 Publicado por Ekaterina Semashko, Desarrollador Strong Junior iOS, DataArt
Publicado por Ekaterina Semashko, Desarrollador Strong Junior iOS, DataArtUn poco sobre el proyecto: una aplicación móvil para la plataforma iOS, escrita en Swift. El propósito de la aplicación es la capacidad de compartir tarjetas de descuento entre los empleados de la empresa y sus amigos.
Uno de los objetivos del proyecto era aprender y practicar tecnologías y bibliotecas populares. El reino fue elegido para almacenar datos locales, Alamofire se usó para trabajar con el servidor, Google Sign-In se usó para la autenticación, PINRemoteImage se usó para cargar imágenes.
Las principales funciones de la aplicación:
- agregar un mapa, editarlo y eliminarlo;
- ver las tarjetas de otras personas;
- buscar tarjetas por nombre de tienda / nombre de usuario;
- Agregue tarjetas a sus favoritos para un acceso rápido.
La capacidad de usar la aplicación sin conectarse a la red se asumió desde el principio, pero solo en modo de lectura. Es decir podríamos ver información sobre tarjetas, pero no podríamos modificarlas sin Internet. Para esto, la aplicación siempre tenía una copia de todas las tarjetas y marcas de la base de datos del servidor, además de una lista de favoritos para el usuario actual. La búsqueda también se implementó localmente.
Más tarde, decidimos expandirnos sin conexión agregando un modo de grabación. La información sobre los cambios realizados por el usuario se almacenó y sincronizó cuando apareció una conexión a Internet. Se discutirá la implementación de dicho modo fuera de línea de lectura-escritura.
¿Qué es necesario para un modo sin conexión completo en una aplicación móvil? Necesitamos eliminar la dependencia del usuario de la calidad de la conexión a Internet, en particular:
- Elimine la dependencia de las respuestas al usuario de sus acciones en la interfaz de usuario del servidor. En primer lugar, la solicitud interactuará con el almacenamiento local, luego se enviará al servidor.
- Marcar y almacenar cambios locales.
- Implemente un mecanismo de sincronización: cuando aparece una conexión a Internet, debe enviar los cambios al servidor.
- Mostrar al usuario qué cambios están sincronizados, cuáles no.
Enfoque sin conexión primero
En primer lugar, tuve que cambiar el mecanismo existente para interactuar con el servidor y la base de datos. El objetivo era evitar que el usuario dependiera de la presencia o ausencia de Internet. En primer lugar, debe interactuar con el almacén de datos local y las solicitudes del servidor deben pasar a un segundo plano.
En la versión anterior, había una fuerte conexión entre la capa de almacenamiento de datos y la capa de red. El mecanismo para trabajar con datos fue el siguiente: primero se realizó una solicitud al servidor a través de la clase NetworkManager, esperamos el resultado, luego los datos se guardaron en la base de datos a través de la clase Repository. Luego, el resultado fue dado a la interfaz de usuario, como se muestra en el diagrama.
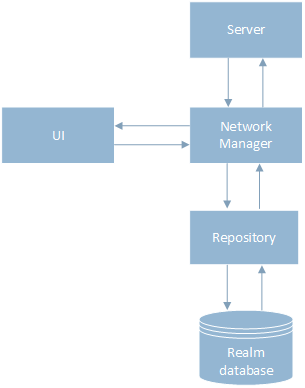
Para implementar el primer enfoque fuera de línea, separé la capa de almacenamiento de datos y la capa de red, introduciendo una nueva clase Flow que controlaba el orden en que se llamaba NetworkManager y Repository. Ahora los datos se guardan primero en la base de datos a través de la clase Repository, luego el resultado se envía a la interfaz de usuario y el usuario continúa trabajando con la aplicación. En segundo plano, se realiza una solicitud al servidor, después de la respuesta, se actualiza la información en la base de datos y la interfaz de usuario.
Trabajar con identificadores de objeto
Con la nueva arquitectura, aparecieron varias tareas nuevas, una de las cuales es trabajar con objetos de identificación. Anteriormente, los recibimos del servidor al crear el objeto. Pero ahora el objeto se creó localmente, por lo tanto, era necesario generar una identificación y después de la sincronización actualizarlos a los actuales. Aquí me encontré con la primera limitación de Realm: después de crear un objeto, no puedes cambiar su clave principal.
La primera opción era abandonar la clave primaria en el objeto, hacer id en un campo regular. Pero al mismo tiempo, se perdieron las ventajas de usar la clave primaria: la indexación de dominios, que acelera la búsqueda del objeto, la capacidad de actualizar el objeto con el indicador de creación (crear un objeto si no existe) y el cumplimiento de la unicidad del objeto.
Quería guardar la clave primaria, pero no podía ser la identificación del objeto del servidor. Como resultado, la solución de trabajo era tener dos identificadores, uno de ellos servidor, campo opcional, y el segundo local, que sería la clave principal.
Como resultado, se genera una identificación local en el cliente cuando se crea el objeto localmente, y en el caso de que el objeto provenga del servidor, es igual a la identificación del servidor. Dado que en la aplicación de fuente única de verdad hay una base de datos, cuando se reciben datos del servidor, el objeto se actualiza con el identificador local actual y solo funciona con él. Al enviar datos al servidor, se transmite el identificador del servidor.
Almacenamiento de cambios no sincronizados
Los cambios en los objetos que aún no se han enviado al servidor deben almacenarse localmente. Esto se puede implementar de las siguientes maneras:
- Agregar campos a objetos existentes
- almacenar objetos no sincronizados en tablas separadas;
- almacenar cambios de campo individuales en algún formato.
No uso objetos Realm directamente en mis clases, pero hago su mapeo por mi cuenta para evitar problemas con el subprocesamiento múltiple. Las actualizaciones automáticas de la interfaz se realizan utilizando ejemplos de resultados de actualización automática, donde me suscribo a las solicitudes de actualización. Solo el primer enfoque funcionó con mi arquitectura actual, por lo que la elección recayó en agregar campos a los objetos existentes.
El objeto del mapa ha sufrido la mayoría de los cambios:
- sincronizado: ¿hay datos en el servidor?
- eliminado: verdadero, si la tarjeta se elimina solo localmente, se requiere sincronización.
Identificadores que se discutieron en la parte anterior:
- localId: la clave principal de la entidad en la aplicación, ya sea igual a la identificación del servidor o generada localmente;
- serverId: identificación del servidor.
Por separado vale la pena mencionar es el almacenamiento de imágenes. En esencia, el campo Attachment diskURL se agregó al campo serverURL de la imagen en el servidor, que almacena la dirección de la imagen local no sincronizada. Al sincronizar la imagen, la local se eliminó para no obstruir la memoria del dispositivo.
Sincronización del servidor
Para sincronizar con el servidor, se agregó el trabajo con Accesibilidad, para que cuando aparezca Internet, se inicie el mecanismo de sincronización.
Primero, verifica si hay cambios en la base de datos que deben enviarse. Luego, se envía una solicitud al servidor para una transmisión de datos real, como resultado, los cambios que no es necesario enviar al cliente se descartan (por ejemplo, cambiar un objeto que ya se ha eliminado en el servidor). Los cambios restantes ponen en cola las solicitudes al servidor.
Para enviar cambios, fue posible implementar actualizaciones masivas, enviar los cambios en una matriz o hacer una solicitud grande para sincronizar todos los datos. Pero en ese momento, el desarrollador de back-end ya estaba ocupado en otro proyecto y solo nos ayudó en nuestro tiempo libre, por lo que creamos una solicitud para cada tipo de cambio.
Implementé la cola a través de OperationQueue y envolví cada solicitud en una operación asincrónica. Algunas operaciones dependen unas de otras, por ejemplo, no podemos cargar la imagen del mapa antes de crear el mapa, así que agregué la dependencia de la operación de la imagen a la operación del mapa. Además, la operación de cargar imágenes al servidor recibió una prioridad menor que todos los demás, y las agregué a la cola también duran debido a su gran peso.
Al planificar el modo fuera de línea, la gran pregunta era resolver conflictos con el servidor durante la sincronización. Pero cuando llegamos a este punto durante la implementación, nos dimos cuenta de que el caso en que un usuario cambia los mismos datos en diferentes dispositivos es muy raro. Por lo tanto, es suficiente para nosotros implementar el mecanismo del último escritor ganador. Durante la sincronización, siempre se da prioridad a los cambios no enviados en el cliente, no se eliminan.
El manejo de errores aún está en su infancia, si la sincronización falla, el objeto se agregará a la cola de cambios la próxima vez que aparezca Internet. Y luego, si aún no se sincroniza después de la fusión, el usuario decidirá si lo deja o lo elimina.
Solución adicional al trabajar con Realm
Cuando trabajas con Realm enfrentas varios problemas más. Quizás esta experiencia también sea útil para alguien.
Al ordenar por cadena, el orden va de acuerdo con el orden de los caracteres en UTF-8, no hay soporte de búsqueda entre mayúsculas y minúsculas. Nos enfrentamos a una situación en la que los nombres en minúscula van después de los nombres en mayúscula, por ejemplo: Imán, Pyaterochka, Cinta. Si la lista es muy grande, todos los nombres en minúsculas estarán en la parte inferior, lo cual es muy desagradable.
Para preservar el orden de clasificación, independientemente del caso, tuvimos que introducir un nuevo campo de nombre en minúsculas, actualizarlo al actualizar el nombre y ordenar por él.
Además, se agregó un nuevo campo para ordenar por la presencia de una tarjeta en los favoritos, ya que en esencia esto requiere una subconsulta para las relaciones del objeto.
Al buscar en Realm, existe el método CONTAINS [c]% @ para búsquedas que no distinguen entre mayúsculas y minúsculas. Pero, por desgracia, solo funciona con el alfabeto latino. Para las marcas rusas, también tuvimos que crear campos separados y buscarlos. Pero más tarde resultó estar en nuestras manos excluir caracteres especiales al buscar.
Como puede ver, para aplicaciones móviles es bastante posible implementar un modo fuera de línea con cambios de guardado y sincronización con poca sangre, y a veces incluso con cambios mínimos en el backend.
A pesar de algunas dificultades, puede usar Realm para implementarlo, mientras recibe todas las ventajas en forma de actualizaciones en vivo, arquitectura de copia cero y una API conveniente.
Por lo tanto, no hay ninguna razón para negar a sus usuarios el acceso a los datos en cualquier momento, independientemente de la calidad de la conexión.