
La tienda en línea de Ozon tiene casi todo: refrigeradores, comida para bebés, computadoras portátiles por 100,000, etc. Esto significa que todo esto también se encuentra en los almacenes de la empresa, y cuanto más tiempo estén los productos, más costosa será la empresa. Para saber cuánto y qué le gustaría pedir a la gente, y que Ozon necesitaría comprar, utilizamos el aprendizaje automático.
Pronóstico de ventas: desafíos
Antes de profundizar en el enunciado del problema, comenzamos con un ejemplo. Este es un verdadero calendario de ventas de Ozon por un tiempo. Pregunta: ¿a dónde irá después?
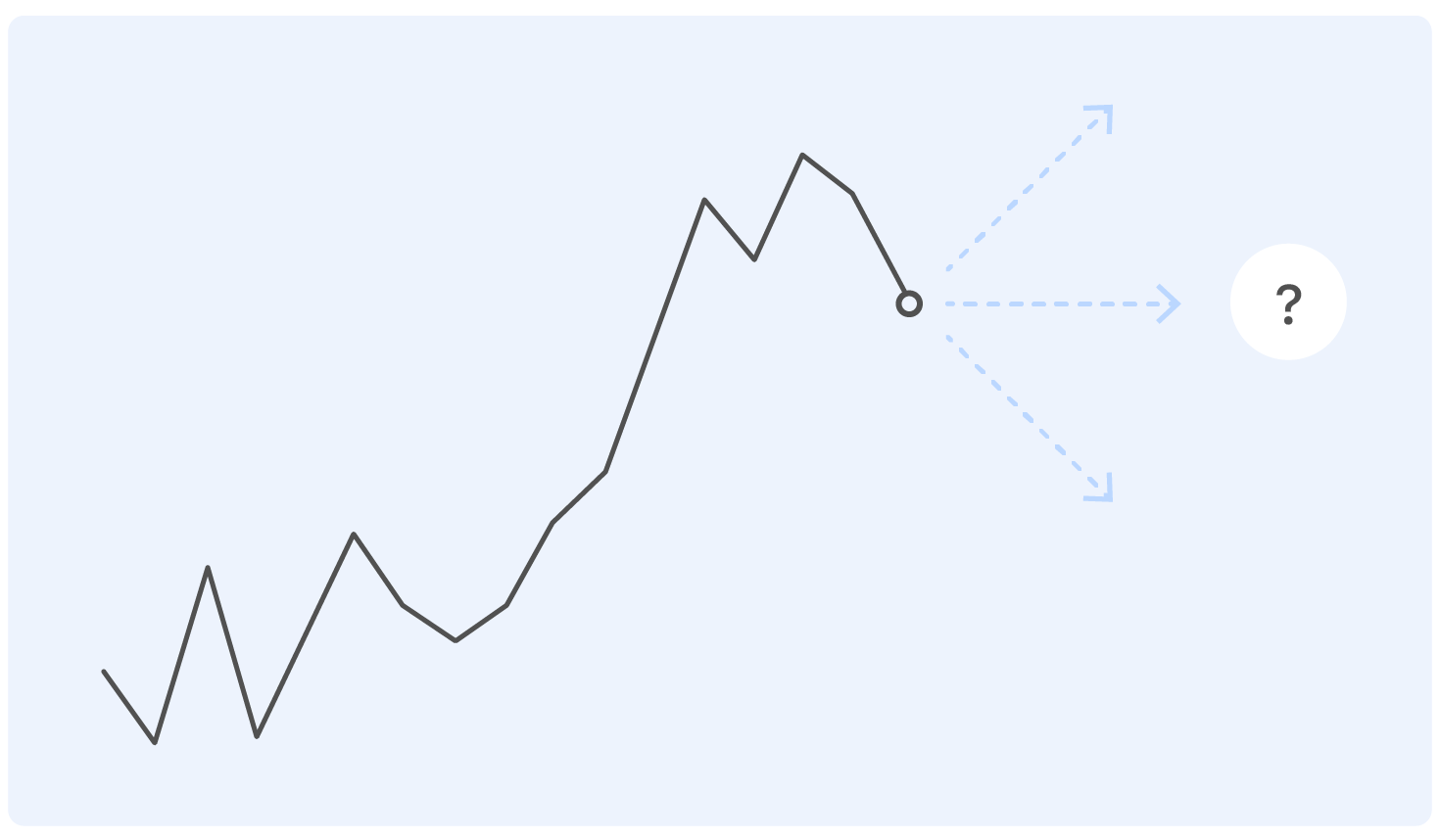
Una persona con una educación casi técnica para tal formulación del problema tendrá preguntas: ¿Dónde están los ejes? ¿Y qué tipo de producto? ¿Y en qué unidades? ¿De qué instituto te graduaste? - y muchos otros no incluidos en este artículo por razones éticas.
De hecho, nadie puede responder correctamente la pregunta en tal declaración, y si alguien puede, entonces lo más probable es que se equivoque.
Agregue más información a este cuadro: ejes y cambios de precios en el sitio web de Ozon (azul) y en el sitio web de la competencia (naranja).
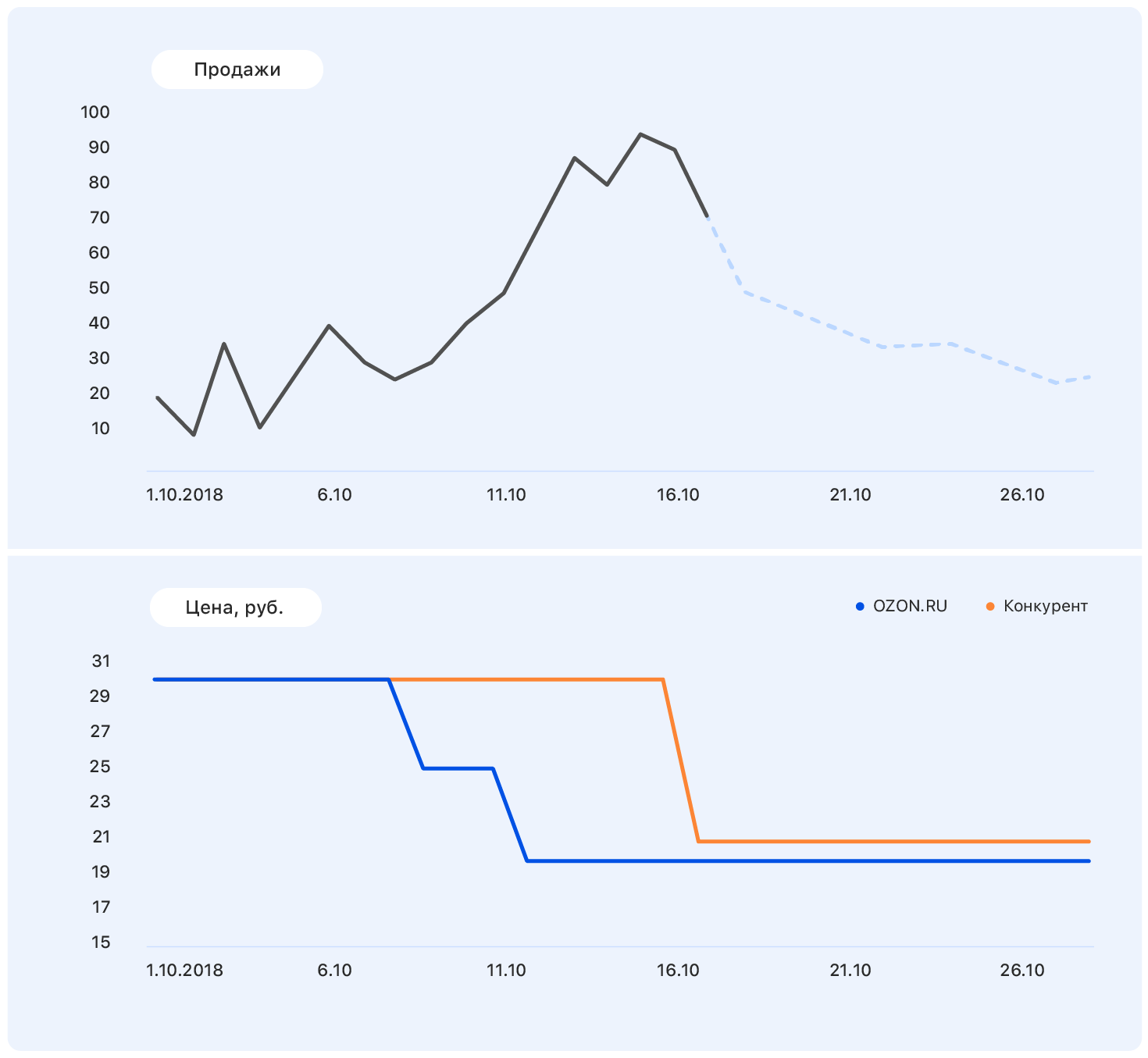
Nuestro precio cayó en algún momento, pero la competencia siguió siendo la misma, y las ventas de Ozon aumentaron. Conocemos los planes de precios: nuestro precio se mantendrá en el mismo nivel, pero el competidor, siguiendo a Ozon, bajó el precio a casi el nuestro.
Estos datos son suficientes para hacer una suposición significativa, por ejemplo, que las ventas volverán al nivel anterior. Y si nos fijamos en el gráfico, resulta que será así.
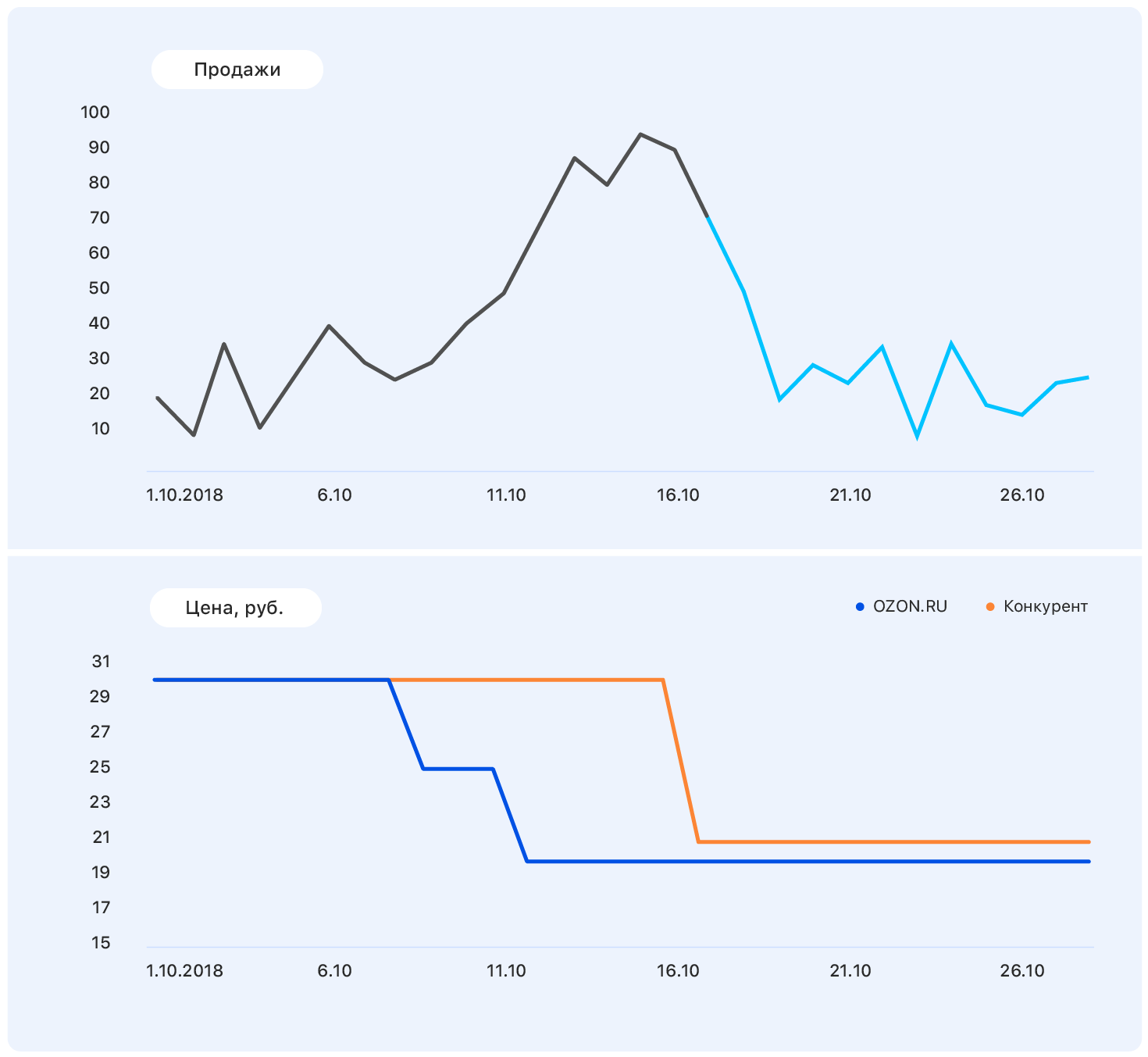
El problema es que, de hecho, la demanda de este producto no se ve muy afectada por el precio, y el crecimiento de las ventas fue causado, entre otras cosas, por la ausencia de la mayoría de los competidores de este producto en nuestra tienda. Todavía hay muchos factores que no tomamos en cuenta: ¿se anunciaron los productos en la televisión? o tal vez son dulces, y pronto el 8 de marzo?
Una cosa está clara: hacer un pronóstico "sobre la rodilla" no funcionará. Seguimos el camino estándar de un
rastrillo y muletas para construir cualquier algoritmo de ML. Y así es como fue.
Selección métrica
Elegir una métrica es donde comenzar si al menos otra persona además de usted usará su pronóstico.
Considere un ejemplo: tenemos tres opciones de pronóstico. Cual es mejor
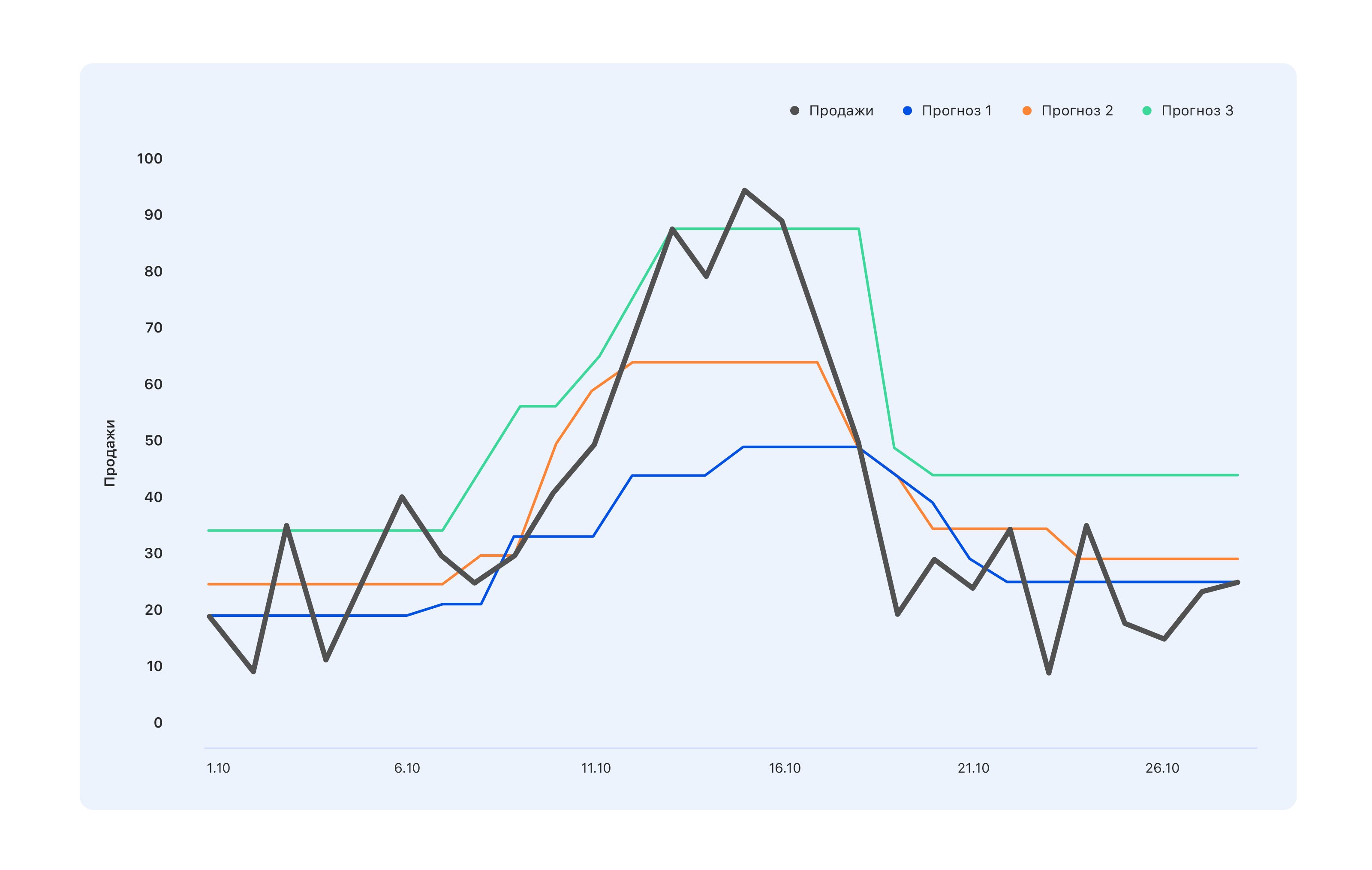
Desde el punto de vista de los especialistas en el almacén, necesitamos un pronóstico azul: compraremos un poco menos y nos perderemos el pico a mediados de octubre, pero no quedará nada en el almacén. Los expertos cuyos KPI están vinculados a las ventas tienen la opinión opuesta: incluso el pronóstico turquesa no es del todo correcto, no todos los saltos en la demanda se han reflejado: vaya a modificarlo. Pero desde el punto de vista de una persona, desde afuera, generalmente se necesita algo mejor, para que todos se sientan bien o viceversa.
Por lo tanto, antes de hacer un pronóstico, es necesario determinar quién lo usará y por qué. Es decir, elija una métrica y comprenda qué esperar de una previsión construida sobre dicha métrica. Y espera solo eso.
Elegimos MAE, el error absoluto promedio. Esta métrica es adecuada para nuestra muestra de entrenamiento altamente desequilibrada. Dado que el surtido es muy amplio (1,5 millones de artículos), cada producto individualmente en una región particular se vende en pequeñas cantidades. Y si en total vendemos cientos de vestidos verdes, entonces un vestido verde particular con gatos se vende a 2-3 por día. Como resultado, la muestra se desplaza hacia valores pequeños. Por otro lado, hay iPhones, hilanderos, un nuevo libro de Olga Buzova (una broma), etc. - Y se venden en cualquier ciudad en grandes cantidades. MAE le permite no recibir grandes multas en iPhones condicionales y, en general, funciona bien en la mayor parte de los productos.
Primeros pasos
Comenzamos construyendo el pronóstico más estúpido que podría ser: un número aleatorio de 0 a 1000 se venderá durante la próxima semana y obtendrá la métrica MAE = 496. Probablemente, puede ser peor, pero esto ya es muy malo. Entonces obtuvimos una directriz: si obtenemos un valor tan métrico, entonces obviamente estamos haciendo algo mal.
Luego comenzamos a interpretar a personas que saben cómo hacer un pronóstico sin aprendizaje automático, e intentamos predecir que las ventas de bienes durante la próxima semana serían iguales a las ventas promedio de todas las últimas semanas, y obtuvimos la métrica MAE = 1.45, que es mucho mejor.
Continuando con la razón, decidimos que las ventas de la semana pasada no serían más relevantes para pronosticar las ventas para la próxima semana. Para tal pronóstico, el MAE fue de 1.26. En la siguiente ronda de pensamiento pronóstico, decidimos tener en cuenta ambos factores y predecir las ventas para la próxima semana como la suma del 50% de las ventas promedio y el 50% de las ventas durante la semana pasada: obtuvimos MAE = 1.23.
Pero nos pareció demasiado simple, y decidimos complicar las cosas. Recolectamos una pequeña muestra de entrenamiento en la cual los signos eran ventas pasadas y promedio, y los objetivos eran ventas durante la próxima semana, y entrenamos en ella una regresión lineal simple. Obtuvimos pesos de 0.46 y 0.55 para el promedio y las últimas semanas y el MAE en la muestra de prueba igual a 1.2.
Conclusión: nuestros datos tienen potencial predictivo.
Ingeniería de características
Habiendo decidido que construir un pronóstico sobre dos bases no es nuestro nivel, nos sentamos para generar nuevas características complejas. Esta es información sobre ventas pasadas: hace 1, 2, 3, 4 semanas, una semana exactamente hace un año, etc. Y vistas en las últimas semanas, adiciones a la canasta, conversión de vistas y adiciones a la canasta en pedidos, y todo esto por diferentes períodos.
Necesitábamos proporcionar un modelo de conocimiento sobre cómo se vende el producto en su conjunto, cómo ha cambiado la dinámica de sus ventas últimamente, cómo está evolucionando el interés en él, cómo sus ventas dependen de los precios y otros factores que, en nuestra opinión, pueden ser útiles.
Cuando nuestras ideas se agotaron, acudimos a los expertos del departamento de ventas. Allí, por ejemplo, aprendimos que el próximo año es el año del cerdo, por lo tanto, los productos que al menos se parecen remotamente a los cerdos serán muy populares. O, por ejemplo, que "no se congele" nuestra gente no compra por adelantado, sino exactamente el día de las primeras heladas, así que tenga en cuenta el pronóstico del tiempo. En general, todos estaban satisfechos. Nosotros, debido a que recibimos un montón de nuevas ideas que nunca hubiéramos pensado de nosotros mismos y de los hombres de negocios, que pronto será posible hacer algo más interesante que el pronóstico de ventas.
Pero aún es demasiado simple, y hemos agregado síntomas combinados:
- conversión de vistas a ventas: cómo fue, cómo cambió;
- la relación de ventas durante 4 semanas a ventas durante la última semana (si esta cifra es muy diferente de 4, en este momento la demanda de este producto está sujeta a "turbulencia");
- la relación entre ventas de productos y ventas en toda la categoría: si esta cifra es cercana a uno, entonces el producto es un "monopolista".
En esta etapa, debe llegar a la mayor cantidad posible: deseche los signos no informativos en la etapa de entrenamiento.
Como resultado, obtuvimos 170 signos. Mirando hacia el futuro, la mayor importancia de la característica tenía
- Ventas de la semana pasada (para dos, tres y cuatro).
- La disponibilidad del producto la semana pasada es el porcentaje de tiempo que el producto estuvo presente en el sitio.
- El coeficiente angular del cronograma de ventas de bienes para los últimos 7 días.
- La relación entre el precio pasado y el futuro: con un gran descuento, comience a comprar bienes más activamente.
- El número de competidores directos dentro de nuestro sitio. Si, por ejemplo, este bolígrafo es el único en su categoría, las ventas serán bastante estacionarias.
- Dimensiones del producto: resultó que el largo y el ancho afectan significativamente la previsibilidad de las ventas. Por alguna razón, para objetos largos y estrechos, como paraguas o cañas de pescar, por ejemplo, el horario es mucho más volátil. Todavía no sabemos cómo explicar esto.
- Número de día del año: muestra si se acerca el Año Nuevo, el 8 de marzo, el inicio de un aumento estacional en las ventas, etc.
Muestreo
La muestra de entrenamiento es el dolor. Lo recolectamos durante aproximadamente 4 semanas, dos de las cuales fueron a diferentes custodios de datos y pidieron un vistazo a lo que tienen. Esto sucede cada vez que necesita datos durante un largo período. Incluso en un sistema de recopilación de datos ideal durante mucho tiempo, algo sucederá con el espíritu de "solíamos pensar así, pero luego comenzamos a pensar de manera diferente y escribir los datos en la misma columna". O hace un año o dos, el servidor se bloqueó, pero nadie escribió exactamente cuándo, y los ceros ya no significan que no hubo ventas.
Como resultado, teníamos información sobre lo que la gente hacía en el sitio, qué y en qué cantidades, se agregaron a favoritos y una cesta, y se compraron. Recolectamos una muestra de aproximadamente 15 millones de muestras de 170 características cada una, el objetivo era el número de ventas para la próxima semana.
Escribimos 2 mil líneas de código en Spark. Funcionó lentamente, pero permitió masticar grandes cantidades de datos. Simplemente parece que calcular la pendiente de una línea recta es simple. Y hacerlo 10kk veces cuando las ventas se obtienen de varias bases: la tarea no es para los débiles de corazón.
Durante otra semana, nos dedicamos a la limpieza de datos para que el modelo no se distrajera con las emisiones y las características de muestreo locales, sino que solo extrajera las verdaderas dependencias inherentes a las ventas de Ozon. Aquí irán 3 sigma y más métodos astutos para buscar anomalías. El caso más difícil es restablecer las ventas durante los períodos de falta de bienes en stock. La solución más simple es descartar las semanas en que el producto estuvo fuera durante la semana "objetivo".
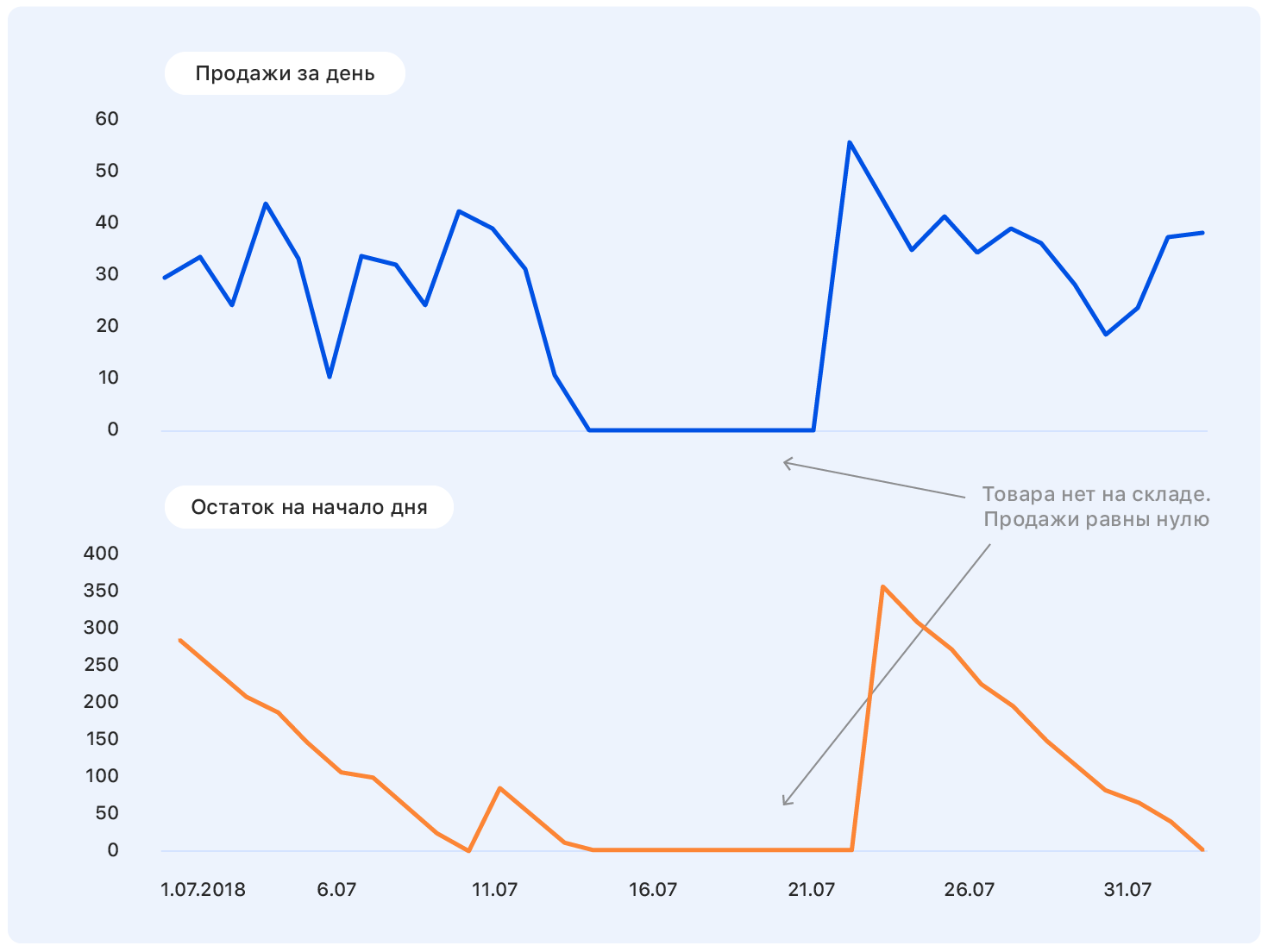
Como resultado, de 15 millones de muestras, quedaron 10 millones. Aquí es importante no dejarse llevar y no perder la integridad de la muestra (de hecho, la falta de productos en el almacén es una característica indirecta de su importancia para la empresa; retirar esos productos de la muestra no es lo mismo que tirar muestras aleatorias )
Tiempo de ML
En una muestra limpia y comenzó a entrenar modelos. Naturalmente, comenzamos con regresión lineal y obtuvimos MAE = 1.15. Parece que este es un aumento muy pequeño, pero cuando tiene una muestra de 10 millones en la que los valores promedio son 5-10, incluso un pequeño cambio en el valor métrico produce un aumento inconmensurable en la calidad visual del pronóstico. Y dado que eventualmente tendrá que presentar la solución a los clientes comerciales, aumentar su nivel de alegría es un factor importante.
El siguiente fue sklearn.ensemble.RandomForestRegressor, que después de una corta selección de hiperparámetros mostró MAE = 1.10. Luego probamos XGBoost (sin él), todo estaría bien y MAE = 1.03, solo un tiempo muy largo. Desafortunadamente, no teníamos acceso a la GPU para entrenar XGBoost, y en los procesadores un modelo fue entrenado durante mucho tiempo. Intentamos encontrar algo más rápido y nos decidimos por LightGBM: entrenó el doble de rápido y mostró MAE incluso un poco menos: 1.01.
Dividimos todos los productos en 13 categorías, como en el catálogo en el sitio: mesas, computadoras portátiles, botellas, y para cada una de las categorías capacitamos modelos con diferentes profundidades de pronóstico: de 5 a 16 días.
La capacitación tomó alrededor de cinco días, y para esto creamos enormes grupos de computación. Desarrollamos una tubería de este tipo: la búsqueda aleatoria funciona durante mucho tiempo, proporciona los 10 conjuntos principales de hiperparámetros, y luego el científico trabaja con ellos manualmente: construye métricas de calidad adicionales (calculamos MAE para diferentes rangos de objetivos), construye curvas de aprendizaje (por ejemplo, eliminamos parte de la capacitación muestras y entrenados nuevamente, verificando si los nuevos datos reducen la pérdida en la muestra de prueba) y otros gráficos.
Un ejemplo de un análisis detallado para uno de los conjuntos de hiperparámetros:
Métrica de calidad detalladaConjunto de trenes:
| Conjunto de prueba:
|
| Para objetivo = 0, MAE = 0.142222484602 | Para 0 MAE = 0.141900737761 |
| Para el objetivo> 0, MAPE = 45.168530676 | Para> 0 MAPE = 45.5771812826 |
| Errores mayores que 0 - 67.931341691% | Errores mayores que 0 - 51.6405939896% |
| Errores mayores que 1 - 19.0346986379% | Errores mayores que 1 - 12.1977096603% |
| Errores más de 2 - 8.94313926245% | Errores más de 2 - 5.16977226441% |
| Errores más de 3 - 5.42406856507% | Errores más de 3 - 3.12760834969% |
Errores más de 4 - 3.67938161595%
| Errores más de 4 - 2.10263125679% |
Errores más de 5 - 2.67322988948%
| Errores más de 5 - 1.56473158807%
|
Errores más de 6 - 2.0618556701%
| Errores más de 6 - 1.19599209102%
|
| Errores más de 7 - 1.65887701209% | Errores mayores que 7 - 0.949300173983%
|
Errores más de 8 - 1.36821095777%
| Errores más de 8 - 0.78310772461% |
| Errores más de 9 - 1.15368611519% | Errores mayores que 9 - 0.659205318158%
|
| Errores más de 10 - 0.99199395014% | Errores más de 10 - 0.554593106723% |
| Errores más de 11 - 0.863969667827% | Errores más de 11 - 0.490045146476%
|
Errores más de 12 - 0.764347266082%
| Errores más de 12 - 0.428835873827%
|
| Errores más de 13 - 0.68086818247% | Errores más de 13 - 0.386545830907%
|
| Errores más de 14 - 0.613446089087% | Errores más de 14 - 0.343884822697%
|
Errores más de 15 - 0.556297016335%
| Errores más de 15 - 0.316433391328%
|
Para objetivo = 0, MAE = 0.142222484602
| Para objetivo = 0, MAE = 0.141900737761
|
Para objetivo = 1, MAE = 0.63978556493
| Para objetivo = 1, MAE = 0.660823509405 |
| Para objetivo = 2, MAE = 1.01528075312 | Para objetivo = 2, MAE = 1.01098070566 |
| Para objetivo = 3, MAE = 1.43762342295 | Para objetivo = 3, MAE = 1.44836233499 |
Para objetivo = 4, MAE = 1.82790678437
| Para objetivo = 4, MAE = 1.86539223382
|
Para objetivo = 5, MAE = 2.15369976552
| Para objetivo = 5, MAE = 2.16017884573 |
Para objetivo = 6, MAE = 2.51629758129
| Para objetivo = 6, MAE = 2.51987403661
|
Para objetivo = 7, MAE = 2.80225497415
| Para objetivo = 7, MAE = 2.97580015564
|
Para objetivo = 8, MAE = 3.09405048248
| Para objetivo = 8, MAE = 3.21914648525
|
Para objetivo = 9, MAE = 3.39256765159
| Para objetivo = 9, MAE = 3.54572928241
|
| Para objetivo = 10, MAE = 3.6640339953 | Para objetivo = 10, MAE = 3.84409605282
|
Para objetivo = 11, MAE = 4.02797747118
| Para objetivo = 11, MAE = 4.21828735273
|
Para objetivo = 12, MAE = 4.17163467899
| Para objetivo = 12, MAE = 3.92536509115
|
Para objetivo = 14, MAE = 4.78590364522
| Para objetivo = 14, MAE = 5.11290428675 |
Para objetivo = 15, MAE = 4.89409916994
| Para objetivo = 15, MAE = 5.20892023117
|
Pérdida de tren = 0.535842111392
Pérdida de prueba = 0.895529959873
Predicción gráfica (objetivo) para el conjunto de entrenamiento Predicción gráfica (objetivo) para la muestra de prueba Error de predicción de vez en cuando Ordenar error ascendente en muestra de prueba Si ninguno coincide, busque al azar nuevamente. Así es como entrenamos el modelo durante 5 o 5 días al ritmo industrial. Estábamos de servicio, alguien por la noche, alguien se despertaba por la mañana, miraba los 10 parámetros principales, reiniciaba o guardaba el modelo y se acostaba más. En este modo, trabajamos durante una semana y capacitamos a 130 modelos: 13 tipos de productos y 10 profundidades de pronóstico, cada uno con 170 características. El promedio de MAE para la serie temporal de 5 veces cv obtuvimos igual a 1.
Puede parecer que esto no es muy bueno, y esto es así, a menos que tenga una gran parte en la selección de unidades. Como lo muestra un análisis de los resultados, se predice que las unidades son las peores de todas: el hecho de que un producto se haya comprado una vez por semana no dice nada acerca de si hay demanda para él. Una vez que se puede vender algo, hay una persona que comprará una figura de porcelana en forma de dentista, y esto no dice nada sobre ventas futuras o sobre ventas pasadas. En general, no nos enojamos mucho por esto.
Consejos y trucos.
¿Qué salió mal y cómo se puede evitar?
El primer problema es la selección de parámetros. Comenzamos a usar RandomizedSearchCV, una herramienta muy conocida de sklearn para ordenar hiperparámetros. Aquí es donde nos esperaba la primera sorpresa.
Como estefrom sklearn.model_selection import ParameterSampler
from sklearn.model_selection import RandomizedSearchCV
estimator = lightgbm.LGBMRegressor(application='regression_l1', is_training_metric = True, objective = 'regression_l1', num_threads=72)
param_grid = {'boosting_type': boosting_type, 'num_leaves': num_leaves, 'max_depth': max_depth, 'learning_rate':learning_rate, 'n_estimators': n_estimators, 'subsample_for_bin': subsample_for_bin, 'min_child_samples': min_child_samples, 'colsample_bytree': colsample_bytree, 'reg_alpha': reg_alpha, 'max_bin': max_bin}
rscv = RandomizedSearchCV(estimator, param_grid, refit=False, n_iter=100, scoring='neg_mean_absolute_error', n_jobs=1, cv=10, verbose=3, pre_dispatch='1*n_jobs', error_score=-1, return_train_score='warn')
rscv .fit(X_train.values, y_train['target'].values)
print('Best parameters found by grid search are:', rscv.best_params_)
El cálculo simplemente se detiene (lo cual es importante, no cae, pero continúa funcionando, pero en un número cada vez menor de núcleos y en algún momento simplemente se detiene).
Tuve que paralelizar el proceso debido a RandomizedSearchCVestimator = lightgbm.LGBMRegressor(application='regression_l1', is_training_metric = True, objective = 'regression_l1', num_threads=1)
rscv = RandomizedSearchCV(estimator, param_grid, refit=False, n_iter=100, scoring='neg_mean_absolute_error', n_jobs=72, cv=10, verbose=3, pre_dispatch='1*n_jobs', error_score=-1, return_train_score='warn')
rscv .fit(X_train.values, y_train['target'].values)
print('Best parameters found by grid search are:', rscv.best_params_)
Pero RandomizedSearchCV toma casi todo el conjunto de datos para cada "trabajo". En consecuencia, es necesario expandir en gran medida la cantidad de RAM, posiblemente sacrificando el número de núcleos.
¡Quién nos diría sobre cosas tan maravillosas como el hipermétrope! Desde que aprendimos, solo lo usamos.
Otro truco que se nos ocurrió cerca del final del proyecto fue elegir modelos que tuvieran el parámetro colsample_bytree (este es el parámetro LightGBM, que dice qué porcentaje de características dar a cada nivel) en la región de 0.2-0.3, porque cuando el automóvil Funciona en producción, puede que no haya tablas y que las características individuales no se cuenten correctamente. Dicha regularización le permite asegurarse de que estas características no contabilizadas afecten al menos a no todos los prestamistas dentro del modelo.
Empíricamente, hemos llegado a la conclusión de que necesitamos hacer más estimadores y torcer más la regularización. Esta no es una regla de trabajo con LightGBM, pero tal esquema funcionó para nosotros.
Bueno y, por supuesto, Spark. Por ejemplo, hay un error que Spark mismo conoce: si toma varias columnas de una tabla y crea una nueva, y luego toma otras de la misma tabla y crea una nueva, y luego sintoniza las tablas que recibe, todo se romperá, aunque no debería. Solo puede salvarse al deshacerse de todos los cálculos perezosos. Incluso escribimos una función especial: bumb_df, convierte el Marco de datos en un RDD nuevamente en un Marco de datos. Es decir, restablece todos los cálculos perezosos. Esto puede protegerte de la mayoría de los problemas de Spark.
bumb_dfdef bump_df(df):
# to avoid problem: AnalysisException: resolved attribute(s)
df_rdd = df.rdd
if df_rdd.isEmpty():
df = df_rdd.toDF(schema=df.schema)
return df
else:
return df_rdd.toDF(schema=df.schema)
El pronóstico está listo: ¿cuánto pediremos?
Pronosticar las ventas es una tarea puramente matemática, y si la distribución normal de un error de media cero es una victoria para un matemático, entonces, para los comerciantes que tienen todos los rublos en su cuenta, esto es inaceptable.
Si un iPhone adicional o un vestido de moda en el almacén no es un problema, sino más bien un stock de seguros, entonces la ausencia del mismo iPhone en el almacén es una pérdida de al menos un margen, y como máximo de imagen, y esto no puede permitirse.
Para enseñar el algoritmo a comprar tanto como sea necesario, tuvimos que calcular el costo de recompra y subcompra de cada producto y entrenar un modelo simple para minimizar las posibles pérdidas de dinero.
El modelo recibe un pronóstico de ventas en la entrada, le agrega ruido aleatorio, normalmente distribuido (simulamos las imperfecciones de los proveedores) y aprende a agregar exactamente lo mismo al pronóstico para cada producto en particular para minimizar las pérdidas de dinero.
Por lo tanto, un pedido es un pronóstico + stock de seguridad, que garantiza la cobertura del error de pronóstico y la imperfección del mundo exterior.
Como en prod
Ozon tiene su propio clúster informático bastante grande, en el que todas las noches se lanza una tubería (usamos flujo de aire) de más de 15 trabajos. Se ve así:

Cada noche, se lanza el algoritmo, extrae alrededor de 20 GB de datos de una variedad de fuentes en archivos hdf locales, selecciona un proveedor para cada producto, recopila características para cada producto, realiza un pronóstico de ventas y genera pedidos basados en el cronograma de entrega. A las 6-7 a.m., entregamos a la mesa personas que son responsables de trabajar con los proveedores de mesas preparadas que se van volando con solo un clic a los proveedores.
Ni un solo pronóstico
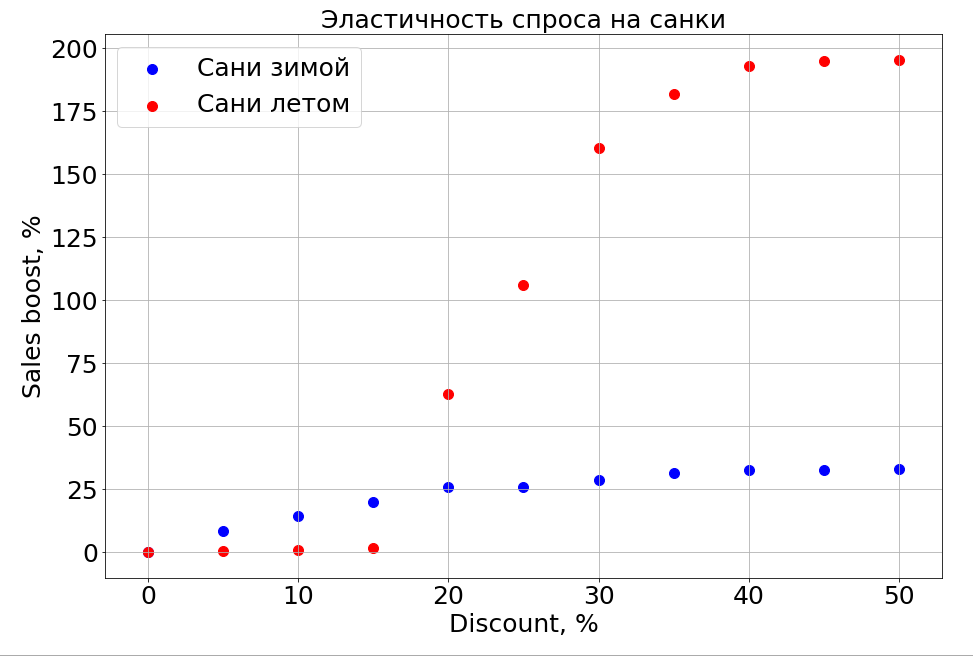
El modelo entrenado sabe sobre la dependencia del pronóstico en cualquier característica y, como resultado, si congela los signos N-1 y comienza a cambiar uno, puede observar cómo afecta el pronóstico. Por supuesto, lo más interesante de esto es cómo las ventas dependen del precio.
Es importante tener en cuenta que la demanda depende no solo del precio. Por ejemplo, si hace pequeños descuentos en trineos en el verano, todavía no les ayuda a vender. Estamos haciendo un descuento más, y aparecen personas que están "preparando un trineo en el verano". Pero hasta cierto nivel de descuentos, aún no podemos llegar a la parte del cerebro responsable de la planificación. En invierno, funciona como para cualquier producto: hace un descuento y se vende más rápido.
Planes
Ahora estamos estudiando activamente la agrupación de series de tiempo para distribuir productos entre grupos en función de la naturaleza de la curva que describe sus ventas. Por ejemplo, estacional, tradicionalmente popular en verano o, por el contrario, en invierno. Cuando aprendamos cómo separar productos con un largo historial de ventas, planeamos resaltar las características basadas en artículos que le indicarán cuál será el patrón de ventas para un producto nuevo y recién presentado; por ahora, esta es nuestra tarea principal.
Las redes neuronales y los modelos paramétricos de series de tiempo, y todo esto en el conjunto, seguramente estarán más allá.
En particular, gracias al nuevo sistema de pronóstico, Ozon cambió de comprar bienes con stock a entregas cíclicas, cuando compramos de un suministro a otro y no almacenamos saldos en stock.
Ahora tenemos que decidir cómo enseñar el algoritmo para predecir las ventas de nuevos productos y categorías enteras. El próximo año, la compañía planea aumentar las ventas x10 en categorías y x2.5 en áreas de cumplimiento. Y debemos decirles a los modelos que estos datos antiguos son relevantes, pero para una tienda anterior diferente. Y mientras estamos pensando cómo hacerlo.
La segunda cosa irracional por naturaleza que tenemos que aprender a predecir es la moda. ¿Cómo podría uno predecir que una ruleta se vendería así? ¿Cómo predecir las ventas de libros nuevos de Dan Brown si uno de sus libros está agotado y el otro no? Mientras estamos trabajando en ello.
Si sabe cómo hacerlo mejor, o si tiene historias sobre el uso del aprendizaje automático en la batalla en los comentarios, lo discutiremos.