El 1 de noviembre de 2017, me convertí en el líder del equipo de desarrollo en el departamento de desarrollo de software de Timeweb. Y el 12 de noviembre de 2018, el jefe del departamento preguntó cuándo estaría listo el artículo para Habrahabr, porque el departamento de marketing preguntó, los voluntarios habían terminado y el plan de contenido requería algo más)
Por lo tanto, quiero dar una retrospectiva de cómo los procesos de desarrollo, prueba y entrega de nuestros productos han cambiado durante el año pasado. Sobre procesos y herramientas heredados, docker, gitlab y cómo nos estamos desarrollando.
Timeweb Hoster existe desde 2006. Todo este tiempo, la compañía invierte mucho esfuerzo para proporcionar a los clientes un servicio único y conveniente que lo distinga de los competidores. Timeweb tiene sus propias aplicaciones móviles, una interfaz de correo electrónico basada en la web, paneles de control de alojamiento virtual, VDS, un programa de afiliación, sus herramientas de soporte y mucho más.
Hay alrededor de 250 proyectos en nuestro gitlab: estas son aplicaciones de cliente, herramientas internas, bibliotecas, repositorios de configuración. Decenas de ellos se desarrollan y apoyan activamente: se comprometen durante la semana laboral, los prueban, recopilan y liberan.
Además de la gran cantidad de código heredado, todo esto trae consigo un número apropiado de procesos heredados y herramientas relacionadas. Como cualquier legado, también necesitan ser mantenidos, optimizados, refactorizados y algunas veces reemplazados.
De toda esta abundancia de proyectos, los paneles de control son los más cercanos a los clientes de alojamiento. Y es precisamente en el proyecto del "Panel de control" donde a menudo realizamos varias mejoras de infraestructura y hacemos muchos esfuerzos para mantener la infraestructura conectada en forma. Difundir la experiencia adquirida y las prácticas gustadas a otros productos y sus equipos.
Sobre los diferentes cambios en las herramientas y procesos durante el año pasado, lo diré.
Vagabundo → docker-compose
El problema
El primer día hábil, intenté elevar los paneles de control localmente. En ese momento, había cinco aplicaciones web en un repositorio:
- PU virtual hosting 3.0,
- PU VDS 2.0,
- webmasters de PU,
- PERSONAL (herramienta compatible),
- Directrices (demostración de componentes front-end estandarizados).
Para ejecutar, localmente utiliza Vagrant. Vagabundo lanzó ansible. Para iniciarlo y configurarlo se necesitó la ayuda de colegas y aproximadamente un día de tiempo limpio. Tuve que instalar una versión especial de Virtual Box (hubo problemas en la versión estable actual), trabajar desde la consola dentro de la máquina virtual fue muy desconcertante: los comandos triviales como npm / composer install se ralentizaron significativamente.
El rendimiento de las propias aplicaciones en la máquina virtual estaba lejos de ser posible, dada la pila de tecnología utilizada y la potencia de la máquina. Sin mencionar que una máquina virtual es una máquina virtual y, por definición, ocupa una parte importante de los recursos de su PC.
Solución
El entorno de desarrollo local se ha reescrito para ejecutarse en contenedores acoplables. La contenedorización basada en docker es la solución más común para aislar el entorno de la aplicación en todas las etapas de su ciclo de vida. Por lo tanto, no hay alternativas especiales.
Conclusiones
De los profesionales:
- localmente, la aplicación se ha vuelto más receptiva, los contenedores requieren menos que las máquinas virtuales,
- el lanzamiento de una nueva instancia, como lo ha demostrado la práctica, lleva unos minutos y solo requiere un acoplador (-composición) no inferior a ciertas versiones. Después de la clonación, solo haz:
make install-dev make run-dev
Hubo algunos compromisos:
- Tuve que escribir enlaces de shell para comandos dockerizados (compositor, npm, etc.). Ellos, como docker-compose.yml, no son completamente multiplataforma en comparación con Vagrant. Por ejemplo, iniciar bajo Mac requiere esfuerzos adicionales, y bajo Windows probablemente será más fácil ejecutar una distribución con Docker en la máquina virtual de Linux. Pero este es un compromiso aceptable, ya que el equipo usa solo distribuciones basadas en Debian, esta es una limitación aceptable para el desarrollo comercial,
- para admitir hosts virtuales,
se lanza localmente un contenedor basado en
github.com/jwilder/nginx-proxy . No es una muleta, sino un software adicional, que a veces necesita ser recordado, aunque no causa problemas.
Sí, todos en el equipo tuvieron que darse cuenta al menos un poco de lo que es Docker. Aunque gracias a los scripts de shell y Makefile mencionados, los desarrolladores llevan a cabo el 95% de sus tareas sin pensar en contenedores, pero en un entorno idéntico garantizado.
newcp-dev → cp-stands
Estas frases extrañas son los nombres de máquinas con bancos de pruebas de paneles de control, nuevos y viejos, respectivamente.
El problema
Las recetas de Ansible se usaron exclusivamente dentro de Vagrant, por lo que no se logró la principal ventaja: las versiones de los paquetes en el producto y en los stands eran diferentes de las que trabajaban los desarrolladores.
La falta de coincidencia de las versiones de los paquetes de software del servidor en los soportes antiguos con lo que tenían los desarrolladores, condujo a problemas. La sincronización fue complicada por el hecho de que los administradores del sistema usan un sistema de administración de configuración diferente, y no es posible integrarlo con el repositorio de desarrolladores.
Solución
Después de la contenedorización, no fue difícil extender la configuración de compilación acoplable para su uso en bancos de prueba. Se creó una nueva máquina para desplegar stands en DOCKER_HOST.
Conclusiones
Los desarrolladores ahora confían en la relevancia de los entornos locales y de prueba.
TeamCity → gitlab-ci
Los problemas
La configuración del proyecto en TeamCity es un proceso minucioso y desagradecido. La configuración de CI se almacenó por separado del código, en xml, al que no se aplica el control de versiones normal, y una descripción general de los cambios. También experimentamos problemas con la estabilidad del proceso de compilación en los agentes de TeamCity.
Solución
Dado que gitlab ya se usaba como repositorio para repositorios, comenzar a usar su CI no solo era lógico, sino también fácil y agradable. Ahora toda la configuración de CI / CD está en el repositorio.
Resultado
Durante el año, casi todos los proyectos reunidos por TeamCity se trasladaron de forma segura a gitlab-ci. Tuvimos la oportunidad de implementar rápidamente una variedad de características para automatizar los procesos de CI / CD.
Las capturas de pantalla de las tuberías serán las más obvias:
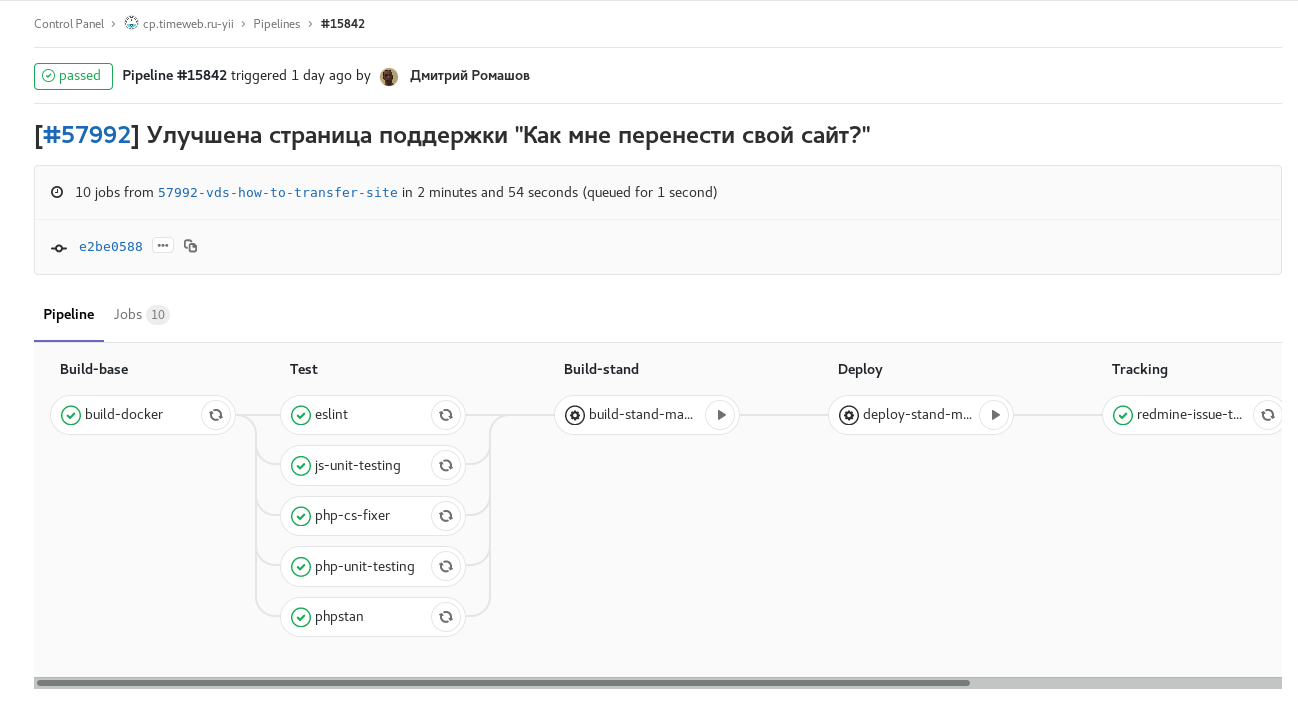 Fig. 1. característica-rama: se incluyen todas las comprobaciones y pruebas automáticas disponibles. Cuando se completa, envía un comentario con un enlace a la tubería a la tarea de minería. Tareas manuales para ensamblar y lanzar un stand con esta rama.
Fig. 1. característica-rama: se incluyen todas las comprobaciones y pruebas automáticas disponibles. Cuando se completa, envía un comentario con un enlace a la tubería a la tarea de minería. Tareas manuales para ensamblar y lanzar un stand con esta rama.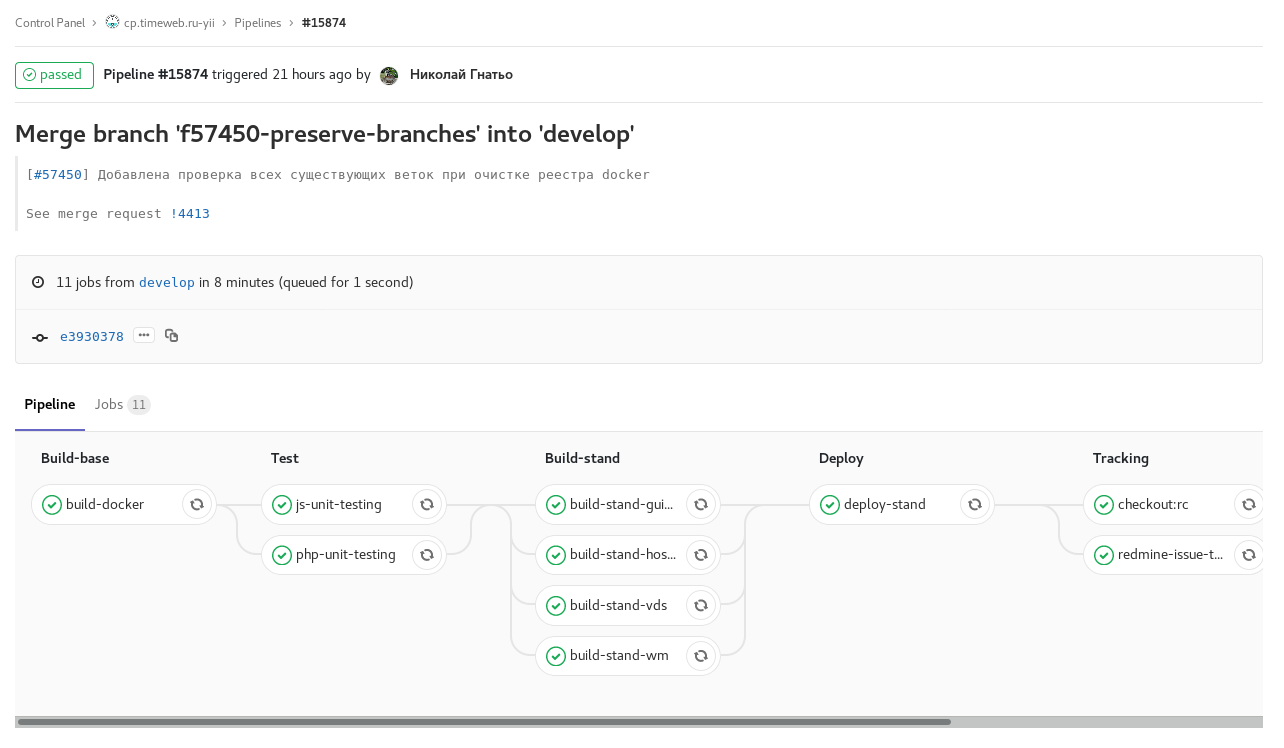 Fig. 2. Desarrolle la compilación programada con congelación de código (checkout: rc): desarrolle la compilación según lo programado con congelación de código. El ensamblaje de imágenes para los stands de paneles de control individuales ocurre en paralelo.
Fig. 2. Desarrolle la compilación programada con congelación de código (checkout: rc): desarrolle la compilación según lo programado con congelación de código. El ensamblaje de imágenes para los stands de paneles de control individuales ocurre en paralelo.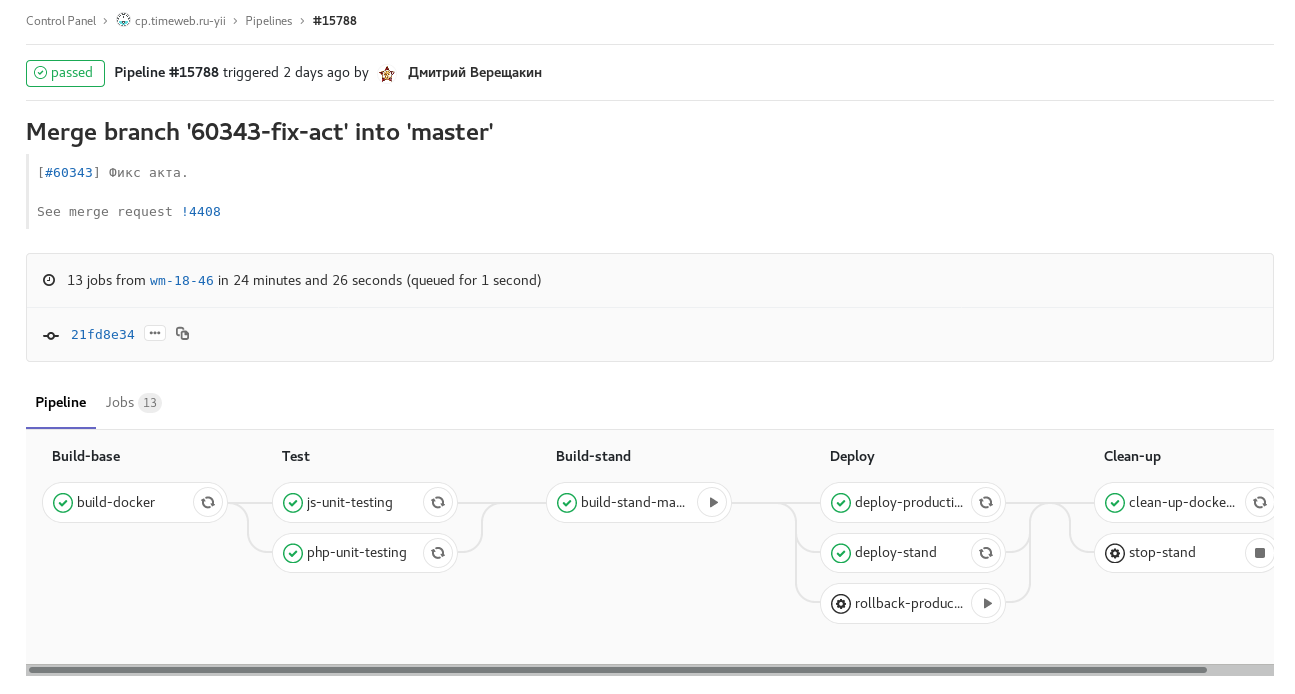 Fig. 3. etiqueta de tubería: liberación de uno de los paneles de control. Tarea manual para la liberación de reversión.
Fig. 3. etiqueta de tubería: liberación de uno de los paneles de control. Tarea manual para la liberación de reversión.Además, desde gitlab-ci hay un cambio de estado y el nombramiento de una persona en redmine en las etapas En progreso → Revisión → Control de calidad, notificación en Slack sobre lanzamientos y actualizaciones de etapas y retrocesos.
Esto es conveniente, pero no tomamos en cuenta un punto metodológico. Habiendo implementado dicha automatización en un proyecto, las personas se acostumbran rápidamente. Y en el caso de cambiar a otro proyecto donde todavía no existe, o el proceso es diferente, puede olvidarse de mover y reasignar la tarea en redmine o dejar un comentario con un enlace a Solicitud de fusión (que también hace gitlab-ci), obligando al espectador a buscar el deseado MR usted mismo. Al mismo tiempo, simplemente no desea copiar las piezas .gitlab-ci.yml y el código de shell que lo acompaña entre los proyectos, ya que debe admitir copiar y pegar.
Conclusión: la automatización es buena, pero cuando es igual a nivel de todos los equipos y proyectos, incluso mejor. Le agradecería al distinguido público las ideas sobre cómo organizar bellamente la reutilización de dicha configuración.
Duración de la tubería: 80 min. → 8 min.
Gradualmente, nuestro IC comenzó a tomar indecentemente mucho tiempo. Los probadores sufrieron mucho de esto: cada arreglo en master tuvo que esperar una hora para un lanzamiento. Se veía así:
 Fig. 4. tubería 80
Fig. 4. tubería 80 lvl min duración.Tuve que sumergirme en el análisis de lugares lentos durante varios días y buscar formas de acelerar mientras mantenía la funcionalidad.
Los lugares más largos en el proceso fueron la instalación de paquetes npm. Sin ningún problema, lo reemplazaron con hilo y lo guardaron en varios lugares hasta 7 minutos.
Rechazaron las actualizaciones automáticas, prefirieron el control manual del estado de este stand.
También agregamos varios corredores y dividimos en tareas paralelas el ensamblaje de las imágenes de la aplicación y todas las comprobaciones. Después de estas optimizaciones, la tubería de la rama principal con la actualización de todos los stands comenzó a tomar en la mayoría de los casos de 7 a 8 minutos.
Capistrano → desplegador
Para el despliegue en producción y en el soporte qa, se usó Capistrano (y continúa utilizándose en el momento de la redacción). El escenario principal de esta herramienta es: clonar el repositorio en el servidor de destino y realizar todas las tareas allí.
Anteriormente, el despliegue fue activado por manos de un ingeniero de control de calidad con las claves ssh necesarias de Vagrant. Luego, cuando Vagrant abandonó, Capistrano se mudó a un contenedor separado. Ahora el despliegue se realiza desde el contenedor con Capistrano con gitlab-runners, marcado con etiquetas especiales y con las claves necesarias, automáticamente cuando aparecen las etiquetas necesarias.
El problema aquí es que todo el proceso de compilación:
a) consume significativamente los recursos del servidor de combate (especialmente nodo / trago),
b) no hay manera de mantener actualizadas las versiones npm del compositor. nodo, etc.
Es más lógico construir en un servidor de compilación (en nuestro caso es gitlab-runner) y cargar artefactos listos en el servidor de destino. Esto salvará al servidor de batalla de las utilidades de ensamblaje y la responsabilidad extranjera.
Ahora consideramos el implementador como un reemplazo para capistrano (ya que no tenemos ningún rubista, ni tenemos el deseo de trabajar con su DSL) y planeamos transferir el ensamblaje al lado de gitlab. En algunos proyectos no críticos, ya logramos probarlo y hasta ahora estamos satisfechos: parece más fácil, no hemos encontrado ninguna restricción.
Gitflow: rc-sucursales → etiquetas
El desarrollo se lleva a cabo en ciclos semanales. En el transcurso de cinco días, se está desarrollando una nueva versión: el desarrollo acepta las mejoras y correcciones previstas para el lanzamiento la próxima semana. El viernes por la noche, el código se congela automáticamente. El lunes, comienza la prueba de la nueva versión, se realizan mejoras y, a mediados de la semana laboral, se produce un lanzamiento.
Anteriormente, utilizamos ramas con nombres de la forma rc18-47, lo que significa que el candidato de lanzamiento es la semana 47 de 2018. La congelación de código consistía en finalizar el desarrollo de la rama rc. Pero en octubre de este año, cambiamos a etiquetas. Las etiquetas se establecieron antes, pero después del hecho, después del lanzamiento y fusión de rc con master. Ahora, la aparición de la etiqueta conduce a una implementación automática, y la congelación es una combinación de desarrollo en maestro.
Así que nos deshicimos de entidades adicionales en git y variables en el proceso.
Ahora estamos "tirando" de proyectos rezagados en el proceso a un flujo de trabajo similar.
Conclusión
La automatización de los procesos, su optimización, así como el desarrollo, es una cuestión constante: mientras el producto se desarrolle activamente y el equipo esté trabajando, habrá tareas correspondientes. Aparecen nuevas ideas sobre cómo deshacerse de las acciones de rutina: las características se implementan en gitlab-ci.
A medida que las aplicaciones crecen, los procesos de CI comienzan a tomar un tiempo inaceptablemente largo: es hora de trabajar en su rendimiento. Dado que los enfoques y las herramientas se están volviendo obsoletos, debe tomarse el tiempo para refactorizarlos, revisarlos y actualizarlos.
