Recientemente, Yegor Budnikov, analista de sistemas del departamento de tecnología de ABBYY, habló en Yandex en la conferencia
Data & Science: Law and Records Management . Contó cómo funciona la visión por computadora, el procesamiento de texto, a qué es importante prestar atención al extraer información de documentos legales y mucho más.
- Una empresa puede haber desarrollado metodologías para el análisis de datos y la gestión electrónica de documentos, mientras que los documentos creados en Word pueden provenir de clientes o de departamentos vecinos, impresos, fotocopiados, escaneados y llevados a una unidad flash.
¿Qué hacer con el flujo de documentos, que es ahora, con documentos "sucios", con almacenamiento de papel, hasta el hecho de que los documentos pueden almacenarse hasta 70 años antes de ser escaneados y deben reconocerse?
ABBYY está desarrollando tecnologías de inteligencia artificial para tareas comerciales. La inteligencia artificial debería ser capaz de hacer aproximadamente lo mismo que hace una persona en las actividades cotidianas o profesionales, a saber: leer información sobre el mundo real a partir de una imagen o una secuencia de imágenes. Esto puede ser no solo visión artificial, sino también audición o reconocimiento de datos de sensores, por ejemplo, de sensores de humo o temperatura. Además, los datos de estos sensores ingresan al sistema y deben participar en la decisión. Para implementar con éxito esta función, el sistema debe evitar errores lógicos estúpidos, como en la imagen:

Los textos son difíciles de analizar: la diversidad y el desarrollo del lenguaje los hace hermosos y expresivos, pero esto complica la tarea de su procesamiento automático. Por lo general, la ambigüedad de las palabras se ve superada por el hecho de que podemos determinar por el contexto lo que significa una palabra en particular, pero a veces el contexto deja espacio para la interpretación. En la frase "
Estos tipos de acero están en stock " es imposible de entender con absoluta precisión en términos de contexto: si son las personas en la sala las que almuerzan, o estos son algunos tipos de acero que se almacenan en el almacén. Para resolver esta ambigüedad, se necesita un contexto más amplio.
La parte inferior del collage es un fotograma de la película "Operación" Y "y otras aventuras de Shurik".En el caso general, la inteligencia artificial o un robot inteligente debe poder moverse en el espacio e interactuar con éxito con los objetos, por ejemplo, levantar la caja una y otra vez, que el instructor le quita de las manos.
Finalmente, la inteligencia general y la representación del conocimiento: el conocimiento difiere de la información en que sus partes interactúan activamente entre sí, generando nuevo conocimiento. Para resolver eficazmente el problema de mezclar cócteles, puede seguir el camino simple: enumere los ingredientes e indique en qué orden mezclarlos. En este caso, el sistema no podrá responder preguntas arbitrarias sobre el tema de su interés. Por ejemplo, qué sucede si reemplaza el jugo de tomate con piña. Para que el sistema domine el material más profundamente, bases de datos, taxonomías (árboles conceptuales relacionados lógicamente entre sí), se debe agregar un procedimiento de inferencia lógica. En este caso, realmente podemos decir que el sistema comprende lo que está haciendo y podrá responder una pregunta arbitraria sobre el proceso.
La inteligencia artificial desarrollada por ABBYY procesa documentos, es decir, convierte el papel, el escaneo y los medios electrónicos en información estructurada extraída de estos documentos. Detengámonos en dos componentes, como la visión por computadora y el procesamiento de textos. La visión por computadora le permite convertir PDF, imágenes escaneadas, imágenes en formatos de texto editables. ¿Por qué es una tarea difícil? En primer lugar, los documentos pueden tener una estructura arbitraria.
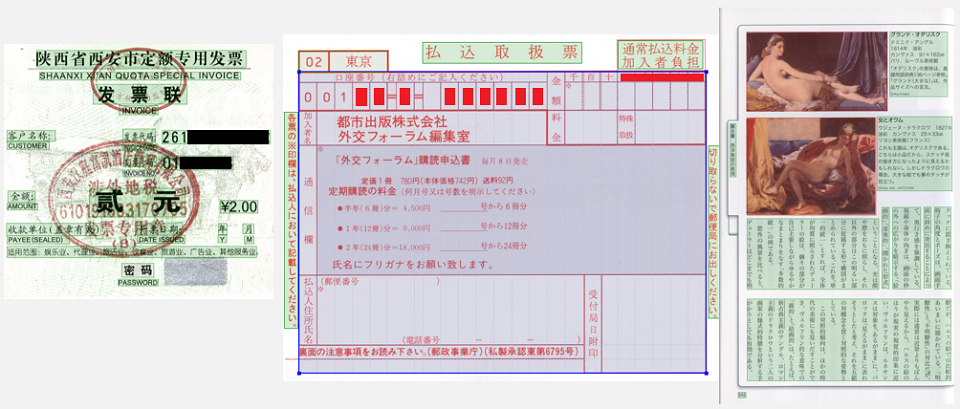
Esto significa que primero debe resolver el problema del análisis estructural de los documentos: comprender dónde se encuentran los bloques de texto, imágenes, tablas y listas, y luego determinar cómo interactúan entre sí. En segundo lugar, los documentos pueden estar en diferentes idiomas. Esto significa que es necesario apoyar la detección de diferentes tipos de escritura y la capacidad de reconocer palabras y caracteres que pueden ser muy diferentes entre sí. En tercer lugar, nos llegan imágenes del mundo real, lo que significa que les puede pasar cualquier cosa. Pueden distorsionarse, fotografiarse con una perspectiva incorrecta, pueden tener manchas de café, rayas de la impresora y luego del escáner. Todo esto debe ser gestionado de alguna manera para extraer información posteriormente.
¿Cómo funciona el reconocimiento de imágenes con nosotros? En la primera etapa, recibimos y procesamos imágenes. El documento está nivelado, las distorsiones se corrigen. Luego se realiza un análisis de la estructura de la página, en esta etapa se encuentran y determinan los tipos de bloques. Cuando se definen los bloques, las filas o columnas están alineadas, puede dividir estas líneas en palabras y símbolos, por ejemplo, mediante histogramas verticales y horizontales de la distribución del color negro.
Por lo tanto, es posible determinar dónde están los límites de los símbolos y las palabras, y luego reconocer cuáles son estos símbolos y palabras. Finalmente, los bloques reconocidos se sintetizan en documentos de texto único y se exportan.
Puede ver este proceso desde el punto de vista de entidades de diferentes niveles. Primero tenemos un documento paginado. Luego, estas páginas deben dividirse en bloques, bloques en líneas, líneas en palabras, palabras en caracteres, y luego estos caracteres deben ser reconocidos. Después de eso, recopilamos los caracteres reconocidos en palabras, palabras en líneas, líneas en bloques, bloques en páginas, páginas en un documento. Además, en el camino de regreso, la partición inicial puede variar. El ejemplo más simple es si los bloques inicialmente rotos pertenecían a la misma lista numerada, por lo que finalmente deberían pertenecer al mismo bloque con el tipo de lista estructurada. En otras palabras, los pasos adyacentes pueden influenciarse entre sí para mejorar la calidad del reconocimiento.
El documento fue reconocido, entonces necesita extraer información de él. Los documentos se pueden dividir en otros más estructurados y menos estructurados. Los más estructurados incluyen tarjetas de visita, cheques, facturas. Los menos estructurados incluyen poderes notariales, cartas, artículos en revistas. Si el tipo de documento es fijo, está más o menos estructurado y los documentos dentro de este tipo difieren poco entre sí en la estructura, puede aplicar métodos que aprendan a extraer directamente los atributos necesarios de un documento de texto utilizando atributos de texto y gráficos. Por ejemplo, utilizando redes neuronales recurrentes, puede extraer artículos de productos de las facturas. Las facturas son documentos en los que se presentan las posiciones de los bienes y una descripción de los métodos de pago de estos bienes.

Otro ejemplo son los cheques. Usando redes neuronales convolucionales, puede recuperar atributos únicos, como TIN, número de verificación, fecha-hora, puntaje total. Hablando francamente, tanto los métodos como los cheques se usan en cheques y facturas, pero para diferentes propósitos. Las redes neuronales convolucionales son buenas para atributos únicos que tienen algún tipo de posición, y las redes recurrentes son para elementos repetidos.
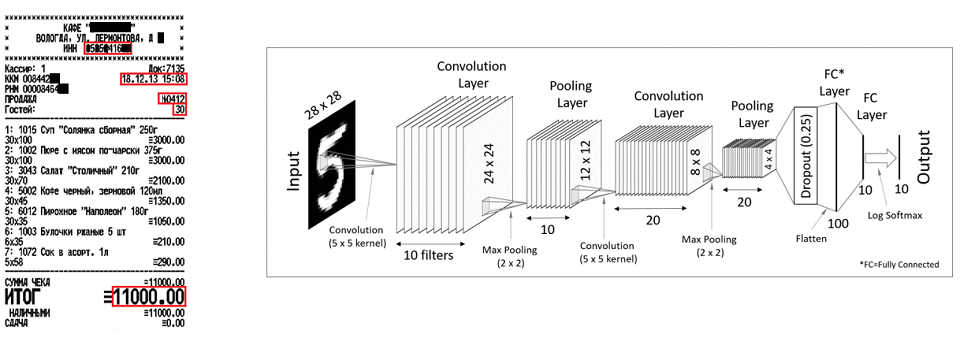
Si los documentos están menos estructurados, el procesamiento del lenguaje natural, el procesamiento del lenguaje natural o los métodos de PNL entran en juego. ¿Por qué es dificil? Ya hablé sobre la polisemia de las palabras. La palabra dirección, por ejemplo, puede significar la dirección de una empresa, o puede significar su compromiso para resolver algunos problemas de los clientes.
Además, los textos a menudo se omiten, pero las palabras están implícitas. Para extraer información, necesita recuperar estas palabras faltantes. Este efecto en lingüística se llama "puntos suspensivos".
El lenguaje es diverso, y generalmente hay innumerables formas de expresar un mismo pensamiento. Para procesar textos automáticamente, es necesario reducir de alguna manera esta variabilidad: el uso de sinónimos y construcciones similares para reemplazar una sola palabra o expresión; permutación de palabras o cambio de voz gramatical. Por ejemplo, "las empresas concluyeron un acuerdo" y "se concluyó un acuerdo entre empresas" para decir lo mismo. En el caso de los sinónimos, se puede introducir el llamado espacio semántico, un espacio vectorial en el que las palabras se representan como puntos. Los puntos cercanos indican conceptos relacionados, los puntos distantes indican conceptos más distantes. Para reducir la variabilidad de las formulaciones, puede introducir árboles de análisis sintácticos y semánticos. En este caso, también se resuelve un problema similar, y el algoritmo de extracción de información puede extraer información, incluso si encuentra construcciones o palabras que no se encontraron previamente en el conjunto de entrenamiento.
¿Cómo se extrae la información? En la primera etapa, se realiza un análisis léxico del documento. El texto se divide en párrafos, párrafos en oraciones, oraciones en palabras. Esto puede no ser trivial: aquellos de ustedes que estén familiarizados con la PNL pueden saber que incluso una tarea aparentemente simple como dividir el texto en oraciones puede ser difícil: los puntos no siempre indican el final de una oración. Estas pueden ser abreviaturas desconocidas, por lo tanto, en el análisis léxico, tratamos de clasificar todas las opciones posibles para dividir las oraciones en palabras y dejar las más probables. Este problema, por regla general, lo encontramos en idiomas en los que hay un pequeño número o ausencia total de espacios, como el japonés o el chino. O que tienen una rica formación de palabras. Este, por ejemplo, es un idioma como el alemán: tiene palabras muy largas que consisten en varias palabras (tales palabras se llaman compuestas). Además, para todas estas palabras, se calculan todas las posibles interpretaciones. Por ejemplo, si aparece "g" en el texto con un punto, puede significar mucho: ciudad, año, gramo, señor e incluso el cuarto párrafo (a, b, c, d).

Luego se realiza la segmentación, es decir, una búsqueda de las secciones que nos interesan. Se produce por varias razones, por ejemplo, para acelerar el procesamiento de documentos o encontrar información que nos interese; para encontrar alguna pieza del documento que describa las obligaciones de la parte. O esto es una aceleración del procesamiento, por ejemplo, nuestro documento puede constar de varias decenas o incluso cientos de páginas en casos especialmente avanzados, mientras que la información interesante se encuentra en solo unas pocas páginas. La segmentación le permite encontrar estas piezas interesantes y analizarlas solo. Luego, un análisis semántico del documento puede o no realizarse, depende de la tarea, y en esta etapa se realiza la búsqueda de las mejores interpretaciones de las oraciones, todas las oraciones del documento o solo aquellas que encontramos en la etapa anterior. Las características semánticas para el clasificador también se generan en el siguiente paso.
Finalmente, la etapa de extracción directa de atributos. Aquí se usan modelos entrenados en máquina o se escriben patrones simples. De una forma u otra, confían en los signos generados por los pasos anteriores. Estas son características estructurales, tanto léxicas como semánticas. Dependiendo de la complejidad de la tarea, utilizamos muchos métodos diferentes: métodos de aprendizaje automático y métodos de escritura de plantillas. En esta etapa, estamos buscando los atributos que nos interesan. Pueden ser los nombres de las partes, obligaciones, fecha de firma, etc.
Finalmente, algunos atributos pueden requerir un procesamiento posterior. Llevar a la forma normal o enviar a una plantilla de fecha. Algunos atributos pueden calcularse en principio, no se extraen del contrato, sino que se calculan en función de los atributos que se extraen del contrato. Por ejemplo, la duración del contrato en función del comienzo de la acción y su finalización.
Considere esto en uno de los escenarios, se llama "Abrir una cuenta con una entidad legal". ¿Cuál es el desafío? Una entidad legal, o más bien, su representante, acude al banco y trae una gran cantidad de documentos. En un buen caso, ya ha escaneado estos documentos, pero no está claro con qué calidad. Para optimizar el proceso, reducir el número de errores al ingresar esta información en el sistema, acelerar este proceso y, por lo tanto, acelerar la toma de decisiones y aumentar la lealtad del cliente, se propuso el siguiente esquema:
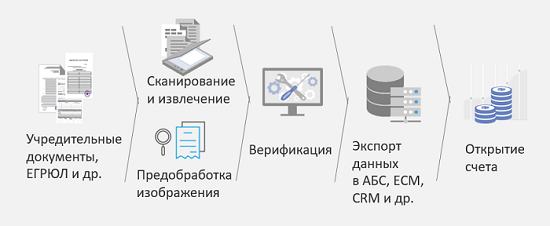
Los documentos constitutivos, que incluyen muchos tipos diferentes, se escanean primero y luego se reconocen. Además, después del reconocimiento, se clasifican por diferentes tipos y, según el tipo, se pueden usar diferentes algoritmos para reconocer y extraer información. Luego, esta información extraída, si es necesario, se envía a las personas para su verificación, y después de eso ya es posible tomar una decisión: abrir una cuenta o se necesitan otros documentos adicionales. El resultado principal de esta decisión es reducir a la mitad el costo de la entrada de datos al abrir una cuenta. Resultados basados en mediciones de nuestro cliente.
¿Qué atributos necesitas recuperar? Muchas cosas Supongamos que tenemos algún tipo de carta entrante. Primero lo reconocemos. Como recordamos, esto puede ser bastante problemático si se trata de un escaneo o una fotografía. Luego determinamos el tipo de documento, y esto es importante porque la información que necesitamos puede estar contenida en un capítulo o subcláusula específica y, por lo tanto, el conocimiento de cuándo comienza o termina este capítulo o subcláusula ayuda en gran medida al algoritmo de extracción de información.
Luego, la máquina recupera todas las entidades básicas que puede alcanzar:
Esto es necesario para que en la siguiente etapa de extracción de atributos o definición de roles, el algoritmo pueda usar no solo el contexto, sino también las características que se generaron en las etapas anteriores. Por ejemplo, puede simplificar enormemente la tarea de determinar quién es el director de una entidad legal, la información de que se trata de algún tipo de persona. En consecuencia, entre el conjunto de personas que aparecen en el documento, debemos clasificarlos, el director o no el director. Cuando tenemos un número limitado de objetos, esto simplifica enormemente la tarea.
En los últimos dos años, hemos encontrado varias tareas más de clientes y las hemos resuelto con éxito. Por ejemplo, monitoreo de medios para riesgos corporativos.
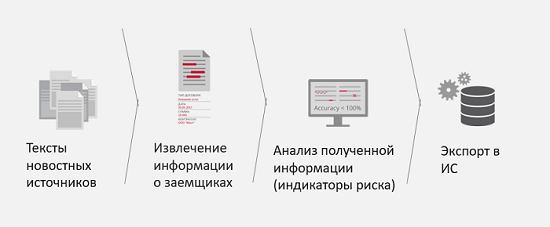
¿Cuál es el desafío comercial aquí? Por ejemplo, usted tiene un socio o cliente potencial que quiere pedirle un préstamo. Para acelerar el procesamiento de los datos de este cliente y reducir los riesgos de una mala asociación, o la quiebra futura de esta entidad legal, se propone monitorear los medios de comunicación en busca de referencias a esta persona física o jurídica y la presencia de los llamados indicadores de riesgo en las noticias. Es decir, si, por ejemplo, en las noticias aparece constantemente que una entidad legal está involucrada en procedimientos legales o una empresa está rota por conflictos de accionistas, es mejor averiguarlo antes para transmitir esta información a los analistas o al sistema analítico y comprender cuán malo o bueno es para su negocio . El resultado de resolver este problema es obtener información más completa y precisa sobre el prestatario, y también se reduce la cantidad de tiempo para obtener esta información.

Otro ejemplo de una aplicación en la que es necesario reducir la cantidad de rutina y el número de errores al ingresar información en el sistema es la extracción de datos de los contratos. Se propone que los contratos reconozcan, extraigan información de ellos y la envíen inmediatamente al sistema. Después de eso, el departamento de personal le agradece con lágrimas y calurosa bienvenida en cada reunión.
El departamento de recursos humanos no solo sufre una gran cantidad de trabajo de rutina con la documentación entrante, sino también los departamentos de contabilidad, departamentos de ventas y departamentos de compras. Los empleados tienen que pasar mucho tiempo ingresando información de facturas, actos entrantes, etc.
De hecho, todos estos documentos están estructurados y, por lo tanto, es fácil reconocerlos y extraer información de ellos. La velocidad de entrada de datos se incrementa hasta 5 veces y se reduce el número de errores, porque se excluye el factor humano. Condicionalmente, si un empleado regresó después del almuerzo, puede comenzar a ingresar datos sin prestar atención. , , , , , , 95%, 90%. , , .
- , – , - – , , , : «, ». , . : , .
, .
. -, , , , , . -, , , , , , , , .. , , , - .
, , , , .
. , Excel, , , - . .
, , , , , , . , . Gracias