¿Alguna vez le han pedido que calcule la cantidad de algo basándose en los datos de la base de datos del último mes, agrupando el resultado por algunos valores y desglosándolo todo por día / hora?
Si es así, entonces ya te imaginas que tienes que escribir algo como esto, solo que peor
SELECT hour(datetime), somename, count(*), sum(somemetric) from table where datetime > :monthAgo group by 1, 2 order by 1 desc, 2
De vez en cuando, comienzan a aparecer una gran variedad de tales solicitudes, y si aguanta y ayuda una vez, lamentablemente, las apelaciones vendrán en el futuro.
Pero tales solicitudes son malas ya que consumen bien los recursos del sistema en tiempo de ejecución, y puede haber tantos datos que incluso una réplica para tales solicitudes será una pena (y su momento).
Pero, ¿qué sucede si digo que justo en PostgreSQL puede crear una vista que sobre la marcha solo tendrá en cuenta los nuevos datos entrantes en una consulta directamente similar, como se indicó anteriormente?
Entonces, puede hacer la extensión PipelineDB
Demo de su sitio como funciona PipelineDB era anteriormente un proyecto separado, pero ahora está disponible como una extensión para PG 10.1 y superior.
Y aunque las oportunidades ofrecidas han existido durante mucho tiempo en otros productos diseñados específicamente para recopilar métricas en tiempo real, PipelineDB tiene una ventaja significativa: un umbral de entrada más bajo para los desarrolladores que ya conocen SQL).
Quizás para algunos no sea esencial. Personalmente, no soy demasiado vago para probar todo lo que parece adecuado para resolver un problema en particular, pero no me moveré de inmediato para usar una nueva solución para todos los casos. Por lo tanto, en este artículo no insto a soltar todo e instalar PipelineDB de inmediato, esto es solo una descripción general de la funcionalidad principal, como La cosa me pareció curiosa.
Entonces, en general, tienen buena documentación, pero quiero compartir mi experiencia sobre cómo probar este negocio en la práctica y llevar los resultados a Grafana.
Para no tirar basura en la máquina local, implemento todo en la ventana acoplable.
Imágenes utilizadas:
postgres:latest ,
grafana/grafanaInstalar PipelineDB en Postgres
En una máquina con postgres, ejecute secuencialmente:
apt updateapt install curlcurl -s http://download.pipelinedb.com/apt.sh | bashapt install pipelinedb-postgresql-11cd /var/lib/postgresql/data- Abra el archivo
postgresql.conf en cualquier editor - Encuentre la clave
shared_preload_libraries , descomente y establezca el valor pipelinedb - Key
max_worker_processes establecido en 128 (muelles de recomendación) - Reiniciar el servidor
Crear una secuencia y una vista en PipelineDB
Después de reiniciar pg - mira los registros para que haya tal cosa - La base de datos en la que trabajaremos:
CREATE DATABASE testpipe; - Crear una extensión:
CREATE EXTENSION pipelinedb; - Ahora lo más interesante es crear una secuencia. Es en él que necesita agregar datos para su posterior procesamiento:
CREATE FOREIGN TABLE flow_stream ( dtmsk timestamp without time zone, action text, duration smallint ) SERVER pipelinedb;
De hecho, es muy similar a crear una tabla normal, no puede obtener datos de esta secuencia con una simple select : necesita una vista - en realidad cómo crearlo:
CREATE VIEW viewflow WITH (ttl = '3 month', ttl_column = 'm') AS select minute(dtmsk) m, action, count(*), avg(duration)::smallint, min(duration), max(duration) from flow_stream group by 1, 2;
Se denominan Vistas continuas y su material predeterminado es materializar, es decir. con preservacion de estado.
La WITH pasa parámetros adicionales.
En mi caso, ttl = '3 month' significa que necesita almacenar datos solo durante los últimos 3 meses y tomar la fecha / hora de la columna M El proceso de reaper segundo plano reaper datos obsoletos y los elimina.
Para aquellos que no están al tanto, la función de minute devuelve una fecha / hora sin segundos. Por lo tanto, todos los eventos que ocurrieron en un minuto tendrán el mismo tiempo como resultado de la agregación. - Tal vista es casi una tabla, porque el índice por fecha para el muestreo será útil si se almacenan muchos datos
create index on viewflow (m desc, action);
Usando PipelineDB
Recuerde: inserte datos en la secuencia y lea desde la vista que se suscribe
insert into flow_stream VALUES (now(), 'act1', 21); insert into flow_stream VALUES (now(), 'act2', 33); select * from viewflow order by m desc, action limit 4; select now()
Ejecuto la solicitud manualmente Primero veo cómo cambian los datos en el minuto 46
Tan pronto como llega el 47, el anterior deja de actualizarse y el minuto actual comienza a funcionar.
Si presta atención al plan de consulta, puede ver la tabla original con datos
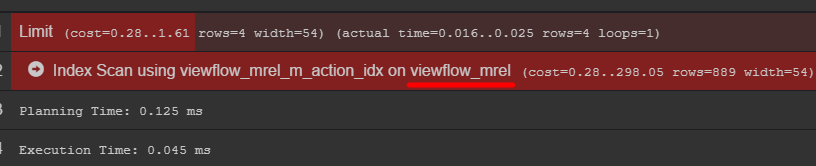
Recomiendo ir a él y descubrir cómo se almacenan realmente sus datos
Generador de eventos C # using Npgsql; using System; using System.Threading; namespace PipelineDbLogGenerator { class Program { private static Random _rnd = new Random(); private static string[] _actions = new string[] { "foo", "bar", "yep", "goal", "ano" }; static void Main(string[] args) { var connString = "Host=localhost;port=5432;Username=postgres;Database=testpipe"; using (var conn = new NpgsqlConnection(connString)) { conn.Open(); while (true) { var dt = DateTime.UtcNow; using (var cmd = new NpgsqlCommand()) { var act = GetAction(); cmd.Connection = conn; cmd.CommandText = "INSERT INTO flow_stream VALUES (@dtmsk, @action, @duration)"; cmd.Parameters.AddWithValue("dtmsk", dt); cmd.Parameters.AddWithValue("action", act); cmd.Parameters.AddWithValue("duration", GetDuration(act)); var res = cmd.ExecuteNonQuery(); Console.WriteLine($"{res} {dt}"); } Thread.Sleep(_rnd.Next(50, 230)); } } } private static int GetDuration(string act) { var c = 0; for (int i = 0; i < act.Length; i++) { c += act[i]; } return _rnd.Next(c); } private static string GetAction() { return _actions[_rnd.Next(_actions.Length)]; } } }
Conclusión en Grafana
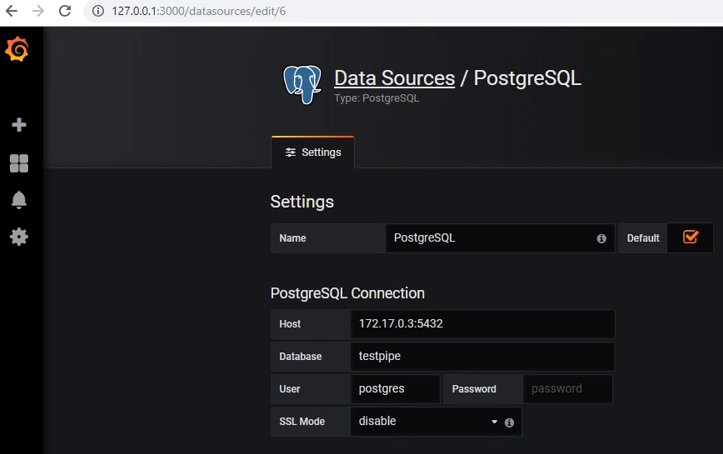
Para obtener datos de postgres, debe agregar la fuente de datos adecuada:
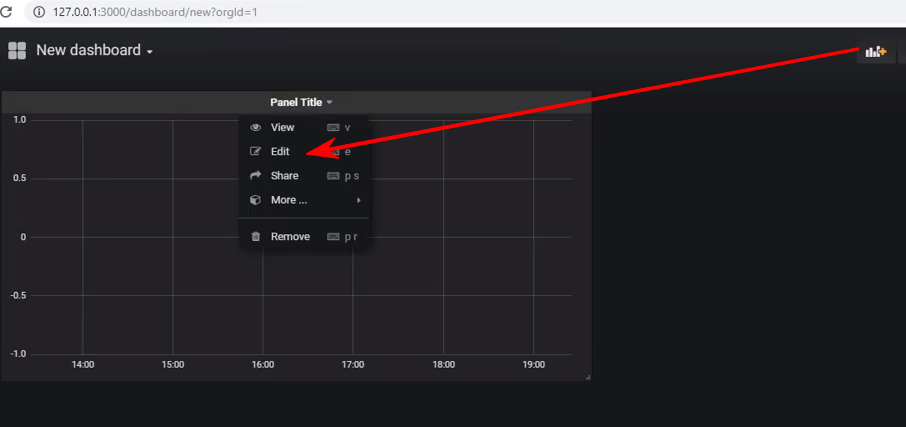
Cree un nuevo panel de control y agregue un panel de tipo Gráfico, y luego debe editar el panel:
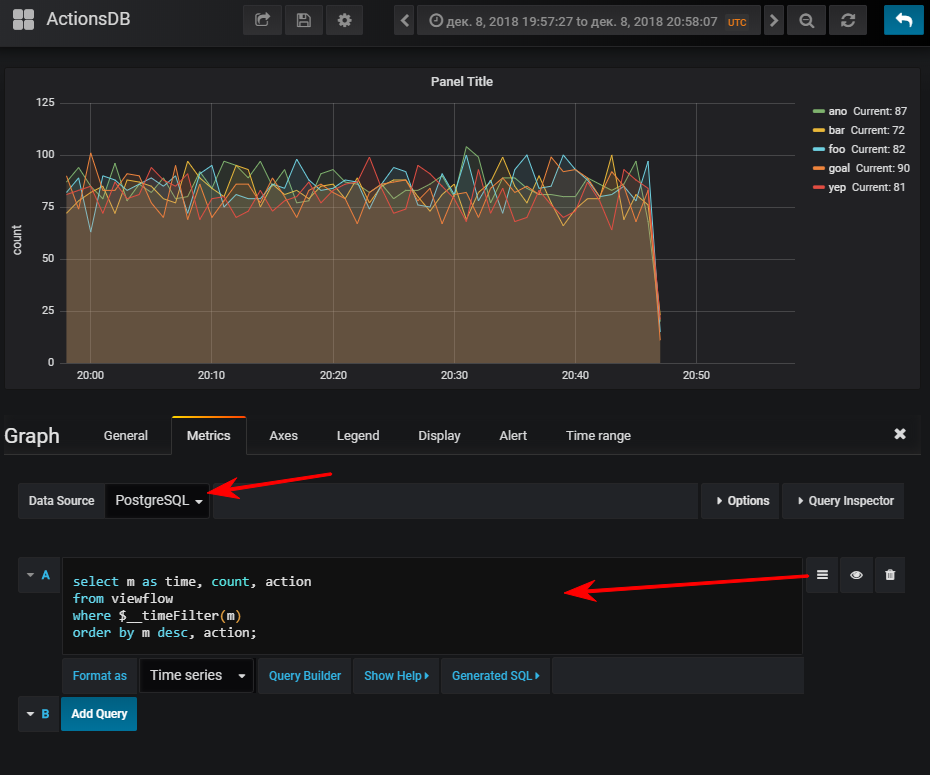
A continuación, seleccione una fuente de datos, cambie al modo de escritura sql-query e ingrese esto:
select m as time,
Y luego obtienes un horario normal, por supuesto, si iniciaste el generador de eventos
FYI: tener un índice puede ser muy importante. Aunque su uso depende del volumen de la tabla resultante. Si planea almacenar una pequeña cantidad de filas en un corto período de tiempo, puede resultar muy fácil que la exploración secuencial sea más barata, y el índice solo agregará más. cargar al actualizar valores
Se pueden suscribir varias vistas a una secuencia.
Supongamos que quiero ver cuántos métodos de API realizan los percentiles.
CREATE VIEW viewflow_per WITH (ttl = '3 d', ttl_column = 'm') AS select minute(dtmsk) m, action, percentile_cont(0.50) WITHIN GROUP (ORDER BY duration)::smallint p50, percentile_cont(0.95) WITHIN GROUP (ORDER BY duration)::smallint p95, percentile_cont(0.99) WITHIN GROUP (ORDER BY duration)::smallint p99 from flow_stream group by 1, 2; create index on viewflow_per (m desc);
Hago el mismo truco con grafana y obtengo: Total
En general, la cosa está funcionando, se comportó bien, sin quejas. Aunque bajo el docker, la descarga de su base de datos de demostración en el archivo (2,3 GB) resultó ser un poco larga.
Quiero señalar: no realicé pruebas de estrés.
Documentación oficialPuede ser interesante