Entrada
Como parte del programa de préstamos, el banco coopera con muchas tiendas minoristas.
Uno de los elementos clave de una solicitud de préstamo es una fotografía del prestatario: un agente de la tienda asociada fotografía al comprador; dicha fotografía se incluye en el "archivo personal" del cliente y se utiliza en el futuro como una de las formas de confirmar su presencia en el momento de solicitar un préstamo.
Desafortunadamente, siempre existe el riesgo de un comportamiento deshonesto de un agente que puede transferir fotos inexactas al banco, por ejemplo, fotos de clientes de redes sociales o pasaportes.
Por lo general, los bancos resuelven este problema verificando la foto: los empleados de la oficina miran fotos e intentan identificar imágenes inexactas.
Queríamos intentar automatizar el proceso y resolver el problema utilizando redes neuronales.
Formalización de tareas
Examinamos solo fotografías en las que hay personas. Las imágenes sin rostro se pueden
cortar con la biblioteca abierta
Dlib .
Para mayor claridad, damos ejemplos de fotografías (se muestran los empleados del banco):
 Fig. 1. Fotos del punto de venta.
Fig. 1. Fotos del punto de venta. Fig. 2. Fotos de las redes sociales.
Fig. 2. Fotos de las redes sociales. Fig 3. Foto del pasaporte
Fig 3. Foto del pasaporteEntonces, necesitábamos escribir un modelo que analizara el fondo de la fotografía. El resultado de su trabajo fue determinar la probabilidad de que la foto fuera tomada en uno de los puntos de venta de nuestros socios. Identificamos tres formas de resolver este problema: segmentación, comparación con otras fotos en el mismo punto de venta, clasificación. Consideremos cada uno de ellos con más detalle.
A) segmentación
Lo primero que se me ocurrió fue resolver este problema segmentando la imagen, identificando áreas con el fondo de las tiendas asociadas.
Contras:
- La preparación de la muestra de entrenamiento lleva demasiado tiempo.
- Un servicio construido en este modelo no funcionará rápidamente.
Se decidió volver a este método solo en caso de abandono de opciones alternativas. Spoiler: no regresó.
B) Comparación con otras fotos en el mismo punto de venta.
Junto con la foto, recibimos información sobre en qué tienda minorista en particular se realizó. Es decir, tenemos grupos de fotos tomadas en los mismos puntos de venta. El número total de fotos en cada grupo varía desde unas pocas unidades hasta varios miles.
Otra idea surgió: construir un modelo que comparara dos fotografías y predeciera la probabilidad de que fueran tomadas en un punto de venta. Luego podemos comparar la foto recién recibida con las fotos existentes en la misma tienda. Si resulta ser similar a ellos, entonces la imagen es definitivamente confiable. Si la imagen queda fuera de la imagen, también la enviamos para verificación manual.
Contras:
- Muestreo desequilibrado.
- El servicio funcionará durante mucho tiempo si hay muchas fotos en el punto de venta.
- Cuando aparece un nuevo punto de venta, debe volver a capacitar al modelo.
A pesar de las desventajas, implementamos el modelo del
artículo utilizando los bloques de redes neuronales VGG-16 y ResNet-50. Y ... recibieron un porcentaje de respuestas correctas no muy superior al 50% en ambos casos :(
B) Clasificación!
La idea más tentadora era hacer un clasificador simple que dividiera las fotos en 3 grupos: fotos de puntos de venta, pasaportes y redes sociales. Solo queda verificar si este enfoque funciona. Bueno, también pasa algo de tiempo preparando los datos para el entrenamiento.
Preparación de datos
En el conjunto de datos de imágenes de las redes sociales que usan la biblioteca Dlib, solo se seleccionaron aquellas fotos que tienen personas.
Las fotografías del pasaporte tuvieron que recortarse de manera diferente, dejando solo la cara. Aquí nuevamente Dlib vino al rescate. El principio del trabajo resultó así: al usar la biblioteca se encontraron las coordenadas de la cara -> se cortó la foto del pasaporte, dejando la cara.
En cada una de las 3 clases salieron 40,000 fotos. No te olvides del
aumento de datosModelo
ResNet-50 usado. Resolvieron el problema como un problema de clasificación multiclase con clases disjuntas. Es decir, se creía que una foto solo podía pertenecer a una clase.
model = keras.applications.resnet50.ResNet50() model.layers.pop() for layer in model.layers: layer.trainable=True last = model.layers[-1].output x = Dense(3, activation="softmax")(last) resnet50_1 = Model(model.input, x) resnet50_1.compile(optimizer=Adam(lr=0.00001), loss='categorical_crossentropy', metrics=[ 'accuracy'])
Resultados
En la muestra de prueba, quedaron 24,000 imágenes, es decir, 20%. La matriz de error fue la siguiente:
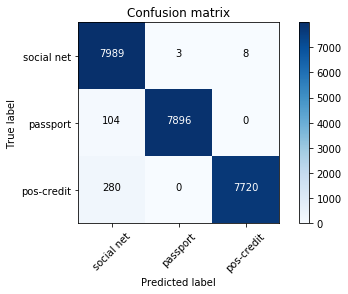
red social - redes sociales;
pasaporte - pasaportes;
poscrédito: puntos de venta, socios que otorgan préstamos.
El porcentaje total de errores es 1.6%, para fotos desde puntos de venta - 1.2%. La mayoría de las imágenes erróneamente definidas son imágenes similares a dos clases al mismo tiempo. Por ejemplo, casi todas las fotos incorrectamente definidas de la clase poscrédito se tomaron desde ángulos fallidos (contra la pared blanca, solo se ve la cara). Por lo tanto, también eran similares a las fotos de la clase de red social. Dichas fotografías tenían una baja probabilidad máxima.
Hemos agregado un umbral para la máxima probabilidad. Si el valor final es más alto, confiamos en el clasificador, más bajo, enviamos la imagen para verificación manual.
Como resultado, el resultado del servicio de fotografía.

se ve así:
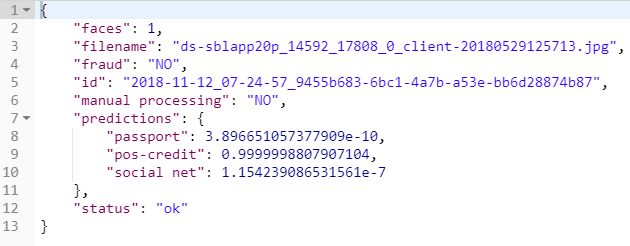
Resumen
Entonces, usando un modelo simple, aprendimos cómo determinar automáticamente que se tomó una fotografía en uno de los puntos de venta de nuestros socios. Esto nos permitió automatizar parte del gran proceso de aprobación de una solicitud de préstamo.