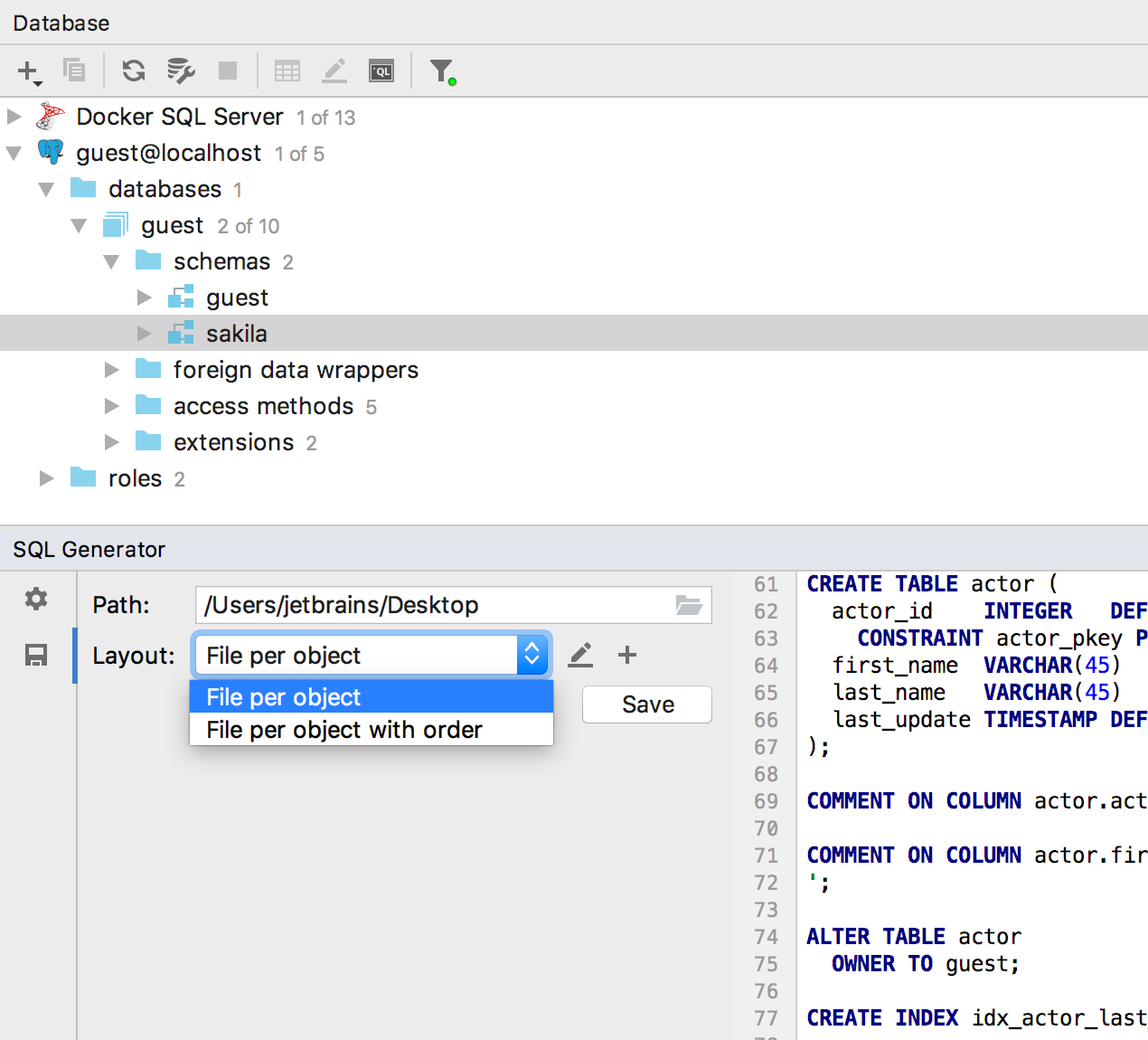
O en este momento, si hace clic en el lápiz de la derecha, puede editar los guiones correspondientes en Groovy. O crea el tuyo propio.
 Extensiones
Extensiones compatibles en PostgreSQL.
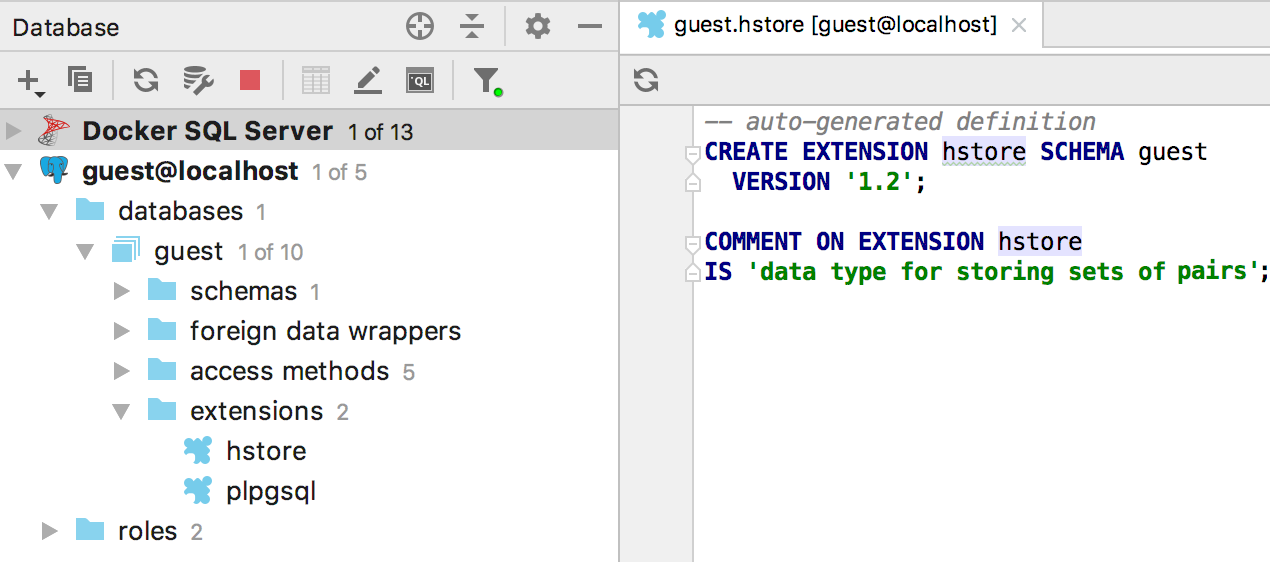
Mostramos
estadísticas en la ventana de información para la fuente de datos (Ctrl + Q para Windows / Linux, F1 para OSX), incluida la cantidad de objetos diferentes.
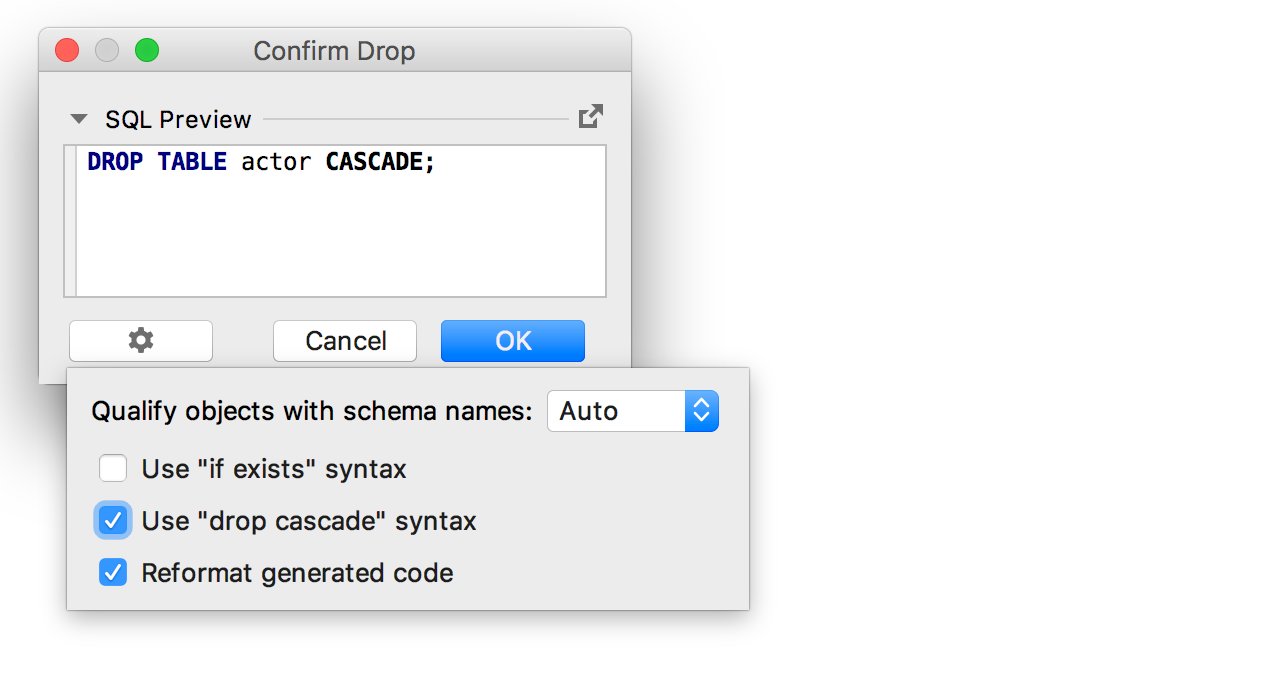
Y al generar código para eliminar el objeto,
se agregó la opción
' Usar sintaxis de caída en cascada ' .
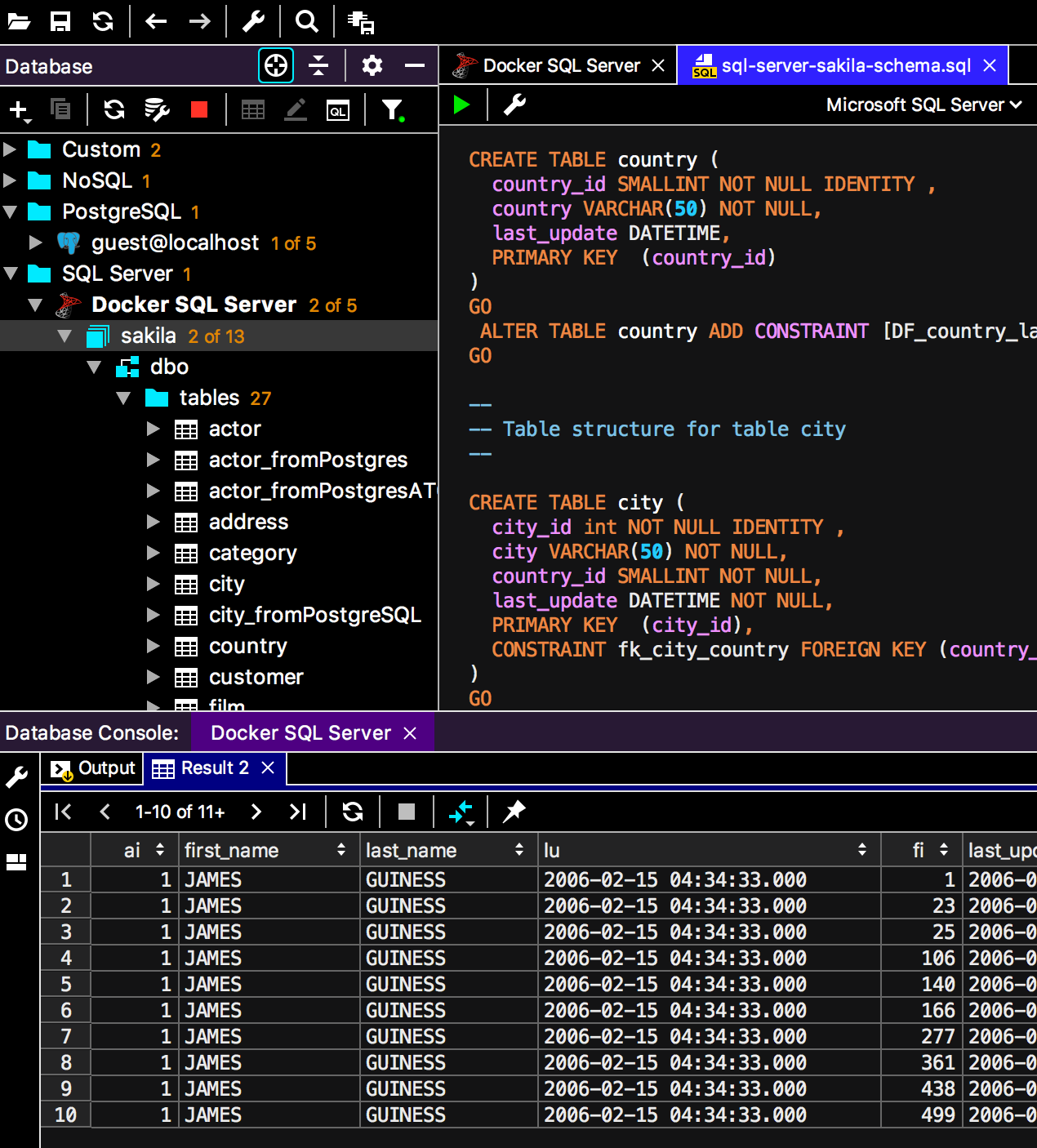
Conexión
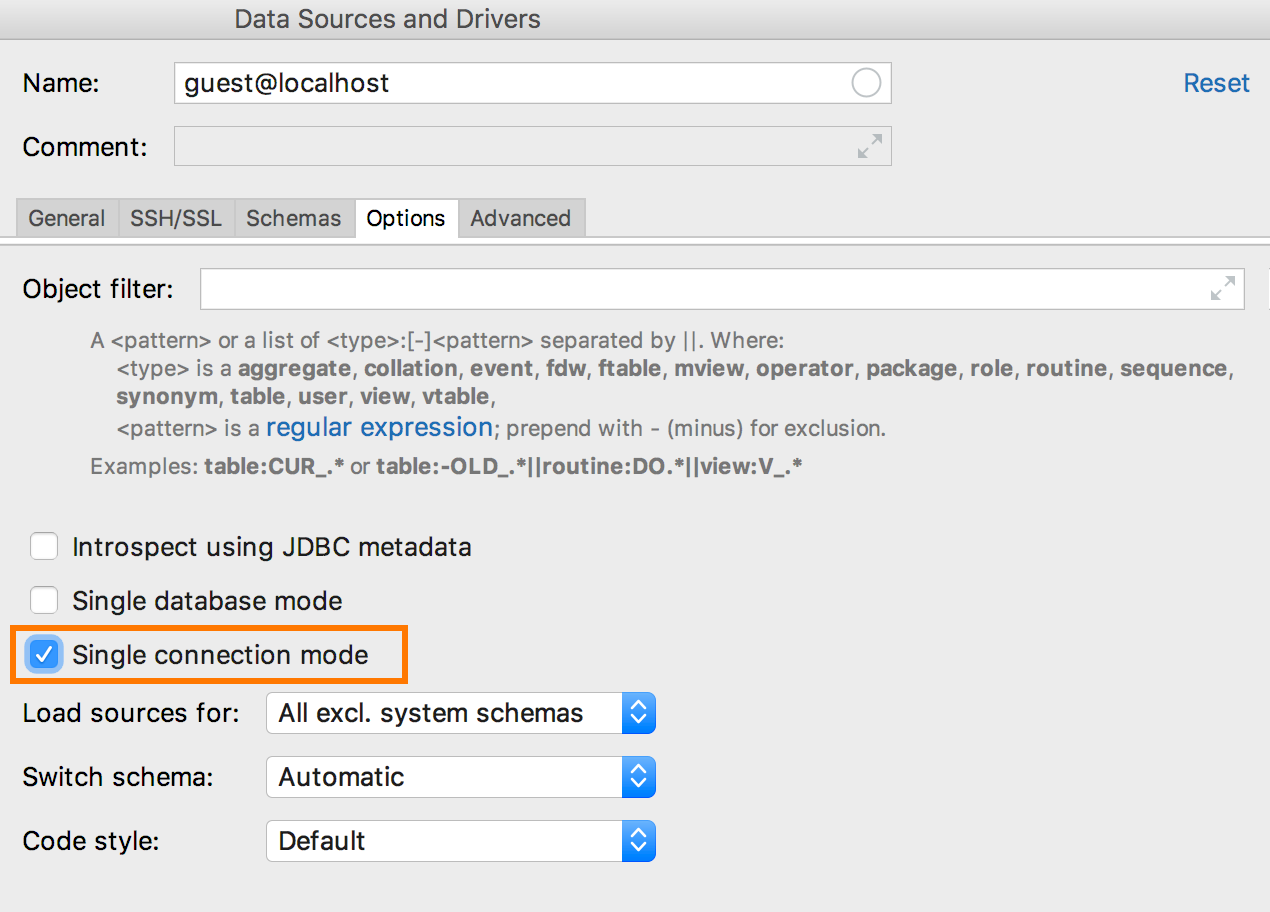
Antes de la versión actual, cada nueva consola significaba una nueva conexión. Otras cosas que no requerían que la consola también crearan conexiones separadas: ejecutar scripts, importar, una interfaz gráfica para crear tablas. En 2018.3, si habilita el
modo de conexión única en las propiedades de la fuente de datos, todo el trabajo con él se realizará a través de una conexión.
Como resultado, aparecerán objetos temporales en el árbol, y las consolas y los editores de datos funcionarán dentro de la misma transacción. Este es el primer paso para administrar completamente las conexiones que estamos a punto de abordar.
Y también lo hicieron para que el IDE se
vuelva a
conectar después del tiempo de inactividad.
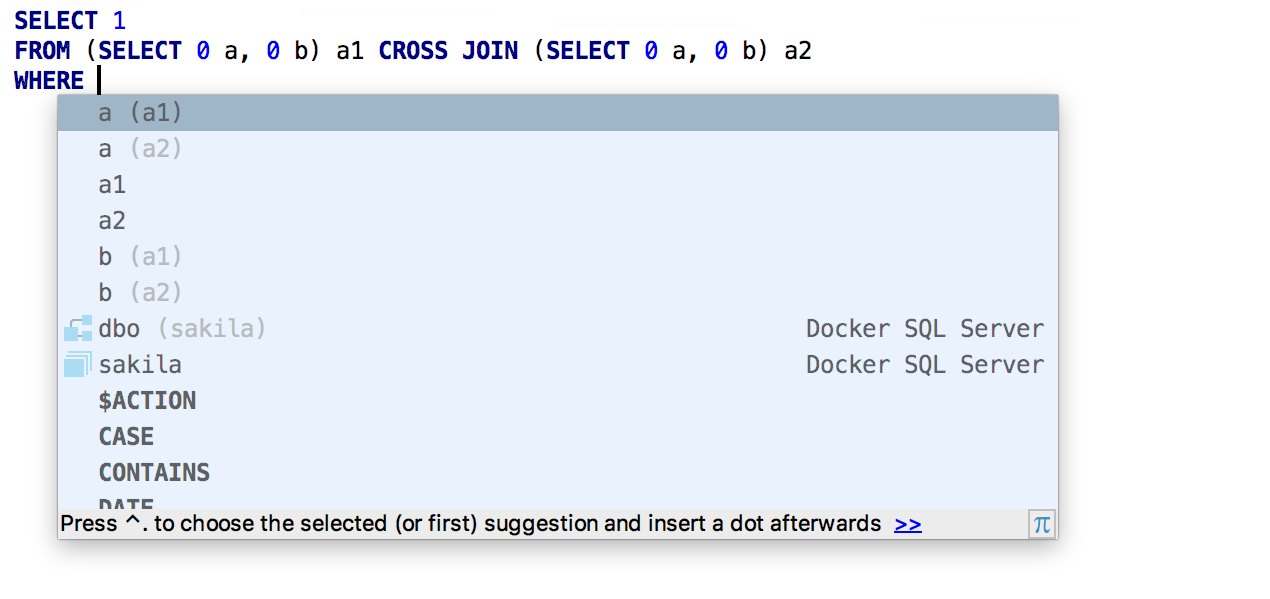
Búsqueda y navegación
La plataforma IntelliJ introdujo una
nueva búsqueda : combina diferentes tipos de búsquedas fragmentadas:
Buscar en todas partes ,
Buscar acción ,
Ir a la tabla / vista / procedimiento / ,
Ir al archivo e
Ir al símbolo . En DataGrip, la segunda pestaña se llama Tablas, y en otros IDE se llama Clases. Pero ella hace lo mismo: busca tanto los objetos de la base de datos como las clases. La tecla Tab alterna las pestañas.
No hemos cambiado seriamente los algoritmos de búsqueda: si de repente solía buscar algo bien, pero ahora se busca mal, escriba.
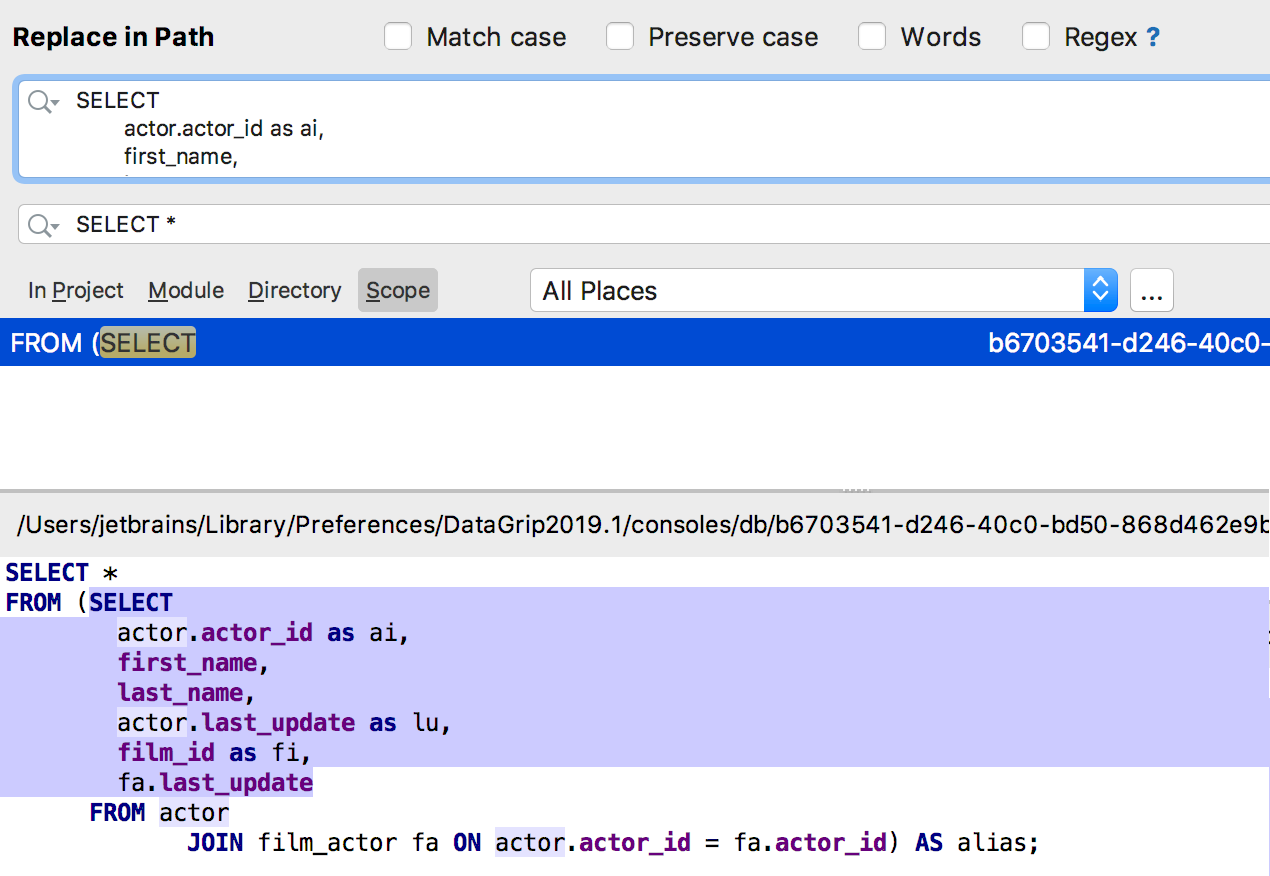
Ahora se pueden encontrar
varias líneas a la vez en "Buscar en ruta". Especialmente útil para SQL: la consulta se puede encontrar dentro del código fuente de los objetos.
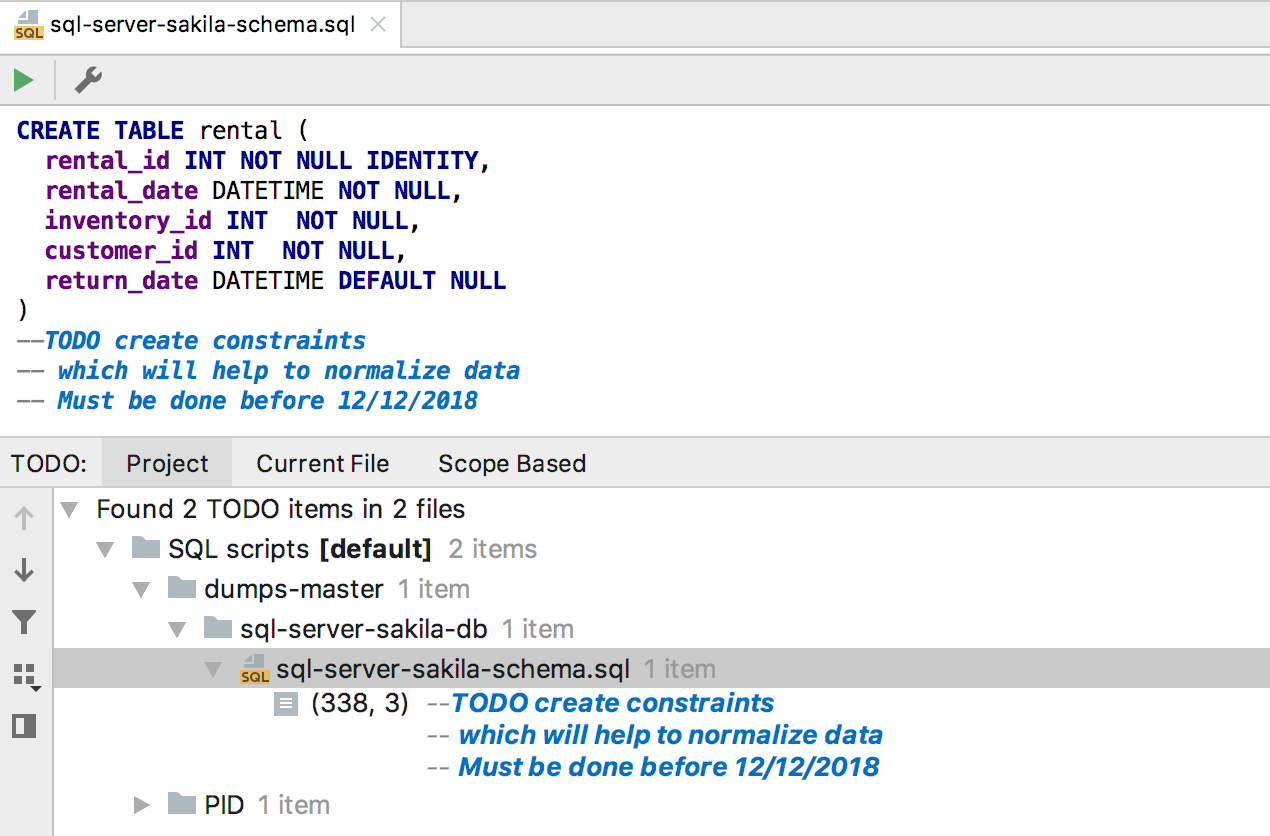
 TODO los comentarios
TODO los comentarios ahora pueden ser de varias líneas. Para captar las siguientes líneas en dicho comentario, sepárelas con un espacio del símbolo de comentario. Las tareas presentadas de esta manera se incluyen en la
ventana TODO Tool .
La imagen es más clara:
Interfaz
El nuevo esquema de color es muy contrastante.
Cambie esquemas como este: presione
Ctrl + `y seleccione Look and Feel.
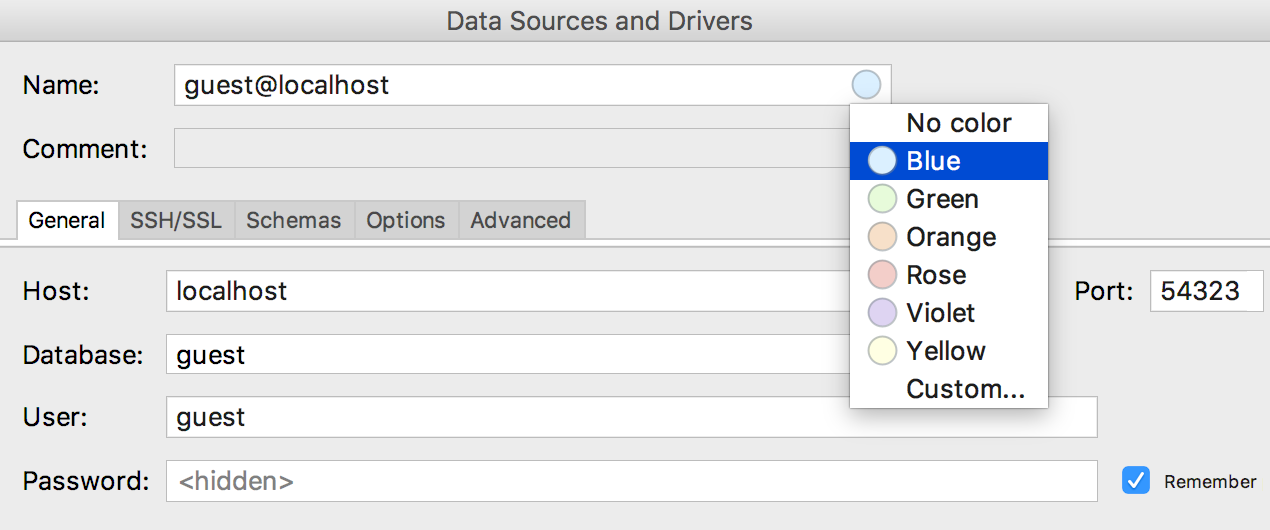
Aparece un menú para
seleccionar el color de la fuente de datos en su ventana de propiedades.
Y se agregó un poco de amabilidad al cuadro de selección de línea en la página. Anteriormente, para que el resultado mostrara todas las líneas, tenía que escribir -1 aquí :)
Ahora hay una casilla de verificación.

Eso es todo!
→
Más detalles aquí→
Descargar versión de prueba por un mes→ El
tweeter que leemos→ El
correo que leemos→
Rastreador de erroresEquipo DataGrip