Hoy en los sitios extranjeros temáticos sobre Big Data puede encontrar una mención de una herramienta relativamente nueva para el ecosistema de Hadoop como Apache NiFi. Esta es una herramienta moderna de código abierto ETL. Arquitectura distribuida para una carga paralela rápida y procesamiento de datos, una gran cantidad de complementos para fuentes y transformaciones, el control de versiones de las configuraciones son solo una parte de sus ventajas. Con toda su potencia, NiFi sigue siendo bastante fácil de usar.
En Rostelecom nos esforzamos por desarrollar el trabajo con Hadoop, por lo que ya hemos probado y evaluado las ventajas de Apache NiFi en comparación con otras soluciones. En este artículo te contaré cómo nos atrajo esta herramienta y cómo la usamos.
Antecedentes
No hace mucho tiempo, nos enfrentamos con la elección de una solución para cargar datos de fuentes externas en un clúster de Hadoop. Durante mucho tiempo, utilizamos
Apache Flume para resolver tales problemas. No hubo quejas sobre Flume en general, excepto por algunos puntos que no nos convenían.
Lo primero que a nosotros, como administradores, no nos gustó fue que escribir la configuración de Flume para realizar la próxima descarga trivial no podía confiarse a un desarrollador o analista que no estuviera inmerso en las complejidades de esta herramienta. La conexión de cada nueva fuente requirió la intervención obligatoria del equipo de administración.
El segundo punto fue la tolerancia a fallas y la escala. Para descargas pesadas, por ejemplo, a través de syslog, fue necesario configurar varios agentes Flume y establecer un equilibrador frente a ellos. Todo esto tuvo que ser monitoreado y restaurado de alguna manera en caso de falla.
En tercer lugar , Flume no permitió descargar datos de varios DBMS y trabajar con algunos otros protocolos listos para usar. Por supuesto, en las vastas extensiones de la red, podría encontrar formas de hacer que Flume funcione con Oracle o SFTP, pero apoyar esas bicicletas no es nada agradable. Para cargar datos del mismo Oracle, tuvimos que usar otra herramienta:
Apache Sqoop .
Francamente, por mi naturaleza, soy una persona perezosa, y no quería apoyar el zoológico de soluciones en absoluto. Y no me gustó que todo este trabajo tuviera que hacerlo yo mismo.
Existen, por supuesto, soluciones bastante potentes en el mercado de herramientas ETL que pueden funcionar con Hadoop. Estos incluyen Informatica, IBM Datastage, SAS y Pentaho Data Integration. Estos son los que con mayor frecuencia se escuchan de los colegas en el taller y de aquellos que primero vienen a la mente. Por cierto, utilizamos IBM DataStage para ETL en soluciones de la clase Data Warehouse. Pero históricamente sucedió que nuestro equipo no pudo usar DataStage para descargas en Hadoop. Nuevamente, no necesitábamos todo el poder de las soluciones de este nivel para realizar conversiones y descargas de datos bastante simples. Lo que necesitábamos era una solución con una buena dinámica de desarrollo, capaz de trabajar con muchos protocolos y una interfaz conveniente e intuitiva que no solo un administrador que entendía todas sus sutilezas podía hacer frente, sino también un desarrollador con un analista, que a menudo son para nosotros. clientes de los datos en sí.
Como puede ver en el título, resolvimos los problemas anteriores con Apache NiFi.
¿Qué es Apache NiFi?
El nombre NiFi proviene de "Niagara Files". El proyecto fue desarrollado por la Agencia de Seguridad Nacional de EE. UU. Durante ocho años, y en noviembre de 2014 su código fuente fue abierto y transferido a la Apache Software Foundation como parte del
Programa de Transferencia de Tecnología de la
NSA .
NiFi es una herramienta ETL / ELT de código abierto que puede funcionar con muchos sistemas, y no solo con las clases Big Data y Data Warehouse. Estos son algunos de ellos: HDFS, Hive, HBase, Solr, Cassandra, MongoDB, ElastcSearch, Kafka, RabbitMQ, Syslog, HTTPS, SFTP. Puede ver la lista completa en la
documentación oficial.
El trabajo con un DBMS específico se implementa agregando el controlador JDBC apropiado. Hay una API para escribir su módulo como receptor adicional o convertidor de datos. Se pueden encontrar ejemplos
aquí y
aquí .
Características clave
NiFi utiliza una interfaz web para crear DataFlow. Un analista que recientemente comenzó a trabajar con Hadoop, un desarrollador y un administrador barbudo se encargarán de ello. Los dos últimos pueden interactuar no solo con “rectángulos y flechas”, sino también con la
API REST para recopilar estadísticas, monitorear y administrar los componentes de DataFlow.
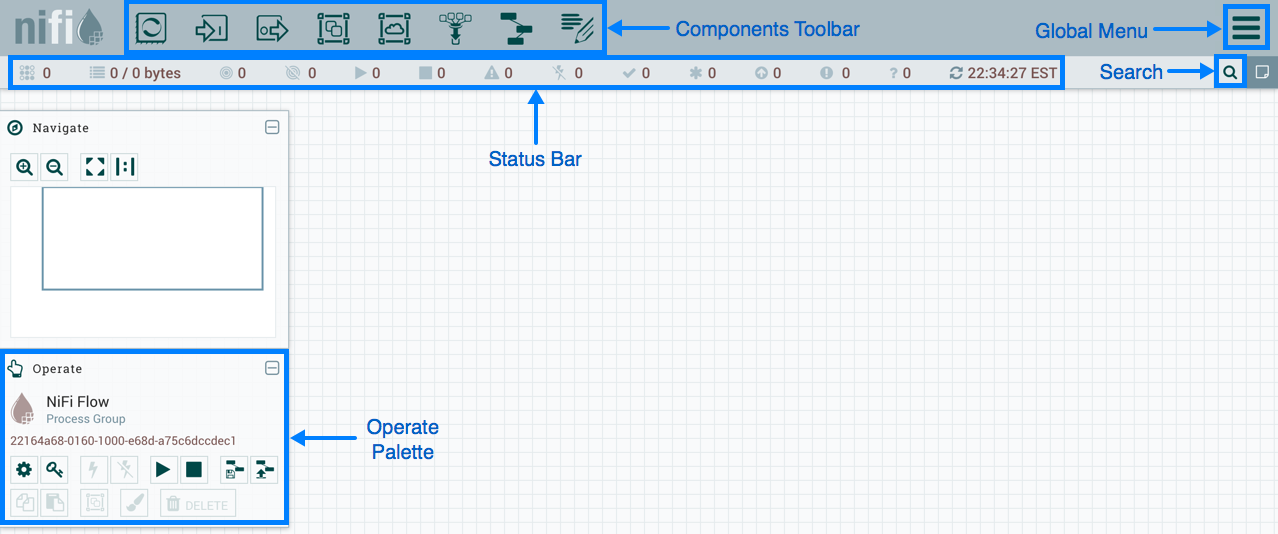 Gestión basada en web NiFi
Gestión basada en web NiFiA continuación, mostraré algunos ejemplos de DataFlow para realizar algunas operaciones comunes.
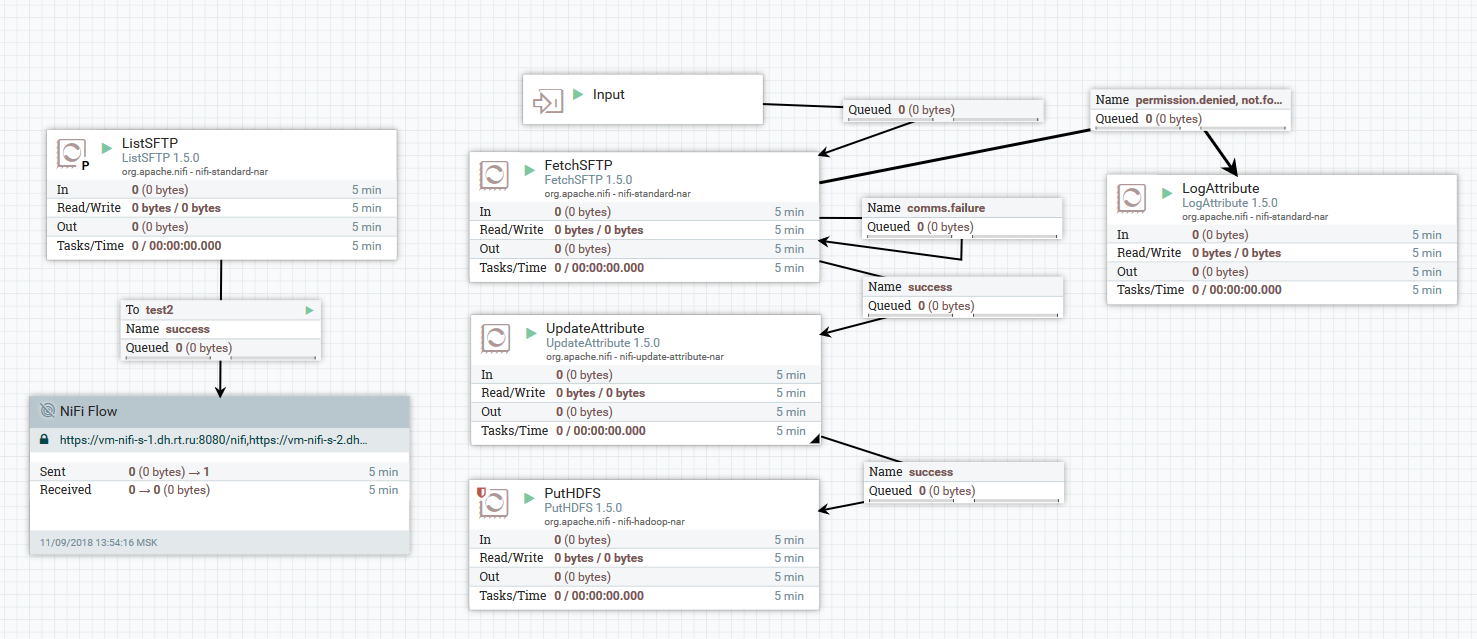 Ejemplo de descarga de archivos de un servidor SFTP a HDFS
Ejemplo de descarga de archivos de un servidor SFTP a HDFSEn este ejemplo, el procesador ListSFTP hace una lista de archivos en el servidor remoto. El resultado de este listado se utiliza para la carga de archivos paralelos por todos los nodos del clúster por el procesador FetchSFTP. Después de eso, los atributos se agregan a cada archivo, obtenido al analizar su nombre, que luego son utilizados por el procesador PutHDFS al escribir el archivo en el directorio final.
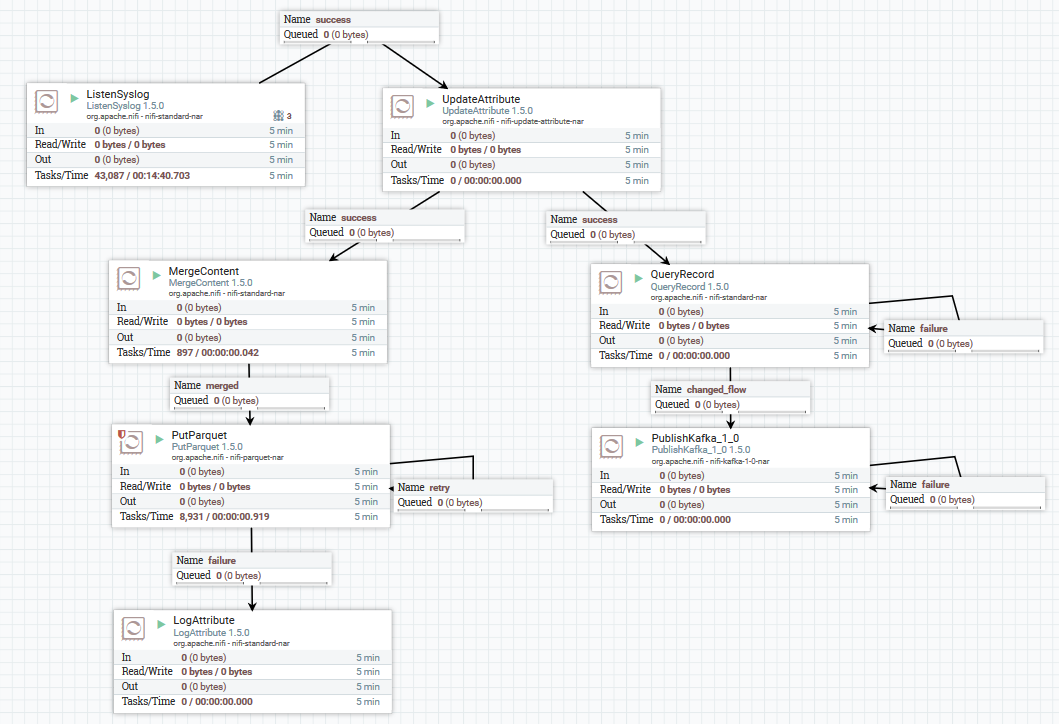 Un ejemplo de descarga de datos de syslog en Kafka y HDFS
Un ejemplo de descarga de datos de syslog en Kafka y HDFSAquí, usando el procesador ListenSyslog, obtenemos el flujo de mensajes de entrada. Después de eso, los atributos sobre el momento de su llegada a NiFi y el nombre del esquema en el Registro de esquemas Avro se agregan a cada grupo de mensajes. A continuación, la primera rama se dirige a la entrada del procesador QueryRecord, que, según el esquema especificado, lee los datos y los analiza mediante SQL, y luego los envía a Kafka. La segunda rama se envía al procesador MergeContent, que agrega los datos durante 10 minutos, y luego los entrega al siguiente procesador para convertirlos al formato Parquet y grabarlos en HDFS.
Aquí hay un ejemplo de cómo puedes diseñar un DataFlow:
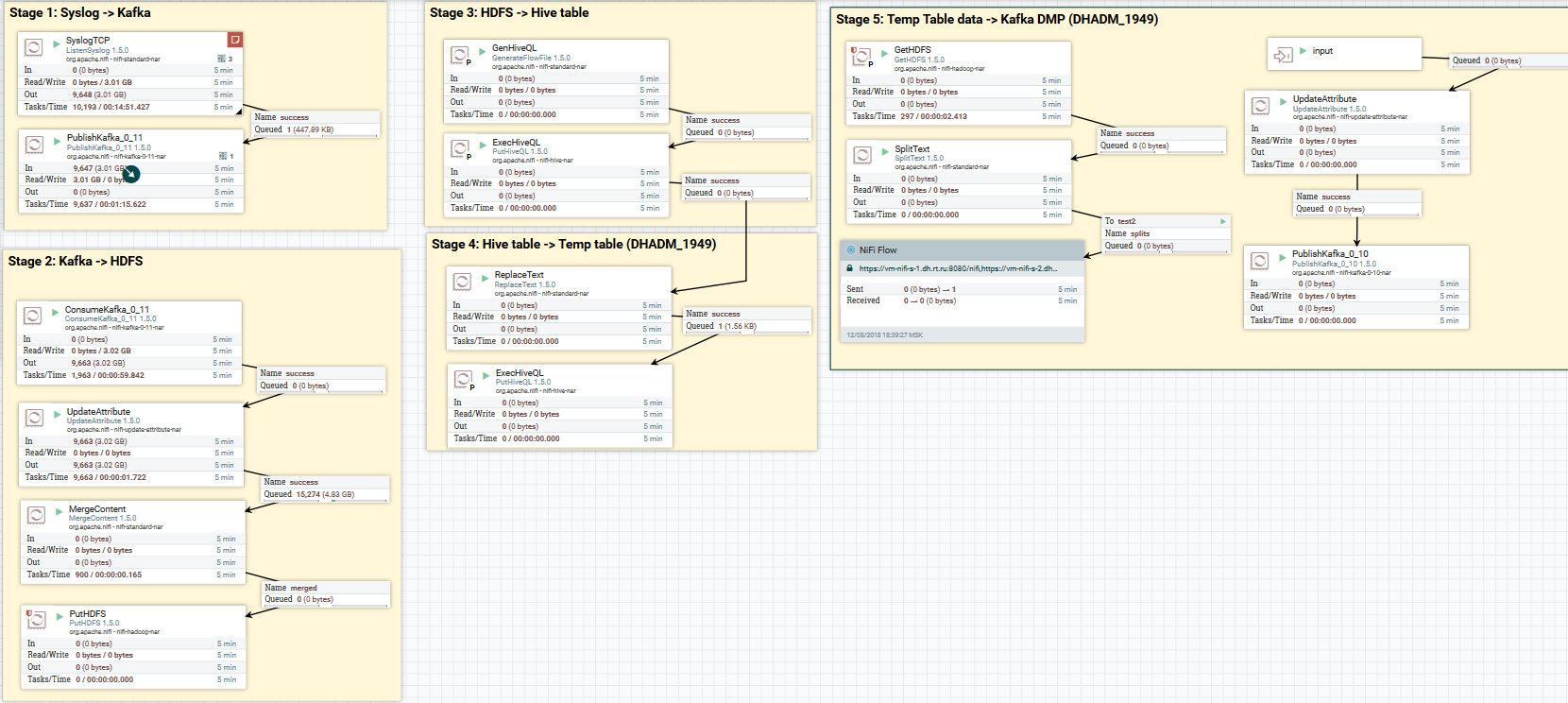 Descargue datos de syslog a Kafka y HDFS. Borrar datos en Hive
Descargue datos de syslog a Kafka y HDFS. Borrar datos en HiveAhora sobre la conversión de datos. NiFi le permite analizar datos con datos regulares, ejecutar SQL en ellos, filtrar y agregar campos y convertir un formato de datos a otro. También tiene su propio lenguaje de expresión, rico en varios operadores y funciones integradas. Con él, puede agregar variables y atributos a los datos, comparar y calcular valores, usarlos más adelante en la formación de varios parámetros, como la ruta para escribir en HDFS o la consulta SQL en Hive. Lee más
aquí .
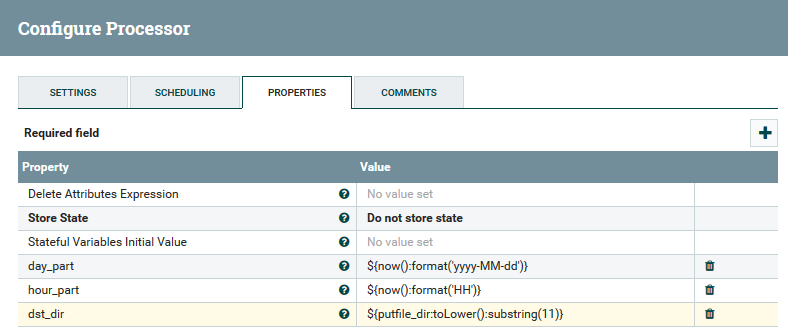 Un ejemplo de uso de variables y funciones en el procesador UpdateAttribute
Un ejemplo de uso de variables y funciones en el procesador UpdateAttributeEl usuario puede rastrear la ruta completa de los datos, observar el cambio en sus contenidos y atributos.
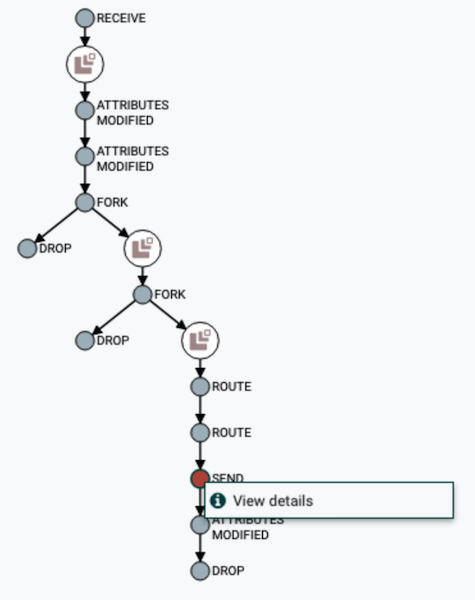 Visualización de la cadena DataFlow
Visualización de la cadena DataFlow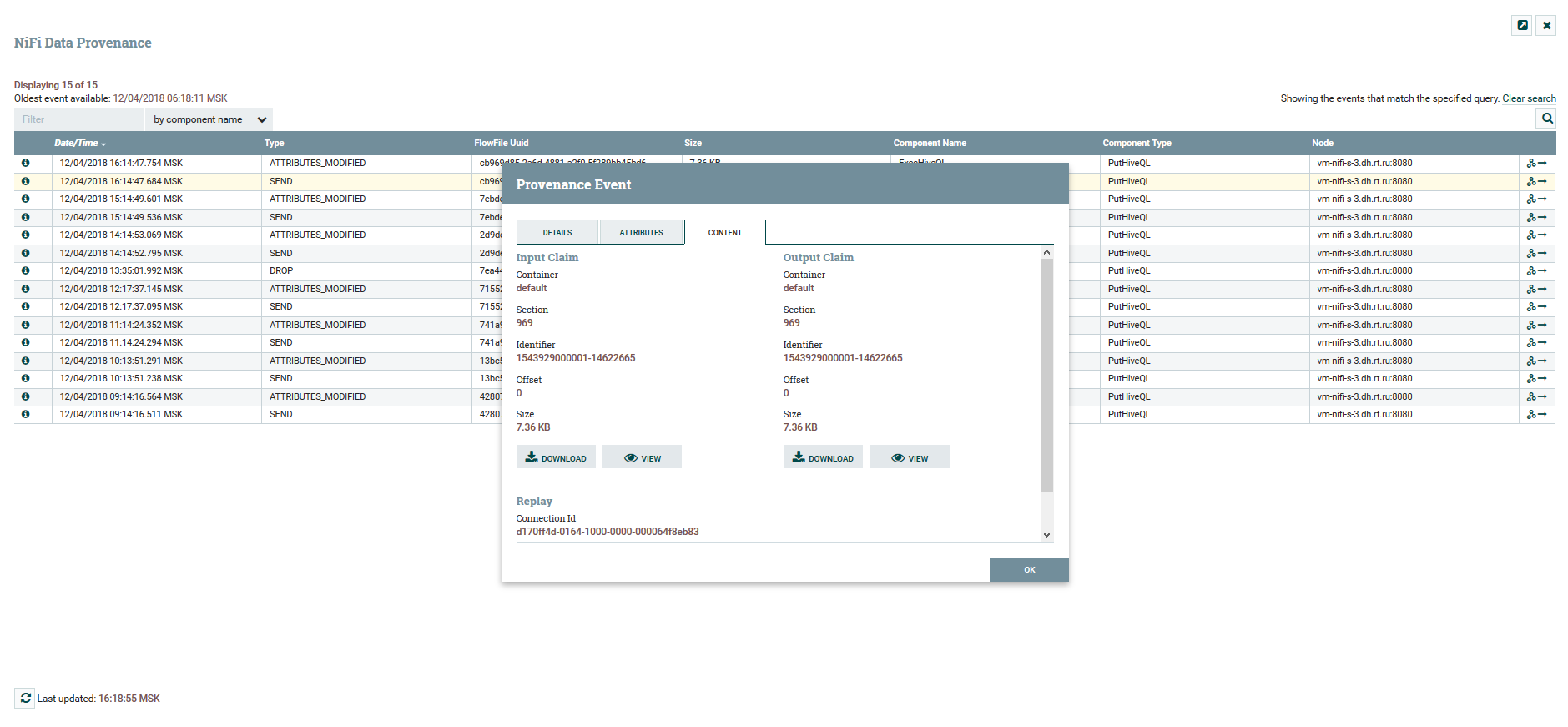 Ver contenido y atributos de datos
Ver contenido y atributos de datosPara versionar DataFlow hay un servicio de
registro de NiFi separado. Al configurarlo, puede administrar los cambios. Puede ejecutar cambios locales, revertir o descargar cualquier versión anterior.
 Menú de control de versiones
Menú de control de versionesEn NiFi, puede controlar el acceso a la interfaz web y la separación de los derechos del usuario. Actualmente se admiten los siguientes mecanismos de autenticación:
No se admite el uso simultáneo de varios mecanismos a la vez. Para autorizar a los usuarios en el sistema, se utilizan FileUserGroupProvider y LdapUserGroupProvider. Lea más sobre esto
aquí .
Como dije, NiFi puede funcionar en modo de clúster. Esto proporciona tolerancia a fallas y permite el escalamiento de carga horizontal. No hay un nodo maestro estáticamente fijo. En cambio,
Apache Zookeeper selecciona un nodo como coordinador y otro como primario. El coordinador recibe información sobre su estado de otros nodos y es responsable de su conexión y desconexión del clúster.
El nodo primario se usa para iniciar procesadores aislados, que no deberían ejecutarse en todos los nodos simultáneamente.
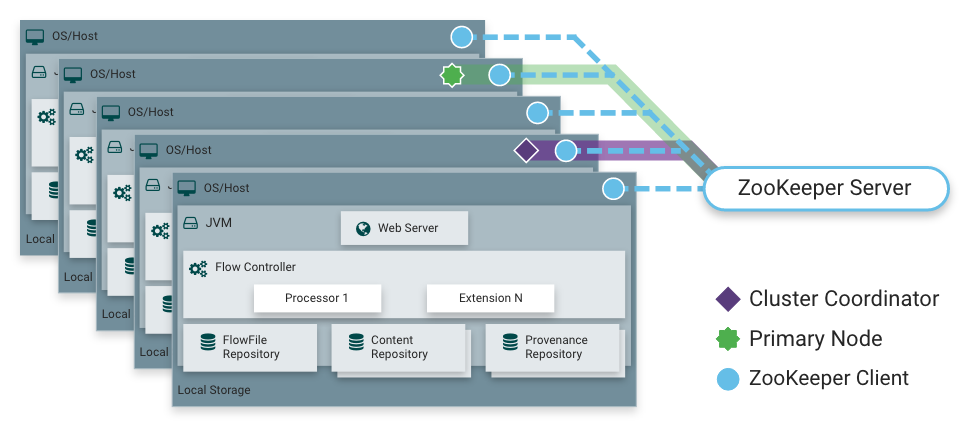 Operación de NiFi en un clúster
Operación de NiFi en un clúster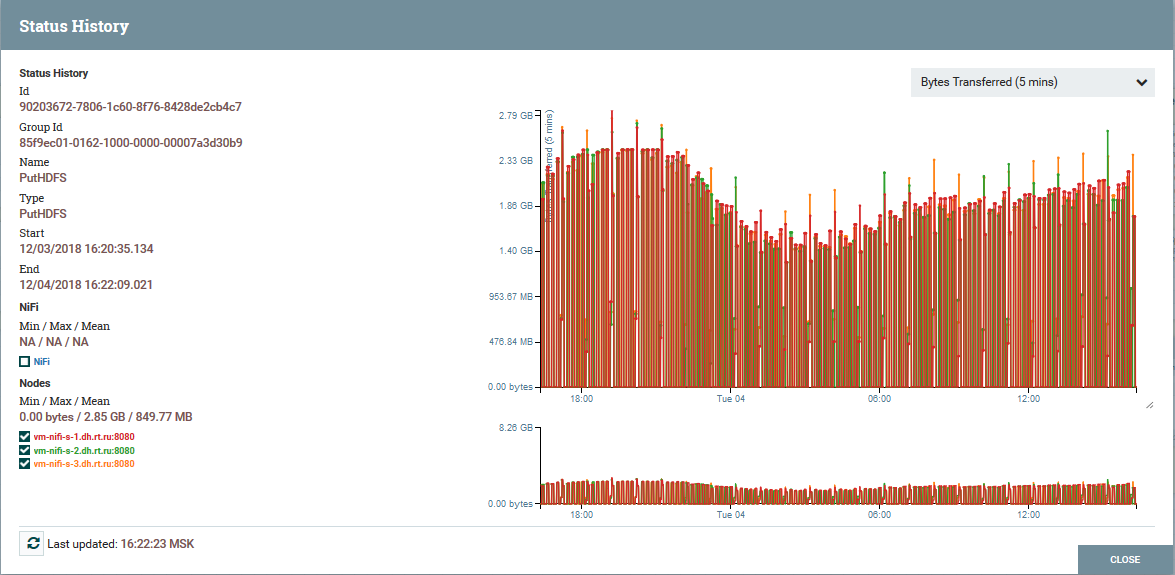 Distribución de carga por nodos de clúster utilizando el procesador PutHDFS como ejemplo
Distribución de carga por nodos de clúster utilizando el procesador PutHDFS como ejemploUna breve descripción de la arquitectura y componentes NiFi
 Arquitectura de instancia de NiFi
Arquitectura de instancia de NiFiNiFi se basa en el concepto de "Programación basada en flujo" (
FBP ). Estos son los conceptos y componentes básicos que cada usuario encuentra:
FlowFile : una entidad que representa un objeto con contenido de cero o más bytes y sus atributos correspondientes. Estos pueden ser los datos en sí (por ejemplo, el flujo de mensajes de Kafka) o el resultado del procesador (PutSQL, por ejemplo), que no contiene datos como tales, sino solo los atributos generados como resultado de la consulta. Los atributos son metadatos de FlowFile.
El procesador FlowFile es exactamente la esencia que hace el trabajo básico en NiFi. Un procesador, por regla general, tiene una o varias funciones para trabajar con FlowFile: crear, leer / escribir y cambiar contenidos, leer / escribir / cambiar atributos, enrutamiento. Por ejemplo, el procesador ListenSyslog recibe datos utilizando el protocolo syslog, creando FlowFiles con los atributos syslog.version, syslog.hostname, syslog.sender y otros. El procesador RouteOnAttribute lee los atributos del FlowFile de entrada y decide redirigirlo a la conexión adecuada con otro procesador, según los valores de los atributos.
Conexión : proporciona conexión y transferencia de archivos de flujo entre varios procesadores y algunas otras entidades NiFi. Connection pone el FlowFile en una cola y luego lo pasa por la cadena. Puede configurar cómo se seleccionan los FlowFiles de la cola, su duración, número máximo y tamaño máximo de todos los objetos en la cola.
Grupo de procesos : un conjunto de procesadores, sus conexiones y otros elementos de DataFlow. Es un mecanismo para organizar muchos componentes en una estructura lógica. Ayuda a simplificar la comprensión de DataFlow. Los puertos de entrada / salida se utilizan para recibir y enviar datos desde los grupos de procesos. Lea más sobre su uso
aquí .
El repositorio de FlowFile es donde NiFi almacena toda la información que conoce sobre cada FlowFile existente en el sistema.
Repositorio de contenido : el repositorio en el que se encuentran los contenidos de todos los FlowFiles, es decir los datos transmitidos en sí.
Repositorio de procedencia : contiene una historia sobre cada FlowFile. Cada vez que ocurre un evento con FlowFile (creación, cambio, etc.), la información correspondiente se ingresa en este repositorio.
Servidor web : proporciona una interfaz web y una API REST.
Conclusión
Con NiFi, Rostelecom pudo mejorar el mecanismo para entregar datos a Data Lake en Hadoop. En general, todo el proceso se ha vuelto más conveniente y confiable. Hoy, puedo decir con seguridad que NiFi es excelente para descargar a Hadoop. No tenemos problemas en su funcionamiento.
Por cierto, NiFi es parte de la distribución de flujo de datos de Hortonworks y es desarrollado activamente por Hortonworks. También tiene un interesante subproyecto Apache MiNiFi, que le permite recopilar datos de varios dispositivos e integrarlos en DataFlow dentro de NiFi.
Información adicional sobre NiFi
Quizás eso es todo. Gracias a todos por su atención. Escriba en los comentarios si tiene preguntas. Les responderé con gusto.