Problema
Casi cualquier sistema de información requiere almacenamiento de datos de manera continua. En la mayoría de los sistemas con carga pequeña y mediana, esta función se realiza mediante DBMS relacionales, cuya ventaja indiscutible es la garantía de la coherencia de los datos.
Un ejemplo clásico que explica qué es la consistencia de los datos: la operación de transferir fondos de una cuenta a otra. En el momento en que la operación de cambiar el saldo de una cuenta ya se ha completado y la otra aún no ha tenido tiempo, puede ocurrir una falla. Luego, los fondos se debitarán de una cuenta, pero no se acreditarán a otra. Este estado de los datos del sistema se llama inconsistente y, tal vez, no hay necesidad de explicar qué consecuencias puede tener esto. Los DBMS relacionales proporcionan un mecanismo de transacción que garantiza la coherencia de los datos en cualquier momento. Una transacción es un conjunto finito de operaciones que transfiere un estado consistente a otro estado consistente.
En el caso de un error en cualquier paso, el DBMS cancela todas las operaciones realizadas anteriormente y devuelve los datos a su estado original acordado. En otras palabras, se realizarán todas las operaciones o no una sola.
En cuanto a los sistemas a gran escala, no siempre es posible utilizar una sola base de datos en ellos debido a una carga demasiado pesada. En tales casos, cada módulo del sistema (servicio) se proporciona con su propia base de datos separada. En este caso, surge la pregunta de cómo garantizar la coherencia de los datos para dicha arquitectura de clúster.
Resolviendo Consistencia de Datos
Una solución son las transacciones distribuidas. Primero, todos los nodos del clúster deben aceptar que la operación es posible, luego los cambios se confirman en todos los nodos. Dado que los nodos no tienen un dispositivo de almacenamiento común, la única forma de llegar a una opinión común es ponerse de acuerdo utilizando algún protocolo de consenso distribuido.
Un protocolo simple para capturar transacciones globales es el compromiso de dos fases (2PC). El nodo que realiza la transacción se considera el coordinador. En la fase de preparación (preparación), el coordinador informa a los otros nodos sobre el compromiso de la transacción y espera la confirmación de ellos de que están listos para comprometerse. Si al menos un nodo no está listo, la transacción se interrumpe. En la fase de confirmación, el coordinador informa a todos los nodos de la decisión de confirmar la transacción. Al recibir la confirmación de todos de que todo está bien, el coordinador también captura la transacción.

Figura 1 - Esquema general de una confirmación de dos fases
Este protocolo evita un mínimo de mensajes, pero no es robusto. Por ejemplo, si el coordinador falla después de la fase de preparación, los nodos restantes no tienen información sobre si la transacción debe confirmarse o cancelarse (tendrán que esperar a que se solucione la falla). Otro inconveniente grave de 2PC (y otros protocolos de transacciones distribuidas, por ejemplo 3PC) es que a medida que aumenta el número de nodos del clúster, disminuye el rendimiento de las confirmaciones de dos fases.

Figura 2 - Dependencia de la velocidad de una confirmación de dos bases en la cantidad de servidores en un clúster DBMS
Además, el enfoque de transacción distribuida impone una limitación: todos los módulos del sistema deben usar el mismo DBMS, lo que no siempre es conveniente.
Otra opción es proporcionar un mecanismo que le permita trabajar con diferentes bases de datos (para servicios) como una sola base de datos (para resolver el problema con la integridad de los datos en una base de datos distribuida). Al mismo tiempo, se requiere un cierto análogo de una transacción para un sistema distribuido ("transacción comercial").
En las transacciones ordinarias, así como en los compromisos de dos fases, todas las operaciones están controladas por el mecanismo de transacción (usando bloqueos), y esto se hace para proporcionar la capacidad de revertir cualquier operación (enfoque pesimista: consideramos que cualquier operación puede estar causando una falla). Este es el cuello de botella del sistema. Una alternativa es el llamado enfoque optimista: creemos que la mayoría de las operaciones se completan con éxito. También realizamos acciones adicionales ante el hecho de una falla. Es decir reduciendo costos para la mayoría de las operaciones, lo que lleva a una mayor productividad.
¿Qué es una saga y cómo funciona?
Una alternativa a las transacciones para la arquitectura de microservicios es Saga. Saga (saga) es un conjunto de pasos realizados por varios módulos del sistema (servicios); También se requiere el servicio de saga, que es responsable de la operación (transacción comercial) en su conjunto. Los pasos están vinculados a través de un gráfico de eventos. Una vez completada la saga, el sistema debe pasar de un estado acordado a otro (en caso de ejecución exitosa) o volver al estado acordado anterior (en caso de cancelación).
¿Cómo implementar tal devolución o reversión de una transacción comercial? Para hacer esto, la saga utiliza el mecanismo de cancelación de pasos (acciones compensatorias). Por ejemplo, uno de los pasos fue exitoso (por ejemplo, se agregó una entrada a la tabla de la base de datos del usuario), pero uno de los siguientes pasos falló y toda la saga debería cancelarse. Luego, el mismo servicio recibe un comando: cancelar la acción. Pero en el servicio DBMS, la transacción local ya se ha completado, se ha agregado el registro de usuario. Luego, para volver al estado anterior, el servicio debe realizar una acción compensatoria (en nuestro ejemplo, eliminar el registro). La cancelación de pasos permite que la atomicidad ("todo o nada") se implemente en el marco de la saga: todos los pasos se realizan o compensan.
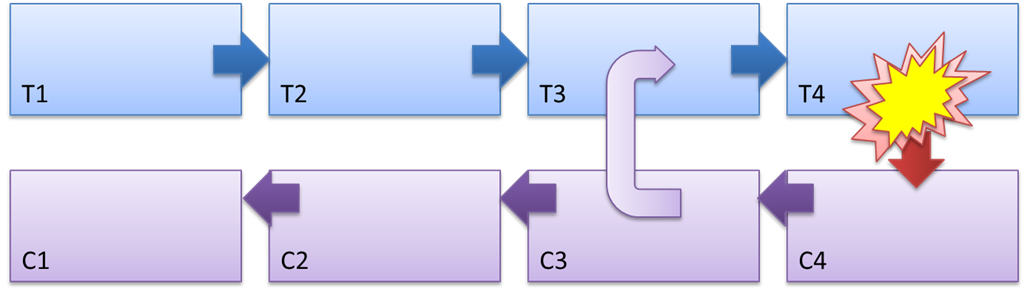
Figura 3 - El mecanismo de trabajo de Saga y la naturaleza del efecto compensatorio.
En la Figura 3, los pasos de la saga se designan como T1 ... T4, acciones de compensación: C1 ... C4.
Las sagas apoyan la idempotencia de los pasos (una acción cuya repetición repetida es equivalente a una sola). El enfoque de hundimiento brinda la oportunidad de repetir cualquier paso (por ejemplo, si no recibió una respuesta al completar con éxito). La idempotencia también le permite restaurar el estado cuando se pierden datos en cualquier nodo (falla y recuperación). Al realizar un paso, cada servicio debe determinar (mediante la clave de idempotencia) si ya realizó este paso o no (si no, ejecutar, de lo contrario omitir). Para acciones de compensación, también es posible agregar claves de idempotencia y repeticiones de operaciones (asegurando persistencia / estabilidad).
Resumen
De los cuatro requisitos para el sistema de transacción ACID (atomicidad, consistencia, aislamiento, estabilidad), el mecanismo de caída permite implementar tres, todos excepto el aislamiento. La falta de aislamiento puede conducir a anomalías ("lecturas sucias", "lecturas no repetibles", reescritura de cambios entre diferentes transacciones comerciales, etc.). Para superar tales situaciones, se requiere el uso de mecanismos adicionales, por ejemplo, el control de versiones de objetos mutables.
Las sagas te permiten resolver las siguientes tareas:
- Proporcionar cambios de datos dependientes para datos críticos del negocio;
- Ser capaz de establecer un estricto orden de pasos;
- Cumplir con un 100% de consistencia (coordinar datos incluso en caso de accidentes);
- Proporcione controles de rendimiento en todos los niveles.
Alcance y ejemplos de aplicación
Las sagas a menudo se usan en sistemas con una gran cantidad de solicitudes. Por ejemplo, servicios populares de correo electrónico, redes sociales. Sin embargo, el enfoque puede encontrar aplicación en proyectos de menor escala.
Nuestra empresa tiene experiencia en el desarrollo de un sistema de contabilidad para una gran empresa que fue diseñado para varias docenas de usuarios y todos los datos se almacenaron en un DBMS relacional. El problema surgió al implementar el cálculo automático del trabajo planificado: en algunos casos, los cálculos eran muy grandes y requerían la inserción de millones de registros en las tablas de DBMS, lo que cargaba significativamente el DBMS y ralentizaba el funcionamiento de todo el sistema.
Se encontró una solución: poner la lógica de cálculo del trabajo en un servicio separado con su propio DBMS para almacenar el trabajo en sí y los objetos relacionados. La consistencia de los datos fue asegurada por la saga. Si el cálculo falla, el módulo principal de la aplicación recibió un comando para cancelar la operación de cálculo lógico.
Bibliotecas habilitadas para saga
La aplicación fue desarrollada en .Net, y para esta tecnología hay varias bibliotecas de administrador de servicios con soporte para sagas. Observamos las bibliotecas NServiceBus, Mass Transit y Rebus. Como resultado, nos decidimos por Rebus: esta biblioteca es más fácil de aprender, a la vez que comprende el principio de las sagas y es de uso gratuito. NServiceBus y Mass transit son herramientas más sofisticadas con toneladas de características adicionales. No fueron necesarios como parte de nuestra tarea, pero puede ser aconsejable usarlos en proyectos futuros con una lógica más compleja.