
En la continuación de nuestros artículos prácticos sobre cómo facilitar la vida en el trabajo diario con Kubernetes, hablamos de dos historias del mundo de la operación: la asignación de nodos individuales para tareas específicas y la configuración de php-fpm (u otro servidor de aplicaciones) para cargas pesadas. Como antes, las soluciones descritas aquí no pretenden ser ideales, pero se ofrecen como un punto de partida para sus casos específicos y una base para la reflexión. ¡Preguntas y mejoras en los comentarios son bienvenidas!
1. La asignación de nodos individuales para tareas específicas
Estamos creando un clúster de Kubernetes en servidores virtuales, nubes o servidores básicos. Si instala todo el software del sistema y las aplicaciones cliente en los mismos nodos, es probable que tenga problemas:
- la aplicación cliente de repente comenzará a "filtrarse" de la memoria, aunque sus límites son muy altos;
- las solicitudes complejas de una sola vez a loghouse, Prometheus o Ingress * conducen a OOM, como resultado la aplicación del cliente sufre;
- una pérdida de memoria debido a un error en el software del sistema mata la aplicación del cliente, aunque los componentes pueden no estar conectados lógicamente entre sí.
* Entre otras cosas, era relevante para las versiones anteriores de Ingress, cuando debido a la gran cantidad de conexiones websocket y las constantes recargas de nginx, aparecían "procesos nginx bloqueados", que ascendían a miles y consumían una gran cantidad de recursos.El caso real es con la instalación de Prometheus con una gran cantidad de métricas, en las que al visualizar el panel "pesado", donde se presentan una gran cantidad de contenedores de aplicaciones, de cada uno de los cuales se dibujan gráficos, el consumo de memoria creció rápidamente a ~ 15 GB. Como resultado, el asesino OOM podría "entrar" en el sistema host y comenzar a matar otros servicios, lo que a su vez condujo a un "comportamiento incomprensible de las aplicaciones en el clúster". Y debido a la alta carga de CPU en la aplicación cliente, es fácil obtener un tiempo de procesamiento de consultas Ingress inestable ...
La solución se aplicó rápidamente: era necesario asignar máquinas individuales para diferentes tareas. Hemos identificado 3 tipos principales de grupos de tareas:
- Frentes , donde colocamos solo Ingresss, para asegurarnos de que ningún otro servicio pueda afectar el tiempo de procesamiento de las solicitudes;
- Los nodos del sistema en los que implementamos VPN , loghouse , Prometheus , Dashboard, CoreDNS, etc.
- Nodos para aplicaciones , de hecho, donde se implementan las aplicaciones cliente. También se pueden asignar a entornos o funcionalidades: dev, prod, perf, ...
Solución
¿Cómo implementamos esto? Muy simple: dos mecanismos nativos de Kubernetes. El primero es
nodeSelector para seleccionar el nodo deseado donde debe ir la aplicación, que se basa en las etiquetas
instaladas en cada nodo.
Digamos que tenemos un nodo
kube-system-1 . Le agregamos una etiqueta adicional:
$ kubectl label node kube-system-1 node-role/monitoring=
... y en
Deployment , que debe implementarse en este nodo, escribimos:
nodeSelector: node-role/monitoring: ""
El segundo mecanismo son las
contaminaciones y las tolerancias . Con su ayuda, indicamos explícitamente que en estas máquinas solo se pueden lanzar contenedores que tengan tolerancia a esta contaminación.
Por ejemplo, hay una máquina
kube-frontend-1 en la que solo lanzaremos Ingress. Agregue contaminación a este nodo:
$ kubectl taint node kube-frontend-1 node-role/frontend="":NoExecute
... y en
Deployment creamos tolerancia:
tolerations: - effect: NoExecute key: node-role/frontend
En el caso de kops, se pueden crear grupos de instancias individuales para las mismas necesidades:
$ kops create ig --name cluster_name IG_NAME
... y obtienes algo como esta configuración de grupo de instancias en kops:
apiVersion: kops/v1alpha2 kind: InstanceGroup metadata: creationTimestamp: 2017-12-07T09:24:49Z labels: dedicated: monitoring kops.k8s.io/cluster: k-dev.k8s name: monitoring spec: image: kope.io/k8s-1.8-debian-jessie-amd64-hvm-ebs-2018-01-14 machineType: m4.4xlarge maxSize: 2 minSize: 2 nodeLabels: dedicated: monitoring role: Node subnets: - eu-central-1c taints: - dedicated=monitoring:NoSchedule
Por lo tanto, los nodos de este grupo de instancias agregarán automáticamente una etiqueta y una mancha adicionales.
2. Configuración de php-fpm para cargas pesadas
Existe una amplia variedad de servidores que se utilizan para ejecutar aplicaciones web: php-fpm, gunicorn y similares. Su uso en Kubernetes significa que hay varias cosas en las que siempre debe pensar:
- Es necesario comprender aproximadamente cuántos trabajadores estamos dispuestos a asignar en php-fpm en cada contenedor. Por ejemplo, podemos asignar 10 trabajadores para procesar solicitudes entrantes, asignar menos recursos para pod y escalar usando el número de pods; esta es una buena práctica. Otro ejemplo es asignar 500 trabajadores para cada grupo y tener 2-3 grupos en producción ... pero esta es una muy mala idea.
- Se requieren pruebas de vida / preparación para verificar el funcionamiento correcto de cada pod y en caso de que el pod se atasque debido a problemas de red o debido al acceso a la base de datos (puede haber alguna de sus opciones y razones) En tales situaciones, debe recrear el pod problemático.
- Es importante registrar explícitamente la solicitud y limitar los recursos para cada contenedor para que la aplicación no "fluya" y no comience a dañar todos los servicios en este servidor.
Soluciones
Desafortunadamente,
no hay una bala de plata que lo ayude a comprender de inmediato cuántos recursos (CPU, RAM) puede necesitar una aplicación. Una opción posible es observar el consumo de recursos y cada vez seleccionar los valores óptimos. Para evitar el OOM kill'ov injustificado y la aceleración de la CPU, que afectan en gran medida el servicio, puede ofrecer:
- agregue las pruebas correctas de vida / preparación para que podamos decir con certeza que este contenedor funciona correctamente. Lo más probable es que sea una página de servicio que verifique la disponibilidad de todos los elementos de infraestructura (necesarios para que la aplicación funcione en el pod) y devuelva un código de respuesta 200 OK;
- seleccione correctamente el número de trabajadores que procesarán las solicitudes y distribúyalos correctamente.
Por ejemplo, tenemos 10 pods que constan de dos contenedores: nginx (para enviar estadísticas y solicitudes de proxy al backend) y php-fpm (en realidad, el backend, que procesa páginas dinámicas). El grupo Php-fpm está configurado para un número estático de trabajadores (10). Por lo tanto, en una unidad de tiempo, podemos procesar 100 solicitudes activas para backends. Deje que PHP procese cada solicitud en 1 segundo.
¿Qué sucede si llega 1 solicitud más en un pod específico, en el cual 10 solicitudes se están procesando activamente ahora? PHP no podrá procesarlo e Ingress lo enviará para reintentar al siguiente pod si se trata de una solicitud GET. Si hubo una solicitud POST, devolverá un error.
Y si tenemos en cuenta que durante el procesamiento de las 10 solicitudes, recibiremos un cheque de kubelet (sonda de vida), terminará con un error y Kubernetes comenzará a pensar que algo está mal con este contenedor y lo matará. En este caso, todas las solicitudes que se procesaron en este momento terminarán con un error (!) Y en el momento del reinicio del contenedor se perderá el equilibrio, lo que implicará un aumento en las solicitudes de todos los demás backends.
Claramente
Supongamos que tenemos 2 pods, cada uno con 10 trabajadores php-fpm configurados. Aquí hay un gráfico que muestra información durante el "tiempo de inactividad", es decir cuando el único que solicita php-fpm es exportador php-fpm (tenemos un trabajador activo cada uno):
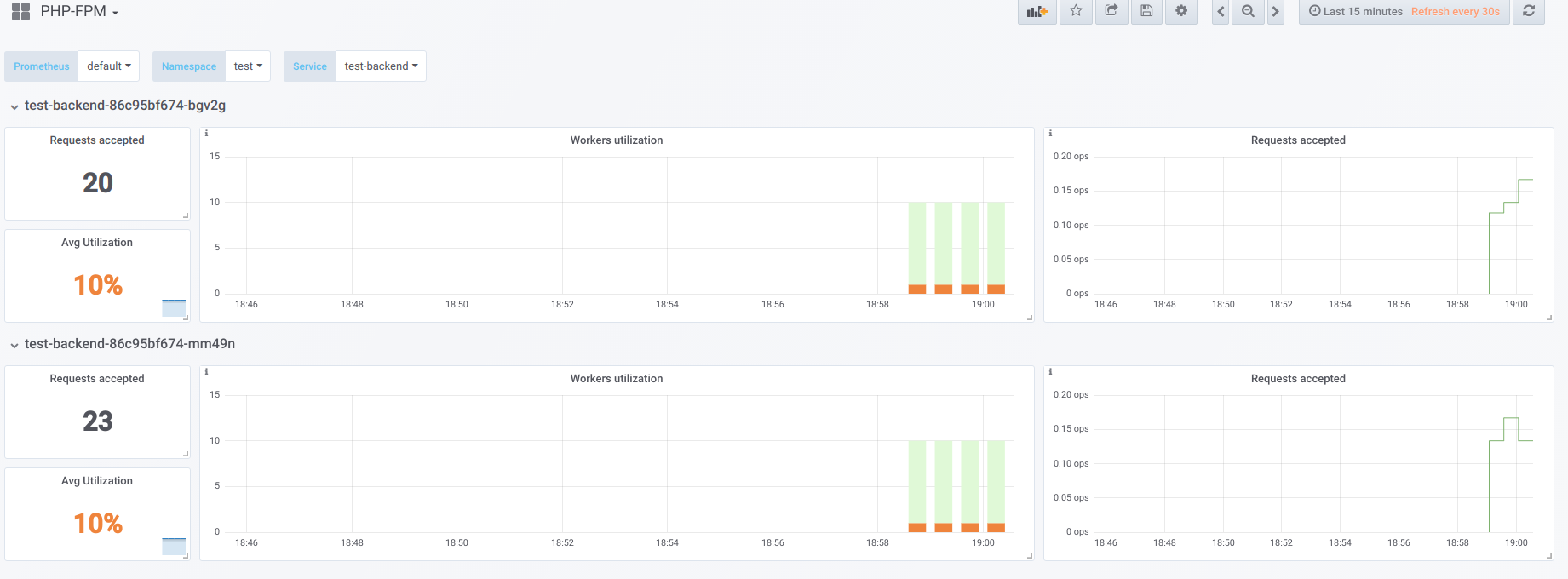
Ahora comience el arranque con concurrencia 19:
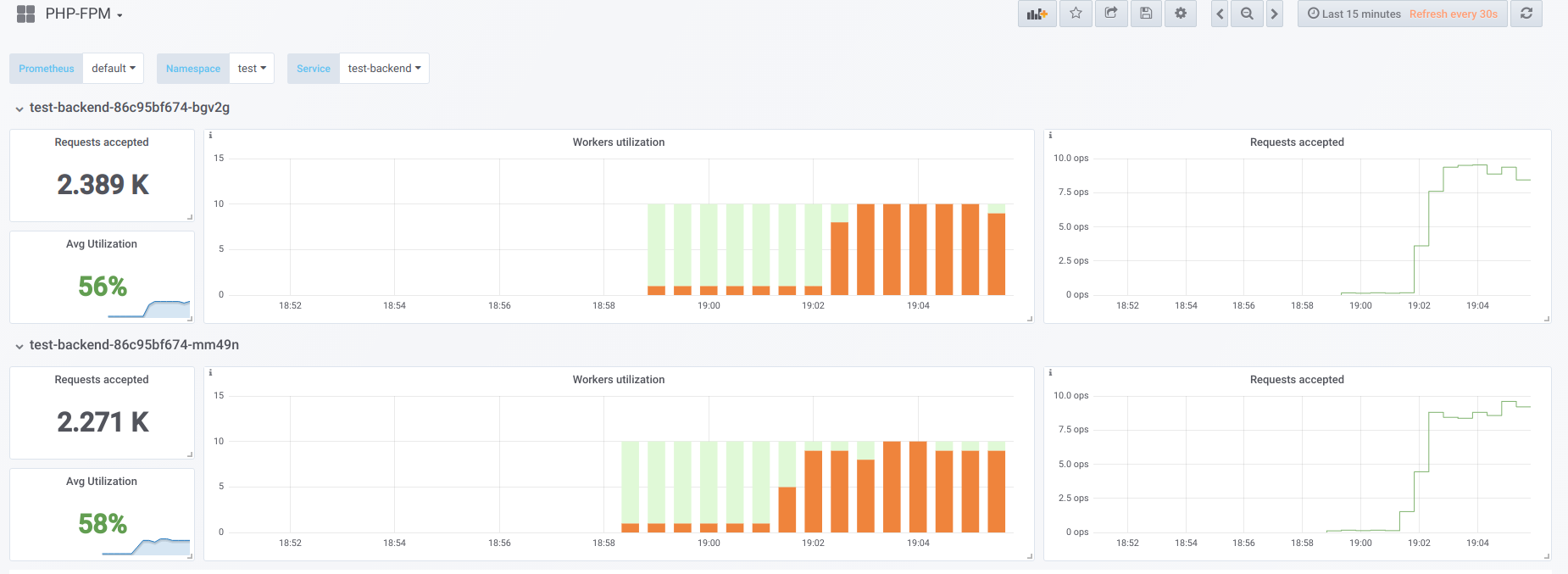
Ahora tratemos de hacer que la concurrencia sea más alta de lo que podemos manejar (20) ... digamos 23. Entonces todos los trabajadores de php-fpm están ocupados procesando solicitudes de clientes:

Los Vorkers ya no son suficientes para procesar una muestra de vida, por lo que vemos esta imagen en el panel de Kubernetes (o en el
describe pod ):

Ahora, cuando uno de los pods se reinicia, se
produce un
efecto de avalancha : las solicitudes comienzan a caer en el segundo pod, que tampoco puede procesarlas, por lo que recibimos una gran cantidad de errores de los clientes. Una vez que los grupos de todos los contenedores están llenos, aumentar el servicio es problemático; esto solo es posible mediante un fuerte aumento en el número de unidades o trabajadores.
Primera opción
En un contenedor con PHP, puede configurar 2 grupos de fpm: uno para procesar las solicitudes de los clientes y el otro para verificar la "capacidad de supervivencia" del contenedor. Luego, en el contenedor nginx, deberá hacer una configuración similar:
upstream backend { server 127.0.0.1:9000 max_fails=0; } upstream backend-status { server 127.0.0.1:9001 max_fails=0; }
Todo lo que queda es enviar la muestra de vida para su procesamiento en sentido ascendente llamado
backend-status .
Ahora que la sonda de vida se procesa por separado, todavía se producirán errores en algunos clientes, pero al menos no hay problemas asociados con el reinicio del pod y la desconexión del resto de los clientes. Por lo tanto, reduciremos en gran medida el número de errores, incluso si nuestros backends no pueden hacer frente a la carga actual.
Esta opción es ciertamente mejor que nada, pero también es mala porque algo le puede pasar al grupo principal, que no aprenderemos sobre el uso de la prueba de vida.
Segunda opción
También puede usar el módulo nginx no muy popular llamado
nginx-limit-upstream . Luego, en PHP especificaremos 11 trabajadores, y en el contenedor con nginx haremos una configuración similar:
limit_upstream_zone limit 32m; upstream backend { server 127.0.0.1:9000 max_fails=0; limit_upstream_conn limit=10 zone=limit backlog=10 timeout=5s; } upstream backend-status { server 127.0.0.1:9000 max_fails=0; }
En el nivel frontend, nginx limitará el número de solicitudes que se enviarán al backend (10). Un punto interesante es que se crea un retraso especial: si la undécima solicitud de nginx proviene del cliente y nginx ve que el grupo php-fpm está ocupado, entonces esta solicitud se coloca en el retraso durante 5 segundos. Si, durante este tiempo, php-fpm no se ha liberado, entonces solo Ingress entrará en acción, lo que reintentará la solicitud a otro pod. Esto suaviza la imagen, ya que siempre tendremos 1 trabajador PHP gratuito para procesar una muestra de vida, podemos evitar el efecto de avalancha.
Otros pensamientos
Para opciones más versátiles y hermosas para resolver este problema, vale la pena mirar en la dirección de
Envoy y sus análogos.
En general, para que Prometheus tenga un empleo claro de trabajadores, lo que a su vez lo ayudará a encontrar rápidamente el problema (y notificarlo), recomiendo encarecidamente que los
exportadores listos para convertir los datos del software al formato de Prometheus.
PS
Otros del ciclo de consejos y trucos de K8s:
Lea también en nuestro blog: