Ayer recibí una carta de un estudiante de décimo grado de Siberia que quiere convertirse en un desarrollador de microprocesadores. Ella ya obtuvo algunos resultados en esta área: agregó la instrucción de multiplicación al procesador schoolMIPS más simple, lo sintetizó para el FPGA Intel FPGA MAX10, determinó la frecuencia máxima y aumentó la productividad de los programas simples. Primero hizo todo esto en el pueblo de Burmistrovo, región de Novosibirsk, y luego en una conferencia en Tomsk.
Ahora Dasha Krivoruchko (ese es el nombre del estudiante de décimo grado) se mudó a vivir en un internado de Moscú y me pregunta qué más debería diseñar. Creo que en esta etapa de su carrera, debería diseñar un acelerador de hardware para redes neuronales basado en una matriz sistólica para la multiplicación de matrices. Utilice el lenguaje de descripción de hardware Verilog y el FPGA Intel FPGA, pero no el MAX10 barato, sino algo más costoso para acomodar una gran matriz sistólica.
Después de eso, compare el rendimiento de la solución de hardware con el programa que se ejecuta en el procesador schoolMIPS, así como con el programa Python que se ejecuta en la computadora de escritorio. Como caso de prueba, use el reconocimiento de números de una matriz pequeña.

En realidad, todas las partes de este ejercicio ya han sido desarrolladas por diferentes personas, pero el objetivo es poner esto en un solo ejercicio documentado, que luego puede usarse como base para el curso en línea y para las competiciones prácticas:
1) eNano, el departamento educativo de RUSNANO, que en el pasado organizó seminarios de Charles Danchek sobre el diseño de la electrónica moderna (ruta RTL a GDSII) para estudiantes y actualmente está trabajando en un curso en línea de este tipo (diseño de hardware en el nivel de transferencias de registros + redes neuronales) está interesado curso lite para estudiantes avanzados. Aquí Charles y yo estamos en su oficina:

2) La base para los Juegos Olímpicos puede estar interesada en
los Juegos Olímpicos del NTI , con los que planteé este tema hace un par de semanas en Moscú. Para tal ejemplo, los participantes en las olimpiadas podrían agregar un hardware para diferentes funciones de activación. Aquí hay colegas de los Juegos Olímpicos de NTI:

Entonces, si Dasha desarrolla esto, teóricamente podría presentar su acelerador bien descrito tanto en RUSNANO como en la Olimpiada de NTI. Creo que sería beneficioso para la administración de su escuela: podría mostrarse en televisión o enviarse al concurso Intel FPGA en general. Aquí hay un
par de rusos de San Petersburgo en la final del concurso Intel FPGA en Santa Clara, California :

Ahora hablemos del lado técnico del proyecto. La idea del acelerador de masa sistólica se describe en un artículo traducido por el editor de Khabra Vyacheslav Golovanov
SLY_G ¿ Por qué los TPU son tan adecuados para el aprendizaje profundo?Así es como se ve un gráfico de red neuronal de flujo de datos para un fácil reconocimiento:

Un elemento computacional primitivo que realiza multiplicaciones y sumas:

Una estructura altamente canalizada de tales elementos, esta matriz sistólica para la multiplicación de matrices es:

En Internet hay un montón de código en Verilog y VHDL con la implementación de una matriz sistólica, por ejemplo, el código se encuentra
en esta publicación de blog :

module top(clk,reset,a1,a2,a3,b1,b2,b3,c1,c2,c3,c4,c5,c6,c7,c8,c9); parameter data_size=8; input wire clk,reset; input wire [data_size-1:0] a1,a2,a3,b1,b2,b3; output wire [2*data_size:0] c1,c2,c3,c4,c5,c6,c7,c8,c9; wire [data_size-1:0] a12,a23,a45,a56,a78,a89,b14,b25,b36,b47,b58,b69; pe pe1 (.clk(clk), .reset(reset), .in_a(a1), .in_b(b1), .out_a(a12), .out_b(b14), .out_c(c1)); pe pe2 (.clk(clk), .reset(reset), .in_a(a12), .in_b(b2), .out_a(a23), .out_b(b25), .out_c(c2)); pe pe3 (.clk(clk), .reset(reset), .in_a(a23), .in_b(b3), .out_a(), .out_b(b36), .out_c(c3)); pe pe4 (.clk(clk), .reset(reset), .in_a(a2), .in_b(b14), .out_a(a45), .out_b(b47), .out_c(c4)); pe pe5 (.clk(clk), .reset(reset), .in_a(a45), .in_b(b25), .out_a(a56), .out_b(b58), .out_c(c5)); pe pe6 (.clk(clk), .reset(reset), .in_a(a56), .in_b(b36), .out_a(), .out_b(b69), .out_c(c6)); pe pe7 (.clk(clk), .reset(reset), .in_a(a3), .in_b(b47), .out_a(a78), .out_b(), .out_c(c7)); pe pe8 (.clk(clk), .reset(reset), .in_a(a78), .in_b(b58), .out_a(a89), .out_b(), .out_c(c8)); pe pe9 (.clk(clk), .reset(reset), .in_a(a89), .in_b(b69), .out_a(), .out_b(), .out_c(c9)); endmodule module pe(clk,reset,in_a,in_b,out_a,out_b,out_c); parameter data_size=8; input wire reset,clk; input wire [data_size-1:0] in_a,in_b; output reg [2*data_size:0] out_c; output reg [data_size-1:0] out_a,out_b; always @(posedge clk)begin if(reset) begin out_a<=0; out_b<=0; out_c<=0; end else begin out_c<=out_c+in_a*in_b; out_a<=in_a; out_b<=in_b; end end endmodule
Observo que este código no está optimizado y generalmente es torpe (e incluso no escrito profesionalmente; la fuente en la publicación usa asignaciones de bloque en @ (posedge clk); lo arreglé). Dasha podría, por ejemplo, usar Verilog para generar construcciones para un código más elegante.
Además de dos realizaciones extremas de la red neuronal (en el procesador y en la matriz sistólica), Dasha podría considerar otras opciones que son más rápidas que el procesador, pero no tan voraces como las operaciones de multiplicación como una matriz sistólica. Es cierto que esto es más probable no para los escolares, sino para los estudiantes.
Una opción es un dispositivo de ejecución con una gran cantidad de bloques de funciones que funcionan en paralelo, como en un procesador fuera de servicio:

Otra opción es la denominada matriz reconfigurable de grano grueso, una matriz de elementos cuasi-procesador, cada uno de los cuales tiene un pequeño programa. Estos elementos del procesador son idealmente similares a las celdas FPGA / FPGA, pero no funcionan con señales individuales, sino con grupos de bits / números en buses y registros. Vea el
informe en vivo desde el nacimiento de un jugador importante en hardware AI, que acelera TensorFlow y compite con NVidia ". .
Ahora la carta original de Dasha:
Buen dia, Yuri.
En 2017, estudié en su escuela en LSHUP en su taller y en octubre de 2017 participé en una conferencia en Tomsk en octubre del mismo año con el trabajo dedicado a integrar la unidad de multiplicación en el procesador SchooolMIPS.
Me gustaría continuar este trabajo ahora. Por el momento, logré obtener permiso en la escuela para tomar este tema como un pequeño curso. ¿Tiene la oportunidad de ayudarme con la continuación de este trabajo?
PD Dado que el trabajo se realiza en un formato específico, se requiere escribir una introducción y una revisión bibliográfica del tema. Indique las fuentes de las que puede obtener información sobre la historia del desarrollo de este tema, sobre filosofías arquitectónicas, etc., si tiene en mente tales recursos.
Además, en el momento en que vivo en Moscú en un internado, puede ser más fácil interactuar.
Saludos
Daria Krivoruchko.
Dasha enseñó Verilog y diseño de nivel de registro con la ayuda de mí y el libro
"Digital Circuitry and Computer Architecture" de David Harris y Sarah Harris . Sin embargo, si eres un colegial / colegiala y quieres comprender los conceptos básicos a un nivel muy simple, entonces la editorial DMK-Press ha lanzado una
traducción al ruso del manga japonés 2013 sobre circuitos digitales creados por Amano Hideharu y Meguro Koji. A pesar de la forma frívola de presentación, el libro introduce correctamente los elementos lógicos y los desencadenantes D,
y luego los vincula a los FPGA :
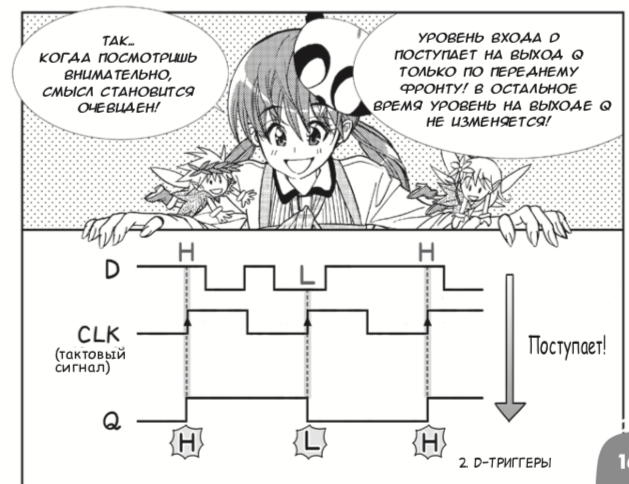
Así es como se veía la
Escuela de Verano para Jóvenes Programadores en la Región de Novosibirsk, donde Dasha aprendió Verilog, FPGA, una metodología de desarrollo de transferencia de registro (Nivel de transferencia de registro - RTL):


Y aquí está el discurso de Dasha en la conferencia en Tomsk junto con otro estudiante de décimo grado, Arseniy Chegodaev:
Después de la conversación de Dasha conmigo y con Stanislav Zhelnio
sparf , el creador principal del núcleo del procesador educativo schoolMIPS para la implementación de FPGA:

El proyecto schoolMIPS se encuentra con documentación en
https://github.com/MIPSfpga/schoolMIPS . En la configuración más simple de este núcleo de procesador de entrenamiento, solo hay 300 líneas en Verilog, mientras que en el núcleo industrial integrado de la clase media hay alrededor de 300 mil líneas. Sin embargo, Dasha pudo sentir cómo es el trabajo de los diseñadores en la industria, que cambian el decodificador y el dispositivo de ejecución de la misma manera cuando agregan nuevas instrucciones al procesador:
En conclusión, presentamos fotografías del decano de la Universidad de Samara, Ilya Kudryavtsev, quien está interesado en crear una escuela de verano y olimpiadas con procesadores FPGA para futuros solicitantes:

Y una foto de los empleados de Zelenograd MIET que ya están planeando tal escuela de verano el próximo año:

Tanto los materiales de RUSNANO como los posibles materiales de los Juegos Olímpicos del NTI, así como los logros alcanzados durante los últimos años en la implementación de FPGA y microarquitectura en el programa del HSE MIEM, la Universidad Estatal de Moscú y
Kazan Innopolis, deberían funcionar bien en un lugar y en otro.