GitHub usa MySQL como su almacén de datos primario para todo lo que no está relacionado con git , por lo que la disponibilidad de MySQL es clave para el funcionamiento normal de GitHub. El sitio en sí, la API de GitHub, el sistema de autenticación y muchas otras características requieren acceso a bases de datos. Utilizamos varios clústeres de MySQL para manejar diversos servicios y tareas. Se configuran según el esquema clásico con un nodo principal disponible para grabación y sus réplicas. Las réplicas (otros nodos del clúster) reproducen asincrónicamente los cambios en el nodo principal y proporcionan acceso de lectura.
La disponibilidad de los sitios host es crítica. Sin el nodo principal, el clúster no admite grabación, lo que significa que no puede guardar los cambios necesarios. Arreglar transacciones, registrar problemas, crear nuevos usuarios, repositorios, revisiones y mucho más será simplemente imposible.
Para admitir la grabación, se requiere un nodo accesible correspondiente: el nodo principal en el clúster. Sin embargo, la capacidad de identificar o detectar dicho nodo es igualmente importante.
En caso de falla del nodo principal actual, es importante asegurar la aparición inmediata de un nuevo servidor para reemplazarlo, así como para poder notificar rápidamente a todos los servicios sobre este cambio. El tiempo de inactividad total consiste en el tiempo necesario para detectar una falla, conmutar por error y notificar sobre un nuevo nodo principal.

Esta publicación describe una solución para garantizar la alta disponibilidad de MySQL en GitHub y descubrir el servicio principal, que nos permite realizar operaciones de manera confiable que abarcan varios centros de datos, mantener la operatividad cuando algunos de estos centros no están disponibles y garantizar un tiempo de inactividad mínimo en caso de falla.
Objetivos de alta disponibilidad
La solución descrita en este artículo es una versión nueva y mejorada de soluciones anteriores de alta disponibilidad (HA) implementadas en GitHub. A medida que crecemos, necesitamos adaptar la estrategia de MySQL HA para cambiar. Nos esforzamos por seguir enfoques similares para MySQL y otros servicios en GitHub.
Para encontrar la solución adecuada para la alta disponibilidad y el descubrimiento de servicios, primero debe responder algunas preguntas específicas. Aquí hay una lista de muestra de ellos:
- ¿Qué tiempo de inactividad máximo no es crítico para usted?
- ¿Qué tan confiables son las herramientas de detección de fallas? ¿Son críticos para usted los falsos positivos (procesamiento de falla prematura)?
- ¿Qué tan confiable es el sistema de failover? ¿Dónde puede ocurrir una falla?
- ¿Qué tan efectiva es la solución en múltiples centros de datos? ¿Qué tan efectiva es la solución en redes de baja y alta latencia?
- ¿La solución continuará funcionando en caso de falla completa del centro de datos (DPC) o aislamiento de la red?
- ¿Qué mecanismo (si lo hay) previene o mitiga las consecuencias de la aparición de dos servidores principales en el clúster que graban de forma independiente?
- ¿La pérdida de datos es crítica para usted? Si es así, ¿en qué medida?
Para demostrarlo, consideremos primero la solución anterior y discutamos por qué decidimos abandonarla.
Negativa a usar VIP y DNS para el descubrimiento
Como parte de la solución anterior, utilizamos:
- orquestador para detección de fallas y failover;
- VIP y DNS para descubrimiento de host.
En ese caso, los clientes descubrieron un nodo de grabación por su nombre, por ejemplo, mysql-writer-1.github.net . El nombre se usó para determinar la dirección IP virtual (VIP) del nodo principal.
Por lo tanto, en una situación normal, los clientes simplemente tenían que resolver el nombre y conectarse a la dirección IP recibida, donde el nodo principal ya los estaba esperando.
Considere la siguiente topología de replicación que abarca tres centros de datos diferentes:
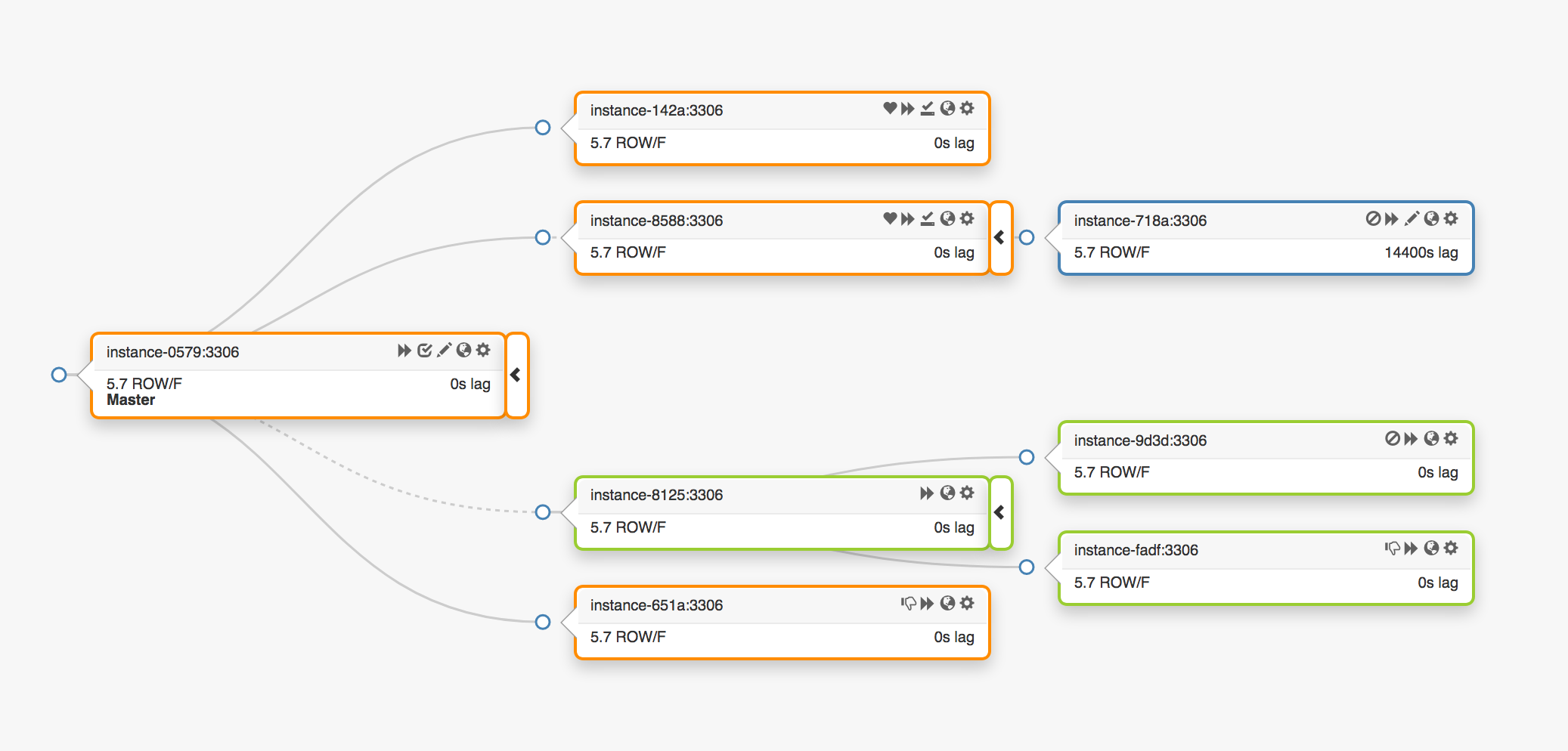
En el caso de una falla del nodo principal, se debe asignar un nuevo servidor a su lugar (una de las réplicas).
orchestrator detecta una falla, selecciona un nuevo nodo maestro y luego asigna el nombre / VIP. Los clientes en realidad no conocen la identidad del nodo principal, solo conocen el nombre, que ahora debería apuntar al nuevo nodo. Sin embargo, presta atención a esto.
Las direcciones VIP son compartidas, los servidores de bases de datos las solicitan y poseen. Para recibir o liberar un VIP, el servidor debe enviar una solicitud ARP. El servidor que posee el VIP primero debe liberarlo antes de que el nuevo maestro pueda acceder a esta dirección. Este enfoque lleva a algunas consecuencias indeseables:
- En modo normal, el sistema de conmutación por error primero se pondrá en contacto con el nodo principal fallido y le solicitará que libere el VIP, y luego recurrirá al nuevo servidor principal con una solicitud de asignación de VIP. Pero, ¿qué hacer si el primer nodo principal no está disponible o rechaza una solicitud para liberar la dirección VIP? Dado que el servidor se encuentra actualmente en un estado de falla, es poco probable que pueda responder a una solicitud a tiempo o responderla en absoluto.
- Como resultado, puede surgir una situación cuando dos anfitriones reclaman sus derechos al mismo VIP. Diferentes clientes pueden conectarse a cualquiera de estos servidores dependiendo de la ruta de red más corta.
- El funcionamiento correcto en esta situación depende de la interacción de dos servidores independientes, y dicha configuración no es confiable.
- Incluso si el primer nodo principal responde a las solicitudes, desperdiciamos un tiempo valioso: el cambio al nuevo servidor principal no ocurre mientras contactamos con el anterior.
- Además, incluso en el caso de la reasignación de VIP, no hay garantía de que las conexiones de clientes existentes en el servidor anterior se desconecten. Nuevamente, corremos el riesgo de estar en una situación con dos nodos principales independientes.
Aquí y allá, dentro de nuestro entorno, las direcciones VIP están asociadas con una ubicación física. Se asignan a un conmutador o enrutador. Por lo tanto, podemos reasignar una dirección VIP solo a un servidor ubicado en el mismo entorno que el host original. En particular, en algunos casos, no podremos asignar un servidor VIP en otro centro de datos y necesitaremos realizar cambios en el DNS.
- La distribución de cambios al DNS lleva más tiempo. Los clientes almacenan nombres DNS por un período de tiempo predefinido. La conmutación por error que involucra múltiples centros de datos implica un mayor tiempo de inactividad, ya que lleva más tiempo proporcionar a todos los clientes información sobre el nuevo nodo principal.
Estas restricciones fueron suficientes para obligarnos a comenzar la búsqueda de una nueva solución, pero también tuvimos que tener en cuenta lo siguiente:
- Los nodos principales transmitieron independientemente paquetes de pulsos a través del servicio
pt-heartbeat para medir el retraso y la regulación de la carga . El servicio tuvo que ser transferido al nodo principal recién designado. Si es posible, debería haberse desactivado en el servidor anterior. - Del mismo modo, los nodos principales controlaban independientemente el funcionamiento del Pseudo-GTID . Era necesario comenzar este proceso en el nuevo nodo principal y preferiblemente detenerse en el antiguo.
- El nuevo nodo maestro se puede escribir. El nodo anterior (si es posible) debería tener
read_only (solo lectura).
Estos pasos adicionales llevaron a un aumento en el tiempo de inactividad general y agregaron sus propios puntos de falla y problemas.
La solución funcionó y GitHub manejó con éxito las fallas de MySQL en segundo plano, pero queríamos mejorar nuestro enfoque de HA de la siguiente manera:
- garantizar la independencia de centros de datos específicos;
- garantizar la operatividad en caso de fallas del centro de datos;
- Abandonar flujos de trabajo colaborativos poco confiables
- reducir el tiempo de inactividad total;
- Realice, en la medida de lo posible, la conmutación por error sin pérdida.
Solución GitHub HA: orquestador, cónsul, GLB
Nuestra nueva estrategia, junto con las mejoras que la acompañan, elimina la mayoría de los problemas mencionados anteriormente o mitiga sus consecuencias. Nuestro sistema HA actual consta de los siguientes elementos:
- orquestador para detección de fallas y failover. Utilizamos el esquema orquestador / balsa con varios centros de datos, como se muestra en la figura siguiente;
- Cónsul Hashicorp para descubrimiento de servicio;
- GLB / HAProxy como capa proxy entre clientes y nodos de grabación. El código fuente para el Director GLB está abierto;
- Tecnología
anycast para enrutamiento de red.
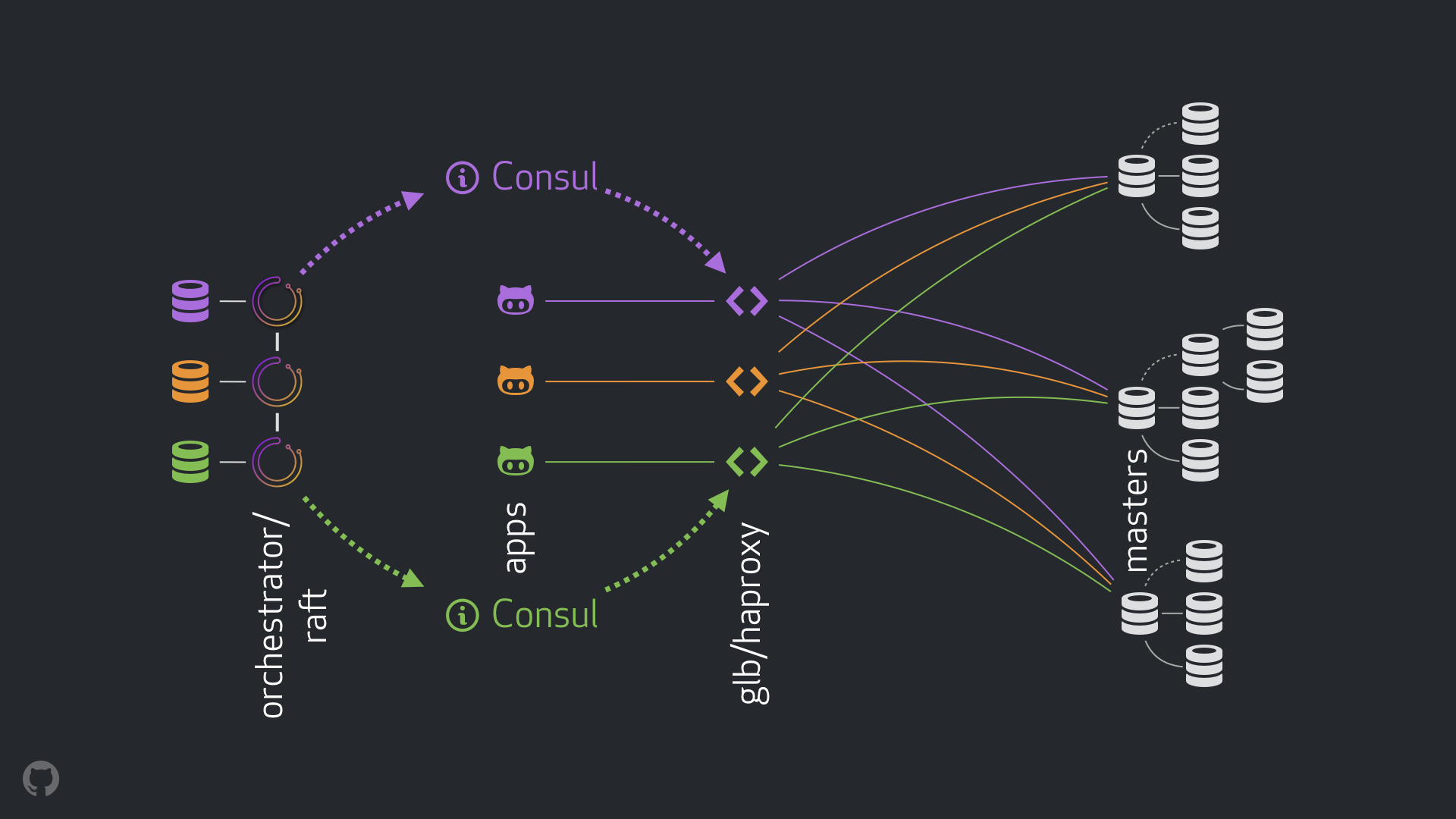
El nuevo esquema permitió abandonar por completo la realización de cambios en el VIP y DNS. Ahora, al introducir nuevos componentes, podemos separarlos y simplificar la tarea. Además, tuvimos la oportunidad de utilizar soluciones confiables y estables. A continuación se ofrece un análisis detallado de la nueva solución.
Flujo normal
En una situación normal, las aplicaciones se conectan a los nodos de grabación a través de GLB / HAProxy.
Las aplicaciones no reciben la identidad del servidor principal. Como antes, usan solo el nombre. Por ejemplo, el nodo principal para mysql-writer-1.github.net sería mysql-writer-1.github.net . Sin embargo, en nuestra configuración actual, este nombre se resuelve en la dirección IP anycast .
Gracias a la tecnología anycast , el nombre se resuelve en la misma dirección IP en cualquier lugar, pero el tráfico se dirige de manera diferente, dada la ubicación del cliente. En particular, varias instancias de GLB, nuestro equilibrador de carga altamente disponible, se implementan en cada uno de nuestros centros de datos. El tráfico en mysql-writer-1.github.net siempre se enruta al clúster GLB del centro de datos local. Debido a esto, todos los clientes son atendidos por representantes locales.
Ejecutamos GLB sobre HAProxy . Nuestro servidor HAProxy proporciona grupos de escritura : uno para cada clúster MySQL. Además, cada grupo tiene solo un servidor (el nodo principal del clúster). Todas las instancias GLB / HAProxy en todos los centros de datos tienen los mismos grupos, y todas apuntan a los mismos servidores en estos grupos. Por lo tanto, si la aplicación desea escribir datos en la base de datos en mysql-writer-1.github.net , no importa a qué servidor GLB se conecte. En cualquier caso, se realizará una redirección al nodo de clúster principal real cluster1 .
Para las aplicaciones, el descubrimiento finaliza en GLB, y el redescubrimiento no es necesario. Ese GLB redirige el tráfico al lugar correcto.
¿De dónde obtiene el GLB información sobre qué servidores enumerar? ¿Cómo hacemos cambios al GLB?
Descubrimiento a través del cónsul
El servicio Cónsul es ampliamente conocido como una solución de descubrimiento de servicios, y también asume funciones de DNS. Sin embargo, en nuestro caso, lo usamos como un almacenamiento altamente accesible de valores clave (KV).
En el repositorio de KV en Consul, registramos la identidad de los nodos principales del clúster. Para cada clúster, hay un conjunto de registros KV que apuntan a los datos del nodo principal correspondiente: sus fqdn , port, ipv4 e ipv6.
Cada nodo GLB / HAProxy lanza una plantilla de cónsul , un servicio que rastrea los cambios en los datos de Consul (en nuestro caso, cambios en los datos de los nodos principales). El servicio de consul-template crea un archivo de configuración y puede volver a cargar HAProxy al cambiar la configuración.
Debido a esto, la información sobre cómo cambiar la identidad del nodo principal en Consul está disponible para cada instancia de GLB / HAProxy. En función de esta información, se realiza la configuración de las instancias, los nuevos nodos principales se indican como la única entidad en el grupo de servidores del clúster. Después de eso, las instancias se vuelven a cargar para que los cambios surtan efecto.
Hemos implementado instancias de Consul en cada centro de datos, y cada instancia proporciona alta disponibilidad. Sin embargo, estas instancias son independientes entre sí. No se replican ni intercambian ningún dato.
¿Dónde obtiene Consul información sobre los cambios y cómo se distribuye entre los centros de datos?
orquestador / balsa
Utilizamos el esquema orchestrator/raft : los nodos del orchestrator comunican entre sí a través del consenso de la balsa . En cada centro de datos, tenemos uno o dos nodos de orchestrator .
orchestrator es responsable de detectar fallas, conmutación por error de MySQL y transferir los datos del nodo maestro modificado a Consul. La conmutación por error es administrada por un único orchestrator/raft host de orchestrator/raft , pero los cambios , noticias de que el clúster ahora es un nuevo maestro, se propagan a todos los nodos del orchestrator utilizando el mecanismo de raft .
Cuando los nodos del orchestrator reciben noticias sobre un cambio en los datos del nodo principal, cada uno de ellos contacta con su propia instancia local de Cónsul e inicia una grabación KV. Los centros de datos con múltiples instancias de orchestrator recibirán varios registros (idénticos) en el Cónsul.
Vista generalizada de toda la transmisión.
Si el nodo maestro falla:
orchestrator nodos del orchestrator detectan fallas;orchestrator/raft maestro de orchestrator/raft inicia la recuperación. Se asigna un nuevo nodo maestro;- el esquema de
orchestrator/raft transfiere los datos sobre el cambio del nodo principal a todos los nodos del grupo de raft - cada instancia de
orchestrator/raft recibe una notificación sobre un cambio de nodo y escribe la identidad de un nuevo nodo maestro en el almacenamiento KV local en Consul; - en cada instancia de GLB / HAProxy, se inicia el servicio de
consul-template , que monitorea los cambios en el repositorio de KV en Consul, reconfigura y reinicia HAProxy; - El tráfico del cliente se redirige al nuevo nodo maestro.
Para cada componente, las responsabilidades están claramente distribuidas y toda la estructura está diversificada y simplificada. orchestrator no interactúa con los equilibradores de carga. El cónsul no requiere información sobre el origen de la información. Los servidores proxy solo funcionan con Consul. Los clientes solo trabajan con servidores proxy.
Por otra parte:
- No es necesario realizar cambios en el DNS y difundir información sobre ellos;
- TTL no se utiliza;
- el hilo no espera respuestas del host en un estado de error. En general, se ignora.
Para estabilizar el flujo, también aplicamos los siguientes métodos:
- El parámetro HAProxy
hard-stop-after se establece en un valor muy pequeño. Cuando HAProxy se reinicia con el nuevo servidor en el grupo de escritura, el servidor termina automáticamente todas las conexiones existentes al antiguo nodo maestro.
- Establecer el parámetro
hard-stop-after permite no esperar ninguna acción de los clientes, además, las consecuencias negativas de la posible aparición de dos nodos principales en el clúster se minimizan. Es importante entender que no hay magia aquí, y en cualquier caso, pasa algún tiempo antes de que se rompan los viejos lazos. Pero hay un punto en el tiempo después del cual podemos dejar de esperar sorpresas desagradables.
- No requerimos la disponibilidad continua del servicio de Cónsul. De hecho, necesitamos que esté disponible solo durante la conmutación por error. Si el servicio de Cónsul no responde, GLB continúa trabajando con los últimos valores conocidos y no toma medidas drásticas.
- El GLB está configurado para verificar la identidad del nodo maestro recién asignado. Al igual que con nuestros grupos de MySQL sensibles al contexto , se realiza una verificación para confirmar que el servidor se puede escribir. Si eliminamos accidentalmente la identidad del nodo principal en Consul, entonces no habrá problemas, se ignorará un registro vacío. Si escribimos por error el nombre de otro servidor (no el principal) al Cónsul, entonces en este caso está bien: GLB no lo actualizará y continuará trabajando con el último estado válido.
En las siguientes secciones, analizamos los problemas y analizamos los objetivos de alta disponibilidad.
Detección de choque con orquestador / balsa
orchestrator adopta un enfoque integral para la detección de fallas, lo que garantiza una alta confiabilidad de la herramienta. No encontramos resultados falsos positivos, no se realizan fallas prematuras, lo que significa que se excluye el tiempo de inactividad innecesario.
El circuito del orchestrator/raft también hace frente a situaciones de aislamiento completo de la red del centro de datos (cercado del centro de datos). El aislamiento de la red del centro de datos puede causar confusión: los servidores dentro del centro de datos pueden comunicarse entre sí. ¿Cómo entender quién está realmente aislado: servidores dentro de un centro de datos dado o todos los demás centros de datos?
En el esquema de orchestrator/raft , el maestro de orchestrator/raft es conmutación por error. El nodo se convierte en el líder, que recibe el apoyo de la mayoría del grupo (quórum). Hemos implementado el nodo del orchestrator de tal manera que ningún centro de datos único puede proporcionar la mayoría, mientras que cualquier centro de datos n-1 puede proporcionarlo.
En el caso del aislamiento completo de la red del centro de datos, los nodos del orchestrator en este centro están desconectados de nodos similares en otros centros de datos. Como resultado, los nodos del orchestrator en un centro de datos aislado no pueden convertirse en líderes en un grupo de raft . Si tal nodo era el maestro, entonces pierde este estado. A un nuevo host se le asignará uno de los nodos de los otros centros de datos. Este líder tendrá el apoyo de todos los demás centros de datos que pueden interactuar entre sí.
De esta manera, el maestro del orchestrator siempre estará fuera del centro de datos aislado de la red. Si el nodo maestro estaba ubicado en un centro de datos aislado, el orchestrator inicia una conmutación por error para reemplazarlo con el servidor de uno de los centros de datos disponibles. Mitigamos el impacto del aislamiento del centro de datos delegando decisiones al quórum de centros de datos disponibles.
Notificación más rápida
El tiempo de inactividad total se puede reducir aún más acelerando la notificación de un cambio en el nodo principal. ¿Cómo lograr esto?
Cuando el orchestrator inicia la conmutación por error, considera un grupo de servidores, uno de los cuales puede asignarse como el principal. Dadas las reglas de replicación, las recomendaciones y las limitaciones, puede tomar una decisión informada sobre el mejor curso de acción.
De acuerdo con los siguientes signos, también puede entender que un servidor accesible es un candidato ideal para ser nombrado como el principal:
- nada impide que el servidor se eleve (y tal vez el usuario recomienda este servidor);
- se espera que el servidor pueda usar todos los demás servidores como réplicas.
En este caso, el orchestrator primero configura el servidor como grabable e inmediatamente anuncia un aumento en su estado (en nuestro caso, escribe el registro en el repositorio KV en Consul). orchestrator , .
, , GLB , , . : !
MySQL , . : , , , .
, . , , . , , , .
: 500 . . ( ), .
( ) . , .
, . , , . , , , .
, / pt-heartbeat / , . , pt-heartbeat , read_only , .
pt-heartbeat , . . . , pt-heartbeat .
orchestrator
orchestrator :
- Pseudo-GTID;
- , ;
- (
read_only ), .
, . , , , . orchestrator .
- , , . , -, .
, .
, , , - . . STONITH . , , , «» - . , , .
: Consul , . . , , , , .
orchestrator/GLB/Consul :
- ;
- ;
- ;
- ;
- , ( );
- ;
10-13 .
20 , — 25 .
Conclusión
«// » , , . . , .