
En una publicación anterior, escalamos el conjunto de réplicas MongoDB e introdujimos StatefulSet. Ahora asumiremos la orquestación del clúster de alta disponibilidad Elasticsearch (con otros nodos maestros, nodos de datos y nodos de clientes) y utilizaremos ES-HQ y Kibana.
Necesitarás:
- Una comprensión básica de Elasticsearch, sus tipos de nodos y sus roles.
- Un clúster de Kubernetes en funcionamiento con al menos tres nodos (al menos cuatro núcleos, 4 GB).
- Capacidad para trabajar con Kibana.
Arquitectura de implementación
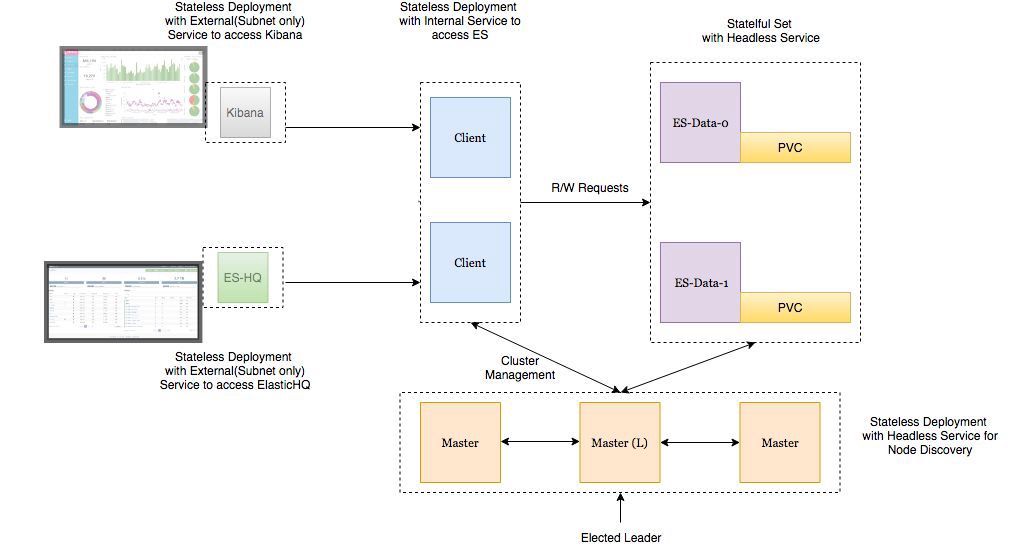
- Los nodos de datos Elasticsearch se implementan como StatefulSet con un servicio sin cabeza para que tengamos identificadores de red estables .
- Los masternodes de Elasticsearch se implementan como ReplicaSet con un servicio sin cabeza. Esto es para auto descubrimiento .
- Los pods en los nodos del cliente Elasticsearch se implementan como un ReplicaSet con un servicio interno para que pueda enviar solicitudes de lectura / escritura a los nodos de datos.
- Los pods Kibana y ElasticHQ se implementan como ReplicaSet con servicios que están disponibles fuera del clúster de Kubernetes , pero se encuentran dentro de la subred (no se abren hacia afuera innecesariamente).
- HPA (Horizonal Pod Autoscaler) se implementa para los nodos del cliente y es responsable del autoescalado horizontal a alta carga.
"Recuerde configurar para el entorno:
- ES_JAVA_OPTS variable.
- CLUSTER_NAME variable.
- La variable NUMBER_OF_MASTERS para el despliegue de los maestros para evitar la situación de cerebro dividido. Si tenemos 3 maestros, especifique 2.
- Reglas anti-afinidad para hogares similares para garantizar una alta confiabilidad si el nodo de trabajo se cae.
"
Implementemos estos servicios en el clúster GKE.
kind: Namespace metadata: name: elasticsearch --- apiVersion: apps/v1beta1 kind: Deployment metadata: name: es-master namespace: elasticsearch labels: component: elasticsearch role: master spec: replicas: 3 template: metadata: labels: component: elasticsearch role: master spec: affinity: podAntiAffinity: preferredDuringSchedulingIgnoredDuringExecution: - weight: 100 podAffinityTerm: labelSelector: matchExpressions: - key: role operator: In values: - master topologyKey: kubernetes.io/hostname initContainers: - name: init-sysctl image: busybox:1.27.2 command: - sysctl - -w - vm.max_map_count=262144 securityContext: privileged: true containers: - name: es-master image: quay.io/pires/docker-elasticsearch-kubernetes:6.2.4 env: - name: NAMESPACE valueFrom: fieldRef: fieldPath: metadata.namespace - name: NODE_NAME valueFrom: fieldRef: fieldPath: metadata.name - name: CLUSTER_NAME value: my-es - name: NUMBER_OF_MASTERS value: "2" - name: NODE_MASTER value: "true" - name: NODE_INGEST value: "false" - name: NODE_DATA value: "false" - name: HTTP_ENABLE value: "false" - name: ES_JAVA_OPTS value: -Xms256m -Xmx256m - name: PROCESSORS valueFrom: resourceFieldRef: resource: limits.cpu resources: limits: cpu: 2 ports: - containerPort: 9300 name: transport volumeMounts: - name: storage mountPath: /data volumes: - emptyDir: medium: "" name: "storage" --- apiVersion: v1 kind: Service metadata: name: elasticsearch-discovery namespace: elasticsearch labels: component: elasticsearch role: master spec: selector: component: elasticsearch role: master ports: - name: transport port: 9300 protocol: TCP clusterIP: None view rawes-master.yml hosted with love by GitHub
(Implementación y servicio sin cabeza para nodos maestros)
root$ kubectl -n elasticsearch get all NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE deploy/es-master 3 3 3 3 32s NAME DESIRED CURRENT READY AGE rs/es-master-594b58b86c 3 3 3 31s NAME READY STATUS RESTARTS AGE po/es-master-594b58b86c-9jkj2 1/1 Running 0 31s po/es-master-594b58b86c-bj7g7 1/1 Running 0 31s po/es-master-594b58b86c-lfpps 1/1 Running 0 31s NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE svc/elasticsearch-discovery ClusterIP None <none> 9300/TCP 31s
Es interesante estudiar los registros de hogar en los nodos maestros y ver cómo se selecciona el maestro entre ellos ahora y cómo será más adelante cuando agreguemos nuevos nodos de datos y nodos de clientes.
root$ kubectl -n elasticsearch logs -f po/es-master-594b58b86c-9jkj2 | grep ClusterApplierService [2018-10-21T07:41:54,958][INFO ][oecsClusterApplierService] [es-master-594b58b86c-9jkj2] detected_master {es-master-594b58b86c-bj7g7}{1aFT97hQQ7yiaBc2CYShBA}{Q3QzlaG3QGazOwtUl7N75Q}{10.9.126.87}{10.9.126.87:9300}, added {{es-master-594b58b86c-lfpps}{wZQmXr5fSfWisCpOHBhaMg}{50jGPeKLSpO9RU_HhnVJCA}{10.9.124.81}{10.9.124.81:9300},{es-master-594b58b86c-bj7g7}{1aFT97hQQ7yiaBc2CYShBA}{Q3QzlaG3QGazOwtUl7N75Q}{10.9.126.87}{10.9.126.87:9300},}, reason: apply cluster state (from master [master {es-master-594b58b86c-bj7g7}{1aFT97hQQ7yiaBc2CYShBA}{Q3QzlaG3QGazOwtUl7N75Q}{10.9.126.87}{10.9.126.87:9300} committed version [3]])
Aquí puede ver que bajo es-master con el nombre es-master-594b58b86c-bj7g7 es seleccionado por el maestro, y los otros dos pods se agregan a él y entre sí.
El servicio de detección de búsqueda elástica sin cabeza se instala de forma predeterminada en la imagen de Docker como una variable de entorno y se utiliza para la detección en nodos. Esta configuración se puede reemplazar si se desea.
Del mismo modo, implementamos nodos de datos y nodos de clientes . Ver configuraciones a continuación.
Desplegar nodo de datos:
kind: Namespace metadata: name: elasticsearch --- apiVersion: storage.k8s.io/v1beta1 kind: StorageClass metadata: name: fast provisioner: kubernetes.io/gce-pd parameters: type: pd-ssd fsType: xfs allowVolumeExpansion: true --- apiVersion: apps/v1beta1 kind: StatefulSet metadata: name: es-data namespace: elasticsearch labels: component: elasticsearch role: data spec: serviceName: elasticsearch-data replicas: 3 template: metadata: labels: component: elasticsearch role: data spec: affinity: podAntiAffinity: preferredDuringSchedulingIgnoredDuringExecution: - weight: 100 podAffinityTerm: labelSelector: matchExpressions: - key: role operator: In values: - data topologyKey: kubernetes.io/hostname initContainers: - name: init-sysctl image: busybox:1.27.2 command: - sysctl - -w - vm.max_map_count=262144 securityContext: privileged: true containers: - name: es-data image: quay.io/pires/docker-elasticsearch-kubernetes:6.2.4 env: - name: NAMESPACE valueFrom: fieldRef: fieldPath: metadata.namespace - name: NODE_NAME valueFrom: fieldRef: fieldPath: metadata.name - name: CLUSTER_NAME value: my-es - name: NODE_MASTER value: "false" - name: NODE_INGEST value: "false" - name: HTTP_ENABLE value: "false" - name: ES_JAVA_OPTS value: -Xms256m -Xmx256m - name: PROCESSORS valueFrom: resourceFieldRef: resource: limits.cpu resources: limits: cpu: 2 ports: - containerPort: 9300 name: transport volumeMounts: - name: storage mountPath: /data volumeClaimTemplates: - metadata: name: storage annotations: volume.beta.kubernetes.io/storage-class: "fast" spec: accessModes: [ "ReadWriteOnce" ] storageClassName: fast resources: requests: storage: 10Gi --- apiVersion: v1 kind: Service metadata: name: elasticsearch-data namespace: elasticsearch labels: component: elasticsearch role: data spec: ports: - port: 9300 name: transport clusterIP: None selector: component: elasticsearch role: data view rawes-data.yml hosted with love by GitHub
(Servicio StatefulSet y sin cabeza para nodos de datos)
El servicio sin cabeza en los nodos de datos emite identificadores de red estables a los nodos y ayuda a transferir datos entre nodos.
Es importante formatear el volumen permanente antes de adjuntarlo al hogar. Simplemente especifique el tipo de volumen cuando cree la clase de almacenamiento. También puede establecer un parámetro que permita la expansión automática del volumen . Lee los detalles aquí .
parameters: type: pd-ssd fsType: xfs allowVolumeExpansion: true ...
Implementar nodos de cliente:
kind: Namespace metadata: name: elasticsearch --- apiVersion: apps/v1beta1 kind: Deployment metadata: name: es-client namespace: elasticsearch labels: component: elasticsearch role: client spec: replicas: 2 template: metadata: labels: component: elasticsearch role: client spec: affinity: podAntiAffinity: preferredDuringSchedulingIgnoredDuringExecution: - weight: 100 podAffinityTerm: labelSelector: matchExpressions: - key: role operator: In values: - client topologyKey: kubernetes.io/hostname initContainers: - name: init-sysctl image: busybox:1.27.2 command: - sysctl - -w - vm.max_map_count=262144 securityContext: privileged: true containers: - name: es-client image: quay.io/pires/docker-elasticsearch-kubernetes:6.2.4 env: - name: NAMESPACE valueFrom: fieldRef: fieldPath: metadata.namespace - name: NODE_NAME valueFrom: fieldRef: fieldPath: metadata.name - name: CLUSTER_NAME value: my-es - name: NODE_MASTER value: "false" - name: NODE_DATA value: "false" - name: HTTP_ENABLE value: "true" - name: ES_JAVA_OPTS value: -Xms256m -Xmx256m - name: NETWORK_HOST value: _site_,_lo_ - name: PROCESSORS valueFrom: resourceFieldRef: resource: limits.cpu resources: limits: cpu: 1 ports: - containerPort: 9200 name: http - containerPort: 9300 name: transport volumeMounts: - name: storage mountPath: /data volumes: - emptyDir: medium: "" name: storage --- apiVersion: v1 kind: Service metadata: name: elasticsearch namespace: elasticsearch annotations: cloud.google.com/load-balancer-type: Internal labels: component: elasticsearch role: client spec: selector: component: elasticsearch role: client ports: - name: http port: 9200 type: LoadBalancer view rawes-client.yml hosted with love by GitHub
(Implementación y servicio externo para nodos de clientes)
El servicio implementado aquí proporciona acceso al clúster de ES fuera del clúster de Kubernetes, pero aún está dentro de la subred. La anotación cloud.google.com/load-balancer-type: Internal es responsable de esto.
Pero si la aplicación que accede al clúster ES para lectura y escritura se implementa dentro del clúster, entonces el acceso al servicio ElasticSearch se puede obtener en http: //elasticsearch.elasticsearch: 9200 .
Cuando expande los nodos de datos y los nodos del cliente, se agregarán al clúster automáticamente. (Busque el maestro debajo de los registros)
root$ kubectl -n elasticsearch get pods -l role=data NAME READY STATUS RESTARTS AGE es-data-0 1/1 Running 0 48s es-data-1 1/1 Running 0 28s -------------------------------------------------------------------- root$ kubectl apply -f es-client.yml root$ kubectl -n elasticsearch get pods -l role=client NAME READY STATUS RESTARTS AGE es-client-69b84b46d8-kr7j4 1/1 Running 0 47s es-client-69b84b46d8-v5pj2 1/1 Running 0 47s -------------------------------------------------------------------- root$ kubectl -n elasticsearch get all NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE deploy/es-client 2 2 2 2 1m deploy/es-master 3 3 3 3 9m NAME DESIRED CURRENT READY AGE rs/es-client-69b84b46d8 2 2 2 1m rs/es-master-594b58b86c 3 3 3 9m NAME DESIRED CURRENT AGE statefulsets/es-data 2 2 3m NAME READY STATUS RESTARTS AGE po/es-client-69b84b46d8-kr7j4 1/1 Running 0 1m po/es-client-69b84b46d8-v5pj2 1/1 Running 0 1m po/es-data-0 1/1 Running 0 3m po/es-data-1 1/1 Running 0 3m po/es-master-594b58b86c-9jkj2 1/1 Running 0 9m po/es-master-594b58b86c-bj7g7 1/1 Running 0 9m po/es-master-594b58b86c-lfpps 1/1 Running 0 9m NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE svc/elasticsearch LoadBalancer 10.9.121.160 10.9.120.8 9200:32310/TCP 1m svc/elasticsearch-data ClusterIP None <none> 9300/TCP 3m svc/elasticsearch-discovery ClusterIP None <none> 9300/TCP 9m -------------------------------------------------------------------- #Check logs of es-master leader pod root$ kubectl -n elasticsearch logs po/es-master-594b58b86c-bj7g7 | grep ClusterApplierService [2018-10-21T07:41:53,731][INFO ][oecsClusterApplierService] [es-master-594b58b86c-bj7g7] new_master {es-master-594b58b86c-bj7g7}{1aFT97hQQ7yiaBc2CYShBA}{Q3QzlaG3QGazOwtUl7N75Q}{10.9.126.87}{10.9.126.87:9300}, added {{es-master-594b58b86c-lfpps}{wZQmXr5fSfWisCpOHBhaMg}{50jGPeKLSpO9RU_HhnVJCA}{10.9.124.81}{10.9.124.81:9300},}, reason: apply cluster state (from master [master {es-master-594b58b86c-bj7g7}{1aFT97hQQ7yiaBc2CYShBA}{Q3QzlaG3QGazOwtUl7N75Q}{10.9.126.87}{10.9.126.87:9300} committed version [1] source [zen-disco-elected-as-master ([1] nodes joined)[{es-master-594b58b86c-lfpps}{wZQmXr5fSfWisCpOHBhaMg}{50jGPeKLSpO9RU_HhnVJCA}{10.9.124.81}{10.9.124.81:9300}]]]) [2018-10-21T07:41:55,162][INFO ][oecsClusterApplierService] [es-master-594b58b86c-bj7g7] added {{es-master-594b58b86c-9jkj2}{x9Prp1VbTq6_kALQVNwIWg}{7NHUSVpuS0mFDTXzAeKRcg}{10.9.125.81}{10.9.125.81:9300},}, reason: apply cluster state (from master [master {es-master-594b58b86c-bj7g7}{1aFT97hQQ7yiaBc2CYShBA}{Q3QzlaG3QGazOwtUl7N75Q}{10.9.126.87}{10.9.126.87:9300} committed version [3] source [zen-disco-node-join[{es-master-594b58b86c-9jkj2}{x9Prp1VbTq6_kALQVNwIWg}{7NHUSVpuS0mFDTXzAeKRcg}{10.9.125.81}{10.9.125.81:9300}]]]) [2018-10-21T07:48:02,485][INFO ][oecsClusterApplierService] [es-master-594b58b86c-bj7g7] added {{es-data-0}{SAOhUiLiRkazskZ_TC6EBQ}{qirmfVJBTjSBQtHZnz-QZw}{10.9.126.88}{10.9.126.88:9300},}, reason: apply cluster state (from master [master {es-master-594b58b86c-bj7g7}{1aFT97hQQ7yiaBc2CYShBA}{Q3QzlaG3QGazOwtUl7N75Q}{10.9.126.87}{10.9.126.87:9300} committed version [4] source [zen-disco-node-join[{es-data-0}{SAOhUiLiRkazskZ_TC6EBQ}{qirmfVJBTjSBQtHZnz-QZw}{10.9.126.88}{10.9.126.88:9300}]]]) [2018-10-21T07:48:21,984][INFO ][oecsClusterApplierService] [es-master-594b58b86c-bj7g7] added {{es-data-1}{fiv5Wh29TRWGPumm5ypJfA}{EXqKGSzIQquRyWRzxIOWhQ}{10.9.125.82}{10.9.125.82:9300},}, reason: apply cluster state (from master [master {es-master-594b58b86c-bj7g7}{1aFT97hQQ7yiaBc2CYShBA}{Q3QzlaG3QGazOwtUl7N75Q}{10.9.126.87}{10.9.126.87:9300} committed version [5] source [zen-disco-node-join[{es-data-1}{fiv5Wh29TRWGPumm5ypJfA}{EXqKGSzIQquRyWRzxIOWhQ}{10.9.125.82}{10.9.125.82:9300}]]]) [2018-10-21T07:50:51,245][INFO ][oecsClusterApplierService] [es-master-594b58b86c-bj7g7] added {{es-client-69b84b46d8-v5pj2}{MMjA_tlTS7ux-UW44i0osg}{rOE4nB_jSmaIQVDZCjP8Rg}{10.9.125.83}{10.9.125.83:9300},}, reason: apply cluster state (from master [master {es-master-594b58b86c-bj7g7}{1aFT97hQQ7yiaBc2CYShBA}{Q3QzlaG3QGazOwtUl7N75Q}{10.9.126.87}{10.9.126.87:9300} committed version [6] source [zen-disco-node-join[{es-client-69b84b46d8-v5pj2}{MMjA_tlTS7ux-UW44i0osg}{rOE4nB_jSmaIQVDZCjP8Rg}{10.9.125.83}{10.9.125.83:9300}]]]) [2018-10-21T07:50:58,964][INFO ][oecsClusterApplierService] [es-master-594b58b86c-bj7g7] added {{es-client-69b84b46d8-kr7j4}{gGC7F4diRWy2oM1TLTvNsg}{IgI6g3iZT5Sa0HsFVMpvvw}{10.9.124.82}{10.9.124.82:9300},}, reason: apply cluster state (from master [master {es-master-594b58b86c-bj7g7}{1aFT97hQQ7yiaBc2CYShBA}{Q3QzlaG3QGazOwtUl7N75Q}{10.9.126.87}{10.9.126.87:9300} committed version [7] source [zen-disco-node-join[{es-client-69b84b46d8-kr7j4}{gGC7F4diRWy2oM1TLTvNsg}{IgI6g3iZT5Sa0HsFVMpvvw}{10.9.124.82}{10.9.124.82:9300}]]]) ] [es-master-594b58b86c-bj7g7] añadido {{es-master-594b58b86c-9jkj2} {} {x9Prp1VbTq6_kALQVNwIWg 7NHUSVpuS0mFDTXzAeKRcg} {10.9.125.81} {10.9 root$ kubectl -n elasticsearch get pods -l role=data NAME READY STATUS RESTARTS AGE es-data-0 1/1 Running 0 48s es-data-1 1/1 Running 0 28s -------------------------------------------------------------------- root$ kubectl apply -f es-client.yml root$ kubectl -n elasticsearch get pods -l role=client NAME READY STATUS RESTARTS AGE es-client-69b84b46d8-kr7j4 1/1 Running 0 47s es-client-69b84b46d8-v5pj2 1/1 Running 0 47s -------------------------------------------------------------------- root$ kubectl -n elasticsearch get all NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE deploy/es-client 2 2 2 2 1m deploy/es-master 3 3 3 3 9m NAME DESIRED CURRENT READY AGE rs/es-client-69b84b46d8 2 2 2 1m rs/es-master-594b58b86c 3 3 3 9m NAME DESIRED CURRENT AGE statefulsets/es-data 2 2 3m NAME READY STATUS RESTARTS AGE po/es-client-69b84b46d8-kr7j4 1/1 Running 0 1m po/es-client-69b84b46d8-v5pj2 1/1 Running 0 1m po/es-data-0 1/1 Running 0 3m po/es-data-1 1/1 Running 0 3m po/es-master-594b58b86c-9jkj2 1/1 Running 0 9m po/es-master-594b58b86c-bj7g7 1/1 Running 0 9m po/es-master-594b58b86c-lfpps 1/1 Running 0 9m NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE svc/elasticsearch LoadBalancer 10.9.121.160 10.9.120.8 9200:32310/TCP 1m svc/elasticsearch-data ClusterIP None <none> 9300/TCP 3m svc/elasticsearch-discovery ClusterIP None <none> 9300/TCP 9m -------------------------------------------------------------------- #Check logs of es-master leader pod root$ kubectl -n elasticsearch logs po/es-master-594b58b86c-bj7g7 | grep ClusterApplierService [2018-10-21T07:41:53,731][INFO ][oecsClusterApplierService] [es-master-594b58b86c-bj7g7] new_master {es-master-594b58b86c-bj7g7}{1aFT97hQQ7yiaBc2CYShBA}{Q3QzlaG3QGazOwtUl7N75Q}{10.9.126.87}{10.9.126.87:9300}, added {{es-master-594b58b86c-lfpps}{wZQmXr5fSfWisCpOHBhaMg}{50jGPeKLSpO9RU_HhnVJCA}{10.9.124.81}{10.9.124.81:9300},}, reason: apply cluster state (from master [master {es-master-594b58b86c-bj7g7}{1aFT97hQQ7yiaBc2CYShBA}{Q3QzlaG3QGazOwtUl7N75Q}{10.9.126.87}{10.9.126.87:9300} committed version [1] source [zen-disco-elected-as-master ([1] nodes joined)[{es-master-594b58b86c-lfpps}{wZQmXr5fSfWisCpOHBhaMg}{50jGPeKLSpO9RU_HhnVJCA}{10.9.124.81}{10.9.124.81:9300}]]]) [2018-10-21T07:41:55,162][INFO ][oecsClusterApplierService] [es-master-594b58b86c-bj7g7] added {{es-master-594b58b86c-9jkj2}{x9Prp1VbTq6_kALQVNwIWg}{7NHUSVpuS0mFDTXzAeKRcg}{10.9.125.81}{10.9.125.81:9300},}, reason: apply cluster state (from master [master {es-master-594b58b86c-bj7g7}{1aFT97hQQ7yiaBc2CYShBA}{Q3QzlaG3QGazOwtUl7N75Q}{10.9.126.87}{10.9.126.87:9300} committed version [3] source [zen-disco-node-join[{es-master-594b58b86c-9jkj2}{x9Prp1VbTq6_kALQVNwIWg}{7NHUSVpuS0mFDTXzAeKRcg}{10.9.125.81}{10.9.125.81:9300}]]]) [2018-10-21T07:48:02,485][INFO ][oecsClusterApplierService] [es-master-594b58b86c-bj7g7] added {{es-data-0}{SAOhUiLiRkazskZ_TC6EBQ}{qirmfVJBTjSBQtHZnz-QZw}{10.9.126.88}{10.9.126.88:9300},}, reason: apply cluster state (from master [master {es-master-594b58b86c-bj7g7}{1aFT97hQQ7yiaBc2CYShBA}{Q3QzlaG3QGazOwtUl7N75Q}{10.9.126.87}{10.9.126.87:9300} committed version [4] source [zen-disco-node-join[{es-data-0}{SAOhUiLiRkazskZ_TC6EBQ}{qirmfVJBTjSBQtHZnz-QZw}{10.9.126.88}{10.9.126.88:9300}]]]) [2018-10-21T07:48:21,984][INFO ][oecsClusterApplierService] [es-master-594b58b86c-bj7g7] added {{es-data-1}{fiv5Wh29TRWGPumm5ypJfA}{EXqKGSzIQquRyWRzxIOWhQ}{10.9.125.82}{10.9.125.82:9300},}, reason: apply cluster state (from master [master {es-master-594b58b86c-bj7g7}{1aFT97hQQ7yiaBc2CYShBA}{Q3QzlaG3QGazOwtUl7N75Q}{10.9.126.87}{10.9.126.87:9300} committed version [5] source [zen-disco-node-join[{es-data-1}{fiv5Wh29TRWGPumm5ypJfA}{EXqKGSzIQquRyWRzxIOWhQ}{10.9.125.82}{10.9.125.82:9300}]]]) [2018-10-21T07:50:51,245][INFO ][oecsClusterApplierService] [es-master-594b58b86c-bj7g7] added {{es-client-69b84b46d8-v5pj2}{MMjA_tlTS7ux-UW44i0osg}{rOE4nB_jSmaIQVDZCjP8Rg}{10.9.125.83}{10.9.125.83:9300},}, reason: apply cluster state (from master [master {es-master-594b58b86c-bj7g7}{1aFT97hQQ7yiaBc2CYShBA}{Q3QzlaG3QGazOwtUl7N75Q}{10.9.126.87}{10.9.126.87:9300} committed version [6] source [zen-disco-node-join[{es-client-69b84b46d8-v5pj2}{MMjA_tlTS7ux-UW44i0osg}{rOE4nB_jSmaIQVDZCjP8Rg}{10.9.125.83}{10.9.125.83:9300}]]]) [2018-10-21T07:50:58,964][INFO ][oecsClusterApplierService] [es-master-594b58b86c-bj7g7] added {{es-client-69b84b46d8-kr7j4}{gGC7F4diRWy2oM1TLTvNsg}{IgI6g3iZT5Sa0HsFVMpvvw}{10.9.124.82}{10.9.124.82:9300},}, reason: apply cluster state (from master [master {es-master-594b58b86c-bj7g7}{1aFT97hQQ7yiaBc2CYShBA}{Q3QzlaG3QGazOwtUl7N75Q}{10.9.126.87}{10.9.126.87:9300} committed version [7] source [zen-disco-node-join[{es-client-69b84b46d8-kr7j4}{gGC7F4diRWy2oM1TLTvNsg}{IgI6g3iZT5Sa0HsFVMpvvw}{10.9.124.82}{10.9.124.82:9300}]]]) ] [es-master-594b58b86c-bj7g7] añadido {{es-Data- root$ kubectl -n elasticsearch get pods -l role=data NAME READY STATUS RESTARTS AGE es-data-0 1/1 Running 0 48s es-data-1 1/1 Running 0 28s -------------------------------------------------------------------- root$ kubectl apply -f es-client.yml root$ kubectl -n elasticsearch get pods -l role=client NAME READY STATUS RESTARTS AGE es-client-69b84b46d8-kr7j4 1/1 Running 0 47s es-client-69b84b46d8-v5pj2 1/1 Running 0 47s -------------------------------------------------------------------- root$ kubectl -n elasticsearch get all NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE deploy/es-client 2 2 2 2 1m deploy/es-master 3 3 3 3 9m NAME DESIRED CURRENT READY AGE rs/es-client-69b84b46d8 2 2 2 1m rs/es-master-594b58b86c 3 3 3 9m NAME DESIRED CURRENT AGE statefulsets/es-data 2 2 3m NAME READY STATUS RESTARTS AGE po/es-client-69b84b46d8-kr7j4 1/1 Running 0 1m po/es-client-69b84b46d8-v5pj2 1/1 Running 0 1m po/es-data-0 1/1 Running 0 3m po/es-data-1 1/1 Running 0 3m po/es-master-594b58b86c-9jkj2 1/1 Running 0 9m po/es-master-594b58b86c-bj7g7 1/1 Running 0 9m po/es-master-594b58b86c-lfpps 1/1 Running 0 9m NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE svc/elasticsearch LoadBalancer 10.9.121.160 10.9.120.8 9200:32310/TCP 1m svc/elasticsearch-data ClusterIP None <none> 9300/TCP 3m svc/elasticsearch-discovery ClusterIP None <none> 9300/TCP 9m -------------------------------------------------------------------- #Check logs of es-master leader pod root$ kubectl -n elasticsearch logs po/es-master-594b58b86c-bj7g7 | grep ClusterApplierService [2018-10-21T07:41:53,731][INFO ][oecsClusterApplierService] [es-master-594b58b86c-bj7g7] new_master {es-master-594b58b86c-bj7g7}{1aFT97hQQ7yiaBc2CYShBA}{Q3QzlaG3QGazOwtUl7N75Q}{10.9.126.87}{10.9.126.87:9300}, added {{es-master-594b58b86c-lfpps}{wZQmXr5fSfWisCpOHBhaMg}{50jGPeKLSpO9RU_HhnVJCA}{10.9.124.81}{10.9.124.81:9300},}, reason: apply cluster state (from master [master {es-master-594b58b86c-bj7g7}{1aFT97hQQ7yiaBc2CYShBA}{Q3QzlaG3QGazOwtUl7N75Q}{10.9.126.87}{10.9.126.87:9300} committed version [1] source [zen-disco-elected-as-master ([1] nodes joined)[{es-master-594b58b86c-lfpps}{wZQmXr5fSfWisCpOHBhaMg}{50jGPeKLSpO9RU_HhnVJCA}{10.9.124.81}{10.9.124.81:9300}]]]) [2018-10-21T07:41:55,162][INFO ][oecsClusterApplierService] [es-master-594b58b86c-bj7g7] added {{es-master-594b58b86c-9jkj2}{x9Prp1VbTq6_kALQVNwIWg}{7NHUSVpuS0mFDTXzAeKRcg}{10.9.125.81}{10.9.125.81:9300},}, reason: apply cluster state (from master [master {es-master-594b58b86c-bj7g7}{1aFT97hQQ7yiaBc2CYShBA}{Q3QzlaG3QGazOwtUl7N75Q}{10.9.126.87}{10.9.126.87:9300} committed version [3] source [zen-disco-node-join[{es-master-594b58b86c-9jkj2}{x9Prp1VbTq6_kALQVNwIWg}{7NHUSVpuS0mFDTXzAeKRcg}{10.9.125.81}{10.9.125.81:9300}]]]) [2018-10-21T07:48:02,485][INFO ][oecsClusterApplierService] [es-master-594b58b86c-bj7g7] added {{es-data-0}{SAOhUiLiRkazskZ_TC6EBQ}{qirmfVJBTjSBQtHZnz-QZw}{10.9.126.88}{10.9.126.88:9300},}, reason: apply cluster state (from master [master {es-master-594b58b86c-bj7g7}{1aFT97hQQ7yiaBc2CYShBA}{Q3QzlaG3QGazOwtUl7N75Q}{10.9.126.87}{10.9.126.87:9300} committed version [4] source [zen-disco-node-join[{es-data-0}{SAOhUiLiRkazskZ_TC6EBQ}{qirmfVJBTjSBQtHZnz-QZw}{10.9.126.88}{10.9.126.88:9300}]]]) [2018-10-21T07:48:21,984][INFO ][oecsClusterApplierService] [es-master-594b58b86c-bj7g7] added {{es-data-1}{fiv5Wh29TRWGPumm5ypJfA}{EXqKGSzIQquRyWRzxIOWhQ}{10.9.125.82}{10.9.125.82:9300},}, reason: apply cluster state (from master [master {es-master-594b58b86c-bj7g7}{1aFT97hQQ7yiaBc2CYShBA}{Q3QzlaG3QGazOwtUl7N75Q}{10.9.126.87}{10.9.126.87:9300} committed version [5] source [zen-disco-node-join[{es-data-1}{fiv5Wh29TRWGPumm5ypJfA}{EXqKGSzIQquRyWRzxIOWhQ}{10.9.125.82}{10.9.125.82:9300}]]]) [2018-10-21T07:50:51,245][INFO ][oecsClusterApplierService] [es-master-594b58b86c-bj7g7] added {{es-client-69b84b46d8-v5pj2}{MMjA_tlTS7ux-UW44i0osg}{rOE4nB_jSmaIQVDZCjP8Rg}{10.9.125.83}{10.9.125.83:9300},}, reason: apply cluster state (from master [master {es-master-594b58b86c-bj7g7}{1aFT97hQQ7yiaBc2CYShBA}{Q3QzlaG3QGazOwtUl7N75Q}{10.9.126.87}{10.9.126.87:9300} committed version [6] source [zen-disco-node-join[{es-client-69b84b46d8-v5pj2}{MMjA_tlTS7ux-UW44i0osg}{rOE4nB_jSmaIQVDZCjP8Rg}{10.9.125.83}{10.9.125.83:9300}]]]) [2018-10-21T07:50:58,964][INFO ][oecsClusterApplierService] [es-master-594b58b86c-bj7g7] added {{es-client-69b84b46d8-kr7j4}{gGC7F4diRWy2oM1TLTvNsg}{IgI6g3iZT5Sa0HsFVMpvvw}{10.9.124.82}{10.9.124.82:9300},}, reason: apply cluster state (from master [master {es-master-594b58b86c-bj7g7}{1aFT97hQQ7yiaBc2CYShBA}{Q3QzlaG3QGazOwtUl7N75Q}{10.9.126.87}{10.9.126.87:9300} committed version [7] source [zen-disco-node-join[{es-client-69b84b46d8-kr7j4}{gGC7F4diRWy2oM1TLTvNsg}{IgI6g3iZT5Sa0HsFVMpvvw}{10.9.124.82}{10.9.124.82:9300}]]]) 10.9.125.82} {10.9.125.82 root$ kubectl -n elasticsearch get pods -l role=data NAME READY STATUS RESTARTS AGE es-data-0 1/1 Running 0 48s es-data-1 1/1 Running 0 28s -------------------------------------------------------------------- root$ kubectl apply -f es-client.yml root$ kubectl -n elasticsearch get pods -l role=client NAME READY STATUS RESTARTS AGE es-client-69b84b46d8-kr7j4 1/1 Running 0 47s es-client-69b84b46d8-v5pj2 1/1 Running 0 47s -------------------------------------------------------------------- root$ kubectl -n elasticsearch get all NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE deploy/es-client 2 2 2 2 1m deploy/es-master 3 3 3 3 9m NAME DESIRED CURRENT READY AGE rs/es-client-69b84b46d8 2 2 2 1m rs/es-master-594b58b86c 3 3 3 9m NAME DESIRED CURRENT AGE statefulsets/es-data 2 2 3m NAME READY STATUS RESTARTS AGE po/es-client-69b84b46d8-kr7j4 1/1 Running 0 1m po/es-client-69b84b46d8-v5pj2 1/1 Running 0 1m po/es-data-0 1/1 Running 0 3m po/es-data-1 1/1 Running 0 3m po/es-master-594b58b86c-9jkj2 1/1 Running 0 9m po/es-master-594b58b86c-bj7g7 1/1 Running 0 9m po/es-master-594b58b86c-lfpps 1/1 Running 0 9m NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE svc/elasticsearch LoadBalancer 10.9.121.160 10.9.120.8 9200:32310/TCP 1m svc/elasticsearch-data ClusterIP None <none> 9300/TCP 3m svc/elasticsearch-discovery ClusterIP None <none> 9300/TCP 9m -------------------------------------------------------------------- #Check logs of es-master leader pod root$ kubectl -n elasticsearch logs po/es-master-594b58b86c-bj7g7 | grep ClusterApplierService [2018-10-21T07:41:53,731][INFO ][oecsClusterApplierService] [es-master-594b58b86c-bj7g7] new_master {es-master-594b58b86c-bj7g7}{1aFT97hQQ7yiaBc2CYShBA}{Q3QzlaG3QGazOwtUl7N75Q}{10.9.126.87}{10.9.126.87:9300}, added {{es-master-594b58b86c-lfpps}{wZQmXr5fSfWisCpOHBhaMg}{50jGPeKLSpO9RU_HhnVJCA}{10.9.124.81}{10.9.124.81:9300},}, reason: apply cluster state (from master [master {es-master-594b58b86c-bj7g7}{1aFT97hQQ7yiaBc2CYShBA}{Q3QzlaG3QGazOwtUl7N75Q}{10.9.126.87}{10.9.126.87:9300} committed version [1] source [zen-disco-elected-as-master ([1] nodes joined)[{es-master-594b58b86c-lfpps}{wZQmXr5fSfWisCpOHBhaMg}{50jGPeKLSpO9RU_HhnVJCA}{10.9.124.81}{10.9.124.81:9300}]]]) [2018-10-21T07:41:55,162][INFO ][oecsClusterApplierService] [es-master-594b58b86c-bj7g7] added {{es-master-594b58b86c-9jkj2}{x9Prp1VbTq6_kALQVNwIWg}{7NHUSVpuS0mFDTXzAeKRcg}{10.9.125.81}{10.9.125.81:9300},}, reason: apply cluster state (from master [master {es-master-594b58b86c-bj7g7}{1aFT97hQQ7yiaBc2CYShBA}{Q3QzlaG3QGazOwtUl7N75Q}{10.9.126.87}{10.9.126.87:9300} committed version [3] source [zen-disco-node-join[{es-master-594b58b86c-9jkj2}{x9Prp1VbTq6_kALQVNwIWg}{7NHUSVpuS0mFDTXzAeKRcg}{10.9.125.81}{10.9.125.81:9300}]]]) [2018-10-21T07:48:02,485][INFO ][oecsClusterApplierService] [es-master-594b58b86c-bj7g7] added {{es-data-0}{SAOhUiLiRkazskZ_TC6EBQ}{qirmfVJBTjSBQtHZnz-QZw}{10.9.126.88}{10.9.126.88:9300},}, reason: apply cluster state (from master [master {es-master-594b58b86c-bj7g7}{1aFT97hQQ7yiaBc2CYShBA}{Q3QzlaG3QGazOwtUl7N75Q}{10.9.126.87}{10.9.126.87:9300} committed version [4] source [zen-disco-node-join[{es-data-0}{SAOhUiLiRkazskZ_TC6EBQ}{qirmfVJBTjSBQtHZnz-QZw}{10.9.126.88}{10.9.126.88:9300}]]]) [2018-10-21T07:48:21,984][INFO ][oecsClusterApplierService] [es-master-594b58b86c-bj7g7] added {{es-data-1}{fiv5Wh29TRWGPumm5ypJfA}{EXqKGSzIQquRyWRzxIOWhQ}{10.9.125.82}{10.9.125.82:9300},}, reason: apply cluster state (from master [master {es-master-594b58b86c-bj7g7}{1aFT97hQQ7yiaBc2CYShBA}{Q3QzlaG3QGazOwtUl7N75Q}{10.9.126.87}{10.9.126.87:9300} committed version [5] source [zen-disco-node-join[{es-data-1}{fiv5Wh29TRWGPumm5ypJfA}{EXqKGSzIQquRyWRzxIOWhQ}{10.9.125.82}{10.9.125.82:9300}]]]) [2018-10-21T07:50:51,245][INFO ][oecsClusterApplierService] [es-master-594b58b86c-bj7g7] added {{es-client-69b84b46d8-v5pj2}{MMjA_tlTS7ux-UW44i0osg}{rOE4nB_jSmaIQVDZCjP8Rg}{10.9.125.83}{10.9.125.83:9300},}, reason: apply cluster state (from master [master {es-master-594b58b86c-bj7g7}{1aFT97hQQ7yiaBc2CYShBA}{Q3QzlaG3QGazOwtUl7N75Q}{10.9.126.87}{10.9.126.87:9300} committed version [6] source [zen-disco-node-join[{es-client-69b84b46d8-v5pj2}{MMjA_tlTS7ux-UW44i0osg}{rOE4nB_jSmaIQVDZCjP8Rg}{10.9.125.83}{10.9.125.83:9300}]]]) [2018-10-21T07:50:58,964][INFO ][oecsClusterApplierService] [es-master-594b58b86c-bj7g7] added {{es-client-69b84b46d8-kr7j4}{gGC7F4diRWy2oM1TLTvNsg}{IgI6g3iZT5Sa0HsFVMpvvw}{10.9.124.82}{10.9.124.82:9300},}, reason: apply cluster state (from master [master {es-master-594b58b86c-bj7g7}{1aFT97hQQ7yiaBc2CYShBA}{Q3QzlaG3QGazOwtUl7N75Q}{10.9.126.87}{10.9.126.87:9300} committed version [7] source [zen-disco-node-join[{es-client-69b84b46d8-kr7j4}{gGC7F4diRWy2oM1TLTvNsg}{IgI6g3iZT5Sa0HsFVMpvvw}{10.9.124.82}{10.9.124.82:9300}]]])
Los registros del módulo principal principal muestran claramente cuándo se agrega cada nodo al clúster. Esto es útil para saber cuándo depurar.
Hemos implementado todos los componentes y ahora debemos verificar:
1) Implemente Elasticsearch desde un clúster de Kubernetes utilizando un contenedor de Ubuntu.
root$ kubectl run my-shell --rm -i --tty --image ubuntu -- bash root@my-shell-68974bb7f7-pj9x6:/# curl http://elasticsearch.elasticsearch:9200/_cluster/health?pretty { "cluster_name" : "my-es", "status" : "green", "timed_out" : false, "number_of_nodes" : 7, "number_of_data_nodes" : 2, "active_primary_shards" : 0, "active_shards" : 0, "relocating_shards" : 0, "initializing_shards" : 0, "unassigned_shards" : 0, "delayed_unassigned_shards" : 0, "number_of_pending_tasks" : 0, "number_of_in_flight_fetch" : 0, "task_max_waiting_in_queue_millis" : 0, "active_shards_percent_as_number" : 100.0 }
2) Implemente Elasticsearch desde fuera del clúster a través de la IP del equilibrador interno GCP (en nuestro caso, 10.9.120.8 ).
root$ curl http://10.9.120.8:9200/_cluster/health?pretty { "cluster_name" : "my-es", "status" : "green", "timed_out" : false, "number_of_nodes" : 7, "number_of_data_nodes" : 2, "active_primary_shards" : 0, "active_shards" : 0, "relocating_shards" : 0, "initializing_shards" : 0, "unassigned_shards" : 0, "delayed_unassigned_shards" : 0, "number_of_pending_tasks" : 0, "number_of_in_flight_fetch" : 0, "task_max_waiting_in_queue_millis" : 0, "active_shards_percent_as_number" : 100.0 }
3) Reglas anti-afinidad para hogares ES.
root$ kubectl -n elasticsearch get pods -o wide NAME READY STATUS RESTARTS AGE IP NODE es-client-69b84b46d8-kr7j4 1/1 Running 0 10m 10.8.14.52 gke-cluster1-pool1-d2ef2b34-t6h9 es-client-69b84b46d8-v5pj2 1/1 Running 0 10m 10.8.15.53 gke-cluster1-pool1-42b4fbc4-cncn es-data-0 1/1 Running 0 12m 10.8.16.58 gke-cluster1-pool1-4cfd808c-kpx1 es-data-1 1/1 Running 0 12m 10.8.15.52 gke-cluster1-pool1-42b4fbc4-cncn es-master-594b58b86c-9jkj2 1/1 Running 0 18m 10.8.15.51 gke-cluster1-pool1-42b4fbc4-cncn es-master-594b58b86c-bj7g7 1/1 Running 0 18m 10.8.16.57 gke-cluster1-pool1-4cfd808c-kpx1 es-master-594b58b86c-lfpps 1/1 Running 0 18m 10.8.14.51 gke-cluster1-pool1-d2ef2b34-t6h9
Tenga en cuenta que no tenemos dos hogares similares en el mismo nodo, por lo que garantizamos una alta confiabilidad en caso de falla del nodo.
Escalamiento
Podemos implementar servicios de autoescalado para nodos de clientes en función del límite de CPU. Ejemplo de HPA para un nodo de cliente:
apiVersion: autoscaling/v1 kind: HorizontalPodAutoscaler metadata: name: es-client namespace: elasticsearch spec: maxReplicas: 5 minReplicas: 2 scaleTargetRef: apiVersion: extensions/v1beta1 kind: Deployment name: es-client targetCPUUtilizationPercentage: 80
El autoescalado agrega pods en el nodo del cliente al cluster, y esto se puede ver en los registros de cualquier pod en el nodo maestro.
Para los pods en los nodos de datos , solo necesita aumentar el número de réplicas en el panel de control de Kubernetes o en la consola GKE. El nodo de datos creado se agregará al clúster y comenzará a replicar datos de otros nodos.
No necesito autoescalar en los nodos maestros : solo almacenan datos sobre el estado del clúster. Pero si va a agregar nodos de datos, asegúrese de que el número de nodos maestros en el clúster sea impar y no olvide cambiar la variable NUMBER_OF_MASTERS para el entorno.
Implementar Kibana y ES-HQ
Kibana y ES-HQ
Kibana es una herramienta simple para visualizar datos de ES, y ES-HQ ayuda a administrar y monitorear el clúster de Elasticsearch. Al implementar Kibana y ES-HQ, recuerde que:
- Pasamos el nombre del clúster ES a la imagen de Docker como una variable de entorno.
- El servicio de acceso a la implementación de Kibana / ES-HQ permanece dentro de la empresa, es decir, no se crea una IP pública. Utilizamos el equilibrador de carga interno de GCP.
Implementar Kibana
kind: Namespace metadata: name: elasticsearch --- apiVersion: apps/v1beta1 kind: Deployment metadata: name: es-kibana namespace: elasticsearch labels: component: elasticsearch role: kibana spec: replicas: 1 template: metadata: labels: component: elasticsearch role: kibana spec: containers: - name: es-kibana image: docker.elastic.co/kibana/kibana-oss:6.2.2 env: - name: CLUSTER_NAME value: my-es - name: ELASTICSEARCH_URL value: http://elasticsearch:9200 resources: limits: cpu: 0.5 ports: - containerPort: 5601 name: http --- apiVersion: v1 kind: Service metadata: name: kibana annotations: cloud.google.com/load-balancer-type: "Internal" namespace: elasticsearch labels: component: elasticsearch role: kibana spec: selector: component: elasticsearch role: kibana ports: - name: http port: 80 targetPort: 5601 protocol: TCP type: LoadBalancer view rawes-kibana.yml hosted with love by GitHub
(Implementación y servicio Kibana)
Implementar ES-HQ
kind: Namespace metadata: name: elasticsearch --- apiVersion: apps/v1beta1 kind: Deployment metadata: name: es-hq namespace: elasticsearch labels: component: elasticsearch role: hq spec: replicas: 1 template: metadata: labels: component: elasticsearch role: hq spec: containers: - name: es-hq image: elastichq/elasticsearch-hq:release-v3.4.0 env: - name: HQ_DEFAULT_URL value: http://elasticsearch:9200 resources: limits: cpu: 0.5 ports: - containerPort: 5000 name: http --- apiVersion: v1 kind: Service metadata: name: hq annotations: cloud.google.com/load-balancer-type: "Internal" namespace: elasticsearch labels: component: elasticsearch role: hq spec: selector: component: elasticsearch role: hq ports: - name: http port: 80 targetPort: 5000 protocol: TCP type: LoadBalancer view rawes-hq.yml hosted with love by GitHub
(Implementación y servicio ES-HQ)
Accedemos a ambos servicios a través del equilibrador interno creado.
root$ kubectl -n elasticsearch get svc -l role=kibana NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kibana LoadBalancer 10.9.121.246 10.9.120.10 80:31400/TCP 1m root$ kubectl -n elasticsearch get svc -l role=hq NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE hq LoadBalancer 10.9.121.150 10.9.120.9 80:31499/TCP 1m
http: // <External-Ip-Kibana-Service> / app / kibana # / home? _g = ()
(Panel de control de Kibana)
http: // <External-Ip-ES-Hq-Service> / #! / clusters / my-es
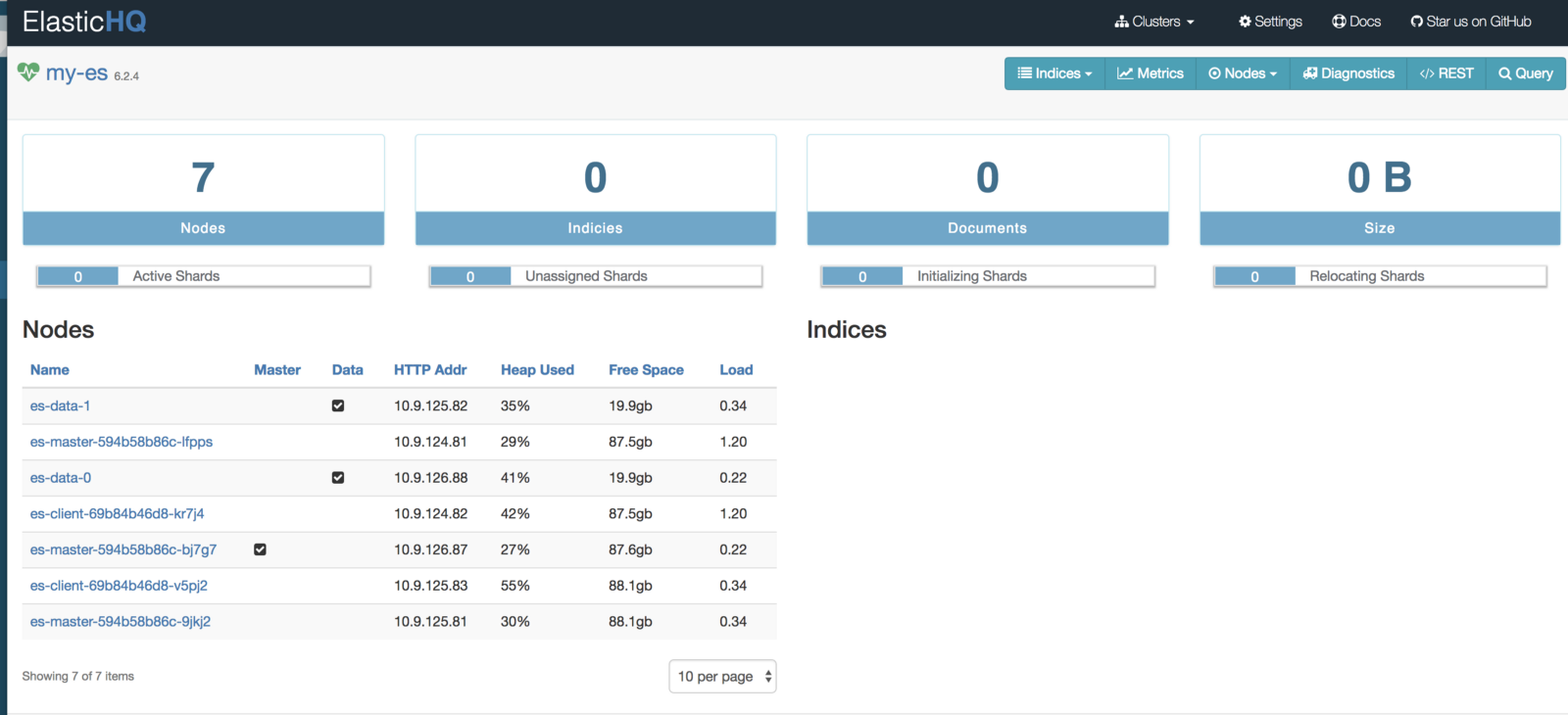
(Panel de control ElasticHQ para monitorear y administrar el clúster)
ES es uno de los sistemas de búsqueda y análisis distribuidos más populares, y en Kubernetes resuelve los problemas clave de escalado y alta disponibilidad. Además, los nuevos clústeres de ES en Kubernetes se implementan instantáneamente.