En X5 procesamos muchos datos en un sistema ERP. Se cree que nadie más nos procesa en SAP ERP y SAP BW en Rusia. Pero hay otro punto: el número de operaciones y la carga en este sistema está aumentando rápidamente. Durante 3 años "luchamos" por el rendimiento de nuestro peso pesado ERP, obtuvimos muchos conos y con qué métodos fueron tratados, contamos debajo del corte.

ERP X5
Ahora X5 opera más de 13,000 tiendas. La mayoría de los procesos de negocio de cada uno de ellos pasa por un único sistema ERP. Cada tienda puede tener de 3,000 a 30,000 productos, esto crea problemas con la carga en el sistema, porque los procesos de recálculo regular de precios pasan por él de acuerdo con promociones y requisitos legislativos y el cálculo de reposición de inventarios. Todo esto es crítico, y si no se calcula a tiempo qué productos se deben entregar a la tienda mañana o qué precio debería estar en los productos, los compradores no encontrarán lo que estaban buscando en los estantes o no podrán comprar los productos al precio de la promoción actual existencias En general, además de contabilizar las transacciones financieras, el sistema ERP es responsable de gran parte de la vida cotidiana de cada tienda.
Un poco de características de rendimiento de un sistema ERP. Su arquitectura es clásica, de tres niveles con elementos orientados al servicio: además tenemos más de 5,000 clientes y terabytes de flujos de información desde tiendas y centros de distribución, en la capa de aplicación: SAP ABAP con más de 10,000 procesos y, finalmente, Oracle Database con más de 100 TB de datos. Cada proceso ABAP es una máquina virtual condicional que ejecuta la lógica empresarial de ABAP con su propio dialecto DBSL y SQL, almacenamiento en caché, gestión de memoria, ORM, etc. Todos los días recibimos más de 15 Tb de cambios en el registro de la base de datos. El nivel de carga es de 500,000 solicitudes por segundo.
Esta arquitectura es un entorno heterogéneo. Cada uno de los componentes es multiplataforma, podemos moverlo a diferentes plataformas, elegir las óptimas, etc.
El hecho de que el sistema ERP esté bajo carga las 24 horas del día los 365 días del año agrega combustible al fuego. Disponibilidad: 99.9% del tiempo durante todo el año. La carga se divide en perfiles diurnos y nocturnos y mantenimiento de la casa en el tiempo libre.
Pero eso no es todo. El sistema tiene un ciclo de liberación apretado y apretado. Lleva más de 2,000 cambios de lotes por año. Este puede ser un botón nuevo y cambios serios en la lógica de las aplicaciones comerciales.

Como resultado, es un sistema grande y altamente cargado, pero al mismo tiempo estable, predecible y listo para el crecimiento que puede albergar a decenas de miles de tiendas. Pero ese no fue siempre el caso.
2014. Punto de bifurcación
Para sumergirse en el material práctico, debe volver al 2014. Luego estaban las tareas más difíciles para optimizar el sistema. Había alrededor de 5,000 tiendas.
El sistema en ese momento estaba en tal estado que la mayoría de los procesos críticos no eran escalables y no respondían adecuadamente a la carga creciente (es decir, la aparición de nuevas tiendas y productos). Además, dos años antes, se compró un Hi-End costoso, y durante algún tiempo una actualización no fue parte de nuestros planes. Además, los procesos en ERP ya estaban a punto de violar SLA. El proveedor concluyó que la carga en el sistema no es escalable. Nadie sabía si podía soportar al menos + 10% del aumento de carga. Y se planeó abrir el doble de tiendas en tres años.
Era imposible alimentar simplemente el sistema ERP con hierro nuevo, y no ayudaría. Por lo tanto, en primer lugar, decidimos incluir una técnica de optimización de software en el ciclo de lanzamiento y seguir la regla: el crecimiento de carga lineal en proporción al crecimiento de los controladores de carga es la clave para la previsibilidad y la escalabilidad.
¿Cuál fue la técnica de optimización? Este es un proceso cíclico, dividido en varias etapas:
- monitoreo (identificar cuellos de botella en el sistema e identificar los principales consumidores de recursos)
- análisis (perfilado de procesos de consumo, identificación de estructuras con el mayor efecto no lineal sobre la carga)
- desarrollo (reduciendo la influencia de las estructuras en la carga, logrando una carga lineal)
- pruebas en un entorno de evaluación de calidad o implementación en un entorno productivo
A continuación, se repitió el ciclo.
En el proceso, nos dimos cuenta de que las herramientas de monitoreo actuales no nos permiten identificar rápidamente a los principales consumidores, identificar cuellos de botella y procesos que consumen muchos recursos. Por lo tanto, para acelerar, probamos las herramientas de búsqueda elástica y Grafana. Para hacer esto, desarrollaron de forma independiente recopiladores que, desde herramientas de monitoreo estándar en Oracle / SAP / AIX / Linux, transfirieron métricas a búsqueda elástica y permitieron el monitoreo en tiempo real del estado del sistema. Además, enriquecieron el monitoreo con sus métricas personalizadas, por ejemplo, el tiempo de respuesta y el rendimiento de componentes específicos de SAP o el diseño de perfiles de carga para procesos comerciales.
Optimización de código y proceso.
En primer lugar, por un menor efecto de los cuellos de botella en la velocidad, aseguraron un suministro de carga más fluido al sistema.
La mayoría de los procesos comerciales en nuestro sistema ERP, por ejemplo, como la planificación regular de precios o la reposición de inventario, son procesos secuenciales paso a paso de una gran cantidad de datos (para todos los productos y todas las tiendas). Para implementar el procesamiento en el marco de tareas tan difíciles, en un momento desarrollamos nuestro propio administrador de procesamiento paralelo por lotes (en lo sucesivo, el planificador de carga). En este caso, en forma de paquete, se presenta un paso de procesamiento realizado por separado para una tienda separada.
Inicialmente, la lógica del planificador era tal que primero se ejecutaban los paquetes de la primera etapa de procesamiento para todas las tiendas, luego los paquetes de la segunda etapa, etc. Es decir, el sistema realizó simultáneamente procesos que crearon el mismo tipo de carga y causaron la degradación de ciertos recursos (entrada / salida a la base de datos o CPU en los servidores de aplicaciones, etc.).
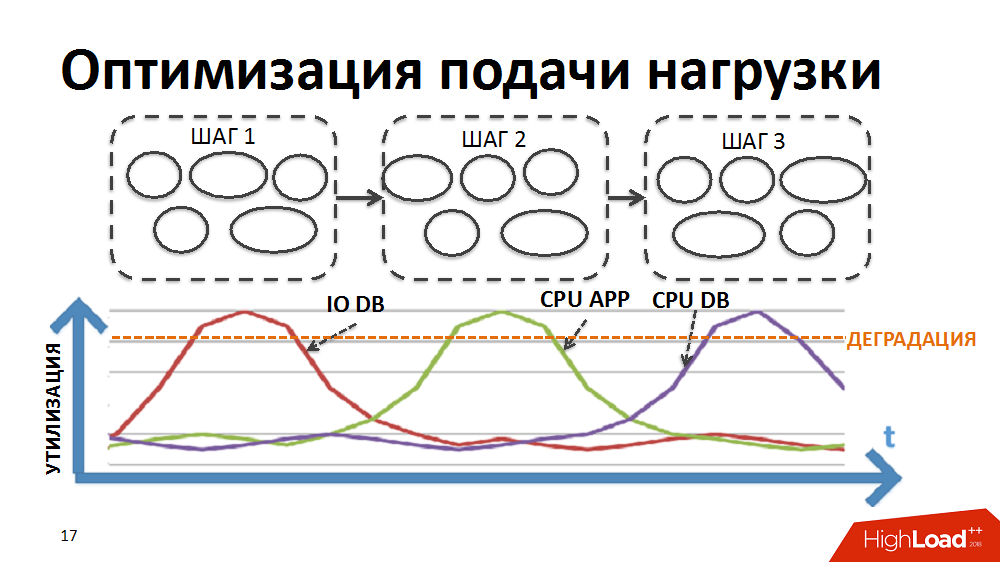
Reescribimos la lógica del planificador para que la cadena de paquetes se formara por separado para cada tienda y la prioridad de lanzar nuevos paquetes no se construyera por etapas, sino por tiendas.
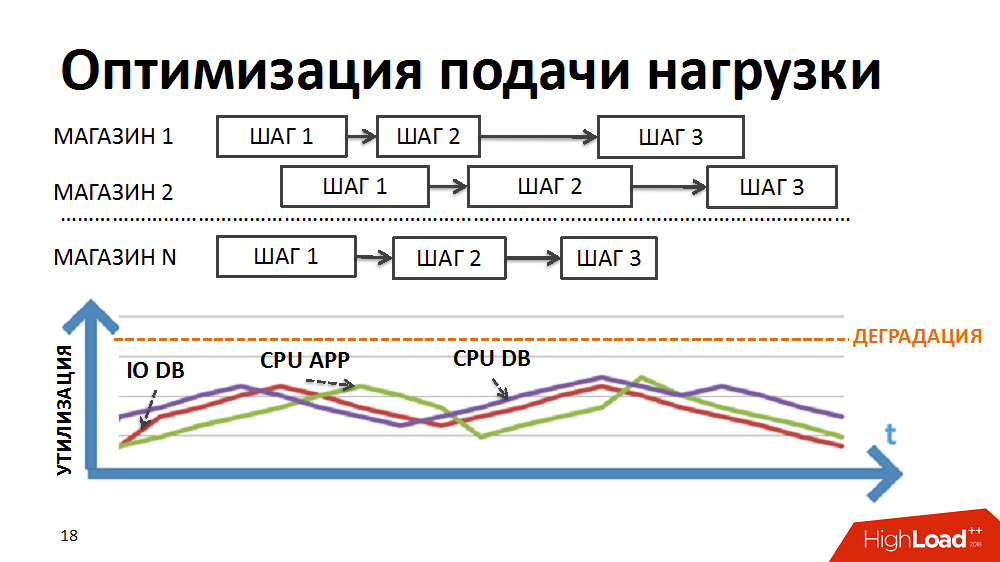
Debido a la diferente duración de los paquetes para diferentes tiendas y al gran número controlado de procesos ejecutados simultáneamente en el marco de las tareas del planificador de carga, hemos logrado la ejecución simultánea de procesos heterogéneos, una carga más suave de la carga y la eliminación de algunos cuellos de botella.
Luego comenzaron a optimizar diseños individuales. Cada paquete individual fue revisado, perfilado y ensamblado, diseños no óptimos y enfoques aplicados para optimizarlos. Posteriormente, estos enfoques se incluyeron en las reglamentaciones del desarrollador para evitar el crecimiento de carga indeseable durante el desarrollo del sistema. Algunos de ellos:
- carga excesiva en la CPU de los servidores de aplicaciones (a menudo generados por algoritmos no lineales en el código del programa, por ejemplo, la buena búsqueda lineal en bucles o algoritmos no lineales para encontrar intersecciones de conjuntos de elementos desordenados, etc.) Se trató reemplazando con algoritmos lineales: reemplace la búsqueda lineal en bucles con binarios; para buscar intersecciones de conjuntos, utilizamos algoritmos lineales, elementos de preordenamiento, etc.)
- llamadas idénticas a la base de datos con las mismas condiciones dentro del mismo proceso a menudo conducen a una utilización excesiva de la CPU de la base de datos (se trata almacenando en caché los resultados de la primera muestra en la memoria del programa o en el nivel del servidor de aplicaciones y utilizando datos en caché para muestras posteriores)
- solicitudes de unión frecuentes (es mejor ejecutarlas, por supuesto, a nivel de la base de datos, pero a veces nos permitimos dividirlas en muestras simples, cuyo resultado se almacena en caché y transferir la lógica de pegado a la aplicación. Esos son casos en los que es mejor calentar el servidor de aplicaciones y no la base de datos). )
- solicitudes de unión pesadas que resultan en muchas E / S
Sobre esto último con más detalle. En este caso, el modelo de datos se tradujo a una forma menos normal. Un ejemplo clásico es una selección de documentos contables para una fecha específica para una tienda individual. Muchos empleados lo solicitan. La tabla maestra (tabla de encabezados) almacena las fechas de los documentos, en la tabla de posiciones: la tienda y las mercancías. Las consultas más comunes son una selección de todos los documentos para una tienda en particular para una fecha específica. Con esta solicitud, el filtro por fecha en la tabla de encabezados da 500 mil registros, el filtro por tienda, la misma cantidad. Al mismo tiempo, después de pegar en una tienda separada para la fecha correcta, tenemos un plazo de 3 mil. No importa de qué tabla empecemos a filtrar y pegar datos, siempre obtenemos muchas E / S no deseadas.
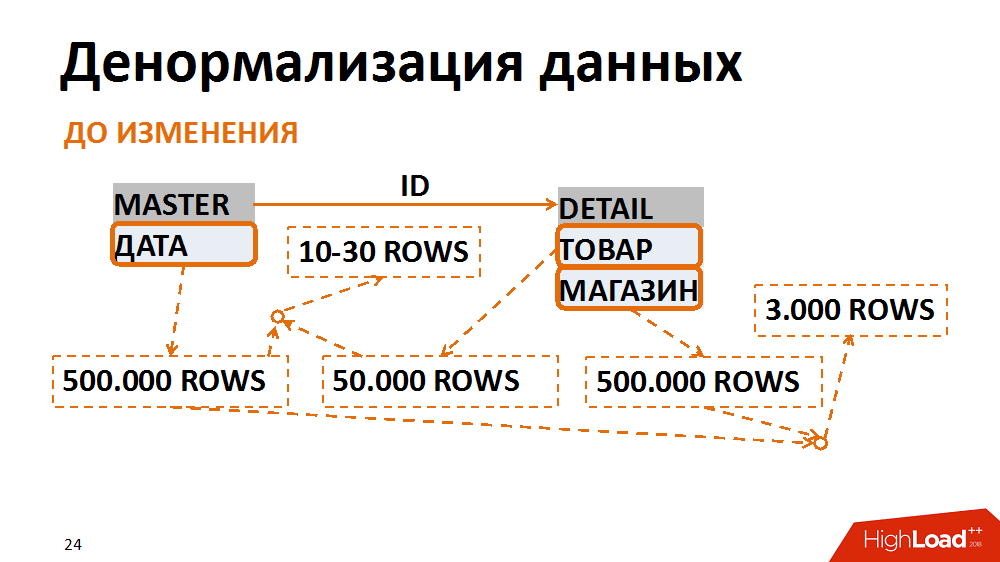
Esto se puede evitar presentando los datos en una forma menos normal. En un caso, el campo de fecha se duplicó en la tabla de posición, se rellenó al crear documentos, los índices se recopilaron para una búsqueda rápida y ya se filtraron de acuerdo con la tabla de posición. Por lo tanto, después de haber sacrificado gastos generales insignificantes para almacenar un nuevo campo e índices, hemos reducido varias veces la cantidad de operaciones de entrada / salida generadas por consultas problemáticas.

2015. El problema de un servicio
Durante un año y medio, hicimos un gran trabajo al optimizar el sistema, se ha vuelto más predecible. Sin embargo, los planes para duplicar el número de tiendas siguen siendo relevantes, por lo que los desafíos aún nos enfrentamos.
En el camino encontramos varios cuellos de botella. Por ejemplo, a fines de 2015, se dieron cuenta de que habían descansado en el desempeño de un servicio central de la plataforma. Este es un servicio de bloqueo lógico SAP ABAP. Por eso, el sistema claramente no resistiría el crecimiento de la carga. Pérdidas de grandes cantidades de dinero aparecieron en el horizonte.
Para aclarar, la tarea del servicio es llevar la transaccionalidad lógica al nivel del servidor de aplicaciones. En ABAP, una sola transacción puede pasar por varios pasos en diferentes flujos de trabajo. Para que la transacción se complete, hay un servicio de bloqueo y mecanismos relacionados. Las operaciones de bloqueo y desbloqueo ocurren rápidamente, pero son atómicas, no se pueden separar. Hubo un problema con la E / S sincrónica.
El servicio se aceleró un poco después de que los desarrolladores de SAP lanzaron un parche especial, cambiamos el servicio a otro hardware y trabajamos en la configuración del sistema, pero esto aún no fue suficiente. El límite máximo del servicio de pasaportes era de aproximadamente 7 mil operaciones por segundo, y durante mucho tiempo ya necesitábamos 10 mil.
Después de la prueba de carga sintética, se descubrió que la degradación no es lineal y, sin embargo, estamos en el límite de rendimiento del servicio por encima del cual se manifiesta la degradación inaceptable de todo el sistema ERP. Las repetidas llamadas a los desarrolladores solo dieron un veredicto decepcionante: el servicio funciona correctamente, solo requerimos demasiado en la arquitectura de la solución actual. Incluso si nos comprometiéramos de inmediato a rehacer toda la arquitectura de la solución, nos llevaría varios meses mantener la operatividad del sistema actual.
Una de las primeras opciones para tratar de extender la vida útil de un servicio de bloqueo es acelerar la E / S y escribir en el sistema de archivos. Que? Experimentos con una alternativa a AIX. Transferí el servicio a Linux en el Power-machine más potente y ganó mucho tiempo de respuesta. El servicio con el sistema de archivos activado se comportó igual que en Aix con los deshabilitados. Luego transferimos este código a uno de los blades x86_64 y obtuvimos una curva de rendimiento con una pendiente aún más fantástica que antes. Se veía gracioso.
Se podría suponer que los desarrolladores de AIX y Linux hicieron algo diferente en la última prueba, pero la arquitectura del procesador también tuvo un efecto aquí.
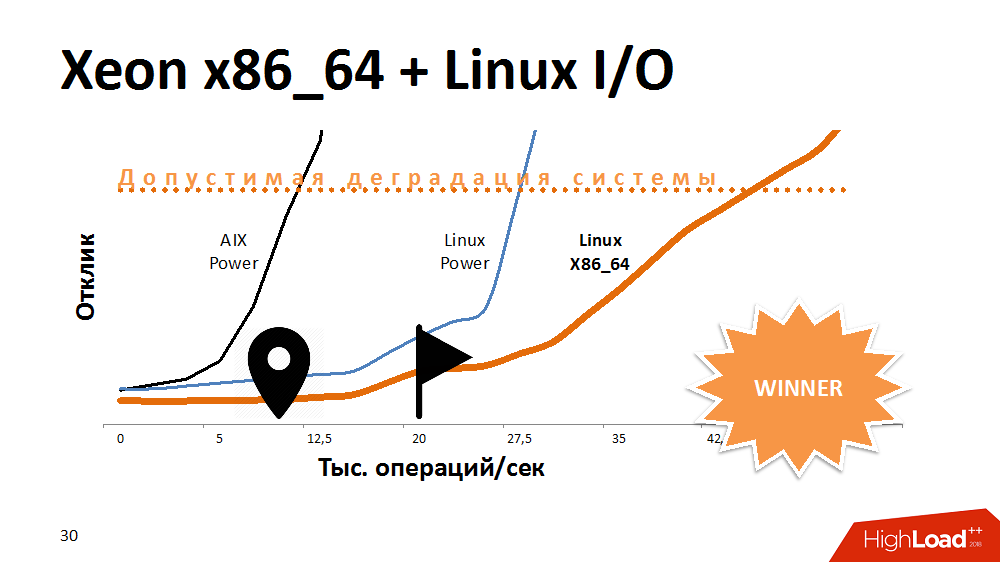
¿Cuál fue la conclusión? Algunas plataformas son ideales para bases de datos de subprocesos múltiples, ya que proporcionan rendimiento y tolerancia a fallas, pero un procesador en una arquitectura diferente puede hacer frente mejor a tareas específicas. Si al comienzo de construir una solución para abandonar la plataforma cruzada, puede perder espacio para maniobras en el futuro.
Sin embargo, descubrimos este problema y el servicio comenzó a funcionar 3-4 veces más rápido, lo que es suficiente para un crecimiento muy largo.
2016. cuello de botella de CPU DB
Literalmente, seis meses después, comenzaron a sentirse problemas exóticos con la CPU en la base de datos. Parece claro que con un aumento en la carga, aumenta el consumo de recursos del procesador. Pero SysTime comenzó a ocupar la mayor parte, y claramente había un problema en el núcleo. Comenzaron a comprender, hacer pruebas de carga sintética y se dieron cuenta de que nuestro rendimiento era de 300 mil operaciones por segundo, es decir mil millones de solicitudes por hora, y luego degradación.
Como resultado, llegamos a la conclusión de que la solicitud perfecta es una que no existe. Expandimos nuestra técnica de optimización con nuevos enfoques y realizamos una auditoría del sistema ERP: comenzamos a buscar consultas, por ejemplo, con baja eficiencia (100 mil selecciones, como resultado de 100 líneas o 0 en general), para rehacer. Si no se pueden eliminar las solicitudes "vacías", déjelas ir al "caché negativo", si corresponde. Si muchas solicitudes de los mismos datos del producto se procesan en paralelo, entonces déjelos atormentar al servidor de aplicaciones y no a la base de datos, lo almacenaremos en caché. También "ampliamos" una gran cantidad de consultas individuales frecuentes en una clave dentro del marco de un proceso, reemplazándola con selecciones más raras en una parte de una clave. O, por ejemplo, para distribuir la carga en la cadena de procesamiento, se podrían realizar diferentes pasos en diferentes servidores de aplicaciones. Esto es bueno, pero en diferentes etapas pueden pedir lo mismo desde la base. Luego, deje el primer paso después de comenzar en la aplicación caché parte de las solicitudes, y permanece allí para finalizar el resto de la cadena.

Con la ayuda de tales trucos, ganamos un poco en todas partes, pero al final descargamos seriamente la base. El sistema cobró vida. Mientras tanto, llegamos a Aix.
Otros experimentos revelaron que hay un límite de rendimiento: las ya mencionadas 300,000 llamadas de DataBase por segundo. La raíz del problema era el rendimiento de la interfaz de red, que tenía un límite máximo: alrededor de 300 mil paquetes por segundo en una dirección. A medida que el techo se acercaba, el tiempo de llamadas al sistema creció. Como resultó más tarde, también era un legado de la pila de red del núcleo AIX.
En general, nunca tuvimos problemas con la latencia, el núcleo de la red era productivo, todos los cables se ensamblaron en un gran canal indestructible en una interfaz. Hicimos una solución alternativa: dividimos toda la red entre los servidores de aplicaciones y la base de datos en grupos en diferentes interfaces. Como resultado, cada grupo de servidores de aplicaciones se comunicó con la base de datos a través de su propia interfaz separada. El rendimiento máximo de cada interfaz se redujo ligeramente, pero en total aceleramos la red a 1 millón de paquetes por segundo en una dirección.
Y el principio "La mejor solicitud es la que no existe" se agregó al Talmud para desarrolladores, para que esto se tenga en cuenta al escribir el código.
2017. Live para actualizar
Bueno, la última etapa de la recuperación de nuestro sistema, aprobada en 2017. Todo lo que quedaba era vivir un poco hasta la actualización y era necesario mantener el SLA por nada. El código fue optimizado, pero vimos que cuanto mayor es la carga en la CPU de la base de datos, más lento funcionan los procesos, aunque el margen de utilización fue del 10-20%. Inicialmente, se estimó que el 100% es el doble que el 50%. Y cuando hay una reserva del 10-20%, esto es del 10-20%. De hecho, con una carga superior al 67-80%, la duración de las tareas aumentó de forma no lineal, es decir La ley de Amdahl funcionó. El sistema tenía un límite de paralelización y cuando se superó, con la participación de un número cada vez mayor de procesadores en el trabajo, el rendimiento de cada procesador individual disminuyó.
En ese momento, utilizamos 125 procesadores físicos, o 500 lógicos, considerando el subprocesamiento múltiple en el nivel AIX. ¿Qué sugerirías? Actualizar? Incluso antes del final de su coordinación, era necesario esperar varios meses y no dejar caer el SLA.
En algún momento, se dieron cuenta de que las métricas de utilización del procesador tradicional no son indicativas para nosotros, no muestran el comienzo real de la degradación. Para una evaluación realista de la salud del sistema, comenzamos a utilizar la métrica integrada, el resultado de una prueba sintética como una métrica para el rendimiento del procesador de la base de datos. Una vez por minuto hicieron una prueba sintética, midieron su duración y mostraron esta métrica en nuestros monitores. Y reaccionaron si la métrica se elevaba por encima del punto crítico declarado. Detuvimos un poco la carga de nuestros planificadores de carga para que permaneciera en el área de "par máximo" de la base de datos.
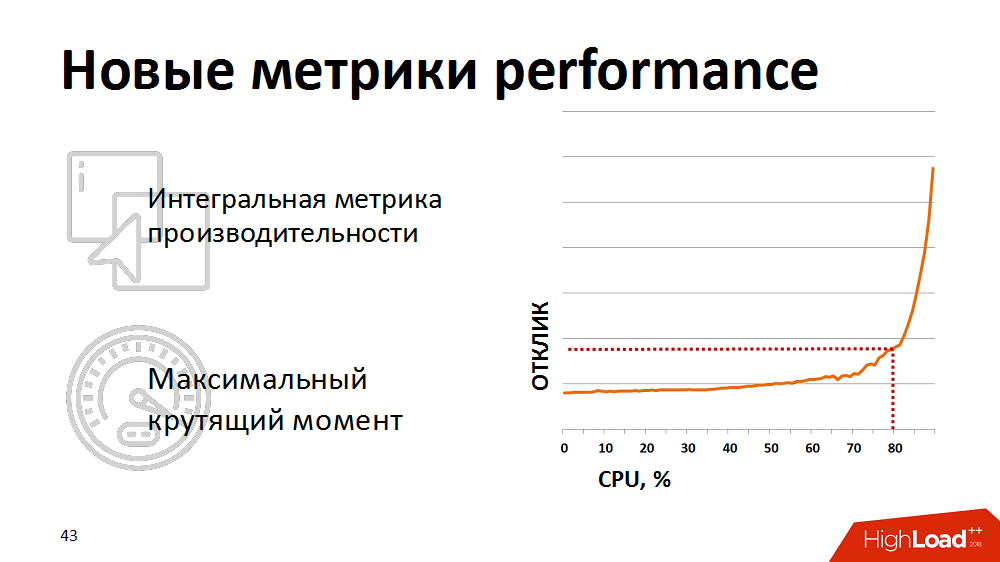
Sin embargo, el control manual no fue efectivo, y estábamos cansados de despertarnos por la noche. Luego reescribimos el planificador de carga para que recibiera comentarios sobre las métricas de rendimiento actuales. (. ), - . . , 80% , , -, .. .
, ERP
- , .
- ( ).
- , .
- , join- .
- , – , – .
- .
- , ; “ ” .
Highload , .
, , SAP #ITX5, #ITX5
SAP.