
Del 6 al 7 de diciembre, se celebró la quinta conferencia de Heisenbag en Moscú.
Su eslogan es "Pruebas. ¡No solo para los probadores! ”, Y durante dos años de visitas regulares a los Heisenbags, yo (anteriormente desarrollador de Java, ahora líder técnico en una pequeña empresa que nunca había trabajado en QA) logré aprender mucho en las pruebas e implementar mucho en nuestro equipo. Quiero compartir una revisión subjetiva de los informes que recuerdo esta vez.
Descargo de responsabilidad. Por supuesto, esto es solo una pequeña fracción (8 de 30) de los informes seleccionados en función de mis preferencias personales. Casi todos estos informes están relacionados de alguna manera con Java y no hay uno solo sobre desarrollo front-end y móvil. En algunos lugares me permitiré una polémica con el hablante. Si está interesado en una revisión más completa y neutral, por tradición debería aparecer
en el blog de los organizadores . Pero, tal vez, será interesante que alguien descubra esos informes a los que no podría acudir.
Las fotos en el artículo son del twitter oficial de la conferencia.Baruch Sadogursky. Tenemos DevOps Vamos a despedir a todos los probadores
 (En la foto, el bombo cuando Baruch distribuyó el libro Liquid Software )
(En la foto, el bombo cuando Baruch distribuyó el libro Liquid Software )Quienes participan en Java y asisten a las conferencias del Grupo JUGRU, Baruch Sadogursky no necesita presentación. Sin embargo, actuó por primera vez en el Heisenbug.
En pocas palabras: fue un informe de revisión sobre las ideas principales de DevOps. La necesidad de la audiencia de tales informes sigue siendo, porque cuando se le pregunta "Dé la definición de DevOps" a la audiencia, la gente aún responde "Esta es esa persona ..."
Pero incluso aquellos que ya han aprendido algo sobre este tema, será muy interesante conocer los estudios de la asociación DORA
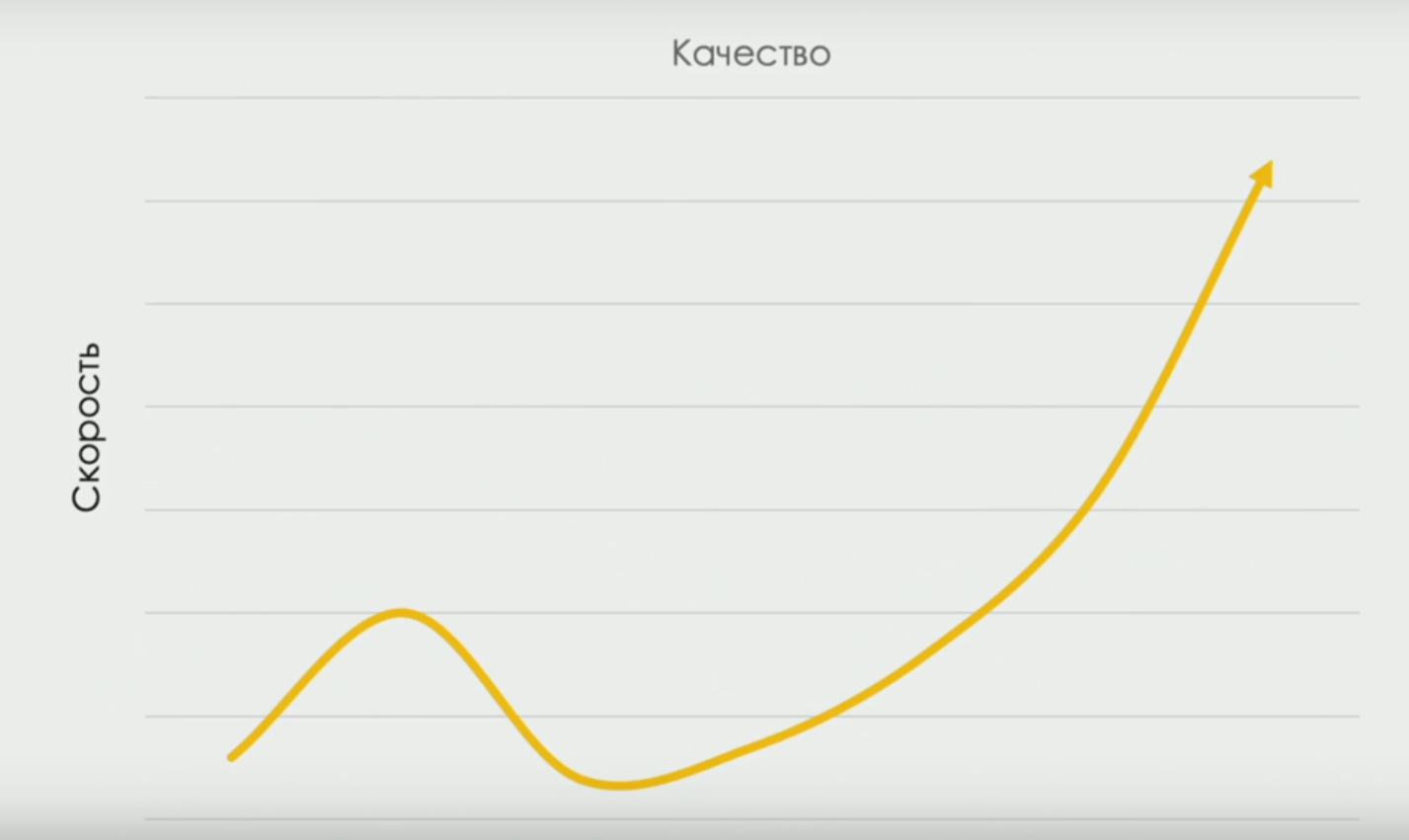
devops-research.com , que recibió porcentajes de variedades de trabajo manual en equipos con diferente rendimiento. Y sobre la curva que conecta la velocidad de entrega y la calidad (en algún momento, la velocidad disminuye, porque necesitamos tiempo para "probar mejor", pero a medida que el equipo se desarrolla, la correlación se vuelve directa):
Aunque el título del informe era provocativo, y en el calendario el informe estaba marcado con la categoría "arderá", su contenido, en mi opinión, era bastante convencional. Por supuesto, no se trataba del despido de los evaluadores bajo las condiciones de la transformación Devops, sino de un cambio en la naturaleza del trabajo de los evaluadores.
Alan Page y Nikolai Alimenkov hablaron mucho sobre estas cosas hace un año. Tanto los roles cambiantes como el desarrollo "horizontal" de las habilidades en forma de T se discutieron hace un año en la mesa redonda "
lo que un probador debe saber en 2018 ".
“Por supuesto, si no quieres cambiar, hay trabajo para ti, aunque no tan interesante. Hasta ahora, todavía hay trabajo para aquellos que desean soportar sistemas escritos en COBOL en los años 70 ", dijo Baruch.
Artyom Eroshenko. ¿Necesita refactorizar un proyecto? ¡Ten una IDEA!

Artyom conoce a los participantes de Heisenbag con informes sobre el sistema de informes de Allure (por ejemplo,
aquí está su informe sobre las oportunidades de Allure que apareció en 2018 del anterior Heisenbag en San Petersburgo). Allure en sí nació en el contexto de proyectos con miles, decenas de miles e incluso más de cientos de miles de pruebas y está diseñado para simplificar la interacción entre desarrolladores y evaluadores. Tiene la capacidad de vincular pruebas con recursos externos como sistemas de tickets y confirmaciones en el sistema de control de versiones. En nuestro microequipo, mientras que el recuento de pruebas fue solo de decenas, nos las arreglamos completamente con los medios estándar. Pero como el número de pruebas en uno de los productos llegó a 700 y la tarea general era crear informes de alta calidad para los clientes, comencé a mirar hacia Allure.
Sin embargo, este informe no era sobre Allure, sino también sobre él.
Artyom convenció al público de que escribir complementos para IntelliJ IDEA es una actividad simple y fascinante. ¿Por qué se requeriría esto? Para automatizar la modificación de código masivo. Por ejemplo, para traducir una gran cantidad de códigos fuente de JUnit4 a JUnit5. O del uso de Allure 1 a Allure 2. O para automatizar el etiquetado de pruebas con comunicación con el sistema de tictac.
Aquellos que trabajan con IDEA saben qué trucos puede hacer con el código (por ejemplo, traducir automáticamente el código usando for-loops en código usando Java Streams y viceversa, o traducir instantáneamente Java a Kotlin). Cuanto más interesante fue ver cómo se abre el velo del secreto sobre las transformaciones de código en IDEA, estamos invitados a participar en esto y crear nuestros propios complementos para nuestras necesidades únicas. La próxima vez, cuando necesite hacer algo con una base de código grande, recordaré este informe y veré cómo se puede automatizar usando un complemento genérico en IDEA.
Kirill Merkushev. Proyecto Java y Reactor: ¿qué pasa con las pruebas?

Me parece que este informe podría haber tenido lugar en las conferencias Joker o JPoint Java. Kirill habló sobre cómo usa el framework
projectreactor.io en una arquitectura de microservicio con un único registro de eventos (Kafka), un poco sobre la esencia de la codificación en "secuencias reactivas", incluyendo cómo las aplicaciones que usan este marco pueden ser depuradas y probadas.
La vida también está presionando a nuestro equipo para que use la arquitectura con un único registro de eventos, y también miramos a Kafka. Sin embargo, para el procesamiento de eventos de transmisión, estamos experimentando con la API de Kafka Streams (donde, me parece, más cosas como el procesamiento con estado se implementan de forma transparente para el desarrollador), y no Reactor. Sin embargo, como es siempre el caso con las nuevas tecnologías, el "rastrillo" y las "trampas" no se conocen de antemano. Por lo tanto, era importante escuchar la historia de un especialista que ya está trabajando con tecnología.
Leonid Rudenko. Gestión de un clúster selenoide con Terraform

Si el informe anterior recordaba una conferencia de JPoint, entonces sin duda se trata de
DevOops . Leonid habló sobre cómo usar las especificaciones de Terraform para generar y configurar un clúster selenoide. Sobre lo que era Selenoid en sí, hubo
un informe sobre el Heisenbug del año pasado: es un sistema distribuido rico que funciona como un servicio elástico y le permite ejecutar una gran cantidad de pruebas de selenio en varios navegadores. Al igual que cualquier sistema que requiera la implementación en varias máquinas, es difícil instalar manualmente Selenoid. Aquí, los sistemas modernos de configuración como código vienen al rescate.
Leonid hizo una descripción bastante detallada de las capacidades de Terraform, un sistema que probablemente no era familiar para la mayoría de la audiencia, pero que en realidad ya era conocido por la automatización DevOps (por ejemplo, en la conferencia Devoops-2018 hubo
un excelente informe de Anton Babenko sobre las mejores prácticas para crear y mantener código en Terraform). Además, se mostró cómo utilizar los scripts de Terraform para describir los parámetros de los contenedores acoplables con Selenoid para cada una de las máquinas del clúster y los parámetros de las propias máquinas virtuales del clúster.
Aunque el caso específico considerado por Leonid ciertamente puede facilitar la tarea de implementar Selenoid, no estoy de acuerdo con el orador en todo. Esencialmente, usa Terraform para dos tareas diferentes: crear recursos y configurarlos. Y esto lleva al hecho de que Leonid se ve obligado a ejecutar Terraform una vez para crear máquinas virtuales y una vez más para cada una de las máquinas virtuales para levantar contenedores acoplables en ellos. En mi opinión, Terraform, que resuelve bien el problema de crear recursos, no resuelve muy bien el problema de configuración. Sería posible evitar la multiplicación de proyectos de terraformación y su lanzamiento repetido utilizando sistemas de configuración especiales, por ejemplo, Ansible u otras soluciones.
Pero en general, como un "programa educativo" para probadores en el campo de Infraestructura como Código, este informe es muy útil.
Andrey Markelov. Pruebas de integración elegantes del zoológico de microservicios con TestContainers y JUnit 5 utilizando el ejemplo de la plataforma global de SMS

Y de nuevo sobre microservicios! Esta vez, la conversación fue sobre cómo ejecutar pruebas que requieren el lanzamiento y la interacción de varios servicios al mismo tiempo. JUnit5 con su
sistema de Extensión y el conocido (y excelente) marco TestContainers fueron propuestos como la base de la solución (ver, por ejemplo,
el informe del año pasado de Sergey Egorov ).
Si está escribiendo algo en Java y aún no sabe qué es TestContainers, le recomiendo que lo estudie con urgencia. TestContainers permite, utilizando la tecnología Docker, directamente en el código de prueba para recoger bases de datos reales y otros servicios, conectarlos a través de la red y, como resultado, realizar pruebas de integración en el entorno que se creó en el momento en que se lanzaron las pruebas y se destruyeron inmediatamente después. Al mismo tiempo, todo funciona directamente desde el código Java, se conecta como una dependencia de Maven y no requiere instalar nada más que Docker en la máquina del desarrollador / servidor CI. Hemos estado usando TestContainers por más de un año.
Andrey mostró un ejemplo bastante impresionante de cómo puede prescribir la configuración del entorno de prueba para pruebas de extremo a extremo utilizando Extensiones JUnit5, anotaciones personalizadas y TestContainers. Por ejemplo, escribir anotaciones sobre su prueba (código condicional)
@Billing @Messaging
podemos, relativamente hablando, escribir
@Test void systemIsDoingRightThings(BillingService b, MessagingService m) {...}
en los parámetros por los cuales se pasarán las interfaces Java a través de las cuales puede comunicarse con los servicios reales generados (desapercibidos por el desarrollador de la prueba) en contenedores.
Estos ejemplos se ven muy elegantes. Para mí, como usuario activo de TestContainers y JUnit 5, son comprensibles y relativamente fáciles de implementar.
Pero, en general, con este enfoque, la gran pregunta sigue sin resolverse, relacionada con el hecho de que la forma de configurar los sistemas de prueba y producción es fundamentalmente diferente.
La implementación de lanzamientos rápidos en producción sin temor a romper todo es posible solo si durante las pruebas de extremo a extremo no solo se probó todo el sistema, sino también la forma de configurarlo. Si ejecutamos repetidamente el script de implementación del sistema durante el proceso de desarrollo y prueba, no tendríamos dudas de que este script funcionaría incluso cuando se lanzara en producción. La función del código que configura el entorno de prueba en el ejemplo de Andrey se realiza mediante anotaciones. Pero en la producción, diseñamos el sistema usando un código completamente diferente: Ansible, Kubernetes, cualquier cosa, que no esté involucrado de ninguna manera con tales pruebas del sistema. Y esto limita estas pruebas, que no son completamente de extremo a extremo.
Andrey Glazkov. Sistemas de prueba con dependencias externas: problemas, soluciones, Mountebank

Para aquellos para quienes el tema de este informe es relevante, les recomiendo que también vean una
brillante presentación de Andrei Solntsev sobre un enfoque
basado en principios para probar sistemas que dependen de servicios externos. Solntsev habla de manera muy convincente sobre la necesidad de utilizar simulacros de sistemas externos para realizar pruebas exhaustivas. Y Andrei Glazkov en su informe describe uno de los sistemas para tal humectación: Mountebank, escrito en NodeJS.
Puede levantar Mountebank como servidor y "entrenar" las respuestas a las solicitudes a través de la red de una manera similar a la forma en que "entrenamos" las simulaciones de la interfaz al escribir pruebas unitarias. La única diferencia es que es un simulacro de un servicio de red. Un caso curioso de usar Mountebank es la capacidad de usarlo como proxy, enviando algunas solicitudes a un sistema externo real.
Cabe señalar aquí que recomendaría que los desarrolladores de Java (y Andrei estuvo de acuerdo en el área de discusión) también miren hacia la biblioteca WireMock, que se crea en Java y se puede ejecutar en modo incrustado, es decir, directamente desde las pruebas sin instalar ninguna Cualquiera de los servicios a la máquina del desarrollador o al servidor CI (aunque también puede funcionar como un servidor independiente). Al igual que Mountebank, WireMock admite el modo proxy. Tenemos una experiencia positiva con WireMock.
La ventaja de Mountebank, sin embargo, es el soporte de protocolos de nivel inferior (WireMock funciona solo para HTTP) y la capacidad de trabajar en un "zoológico" de diferentes tecnologías (existen bibliotecas para diferentes idiomas para Mountebank).
Kirill Tolkachev. Prueba y llanto con la prueba de arranque de primavera

Y de nuevo Java, microservicios y JUnit 5. Kirill es otro orador de las conferencias Joker y JPoint, conocido por la comunidad Java, que habló por primera vez en Heisenbug.
Este informe es una versión modificada del informe
Spring Test Curse del año pasado, con ejemplos modificados para JUnit5 y Spring Boot 2. Se examinan en profundidad varios problemas prácticos relacionados con la configuración de las pruebas Spring Boot en las pruebas de componentes / microservicios. Por ejemplo, me impresionó el ejemplo de usar el
@SpringBootConfiguration StopConfiguration vacío en el lugar correcto en el árbol de origen para detener el proceso de escaneo de la configuración, así como la posibilidad de usar
@MockBean y
@SpyBean lugar de
@SpyBean . Al igual que otros informes de Cyril y Evgeny Borisov, este es un material al que tiene sentido volver en el proceso de uso práctico del Spring Framework.
Andrey Karpov. ¿Qué pueden hacer los analizadores estáticos? ¿Qué no pueden hacer los programadores y probadores?

El análisis de código estático es algo bueno. Según los cánones de la entrega continua, debería ser la primera fase del proceso de entrega, filtrando el código con problemas que pueden detectarse al "leer" el código. El análisis estático es bueno porque es rápido (mucho más rápido que las pruebas) y barato (no requiere esfuerzos adicionales del equipo en forma de pruebas escritas: todos los cheques ya han sido escritos por los autores del analizador).
Andrey Karpov, uno de los fundadores del proyecto PVS-Studio (familiar para los lectores de Habr con su
blog ) elaboró un informe sobre ejemplos de qué errores en el análisis de código de productos conocidos se encontraron utilizando PVS-Studio. PVS Studio en sí es un producto políglota, es compatible con C, C ++, C # y, más recientemente, Java.
A pesar del hecho de que los ejemplos anteriores eran interesantes y la utilidad del análisis estático de ellos es obvio, en mi opinión, el informe de Andrey tenía fallas.
En primer lugar, el informe se basó únicamente en la consideración del producto PVS-Studio (para el cual, según el orador, "el precio promedio es de $ 10,000"). Pero valió la pena mencionar que, de hecho, en muchos idiomas hay muchos sistemas de análisis estático OpenSource desarrollados. Solo en Java: el Checkstyle y SpotBugs gratuitos (el sucesor del proyecto FindBugs congelado), así como el analizador IntelliJ IDEA, que se puede ejecutar por separado del IDE y recibir un informe, hicieron un progreso tremendo.
En segundo lugar, hablando de análisis estático, me parece que siempre vale la pena mencionar las limitaciones fundamentales de este método. No todos pasaron por la teoría de algoritmos en la universidad y están familiarizados con el "problema de cierre", por ejemplo.
Y finalmente, los problemas de introducir el análisis estático en la base de código existente no se plantearon en absoluto, lo que todavía impide que muchos usen analizadores regularmente en proyectos. Por ejemplo, ejecutamos el analizador en un gran proyecto heredado y encontramos 100,500 videos. No hay tiempo ni esfuerzo para solucionarlos en el acto, y cambiar masivamente algo en el código es un riesgo. ¿Qué hacer con esto, cómo hacer que el análisis estático funcione como una puerta de calidad? Este problema se discutió en el área de discusión con Andrei, pero este problema no se consideró en el informe mismo.
En general, le deseo mucho éxito a Andrey y su equipo. Su producto es interesante y la idea de ocupar su nicho en esta área es muy audaz.
***
Quizás no voy a decir nada sobre las notas finales del primer y segundo día: ambos fueron programas de copyright que solo debes ver. Hablar de ellos es como volver a contar en palabras, por ejemplo, una actuación de una banda de rock.
En mi informe de hace un
año, ya intenté transmitir la atmósfera general de la conferencia y hablé sobre lo que está sucediendo en las áreas de discusión, en el almuerzo y en la fiesta, por lo que no me repetiré.
En conclusión, me gustaría agradecer a los organizadores por otra conferencia bellamente organizada. Según tengo entendido, el interés en la conferencia superó ligeramente las expectativas, hubo algunas reservas excesivas y ni siquiera todos tenían suficientes recuerdos. Pero seguro, todos tenían cosas más importantes: informes interesantes, espacio de discusión, comida y bebidas. ¡Espero nuevas reuniones!