
Todos los días, un millón y medio de personas buscan en Ozon una variedad de productos, y para cada uno de ellos el servicio debe seleccionar productos similares (si la aspiradora aún necesita uno más potente) o relacionados (si se necesitan baterías para el dinosaurio que canta). Cuando hay demasiados tipos de productos, el modelo Word2Vec ayuda a resolver el problema. Entendemos cómo funciona y cómo crear representaciones vectoriales para objetos arbitrarios.
Motivación
Para construir y entrenar el modelo, utilizamos la técnica de incrustación, estándar para el aprendizaje automático, cuando cada objeto se convierte en un vector de longitud fija y los vectores cercanos corresponden a objetos cercanos. Casi todos los modelos conocidos requieren que los datos de entrada sean de una longitud fija, y un conjunto de vectores es una manera fácil de llevarlos a esta forma.
Uno de los primeros métodos de incrustación es word2vec. Adaptamos este método para nuestra tarea, usamos productos como palabras y sesiones de usuario como oraciones. Si todo está claro para usted, no dude en revisar los resultados.
A continuación hablaré sobre la arquitectura del modelo y cómo funciona. Dado que estamos tratando con bienes, necesitamos aprender a construir descripciones de ellos que, por un lado, contengan suficiente información y, por otro, sean entendibles para el algoritmo de aprendizaje automático.
En el sitio web, cada producto tiene una tarjeta. Consiste en un título, descripción de texto, especificaciones y fotografías. También a nuestra disposición hay datos sobre la interacción de los usuarios con el producto: las vistas, las adiciones a la cesta o los favoritos se almacenan en los registros.
Hay dos formas fundamentalmente diferentes de construir una descripción vectorial de un producto:
- usar contenido - redes neuronales convolucionales para extraer características de fotos, redes recurrentes o una bolsa de palabras para analizar una descripción de texto;
- uso de datos sobre las interacciones del usuario con el producto: qué productos y con qué frecuencia se ven / agregan a la cesta junto con los datos.
Nos centraremos en el segundo método.
Datos para el modelo Prod2Vec
Primero, descubramos qué datos usamos. Tenemos a nuestra disposición todos los clics de los usuarios en el sitio, se pueden dividir en sesiones de usuario: secuencias de clics con intervalos de no más de 30 minutos entre clics adyacentes. Para entrenar el modelo, utilizamos datos de aproximadamente 100 millones de sesiones de usuarios, en cada una de las cuales solo estamos interesados en ver y agregar productos a la cesta.
Un ejemplo de una sesión de usuario real:

Cada producto en la sesión corresponde a su contexto: todos los productos que el usuario agregó a la cesta en esta sesión, así como los productos que se ven con esto. El modelo prod2vec se basa en la suposición de que productos similares suelen tener contextos similares.
Por ejemplo:

Por lo tanto, si la suposición es cierta, entonces, por ejemplo, los casos para el mismo modelo de teléfono tendrán contextos similares (el mismo teléfono). Probamos esta hipótesis construyendo vectores de productos.
Modelo Prod2Vec
Cuando presentamos los conceptos de un producto y su contexto, describimos el modelo en sí. Esta es una red neuronal con dos capas completamente conectadas. El número de entradas de la primera capa es igual al número de productos para los que queremos construir vectores. Cada producto en la entrada estará codificado por un vector de ceros con una sola unidad: el lugar de este producto en el diccionario.
El número de neuronas en la salida de la primera capa es igual a la dimensión de los vectores que queremos obtener, por ejemplo 64. En la salida de la última capa, nuevamente, hay una cantidad de neuronas igual al número de bienes.

Entrenaremos el modelo para predecir el contexto, conociendo el producto. Esta arquitectura se llama Skip-gram (su alternativa es CBOW, donde predecimos el producto de acuerdo con su contexto). Durante el entrenamiento, los bienes se entregan a la entrada, se espera que los bienes salgan de su contexto (un vector de ceros con una unidad en el lugar correspondiente).
En esencia, esta es una clasificación multiclase, y la pérdida de entropía cruzada puede usarse para entrenar el modelo. Para un par de palabras del contexto, se escribe de la siguiente manera:
donde - predicción de red para el producto desde el contexto, - el número total de bienes - predicción de red para producto .
Después de entrenar el modelo, podemos descartar la segunda capa; no será necesario para obtener vectores. La matriz de pesos de la primera capa (tamaño del número de bienes x 64) es un diccionario de vectores de bienes. Cada producto corresponde a una fila de una matriz de longitud 64; este es el vector correspondiente al producto, que puede usarse en otros algoritmos.
Pero este procedimiento no funciona para una gran cantidad de productos. Y los tenemos, recordemos, un millón y medio.
Por qué Prod2Vec no funciona
- La función de pérdida contiene muchas operaciones para tomar el exponente: es computacionalmente larga e inestable.
- Como resultado, se consideran gradientes para todos los pesos de red, y puede haber decenas de millones.
Para resolver estos problemas, el método de muestreo negativo es adecuado, mediante el cual enseñamos a la red no solo a predecir el contexto del producto, sino también a no predecir los productos que no están exactamente en el contexto. Para hacer esto, necesitamos generar ejemplos negativos: para cada producto, seleccione aquellos que no necesitan predecirse. Y aquí la disponibilidad de una gran cantidad de productos nos ayuda. Al elegir un par aleatorio para un producto, tenemos una probabilidad muy pequeña de que resulte ser un producto del contexto.
Como resultado, para cada producto en el contexto, generamos aleatoriamente 5-10 productos que no están incluidos en el contexto. Además, los productos no se muestrean mediante una distribución uniforme, sino en proporción a la frecuencia de su aparición.
La función de pérdida ahora es similar a la utilizada en la clasificación binaria. Para un par de palabras, desde el contexto, se ve así:
En estas notación denota una columna de la matriz de peso de la segunda capa correspondiente al producto del contexto, - lo mismo para un producto seleccionado al azar, - la fila de la matriz de peso de la primera capa correspondiente al producto principal (este es exactamente el vector que estamos construyendo para él). Función .
La diferencia con la versión anterior es que no necesitamos actualizar todos los pesos de red en cada iteración, solo necesitamos actualizar aquellos que corresponden a un pequeño número de productos (el primer producto es aquel para el que predecimos, el resto es un producto de su contexto o seleccionado al azar ) Al mismo tiempo, eliminamos una gran cantidad de capturas exponenciales en cada iteración.
Otra técnica, que a su vez mejora la calidad del modelo resultante, es el submuestreo. En este caso, tomamos intencionalmente productos que se encuentran con menos frecuencia para capacitación a fin de obtener el mejor resultado para productos raros.
Resultados
Productos relacionados
Entonces, aprendimos cómo obtener vectores para bienes, ahora necesitamos verificar la adecuación y aplicabilidad de nuestro modelo.
La siguiente imagen muestra el producto y sus vecinos más cercanos en la medida de proximidad del coseno.
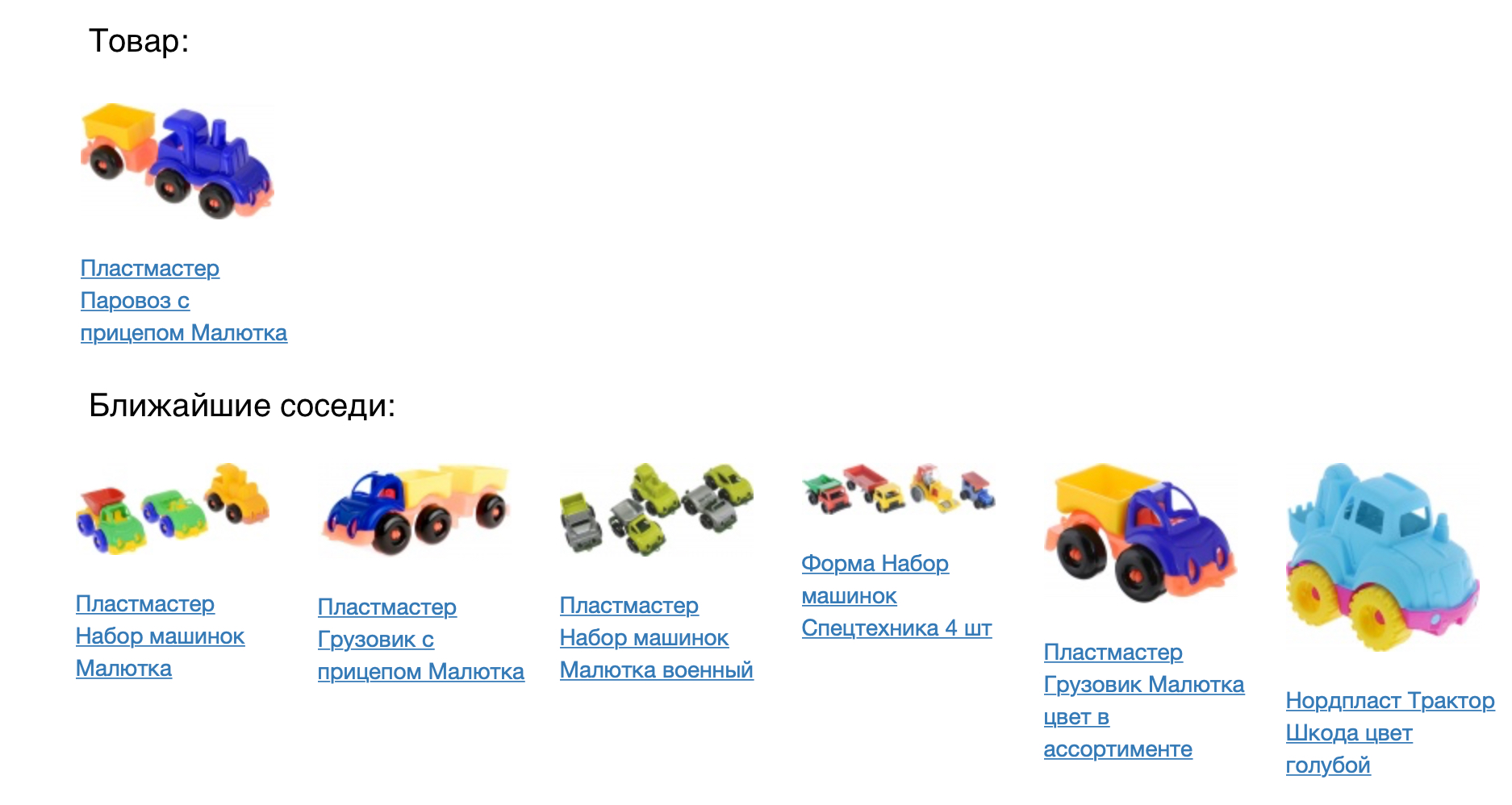
El resultado se ve bien, pero debe verificar numéricamente cuán bueno es nuestro modelo. Para hacer esto, lo aplicamos a la tarea de recomendaciones de productos. Para cada producto, recomendamos venir en un espacio vectorial construido. Comparamos el modelo prod2vec con uno mucho más simple, basado en estadísticas de vistas conjuntas y agregando artículos a la cesta. Para cada producto en la sesión, se tomó una lista de 7 recomendaciones. La combinación de todos los productos recomendados en la sesión se comparó con lo que una persona realmente agregó a la canasta. Usando prod2vec, en más del 40% de las sesiones recomendamos al menos un producto, que luego se agregó a la cesta. A modo de comparación, un algoritmo más simple muestra una calidad del 34%.
La descripción del vector resultante nos permite no solo buscar los más cercanos (lo que se puede hacer con un modelo más simple, aunque con peor calidad). Podemos considerar qué efectos secundarios interesantes se pueden mostrar utilizando nuestro modelo.
Aritmética vectorial
Para ilustrar que los vectores tienen el significado real de los bienes, podemos intentar usar aritmética vectorial para ellos. Como en el ejemplo del libro de texto en word2vec (rey - hombre + mujer = reina), por ejemplo, podemos preguntarnos qué producto está aproximadamente a la misma distancia de la impresora que la bolsa de polvo de la aspiradora. El sentido común dicta que debe ser algún tipo de consumible, es decir, un cartucho. Nuestro modelo puede atrapar tales patrones:

Visualización del espacio del producto.
Para comprender mejor los resultados, podemos visualizar el espacio vectorial de los bienes en el plano, reduciendo la dimensión a dos (en este ejemplo, utilizamos t-SNE).

Se ve claramente que los productos relacionados forman grupos. Por ejemplo, los grupos con textiles para el dormitorio, ropa masculina y femenina, zapatos son claramente visibles. Una vez más, observamos que este modelo se construye solo sobre la base del historial de interacciones del usuario con los productos; no utilizamos la similitud de las imágenes o las descripciones de texto al entrenar.
A partir de la ilustración del espacio, también puede ver cómo, utilizando el modelo, puede seleccionar accesorios para productos. Para hacer esto, debe tomar artículos del grupo más cercano, por ejemplo, recomendar artículos deportivos para camisetas y gorras para suéteres calientes.
Planes
Ahora estamos presentando el modelo prod2vec en producción para calcular las recomendaciones de productos. Además, los vectores obtenidos se pueden usar como características para otros algoritmos de aprendizaje automático en los que nuestro equipo está involucrado (predicción de la demanda de bienes, clasificación en búsquedas y catálogos, recomendaciones personales).
En el futuro, planeamos implementar las incorporaciones recibidas en el sitio en tiempo real. Para todos los productos vistos, los siguientes estarán en la sesión, que se reflejará instantáneamente en la entrega personalizada. También planeamos integrar el análisis de imagen y el análisis de similitud de acuerdo con la descripción del vector en nuestro modelo, lo que mejorará en gran medida la calidad de los vectores resultantes.
Si sabe la mejor manera de hacer esto (o rehacer), venga a visitarnos (e incluso trabaje mejor).
Referencias
- Mikolov, Tomas y col. "Representaciones distribuidas de palabras y frases y su composición". Avances en sistemas de procesamiento de información neuronal. 2013
- Grbovic, Mihajlo y col. "Comercio electrónico en su bandeja de entrada: recomendaciones de productos a escala". Actas de la 21ª Conferencia Internacional ACM SIGKDD sobre Descubrimiento de Conocimiento y Minería de Datos. ACM, 2015.
- Grbovic, Mihajlo y Haibin Cheng. "Personalización en tiempo real usando incrustaciones para el ranking de búsqueda en Airbnb". Actas de la 24ª Conferencia Internacional ACM SIGKDD sobre Descubrimiento de Conocimiento y Minería de Datos. ACM, 2018.