Una de las funciones discretas pero importantes de
nuestros sitios de anuncios es guardar y mostrar el número de sus vistas. Nuestros sitios han estado viendo vistas de anuncios durante más de 10 años. La implementación técnica de la funcionalidad logró cambiar varias veces durante este tiempo, y ahora es un (micro) servicio en Go, trabajando con Redis como caché y cola de tareas, y con MongoDB como almacenamiento persistente. Hace unos años, aprendió a trabajar no solo con la suma de las vistas de anuncios, sino también con las estadísticas de cada día. Pero aprendió a hacer todo esto de manera muy rápida y confiable recientemente.

En total, el servicio procesa ~ 300 mil solicitudes de lectura y ~ 9 mil solicitudes de escritura por minuto, el 99% de las cuales se ejecutan hasta 5 ms. Estos, por supuesto, no son indicadores astronómicos ni el lanzamiento de cohetes en Marte, pero tampoco es una tarea tan trivial como podría parecer el simple almacenamiento de números. Resultó que hacer todo esto, garantizar el almacenamiento de datos sin pérdidas y leer valores consistentes y relevantes, requiere un poco de esfuerzo, que discutiremos a continuación.
Tareas del proyecto y descripción general
Aunque los contadores de vista no son tan críticos para el negocio como, por ejemplo, procesar pagos o
solicitudes de préstamo , son importantes ante todo para nuestros usuarios. La gente está fascinada al rastrear la popularidad de sus anuncios: algunos incluso llaman al soporte cuando notan información de visualización incorrecta (esto sucedió con una de las implementaciones de servicios anteriores). Además, almacenamos y mostramos estadísticas detalladas en las cuentas personales de los usuarios (por ejemplo, para evaluar la efectividad del uso de los servicios pagos). Todo esto nos hace cuidar guardar cada evento de visualización y mostrar los valores más relevantes.
En general, la funcionalidad y los principios del proyecto se ven así:
- La página web o la pantalla de la aplicación realiza una solicitud detrás de los contadores de visualización de anuncios (la solicitud suele ser asíncrona para priorizar la salida de información básica). Y si se muestra la página del anuncio, el cliente le pedirá que aumente y devuelva la cantidad actualizada de visitas.
- Al procesar solicitudes de lectura, el servicio intenta obtener información del caché de Redis y complementa lo desconocido al completar una solicitud a MongoDB.
- Las solicitudes de escritura se envían a 2 estructuras en el rábano: la cola de actualización incremental (procesada en segundo plano, de forma asíncrona) y el caché del número total de vistas.
- Un proceso en segundo plano en el mismo servicio lee elementos de la cola, los acumula en el búfer local y lo escribe periódicamente en MongoDB.
Contadores de vista de registros: trampas
Aunque los pasos descritos anteriormente parecen bastante simples, el problema aquí es la organización de la interacción entre la base de datos y las instancias de microservicio para que los datos no se pierdan, no se dupliquen y no se retrasen.
El uso de un solo repositorio (por ejemplo, solo MongoDB) resolvería algunos de estos problemas. De hecho, el servicio solía funcionar antes, hasta que nos topamos con los problemas de escala, estabilidad y velocidad.
Una implementación ingenua de mover datos entre almacenes podría conducir, por ejemplo, a tales anomalías:
- Pérdida de datos durante la escritura competitiva en caché:
- El proceso A aumenta el recuento de vistas en la memoria caché de Redis, pero descubre que todavía no hay datos para esta entidad (puede ser una declaración nueva o una antigua que se ha sacado de la memoria caché), por lo que el proceso primero debe obtener este valor de MongoDB.
- El proceso A obtiene el recuento de vistas de MongoDB, por ejemplo, el número 5; luego agrega 1 y va a escribir en Redis 6 .
- El proceso B (iniciado, por ejemplo, por otro usuario del sitio que también ha ingresado el mismo anuncio) simultáneamente hace lo mismo.
- El proceso A escribe un valor de 6 en Redis.
- El proceso B escribe un valor de 6 en Redis.
- Como resultado, se pierde una vista debido a la carrera al grabar datos.
El escenario no es tan improbable: por ejemplo, tenemos un servicio pago que coloca un anuncio en la página principal del sitio. Para un nuevo anuncio, tal curso de eventos puede conducir a la pérdida de muchas vistas a la vez debido a su repentino influjo.
- Un ejemplo de otro escenario es la pérdida de datos al mover vistas de Redis a MongoDb:
- El proceso recoge un valor pendiente de Redis y lo almacena en la memoria para luego escribirlo en MongoDB.
- Una solicitud de escritura falla (o el proceso se bloquea antes de ejecutarse).
- Los datos se pierden nuevamente, lo que se hará evidente la próxima vez que el valor almacenado en caché se elimine y se reemplace con el valor de la base de datos.
Pueden ocurrir otros errores, las razones por las cuales también se encuentran en la naturaleza no atómica de las operaciones entre bases de datos, por ejemplo, un conflicto al eliminar y aumentar las vistas de la misma entidad.
Grabación de recuentos de vistas: solución
Nuestro enfoque para almacenar y procesar datos en este proyecto se basa en la expectativa de que, en cualquier momento, MongoDB puede fallar más que Redis. Esto, por supuesto, no es una
regla absoluta, al menos no para cada proyecto, pero en nuestro entorno estamos realmente acostumbrados a observar tiempos de espera periódicos para consultas en MongoDB causadas por el rendimiento de las operaciones de disco, que anteriormente era una de las razones de la pérdida de algunos eventos.
Para evitar muchos de los problemas mencionados anteriormente, utilizamos colas de tareas para guardar diferido y scripts de lua, que permiten cambiar atómicamente los datos en varias estructuras de rábano a la vez. Con esto en mente, los detalles para guardar vistas son los siguientes:
- Cuando una solicitud de escritura cae en el microservicio, ejecuta el script lua IncrementIfExists para aumentar el contador solo si ya existe en el caché. El script devuelve inmediatamente -1 si no hay datos para la entidad que se está viendo en el rábano; de lo contrario, aumenta el valor de las vistas en el caché a través de HINCRBY , agrega el evento a la cola para su posterior almacenamiento en MongoDB (llamado cola pendiente por nosotros) a través de LPUSH , y devuelve la cantidad actualizada de vistas.
- Si IncrementIfExists devuelve un número positivo, este valor se devuelve al cliente y la solicitud finaliza.
De lo contrario, el microservicio recoge el contador de vista de MongoDb, lo incrementa en 1 y lo envía al rábano.
- La escritura en el rábano se realiza a través de otro script lua, Upsert , que guarda el número total de vistas en el caché si todavía está vacío, o las aumenta en 1 si alguien más logró llenar el caché entre los pasos 1 y 3.
- Upsert también agrega un evento de vista a la cola pendiente y devuelve una cantidad actualizada, que luego se envía al cliente.
Debido al hecho de que los scripts lua
se ejecutan atómicamente , evitamos muchos problemas potenciales que podrían ser causados por una escritura competitiva.
Otro detalle importante es garantizar la transferencia segura de actualizaciones de la cola pendiente a MongoDB. Para hacer esto, utilizamos la plantilla de "cola confiable" descrita en la
documentación de Redis , que reduce significativamente las posibilidades de pérdida de datos al crear una copia de los elementos procesados en una cola separada, otra hasta que finalmente se almacenan en un almacenamiento persistente.
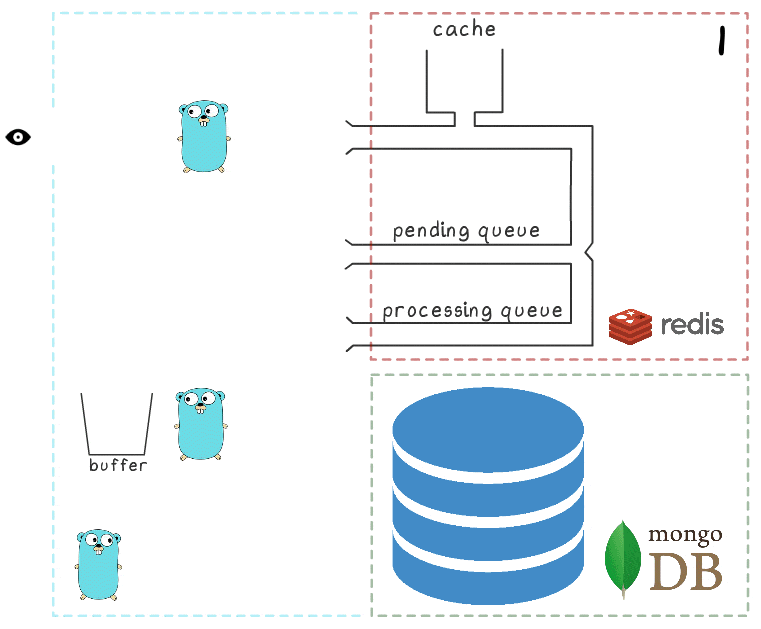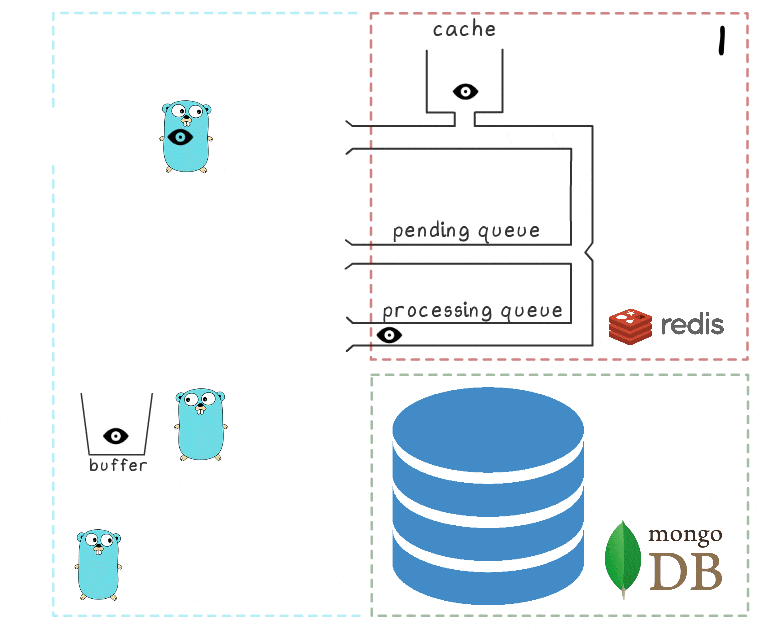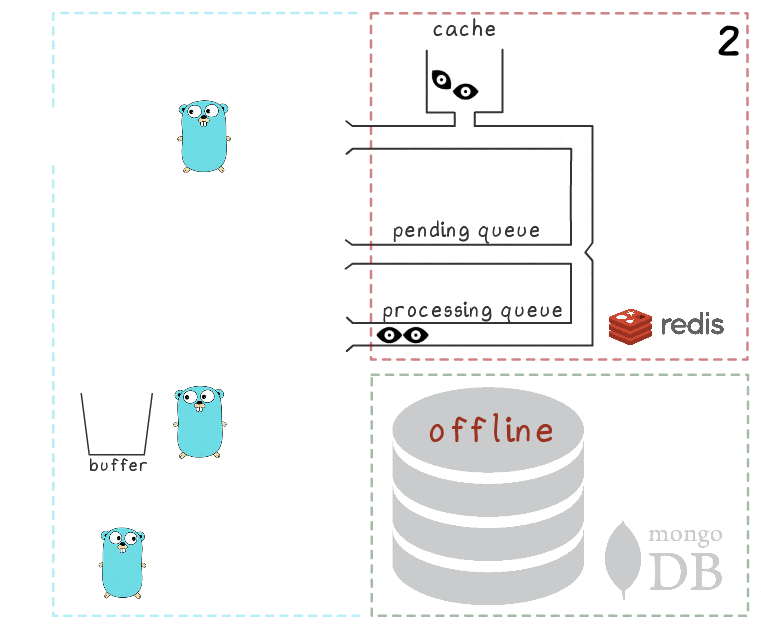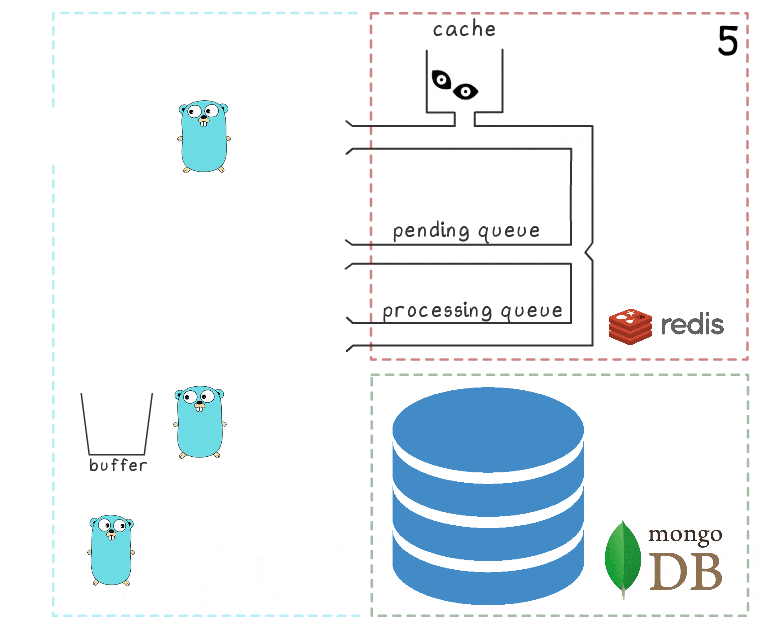
Para comprender mejor todos los pasos del proceso, hemos preparado una pequeña visualización. Primero, veamos un escenario normal y exitoso (los pasos están numerados en la esquina superior derecha y se describen en detalle a continuación):
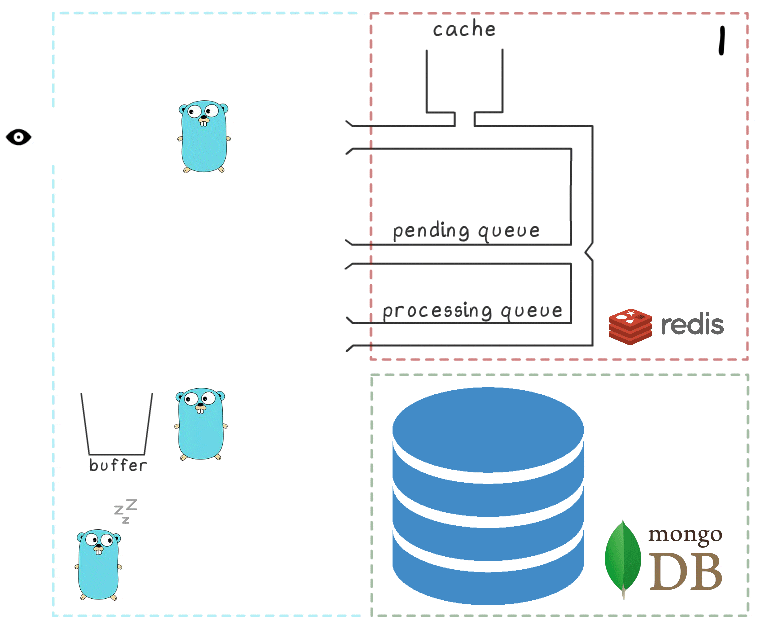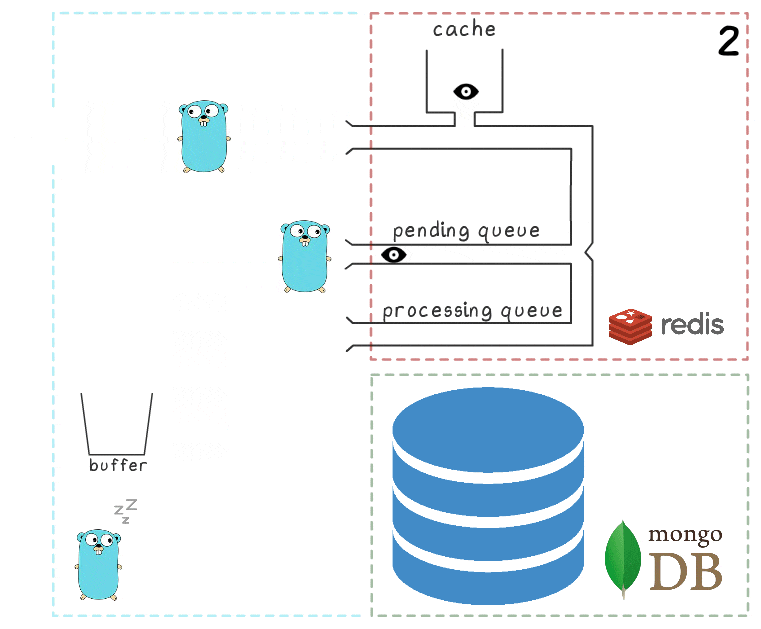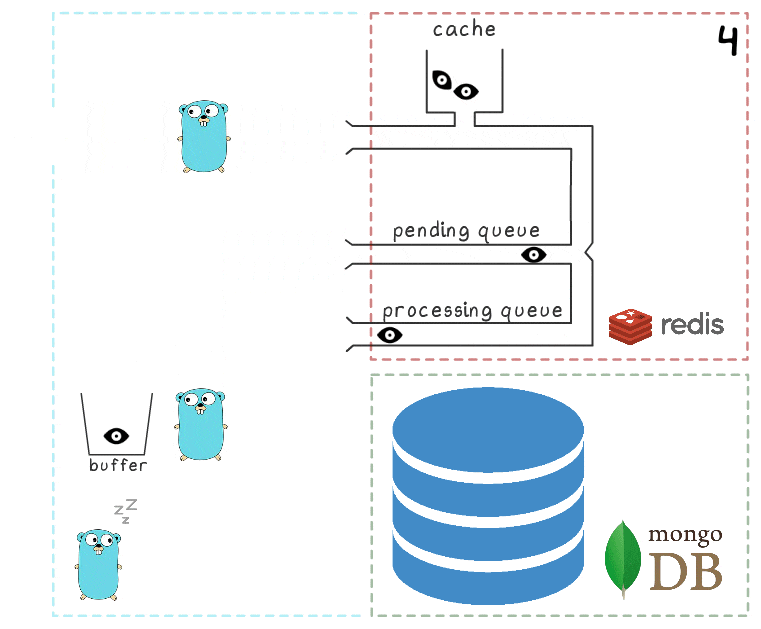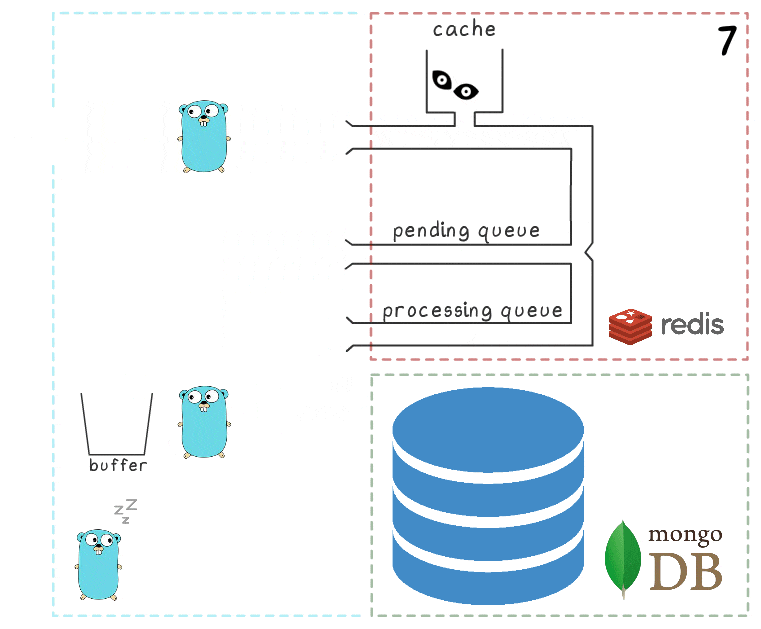
- El microservicio recibe una solicitud de escritura
- El controlador de solicitudes lo pasa a un script lua que escribe la búsqueda en el caché (de inmediato, lo hace legible) y en la cola para su posterior procesamiento.
- La rutina de fondo (periódicamente) realiza la operación BRPopLPush , que mueve atómicamente un elemento de una cola a otra (lo llamamos "cola de procesamiento", una cola con elementos procesados actualmente). El mismo elemento se almacena en un búfer en la memoria del proceso.
- Llega otra solicitud de escritura y se está procesando, lo que nos deja con 2 elementos en el búfer y 2 elementos en la cola de procesamiento.
- Después de un tiempo de espera, el proceso en segundo plano decide vaciar el búfer en MongoDB. La escritura de múltiples valores desde el búfer se realiza mediante una sola solicitud, que afecta positivamente el rendimiento. Además, antes de grabar, el proceso intenta combinar varias vistas en una, resumiendo sus valores para los mismos anuncios.
En cada uno de nuestros proyectos, se utilizan 3 instancias de microservicio, cada una con su propio búfer, que se guarda en la base de datos cada 2 segundos. Durante este tiempo, se acumulan aproximadamente 100 elementos en un búfer.
- Después de una escritura exitosa, el proceso elimina elementos de la cola de procesamiento, lo que indica que el procesamiento se ha completado con éxito.
Cuando todos los subsistemas están en orden, algunos de estos pasos pueden parecer redundantes. Y el lector atento también puede tener una pregunta sobre qué hace el gopher que duerme en la esquina inferior izquierda.
Todo se explica al considerar el escenario cuando MongoDB no está disponible:
- El primer paso es idéntico a los eventos del escenario anterior: el servicio recibe 2 solicitudes para registrar vistas y las procesa.
- El proceso pierde conexión con MongoDB (el proceso en sí mismo, por supuesto, aún no sabe sobre esto).
El controlador Gorutin, como antes, está tratando de vaciar su búfer en la base de datos, pero esta vez sin éxito. Ella vuelve a esperar la próxima iteración.
- Otra rutina de fondo se despierta y verifica la cola de procesamiento. Ella descubre que los elementos se le agregaron hace mucho tiempo; concluyendo que su procesamiento falló, ella los mueve nuevamente a la cola pendiente.
- Después de un tiempo, se restablece la conexión con MongoDB.
- La primera rutina de fondo intenta nuevamente realizar una operación de escritura, esta vez con éxito, y finalmente elimina de forma permanente los elementos de la cola de procesamiento.
En este esquema, hay varios tiempos de espera importantes y heurísticas derivadas de las pruebas y el sentido común: por ejemplo, los elementos se mueven de la cola de procesamiento a la cola pendiente después de 15 minutos de inactividad. Además, la gorutina responsable de esta tarea realiza un
bloqueo antes de la ejecución para que varias instancias del microservicio no intenten restaurar las vistas "congeladas" al mismo tiempo.
Estrictamente hablando, incluso estas medidas no proporcionan garantías teóricamente fundamentadas (por ejemplo, ignoramos escenarios como el proceso se congela durante 15 minutos), pero en la práctica funciona de manera bastante confiable.
También en este esquema hay al menos 2 vulnerabilidades más que conocemos que es importante tener en cuenta:
- Si el microservicio se bloqueó inmediatamente después de guardar con éxito en MongoDb, pero antes de borrar la lista de la cola de procesamiento, estos datos se considerarán no guardados y, después de 15 minutos, se guardarán nuevamente.
Para reducir la probabilidad de tal escenario, hemos proporcionado repetidos intentos de eliminar de la cola de procesamiento en caso de errores. En realidad, aún no hemos observado tales casos en producción.
- Al reiniciar, el rábano puede perder no solo el caché, sino también algunas vistas no guardadas de las colas, ya que está configurado para guardar periódicamente instantáneas RDB cada pocos minutos.
Aunque en teoría esto puede ser un problema grave (especialmente si el proyecto trata con datos realmente críticos), en la práctica los nodos se reinician extremadamente raramente. Al mismo tiempo, según la supervisión, los elementos pasan en colas durante menos de 3 segundos, es decir, la posible cantidad de pérdidas es muy limitada.
Puede parecer que hay más problemas de los que quisiéramos. Sin embargo, de hecho, resulta que el escenario desde el cual defendimos inicialmente, el fracaso de MongoDB, es de hecho una amenaza mucho más real, y el nuevo esquema de procesamiento de datos garantiza con éxito la disponibilidad del servicio y evita pérdidas.
Un vívido ejemplo de esto fue cuando la instancia de MongoDB en uno de los proyectos estuvo absurdamente inaccesible toda la noche. Todo este tiempo, los recuentos de vistas acumulados y rotados en un rábano de una cola a otra, hasta que finalmente se guardaron en la base de datos después de resolver el incidente; la mayoría de los usuarios ni siquiera notaron la falla.
La vista de lectura cuenta
Las solicitudes de lectura son mucho más simples que las solicitudes de escritura: el microservicio primero verifica el caché en el rábano; todo lo que no se encuentra en el caché se rellena con datos de MongoDb y se devuelve al cliente.
No hay escritura de extremo a extremo en la memoria caché durante las operaciones de lectura para evitar la sobrecarga de protección contra escrituras competitivas. La tasa de aciertos del caché sigue siendo buena, ya que la mayoría de las veces ya se calentará gracias a otras solicitudes de escritura.
Las estadísticas de la vista diaria se leen directamente desde MongoDB, ya que se solicitan con mucha menos frecuencia y es más difícil almacenar en caché. También significa que cuando la base de datos no está disponible, la lectura de estadísticas deja de funcionar; pero afecta solo a una pequeña parte de los usuarios.
Esquema de almacenamiento de datos MongoDB
El esquema de recopilación de MongoDB para el proyecto se basa en
estas recomendaciones de los propios desarrolladores de bases de datos , y se ve así:
- Las vistas se guardan en 2 colecciones: en una hay su cantidad total, en la otra: estadísticas por día.
- Los datos en la recopilación de estadísticas se organizan en base a un documento por anuncio por mes . Para nuevos anuncios, se inserta en la colección un documento lleno de treinta y un cero para el mes actual; De acuerdo con el artículo mencionado anteriormente, esto le permite asignar inmediatamente suficiente espacio para un documento en el disco para que la base de datos no tenga que moverlo al agregar datos.
Este elemento hace que el proceso de lectura de estadísticas sea un poco incómodo (las solicitudes deben generarse por meses en el lado del microservicio), pero en general el esquema sigue siendo bastante intuitivo.
- La operación upsert se utiliza para grabar, para actualizar y, si es necesario, crear un documento para la entidad deseada dentro de la misma solicitud.
No estamos utilizando las capacidades transaccionales de MongoDb para actualizar varias colecciones al mismo tiempo, lo que significa que corremos el riesgo de que los datos se puedan escribir en una sola colección. Por el momento, simplemente iniciamos sesión en tales casos; Hay pocos, y hasta ahora esto no presenta el mismo problema significativo que otros escenarios.
Prueba
No confiaría en mis propias palabras de que los escenarios descritos realmente funcionan si no estuvieran cubiertos por las pruebas.
Como la mayor parte del código del proyecto funciona estrechamente con rábanos y MongoDb, la mayoría de las pruebas en él son pruebas de integración. El entorno de prueba es compatible con Docker-compose, lo que significa que se puede implementar rápidamente, proporciona reproducibilidad al restablecer y restaurar el estado en cada inicio, y hace posible experimentar sin afectar las bases de datos de otras personas.
En este proyecto, hay 3 áreas principales de prueba:
- Validación de la lógica de negocios en escenarios típicos, los llamados camino feliz Estas pruebas responden a la pregunta: cuando todos los subsistemas están en orden, ¿funciona el servicio de acuerdo con los requisitos funcionales?
- Verificación de escenarios negativos en los que se espera que el servicio continúe su trabajo. Por ejemplo, ¿el servicio realmente no pierde datos cuando MongoDb falla?
¿Estamos seguros de que la información sigue siendo coherente con los tiempos de espera periódicos, las congelaciones y las operaciones de grabación competitivas? - Verificación de escenarios negativos en los que no esperamos que el servicio continúe, pero aún se debe proporcionar un nivel mínimo de funcionalidad. Por ejemplo, no hay posibilidad de que el servicio continúe guardando y devolviendo datos cuando ni el rábano ni el mongo están disponibles, pero queremos asegurarnos de que en tales casos no se bloquee, sino que espere la recuperación del sistema y luego vuelva a funcionar.
Para verificar escenarios sin éxito, el código de lógica de negocios del servicio funciona con las interfaces de cliente de la base de datos, que en las pruebas necesarias se reemplazan con implementaciones que devuelven errores y / o simulan retrasos en la red. También simulamos la operación paralela de varias instancias de servicio utilizando el patrón "
objeto de entorno ". Esta es una variante del conocido enfoque de "inversión de control", donde las funciones no acceden a las dependencias en sí mismas, sino que las reciben a través del objeto de entorno que se pasa en los argumentos. Entre otras ventajas, el enfoque le permite simular varias copias independientes del servicio en una prueba, cada una de las cuales tiene su propio grupo de conexiones a la base de datos y reproduce de manera más o menos eficiente el entorno de producción. Algunas pruebas ejecutan cada una de esas instancias en paralelo y se aseguran de que todas vean los mismos datos y de que no haya condiciones de carrera.
También realizamos una prueba de esfuerzo rudimentaria, pero aún bastante útil, basada en
asedio , que ayudó aproximadamente a estimar la carga permitida y la velocidad de respuesta del servicio.
Sobre el rendimiento
Para el 90% de las solicitudes, el tiempo de procesamiento es muy pequeño y, lo más importante, estable; Aquí hay un ejemplo de mediciones en uno de los proyectos durante varios días:
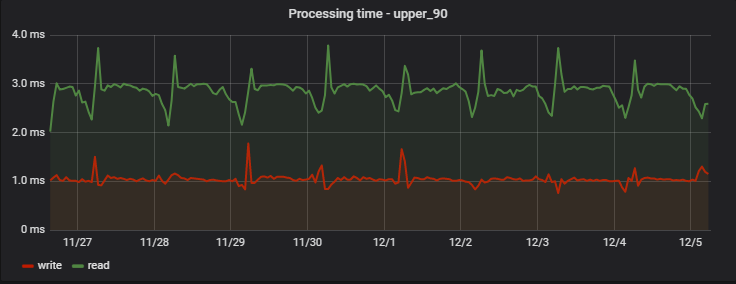
Curiosamente, un registro (que en realidad es una operación de escritura + lectura, porque devuelve valores actualizados) es ligeramente más rápido que la lectura (pero solo desde el punto de vista de un cliente que no observa la escritura pendiente real).
Un aumento regular de las demoras en la mañana es un efecto secundario del trabajo de nuestro equipo de análisis, que recopila sus propias estadísticas diariamente en función de los datos del servicio, creando una "gran carga artificial" para nosotros.
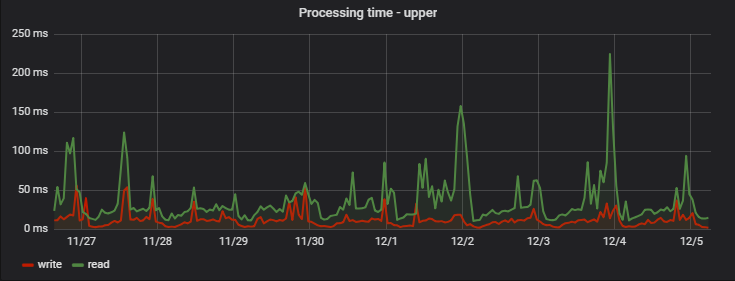
: ( — MongoDB), ( ), :
Conclusión
, - , , Redis .
, 95% , . , . 5.
Go, Redis MongoDB . , . , — .