
Todo comenzó cursi: durante un año, mi compañía ha estado pagando una tarifa mensual por un servicio que sabía cómo encontrar una región con placas en la foto. Esta función se utiliza para dibujar números automáticamente para algunos clientes.
Y un buen día, el Ministerio del Interior de Ucrania abrió el acceso al
registro de vehículos . ¡Ahora, usando la placa de matrícula, es posible verificar cierta información sobre el automóvil (marca, modelo, año de fabricación, color, etc.)! La aburrida rutina de la programación lineal se ha desvanecido antes de una nueva tarea: leer números en toda la base de fotos y validar estos datos con los que el usuario especificó. Usted mismo sabe cómo sucede "con los ojos iluminados": la llamada fue aceptada, todas las demás tareas se volvieron aburridas y monótonas por un tiempo ... Nos pusimos a trabajar y obtuvimos buenos resultados, que, de hecho, decidimos compartir con la comunidad.
Como referencia: en el sitio AUTO.RIA.com, se agregan alrededor de 100,000 fotos por día.
Los expertos en datos saben desde hace mucho tiempo y son capaces de resolver tales problemas, por lo que
dimabendera y
yo escribimos este artículo específicamente para programadores. Si no tienes miedo de la frase "redes convolucionales" y sabes cómo escribir "Hello World" en python, eres bienvenido bajo cat ...
¿Quién más reconoce
Hace un año estudié este mercado y resultó que no muchos servicios y software pueden funcionar con números de países exUSSR. A continuación se muestra una lista de las empresas con las que trabajamos:
- Existe una versión de código abierto y comercial. La versión de Opensource mostró una tasa de reconocimiento muy baja, además, requería dependencias específicas para su ensamblaje y operación (no nos gustó particularmente). La versión comercial, o más bien, el servicio comercial funciona bien. Capaz de trabajar con números rusos y ucranianos. Los precios son moderados: 49 $ / 50K reconocimientos por mes. Demostración en línea de OpenALPR
- Hemos estado usando este servicio durante aproximadamente un año. La calidad es buena Encuentra el área con el número muy bien. El servicio no sabe cómo trabajar con números ucranianos y europeos. Vale la pena señalar el buen trabajo con imágenes de baja calidad (en la nieve, foto de baja resolución, ...). El precio del servicio también es aceptable, pero son reacios a asumir pequeños volúmenes.
Hay muchos sistemas comerciales con software cerrado, pero no encontramos una buena implementación de código abierto. De hecho, esto es muy extraño, ya que las herramientas de código abierto que subyacen a la solución a este problema han existido durante mucho tiempo.
¿Qué herramientas se necesitan para reconocer los números?
Encontrar objetos en una imagen o en una secuencia de video es una tarea del campo de la visión por computadora, que se resuelve mediante diferentes enfoques, pero con mayor frecuencia con la ayuda de las llamadas redes neuronales convolucionales. Necesitamos encontrar no solo el área de la foto en la que se encuentra el objeto deseado, sino también separar todos sus puntos de otros objetos o el fondo. Este tipo de tarea se llama "Segmentación de instancia". La siguiente ilustración visualiza diferentes tipos de tareas de visión por computadora.
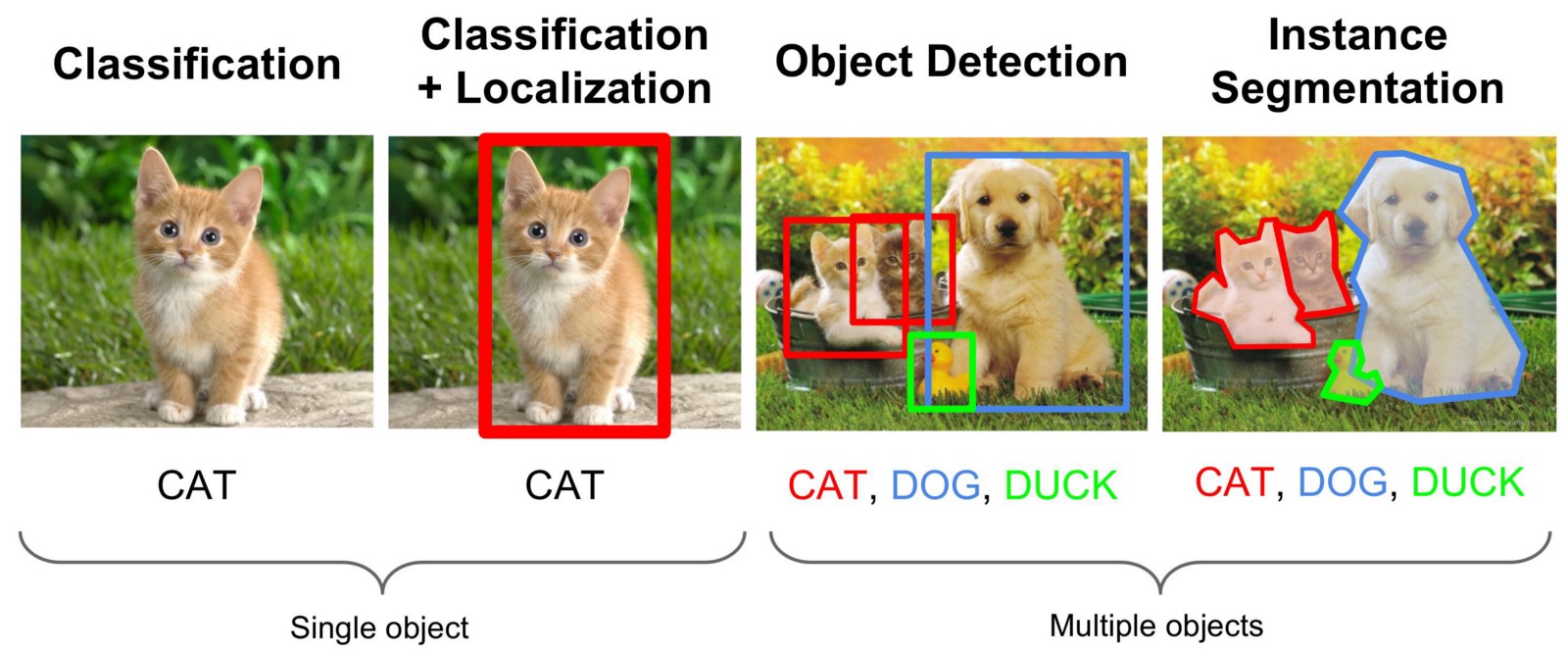
No escribiré mucha teoría sobre cómo funciona la red de convolución, esta información es suficiente en la red e informes en youtube.
Desde arquitecturas modernas de matrices convolucionales para tareas de segmentación, a menudo usan:
U-Net o
Mask R-CNN . Elegimos la máscara R-CNN.
La segunda herramienta que necesitamos es una biblioteca de reconocimiento de texto que pueda funcionar con diferentes idiomas y que pueda personalizarse fácilmente según los detalles de los textos que reconoceremos. Aquí la elección no es tan buena, la más avanzada es
tesseract de Google.
También hay una serie de herramientas menos "globales" con las que tendremos que normalizar el área con la placa de matrícula (tráela de tal manera que sea posible el reconocimiento de texto). Por lo general, opencv se usa para tales conversiones.
Además, será posible tratar de determinar el país y el tipo al que pertenece el número de placa, de modo que en el procesamiento posterior apliquemos una plantilla de refinamiento específica para este país y este tipo de número. Por ejemplo, la matrícula ucraniana, a partir de 2015, decorada en azul y amarillo, consiste en la plantilla "dos letras cuatro números dos letras".

Además, al tener estadísticas sobre la frecuencia de "reunión" en las placas de una combinación particular de letras o números, puede mejorar la calidad del procesamiento posterior en situaciones "controvertidas". "
Nomeroff net
Del título del artículo está claro que todos implementamos y
nombramos el proyecto
Nomeroff Net . Ahora parte del código para este proyecto ya está trabajando en producción en
AUTO.RIA.com . Por supuesto, todavía está lejos de los análogos comerciales; todo funciona bien solo para números ucranianos. Además, se alcanza una velocidad aceptable solo con el soporte del tensorflow del módulo GPU. Sin una GPU, también puedes probar, pero no en la Raspberry Pi :).
Todos los materiales para nuestro proyecto: conjuntos de datos marcados y modelos entrenados , publicamos públicamente con permiso de RIA.com bajo una licencia Creative Commons CC BY 4.0
Que necesitamos
- Python3
- opencv-python versión 3.4 o posterior
- Fresh Mask RCNN , tesseract
- a través del administrador de paquetes pip3 necesitará instalar varios módulos en python3, se enumerarán en un archivo require.txt separado
Dmitry y yo estamos corriendo en Fedora 28, estoy seguro de que todo se puede instalar en cualquier otra distribución de Linux. No quiero convertir esta publicación en instrucciones para instalar y configurar tensorflow, si quieres probar y algo no funciona, pregunta en los comentarios, te responderé y te lo diré.
Para acelerar la instalación, planeamos crear un dockerfile, espere en las próximas actualizaciones del proyecto.
Nomeroff Net "Hola mundo"
Intentemos reconocer algo. Estamos clonando un
repositorio con código de
github . Descargamos a la carpeta de modelos,
modelos entrenados para buscar y clasificar números, ajustaremos ligeramente las variables con la ubicación de las carpetas por nosotros mismos.
UPD: este código está en desuso, solo funcionará
en la rama 0.1.0 ,
consulte los últimos ejemplos aquí :
Todo puede ser reconocido:
import os import sys import json import matplotlib.image as mpimg
Demostración en línea
Esbozaron una
demostración simple para aquellos que no quieren instalar y ejecutar todo esto :). Sea indulgente y paciente con la velocidad del guión.
Si necesita ejemplos de números ucranianos (para verificar el funcionamiento de los algoritmos de corrección), tome un ejemplo
de esta carpeta.Que sigue
Entiendo que el tema es muy específico y es poco probable que genere un gran interés entre una amplia gama de programadores, además, el código y los modelos siguen siendo bastante "primarios" en términos de calidad de reconocimiento, velocidad, consumo de memoria, etc. Pero todavía hay esperanzas de que haya entusiastas quienes estarán interesados en modelos de capacitación para sus necesidades, su país, quienes lo ayudarán y le dirán dónde hay problemas y, junto con nosotros, harán que el proyecto no sea peor que sus contrapartes comerciales.
Problemas conocidos
- El proyecto no tiene documentación, solo ejemplos básicos de código.
- Como módulo de reconocimiento, se selecciona el tesseract universal de OCR y puede leer mucho, pero comete muchos errores. En el caso del reconocimiento de números ucranianos, allí se escribe un sistema de corrección especializado, que hasta ahora compensa algunos de los errores, pero existe el presentimiento de que aquí se puede hacer mucho más.
- Los números "cuadrados" (placas con una proporción de 1: 2) son bastante raros y acabamos de comenzar a tratarlos, por lo que habrá más errores con ellos.
- A veces, en lugar de una placa de matrícula, nuestro modelo encuentra señales de tráfico con el nombre de la aldea, un tablero de instrumentos dentro de la cabina y otros artefactos.
- Con baja calidad del número o baja resolución, una región de 4 puntos no está completamente determinada
Anuncio
Si será interesante para alguien, en la segunda parte vamos a hablar sobre cómo y cómo marcar su conjunto de datos y cómo capacitar a sus modelos que puedan funcionar mejor para su contenido (su país, el tamaño de su foto). También hablaremos sobre cómo crear su propio clasificador, que, por ejemplo, ayudará a determinar si el número está esbozado en la foto.
Algunos ejemplos en el cuaderno Jupyter:
Enlaces utiles