
Érase una vez, una conversación a escondidas tuvo lugar
en el frente de una tienda distante, distante :
NB: - ?
GURU : - «» . . . , ...
NB: - , ?
GURU : - google yandex , . . , .
NB: - ?
GURU : - ?… ...
NB dejó de preguntar, aparentemente temiendo molestar a un interlocutor claramente más experimentado.
GURU puso los ojos en blanco, como si enfatizara el agotamiento del tema de poder y estuviera en silencio ...
Por supuesto,
GURU sabía que una consulta de búsqueda (por ejemplo, por la palabra: proxy) muy pronto llevaría a
NB a obtener la dirección deseada: lista de puertos. Pero después de los primeros experimentos,
NB , con la misma rapidez, comprenderá:
- No todas las direcciones en su lista están funcionando;
- No todos los poderes son igualmente buenos;
- "Pegar" un sitio a través de un proxy manualmente es una tarea que requiere una voluntad considerable;
- Un poder "incorrecto" dañará la situación, porque el sitio puede sospecharse por guiones de gigantes en la envoltura.
En este artículo hablaré sobre cómo significa improvisado (y lo más importante, universal)
(sin usar software específico específico, como
ZennoPoster , etc.)
crear una herramienta automatizada para obtener una lista de servidores proxy "realmente adecuados" y usarlos para organizar visitas (automatizadas) a los promocionados
sitio usando el
navegador Chrome .
Siguiendo las instrucciones, recibirá una herramienta lista para usar que permitirá:
- “Haga clic” en (visitar) el sitio de destino de forma completamente automática, sin temor a comprometerse;
- emular completamente el comportamiento del usuario;
- organizar todas las visitas de acuerdo a un horario (escenario);
- haga todo lo anterior en la cantidad de veces que sea necesario para avanzar.
Y aunque todo mi trabajo (junto con la investigación) tomó una semana, no necesitará dos días para construir dicha herramienta, teniendo conocimientos básicos de la
línea de comandos ,
PHP y
JavaScript .
Sin embargo, antes de desplazarse por debajo del
siguiente diagrama , diré algunas palabras sobre por qué este material está preparado y para quién.
El material será útil si desea comprender cómo se organizan las construcciones (¿o los constructores?) Con las que puede construir una aplicación de forma relativamente rápida, fácil y sin costo, adaptable a los cambios de carga. Si está interesado en la posibilidad de crear una aplicación basada en un bus de servicio (
ESB ).
El texto será útil si desea familiarizarse con el uso de
Docker para sistemas de construcción
instantánea . O si solo está interesado en
Selenium Server y los matices de recibir contenido / manifestación de actividad HTTPx.
Para "usar inmediatamente", leer atentamente todo esto no vale la pena. El código es seguro.
Vaya directamente a configurar la herramienta terminada. La configuración lleva menos de 20 minutos.El manual asume que tiene 2 máquinas a su disposición con Ubuntu 18.04 instalado.
Uno para la infraestructura (
acoplador ), el otro para el control del
proceso (
proceso ).
Se supone que los siguientes paquetes ya están instalados en la
ventana acoplable :
git, docker, docker-compose
Se supone que los siguientes paquetes ya están instalados en el
proceso :
git, php-common, php-cli, php-curl, php-zip, php-memcached, compositor
Si tiene alguna pregunta en este momento, le sugiero que pase 15 minutos leyendo todo el material.
acoplador
proceso
Espera, observa lo que sucede a través del panel web (http: // ip-address-docker-machines: 8080).
El resultado estará disponible en la cola
localizada .
Aplastamiento y planificación
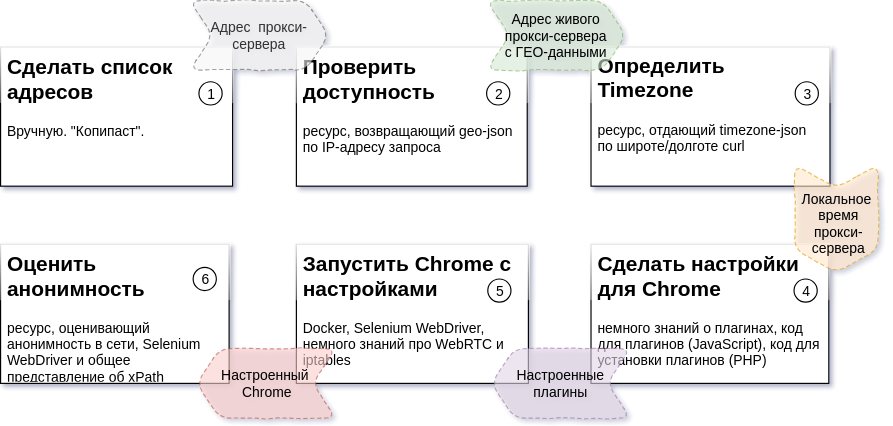
El diagrama anterior describe la secuencia de pasos del proceso, el resultado esperado para cada paso y los recursos que se necesitarán para crear cada parte (detalles:
Tarea 2 ,
Tarea 3 ,
Tarea 4,5,6 ).
En mi caso, todo sucede en dos máquinas
Ubuntu 18.04 . Uno de ellos controla el proceso. Por otro lado, se están ejecutando varios contenedores de infraestructura docker.
Excusas y fracasos
Todo el código del paquete consta de tres partes.
Uno de ellos no es mío (noto que este es un código ordenado y hermoso). La fuente de este código es packagist.org .
Yo mismo escribí otro, intenté hacerlo comprensible y dediqué aproximadamente una semana a esta parte del código.
El resto es un "legado histórico difícil". Esta parte del código fue creada durante un tiempo bastante largo. Incluso en un momento en que no tenía mucha habilidad para programar.
Esta es precisamente la razón de la ubicación de los repositorios en mi GitLab y los paquetes en mi Satis . Para publicar en GitHub.com y packagist.org, este código requerirá procesamiento y documentación más exhaustiva.
Todas las partes del código están abiertas para uso ilimitado. Los repositorios y paquetes estarán disponibles para siempre.
Sin embargo, cuando vuelva a publicar el código, le agradeceré que publique un enlace para mí o para este artículo.
Un poco sobre arquitectura
El enfoque que se usó para crear nuestra herramienta es escribir (o usar una utilidad preparada) para resolver cada tarea específica. Además, cada utilidad, independientemente de la tarea a resolver, tiene dos propiedades comunes a todos:
- la utilidad se puede iniciar independientemente de las demás desde la línea de comandos con parámetros que contienen la tarea;
- la utilidad puede devolver el resultado de la ejecución a stdout (después de configurarse de cierta manera).
Una solución hecha por este principio le permite cambiar el número de manejadores de tareas en ejecución (trabajadores) para cada uno de los pasos del proceso. Un número diferente de trabajadores para cada paso conducirá a un tiempo de inactividad de "0" para los pasos que siguen debido a la duración de las tareas de procesamiento de los pasos anteriores.
El tiempo dedicado a obtener una unidad del resultado del proceso (en nuestro caso es un proxy verificado) depende de factores externos (el número de proxies inadecuados, el tiempo de respuesta de un recurso externo, etc.).
Al cambiar el número de trabajadores para cada uno de los pasos del proceso, transformamos esta dependencia en una dependencia del número de trabajadores en funcionamiento (es decir, dependiendo de la capacidad informática y de las capacidades del canal).
Para sincronizar la operación de partes independientes individuales, es conveniente usar el servidor de cola de mensajes como un solo bus de datos. Le permitirá acumular los resultados de los pasos completados en la cola y darlos a la utilidad "siguiente paso" en el momento adecuado como entrada.
Cola de mensajes MQ y ESB
Como nivel inferior (
MQ ) usaremos
beanstalkd . Pequeño, liviano, sin configuración, disponible en el paquete deb y en el contenedor Docker, un trabajador discreto. El nivel lógico (
ESB ) implementará el código en
PHP .
Se usarán dos clases para la implementación.
esbTask y
nextStepWorker .
esbTask class esbTask // , {
Una instancia de esta clase sirve para "abordar"
paylod a través de los pasos del proceso. El concepto de
ESB aplica varios principios / patrones. Vale la pena prestar atención a dos de ellos por separado:
- Sobre la ruta (secuencia de pasos) del proceso, en cada momento del proceso
nadie lo sabe excepto el sobre a transmitir;
- Cada sobre tiene tres posibles direcciones de resultado:
- el siguiente paso del proceso (continuación normal);
- detener paso (detener objetivo: se selecciona en el siguiente paso, si no tiene sentido continuar con el proceso / detener la situación);
- paso de error (objetivo de terminación de emergencia - se selecciona en el siguiente paso, en caso de un error del trabajador).
El objeto en cola se representa en json, oculto aquí ... nextStepWorkerEl trabajador responsable de cada mensaje procesa cada mensaje que aparece en la cola. Para hacer esto, se implementa el siguiente conjunto de funciones:
class nextStepWorker extends workerConstructor {
Los trabajadores para cada uno de los pasos del proceso se implementan sobre la base de esta clase. La clase se encarga de toda la rutina de procesamiento, direccionamiento y envío del siguiente paso en la ruta.
La solución a cada uno de los problemas es:
- Obtenga esbTask y ejecute el trabajador;
- Implemente la lógica almacenando los resultados en la carga útil;
- Complete la ejecución del trabajador (de emergencia o normal, no importa).
Si se completan los pasos, el resultado se pondrá en cola con el nombre apropiado y el siguiente trabajador comenzará a procesar.
Hazlo una vez. Consultar disponibilidad
De hecho, crear un trabajador para resolver cualquiera de los problemas es la implementación de un método. Un ejemplo (simplificado) de la implementación de un trabajador que resuelve el
problema 2 es el siguiente:
Algunas líneas de código y todo está hecho y "secundado" a la siguiente etapa.
Definir TimeZone. TimeZoneDB y para qué sirve ...
La prueba en profundidad de las solicitudes entrantes implica hacer coincidir el tiempo de la ventana del navegador con el momento en que existe la dirección IP de origen de la solicitud.
Para evitar sospechas de los contadores, necesitamos saber la hora del proxy local.
Para averiguar la hora, tomamos la latitud y la longitud de los resultados del paso anterior del proceso y obtenemos datos sobre la zona horaria en la que funcionará nuestra instancia futura de la ventana del navegador. Estos datos nos serán proporcionados por
profesionales en el campo del tiempo .
Un trabajador simplificado para resolver este problema (
Tarea 3 ) será completamente similar al
anterior . La única diferencia es la URL de solicitud. Puede encontrar la versión completa en el archivo:
// app / src / Process / worker / timeZone.php
Un poco sobre infraestructura
Además del
beanstalkd descrito, nuestra herramienta necesitará:
- Memcached : para tareas de almacenamiento en caché;
- Selenium Server : es conveniente ejecutar Selenium Web Driver en un contenedor separado y puede monitorear el proceso a través de VNC ;
- Paneles de control para monitorear beanstald , memcached y VNC .
Para una implementación rápida de todo esto, Docker (
Cómo instalar en Ubuntu ) es muy conveniente.
Y el "orquestador" para él es docker-compose (comandos para la instalación) ... sudo apt-get -y update sudo apt-get -y install docker-compose
Estas herramientas le permiten ejecutar servidores / procesos ya configurados y configurados (por alguien anterior) en "contenedores" separados del sistema operativo principal. Para más detalles, recomiendo consultar
este o
este artículo.
Entonces ...
Para iniciar la infraestructura, necesita varios comandos en la consola:
Como resultado de la ejecución exitosa del comando en la máquina con la dirección XXX.XXX.XXX.XXX,
Recibirá el siguiente conjunto de servicios:
- XXX.XXX.XXX.XXX:11300 - beanstalkd
- XXX.XXX.XXX.XXX:11211 - Memcached
- XXX.XXX.XXX.XXX-00-00444 - Servidor Selenium
- XXX.XXX.XXX.XXX:5930 - Servidor VNC para controlar lo que sucede en Chrome
- XXX.XXX.XXX.XXX:8081 - Panel web para comunicarse con Memcached (admin: pass)
- XXX.XXX.XXX.XXX:8082 - Panel web para comunicarse con beanstalkd
- XXX.XXX.XXX.XXX:8083 - Panel web para comunicarse con VNC (contraseña: secreto)
- XXX.XXX.XXX.XXX:8080 - Panel web general
"Ver si todo está en su lugar", "entrar en la consola al contenedor", "detener la infraestructura" pueden ser comandos en el spoiler. Tareas 4,5,6: combinar en una sola utilidad
Después de analizar en detalle las tareas de trituración (
diagrama anterior ), es fácil asegurarse de que solo una de las tareas restantes (
tarea 6 ) dependa de un recurso externo. Al realizar tareas con tiempos de ejecución "condicionalmente garantizados" (independientes de factores no controlados), no obtendremos ventajas adicionales a la velocidad de todo el proceso. En este sentido, estas tareas (
4,5,6 ) se combinaron en un solo trabajador. El archivo de trabajo se llama:
// app / src / Process / worker / whoerChecker.php
Realiza ajustes para Chrome. Complementos
Chrome está configurado de manera flexible con complementos.
Un complemento para
Chrome es un archivo que contiene un archivo
manifest.json . Describe el complemento. El archivo también contiene un conjunto de
JavaScript, html, css y otros archivos necesarios para el complemento (
detalles ).
En nuestro caso, uno de los archivos
JavaScript se ejecutará en el contexto de la ventana de trabajo de
Chrome y se aplicarán todas las configuraciones necesarias.
Solo necesitamos tomar la plantilla de complemento y sustituir los datos necesarios (protocolo de interacción, dirección y puerto o zona horaria) para el servidor proxy que se está probando en los lugares correctos.
Un fragmento de código que crea el archivo:
La plantilla para el complemento de ajuste de proxy se encontró
en la alcancía de los resultados del trabajo de las personas que aman su profesión , cambió en la parte del protocolo y se agregó al repositorio.
Cambio de tiempo de ventana
Para cambiar la hora global de una instancia de Chrome en ejecución, debemos reemplazar
window.Date con una clase con una funcionalidad similar, pero válida en la zona horaria correcta.
Realmente aprecio
el trabajo de Sampo Juustila . La secuencia de comandos se realizó para pruebas automáticas de la
interfaz de
usuario , pero después de aplicar un poco de refinamiento.
Aquí hay un matiz al que quiero llamar su atención. Está asociado con el contexto de los scripts descritos en
manifest.json .
Todo el secreto es que el contexto global (aquel en el que se inicia el script principal del complemento y se configuran, por ejemplo, conectado a la red) está aislado del contexto de la pestaña en la que se carga la página.
Empíricamente, se encontró que el impacto en el prototipo de la clase en el contexto global no condujo a su cambio en la pestaña. Sin embargo, después de haber registrado el script en la página ya cargada y haberlo ejecutado antes que los demás, el problema se resolvió.
La solución está representada por el siguiente fragmento de código:
Configuraciones de proxy
Configurar un proxy en Chrome es tan simple que ocultaré el código js en un spoiler Ruta de complementos de Chrome
Todos los complementos se nombran de acuerdo con el esquema y se agregan a la carpeta temporal de la máquina que controla el proceso.// esquema de nombres para el complemento proxy:
proxy- [dirección] - [puerto] - [protocolo]>. zip
Timeshift - ["-" | ""] - [shift_in_minutes_from_GMT] .zip
A continuación, necesitamos instalar estos complementos en un contenedor acoplable que se ejecuta en la máquina responsable de la infraestructura.
Haremos esto con ssh.
Para hacer esto, conocí a phpseclib (incluso más tarde lo lamenté). Fascinado por el comportamiento inusual de la biblioteca, pasé un día estudiándolo.El cliente de consola ssh funcionará mejor aquí y funcionará más rápido, pero el trabajo ya está hecho.Para el nivel bajo (trabajar con SFTP y SSH) la clase base es responsable (abajo). Reemplazar esta clase reemplazará phpseclib con el cliente de la consola.
Derivado de la base sshDocker y la clase proxyHelper ya conocida, no solo produce complementos, sino que también los coloca en una carpeta temporal del contenedor de infraestructura.
Iniciar Chome con configuración
Selenium Server nos ayudará a lanzar Chrome personalizado . Selenium Server es un marco creado por el equipo de FaceBook específicamente para probar interfaces WEB. El marco de trabajo permite al desarrollador emular mediante programación cualquier acción del usuario en una ventana del navegador (usando Chrome o Firefox ). Selenium Server está adaptado para usar con muchos idiomas y es de hecho la herramienta estándar para escribir scripts de prueba. La mejor manera de obtener una nueva versión para usar en un proyecto: composer require facebook/webdriver
La configuración tradicional de la instancia principal del objeto Selenium Server (RemoteWebDriver) me pareció detallada. Y por lo tanto, reduje ligeramente todo esto, optimizando la configuración para mis necesidades:
El ojo se aferra inmediatamente a $ plugins. $ plugins es una estructura de datos responsable de configurar complementos. Para cada directorio y para reemplazar marcadores de posición en los archivos JavaScript del complemento.La estructura se describe en el archivo app / plugs.php y es parte de las opciones globales app / settings.php. Analizar una página con Selenium WebDriver es muy simple. .... $url = 'https://__/_-_'; $page = $chrome->get($url); ....
Como ya escribí, todas estas acciones son implementadas por la utilidad del tercer paso ( Tarea 4,5,6 ):// app / src / Process / worker / whoerChecker.php
Concluyendo la descripción de trabajar con Selenium Server , quiero llamar su atención sobre el hecho de que cuando se utiliza esta tecnología a escala industrial (1000 a 3000 páginas abiertas), no es raro que una sesión con Selenium Server finalice incorrectamente. La ventana no tiene dueño. Y tales ventanas pueden acumularse mucho.Se consideraron varias formas de combatir los "broches". Trabajo "comió" 2 días. El más efectivo fue cron . La correcta instalación y configuración en el contenedor Docker se convirtió en una tarea separada, cuidadosamente y muy detalladamente descrita por renskiy , en un artículo dedicado SOLO A ESTE TEMA (que me sorprendió).La reconstrucción automática de la imagen original de Docker y la instalación de varios scripts para cerrar broches y limpiar complementos no utilizados se describen en docker-compose.yml, el repositorio de infraestructura . La frecuencia de limpieza se establece en el archivo killcron del mismo repositorio.WebRTC
A pesar de que ya hemos establecido la hora correcta, y el tráfico de nuestro navegador pasa por un proxy, aún podemos ser detectados.Además de la diferencia horaria (navegador y dirección IP), hay dos fuentes más de desanonimización de "sentarse detrás de un proxy". Estas son tecnologías flash y WebRTC integradas en el navegador. Flash está deshabilitado en nuestro navegador , WebRTC no.La razón de ambas posibilidades de falla es la misma: los paquetes UDP ubicuos y ágiles . Para WebRTC, estos son dos puertos: 3478 y 19302 .Para detener el éxodo de exploradores desde el contenedor de Chrome, la regla de iptables se aplica en la máquina host con los contenedores de infraestructura: iptables -t raw -I PREROUTING -p udp -m multiport --dports 3478,19302 -j DROP
El mismo proxyHelper implementa esta tarea.El resto de los trabajadores
Para lograr el objetivo con éxito: la implementación de un "clic" en el sitio de destino a través de un proxy anónimo, necesitamos un trabajador más.Será una versión truncada de whoerChecker . Creo que hacerlo solo, usando todo lo escrito, no será difícil.El resultado de todo el proceso, que cae en la cola localizada , contiene datos sobre el "grado" de anonimato de cada dirección de servidor proxy que se ha verificado.Cuando se "juega" contra los contadores, lo más importante para recordar es el anonimato y no dejarse llevar por las visitas robóticas. El cumplimiento del principio de "no te dejes llevar por los clics" está garantizado por la posibilidad de organizar acciones en un horario, que está integrado en esbTask ( desde el campo de nuestro sobre ESB ).Si intenta hacer todo con cuidado, la métrica yandex del sitio de destino será similar a la figura a continuación.
Cómo poner todo junto
Entonces, dado:- utilidades que pueden aceptar "como entrada" (como argumento de línea de comando) esbTask en forma de cadena json y ejecutar algo de lógica y enviar los resultados a beanstalkd ;
- Message Queue Server ( MQ ), basado en beanstalkd ;
- Máquina Linux (máquina de proceso);
Con este "Dado", usualmente uso libevent y React PHP . Todo esto, complementado por varias herramientas, le permite controlar el número (dentro de los límites especificados) de instancias de controlador para cada etapa del proceso automáticamente.Sin embargo, dado el tamaño del artículo y los detalles del tema, estaré encantado de describir todo esto en un artículo separado. Este artículo es tecnología noserver . El futuro es " servidor ".La fecha de su publicación está relacionada con su interés, Estimado lector.. , ,… . , , , , , .
habr , . , , .
. , " server ", README.md .
En " noserver ", una instancia procesará una cola (un paso de proceso). Este enfoque solo puede enojar a los espíritus que uso cuando depuro a los trabajadores.Dependiendo de la velocidad de procesamiento que necesite, puede iniciar tantas copias como desee "manualmente".Puede verse así:
El extraño comienzo del trabajador es sorprendente ... A pesar del hecho de que cada uno de los trabajadores es un objeto PHP, usé exec (...) .Esto se hizo para ahorrar tiempo, a fin de no crear trabajadores separados para " noserver " o no cambiar el trabajador con el fin de comenzar en modo " servidor ".Algunas palabras sobre configuración e implementación
Constantes de configuración
El archivo de configuración para su instancia es app / settings.php . Debe ser creado por usted inmediatamente después de clonar el repositorio. Para hacer esto, cambie el nombre del archivo app / settings.php.dist . Todas las constantes se describen internamente.app / settings.php , entre otras cosas, incluye archivos con otras constantes.- app / queues.php contiene los nombres de colas y trabajos
- app / plugs.php contiene una descripción de los complementos de Chrome
- app / techs.php contiene constantes calculadas
Utilidades
Para la conveniencia de procesar los resultados del proceso y colocar tareas, existen varias utilidades. Las utilidades se inician desde la línea de comandos. Proporcionado con descripciones de argumentos. Ubicado: app / src / Utils . backup.php: guarda las colas en un archivo
clear.php - limpia colas
exporter.php: exporta desde un archivo con una cola guardada
Dirección de pares: puerto
givethejob.php - publica tareas en el proceso
(fuente - dirección: cuadro combinado de puerto).
puede excluir algunas direcciones de la lista
restore.php - restaura una cola guardada
Afinando a los trabajadores
Al usar trabajadores escritos, puede ser conveniente usar las siguientes opciones de configuración:
Despliegue
El manual asume que tiene 2 máquinas a su disposición con Ubuntu 18.04 instalado .Uno para la infraestructura ( acoplador ), el otro para el control del proceso ( proceso ).acoplador
proceso
Espera, observa lo que sucede a través del panel web (http: // ip-address-docker-machines: 8080).El resultado estará disponible en la cola localizada .Y en conclusión
Sorprendentemente, escribir y editar este artículo tomó más tiempo que escribir el código en sí.En mi opinión, todo podría ser al revés (y la diferencia horaria podría ser varias veces mayor), si no fuera por dos ideologías: Message Queue y Enterprise Service Bus .Estaré muy contento si encuentra útil el enfoque presentado para escribir aplicaciones, cuya carga en diferentes partes no está clara en la etapa de diseño.Gracias