
DeepMind crea algoritmos realmente sorprendentes que son capaces de lo que los sistemas de máquinas no podían lograr antes. En particular, la red neuronal
AlphaGo pudo vencer a los mejores jugadores del mundo. Según los expertos, ahora las capacidades del sistema han crecido tanto que ni siquiera tiene sentido tratar de derrotarlo: el resultado está predeterminado.
Sin embargo, la empresa no se detiene allí, sino que continúa trabajando. Gracias a la investigación de sus empleados, nació
una versión mejorada de AlphaGo, llamada AlphaZero. Como se indica en el título, el sistema en sí fue capaz de aprender a jugar tres juegos lógicos a la vez: ajedrez, shogi y listo.
La diferencia entre la nueva versión y todas las anteriores
era que el sistema mismo aprendió casi todo. Comenzó desde cero y rápidamente aprendió a jugar los tres juegos perfectamente. Nadie ayudó a AlphaZero: el sistema "lo consiguió todo por sí mismo".
El ajedrez se incluyó en el set, más bien, según la tradición: no es nada difícil enseñarle a una computadora a jugar ajedrez, no. Por primera vez, se introdujo un sistema informático en el juego en la década de 1950. Luego, ya en los años 60, se creó el programa
Mac Hack IV , que comenzó a vencer a los rivales humanos. Con el tiempo, los programas de ajedrez mejoraron gradualmente, y en 1997, IBM desarrolló la "computadora de ajedrez" Deep Blue, que logró vencer al Gran Maestro y campeón mundial Garry Kasparov.
Como él mismo señala, en la actualidad muchas aplicaciones en un teléfono inteligente juegan al ajedrez mejor que Deep Blue. Después de haber logrado la perfección en la creación de sistemas que pueden jugar al ajedrez, los desarrolladores comenzaron a crear nuevas versiones de rivales informáticos humanos, en particular, lograron enseñar a la computadora a jugar. Anteriormente, este juego con una historia de mil años era considerado uno de los más inaccesibles para la "comprensión" de la computadora. Pero los tiempos han cambiado. Como se mencionó anteriormente, AlphaGo logró un nivel tan alto de dominio del juego de go que una persona no estaba parada cerca.
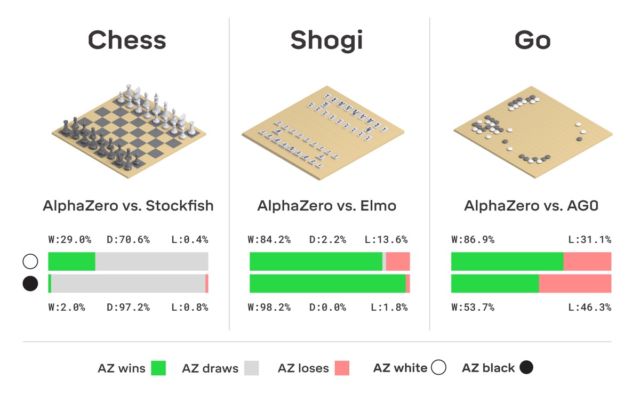
Por cierto, este año AlphaGo recibió una actualización, gracias a la cual la red neuronal ahora puede aprender varias estrategias para jugar sin intervención humana. Jugando consigo mismo una y otra vez, AlphaGo está mejorando. Es este tipo de sistema de entrenamiento el que utiliza el "descendiente" de AlphaGo: la red neuronal AlphaZero. En solo tres días, logró tal nivel de dominio en Go que superó la versión original de AlphaGo con un puntaje de 100 a 0. Lo único que el sistema recibe inicialmente son las reglas del juego.
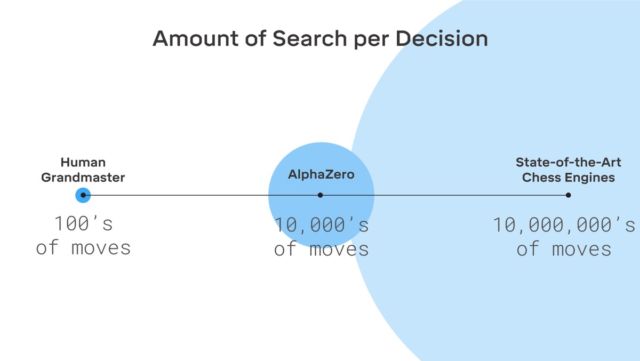
Aquí no hay ficción, DeepMind utiliza el conocido sistema de aprendizaje automático de refuerzo. La computadora busca ganar, porque por cada victoria recibe una recompensa (puntos). Además, AlphaZero pierde millones de combinaciones en el proceso de aprendizaje. AlphaZero gasta solo 0.4 segundos para calcular mal el siguiente movimiento y evaluar la probabilidad de ganar. En cuanto al AlphaGo de la versión original, la red neuronal constaba de dos elementos, dos redes neuronales: una determinaba el próximo movimiento posible y la segunda calculaba las probabilidades.
Para alcanzar el nivel maestro en Go AlphaZero, debes "desplazarte" alrededor de 4,5 millones de juegos cuando juegas contigo mismo. Pero AlphaGo requirió 30 millones de juegos.
Vale la pena señalar que AlphaZero fue creado específicamente para jugar go. La empresa no se ha olvidado de esto. Pero además de ir, el sistema puede aprender y otros dos juegos, que se mencionaron anteriormente. El sistema utilizado es el mismo: aprendizaje automático con refuerzo. Vale la pena señalar que AlphaZero solo trabaja con tareas que tienen un cierto número de soluciones. El sistema también necesita un modelo de entorno (virtual).
Curiosamente, el propio Kasparov cree que una persona puede obtener mucho de sistemas como AlphaGo; usted puede aprender mucho de ellos.
Actualmente, los desarrolladores se enfrentan a la tarea de enseñar a una computadora a jugar póker mejor que cualquiera de las personas, y también a crear un sistema que pueda vencer a cualquier deportista en una pelea justa. En cualquier caso, está claro que las redes neuronales y la IA son capaces de mucho.