En Rostelecom, utilizamos Hadoop para almacenar y procesar datos descargados de múltiples fuentes utilizando aplicaciones java. Ahora pasamos a una nueva versión de hadoop con autenticación Kerberos. Al mudarme, encontré varios problemas, incluido el uso de la API de YARN. El trabajo de Hadoop con la autenticación Kerberos merece un artículo separado, pero en este artículo hablaremos sobre la depuración de Hadoop MapReduce.

Al ejecutar tareas en el clúster, iniciar el depurador se complica por el hecho de que no sabemos qué nodo procesará esta o aquella parte de los datos de entrada, y no podemos configurar nuestro depurador por adelantado.
Puede usar el sistema
System.out.println("message") . Pero, ¿cómo analizar la salida de
System.out.println("message") disperso en estos nodos?
Podemos enviar mensajes a la secuencia de error estándar. Todo lo escrito en stdout o stderr,
enviado al archivo de registro apropiado, que se puede encontrar en la página web de información extendida de la tarea o en los archivos de registro.
También podemos incluir herramientas de depuración en nuestro código, actualizar mensajes de estado de tareas y usar contadores personalizados para ayudarnos a comprender la magnitud del desastre.
La aplicación Hadoop MapReduce se puede depurar en los tres modos en los que Hadoop puede funcionar:
- independiente
- modo pseudodistribuido
- totalmente distribuido
Con más detalle nos centraremos en los dos primeros.
Modo seudodistribuido
El modo pseudodistribuido se utiliza para simular un clúster real. Y se puede usar para realizar pruebas en un entorno lo más productivo posible. ¡En este modo, todos los demonios de Hadoop funcionarán en un nodo!
Si tiene un servidor de desarrollo u otro entorno limitado (por ejemplo, una máquina virtual con un entorno de desarrollo personalizado, como Hortonworks Sanbox con HDP), puede depurar el programa de control utilizando herramientas de depuración remota.
Para comenzar a depurar, debe establecer el valor de la variable de entorno:
YARN_OPTS . El siguiente es un ejemplo. Para mayor comodidad, puede crear el archivo startWordCount.sh y agregarle los parámetros necesarios para iniciar la aplicación.
Ahora, ejecutando el script
`./startWordCount.sh` , veremos un mensaje
Listening for transport dt_socket at address: 6000
Queda por configurar el IDE para la depuración remota. Estoy usando intellij IDEA. Vaya al menú Ejecutar -> Editar configuraciones ... Agregue una nueva configuración
Remote .
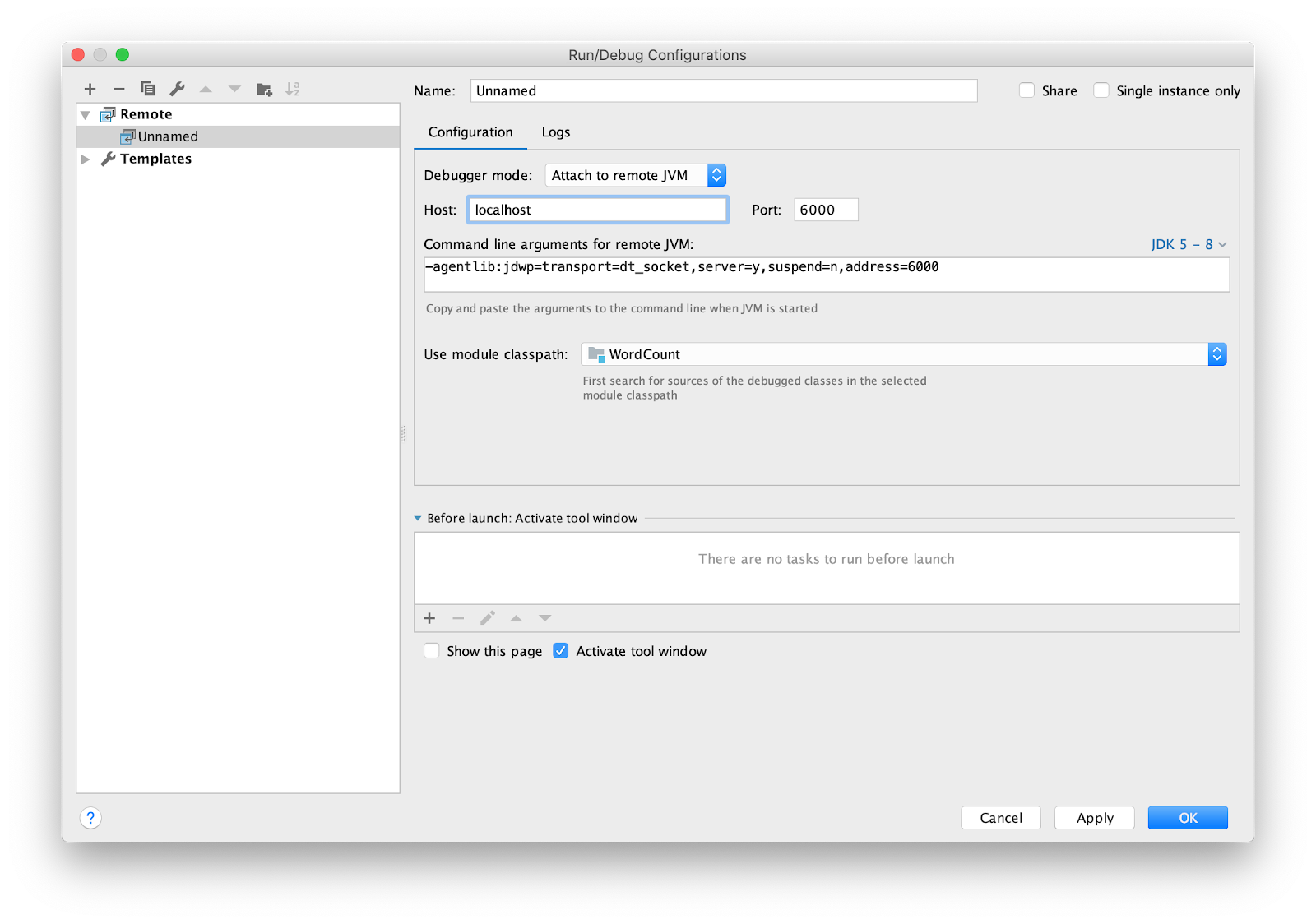
Establezca el punto de interrupción en principal y ejecute.
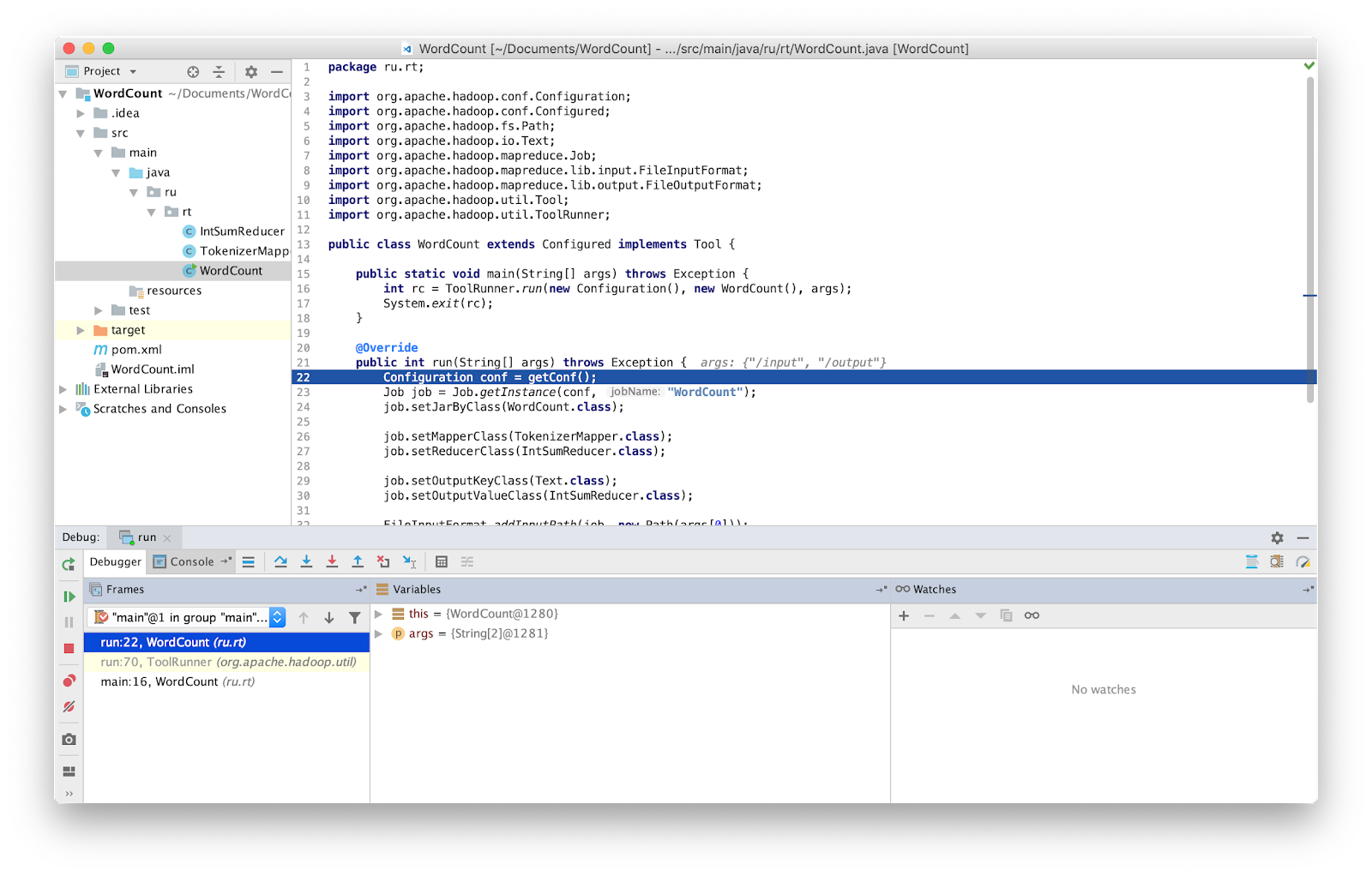
Eso es todo, ahora podemos depurar el programa como de costumbre.
ATENCION Debe asegurarse de estar trabajando con la última versión del código fuente. De lo contrario, puede tener diferencias en las líneas donde se detiene el depurador.
En versiones anteriores de Hadoop, se proporcionaba una clase especial que le permitía reiniciar una tarea fallida: aislamientoRunner. Los datos que causaron la falla se guardaron en el disco en la dirección especificada en la variable de entorno Hadoop mapred.local.dir. Desafortunadamente, en versiones recientes de Hadoop, esta clase ya no se proporciona.
Independiente (inicio local)
Independiente es el modo estándar en el que trabaja Hadoop. Es adecuado para la depuración donde no se usa HDFS. Con dicha depuración, puede usar entradas y salidas a través del sistema de archivos local. El modo independiente suele ser el modo más rápido de Hadoop, ya que utiliza el sistema de archivos local para todos los datos de entrada y salida.
Como se mencionó anteriormente, puede inyectar herramientas de depuración en su código, como contadores. Los contadores están definidos por la
enumeración de Java. El nombre de enumeración define el nombre del grupo, y los campos de enumeración determinan los nombres de los contadores. Un contador puede ser útil para evaluar un problema,
y se puede usar como una adición a la salida de depuración.
Declaración y uso del contador:
package ru.rt.example; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; public class Map extends Mapper<LongWritable, Text, Text, IntWritable> { private Text word = new Text(); enum Word { TOTAL_WORD_COUNT, } @Override public void map(LongWritable key, Text value, Context context) { String[] stringArr = value.toString().split("\\s+"); for (String str : stringArr) { word.set(str); context.getCounter(Word.TOTAL_WORD_COUNT).increment(1); } } } }
Para incrementar el contador, use el método
increment(1) .
... context.getCounter(Word.TOTAL_WORD_COUNT).increment(1); ...
Después de que MapReduce se complete con éxito, la tarea muestra los contadores al final.
Shuffle Errors BAD_ID=0 CONNECTION=0 IO_ERROR=0 WRONG_LENGTH=0 WRONG_MAP=0 WRONG_REDUCE=0 ru.rt.example.Map$Word TOTAL_WORD_COUNT=655
Los datos erróneos pueden enviarse a stderr o stdout, o escribir la salida a hdfs utilizando la clase
MultipleOutputs para su posterior análisis. Los datos recibidos pueden transmitirse a la entrada de la aplicación en modo independiente o al escribir pruebas unitarias.
Hadoop tiene la biblioteca MRUnit, que se usa junto con marcos de prueba (por ejemplo, JUnit). Al escribir pruebas unitarias, verificamos que la función produce el resultado esperado en la salida. Usamos la clase MapDriver del paquete MRUnit, en cuyas propiedades configuramos la clase probada. Para hacer esto, use el método
withMapper() , los valores de entrada
withInputValue() y el resultado esperado
withOutput() o
withMultiOutput() si se usan múltiples salidas.
Aquí está nuestra prueba.
package ru.rt.example; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mrunit.mapreduce.MapDriver; import org.apache.hadoop.mrunit.types.Pair; import org.junit.Before; import org.junit.Test; import java.io.IOException; public class TestWordCount { private MapDriver<Object, Text, Text, IntWritable> mapDriver; @Before public void setUp() { Map mapper = new Map(); mapDriver.setMapper(mapper) } @Test public void mapperTest() throws IOException { mapDriver.withInput(new LongWritable(0), new Text("msg1")); mapDriver.withOutput(new Pair<Text, IntWritable>(new Text("msg1"), new IntWritable(1))); mapDriver.runTest(); } }
Modo completamente distribuido
Como su nombre indica, este es un modo en el que se usa todo el poder de Hadoop. El programa lanzado MapReduce puede ejecutarse en 1000 servidores. Siempre es difícil depurar el programa MapReduce, ya que tiene Mappers ejecutándose en diferentes máquinas con diferentes datos de entrada.
Conclusión
Al final resultó que, probar MapReduce no es tan fácil como parece a primera vista.
Para ahorrar tiempo buscando errores en MapReduce, utilicé todos los métodos enumerados anteriormente y aconsejo a todos que también los apliquen. Esto es especialmente útil en el caso de grandes instalaciones, como las que funcionan en Rostelecom.