Si está creciendo grandes bases de datos y de repente se encuentra con un techo de rendimiento, es hora de expandirse. Con la extensión de escala horizontal está claro: agrega servidores y no conoce el dolor. Con la ampliación, no es tan divertido. De acuerdo con la arquitectura estándar sin cola, tomamos dos procesadores, luego les agregamos dos más ... así llegamos a ocho y eso es todo. Intel ya no lo previó; ahorre en un nuevo servidor.

Pero hay una alternativa: la arquitectura pegada. En él, las unidades informáticas de doble procesador están interconectadas a través de controladores de nodo. Con su ayuda, el umbral superior por servidor aumenta a 16 o más procesadores. En esta publicación, hablaremos más sobre la arquitectura pegada en general y cómo se implementa en nuestros servidores.
Antes de pasar a la arquitectura pegada, en aras de la honestidad, nos detenemos en los pros y los contras de sin pegamento.
Las soluciones hechas de acuerdo con la arquitectura sin cola son típicas. Los procesadores se comunican entre sí sin un dispositivo adicional, sino a través del bus estándar QPI \ UPI. El resultado es un poco más barato que con pegado. Pero cada ocho procesadores tienen que gastar mucho dinero para instalar un nuevo servidor.
 Arquitectura típica sin cola
Arquitectura típica sin colaY con la arquitectura pegada, como ya hemos dicho, el techo aumenta a 16 o más procesadores por servidor.
Cómo funciona la arquitectura pegada Bull BCS2
Las ventajas de la arquitectura Bull BCS2 son proporcionadas por dos componentes: el controlador de nodo eXternal resistente y el almacenamiento en caché del procesador. Se admiten equipos compatibles con los procesadores Intel Xeon E7-4800 / 8800 v4 series.
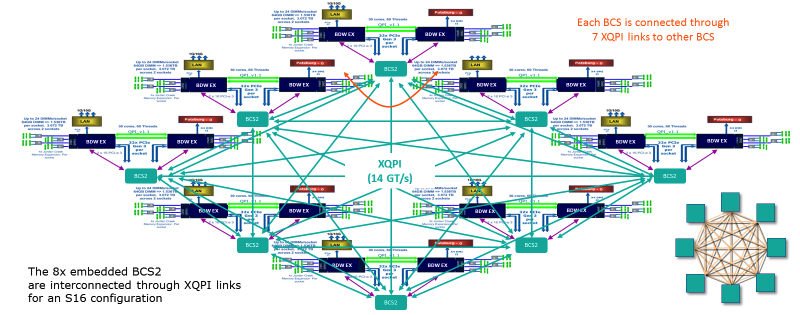
 Arquitectura pegada Bull BCS2. Todas las conexiones en el servidor son visibles aquí. Cada nodo BCS tiene 7 enlaces XQPI.
Arquitectura pegada Bull BCS2. Todas las conexiones en el servidor son visibles aquí. Cada nodo BCS tiene 7 enlaces XQPI.Gracias al almacenamiento en caché, la cantidad de interacción entre los procesadores se reduce: los procesadores de cada módulo tienen acceso a un caché común. Por lo tanto, la carga en RAM se reduce. Noda, a su vez, funciona como un interruptor de tráfico y resuelve el problema de "cuellos estrechos": redirige el tráfico a lo largo de la ruta menos utilizada.
Como resultado, la arquitectura Bull BCS2 consume solo del 5 al 10% del ancho de banda del bus Intel QPI, el estándar para la arquitectura sin cola. En cuanto a los retrasos de acceso a la memoria local, son comparables a los sistemas sin cola de 4 zócalos y son un 44% menos que los sistemas sin cola de 8 zócalos. Según las especificaciones, la velocidad total de transferencia de datos del nodo BCS es de 230 GB / s: se obtienen 25,6 GB / s para cada uno de los 7 puertos. El ancho de banda máximo es de 300 GB / s.

En cada servidor Bullion S, hay un interruptor de este tipo en la placa base. Un enlace XQPI (16 sockets) en términos de velocidad es equivalente a diez puertos 10 GigE.
 Range Bullion S
Range Bullion SEn configuraciones en procesadores 4 y 8, la diferencia entre la arquitectura pegada y sin pegamento es insignificante. Sin embargo, la situación cambia cuando se cambia a 16 procesadores. Recordamos que en sin cola, ya necesita dos servidores para esto. Y en el servidor Bullion S con arquitectura pegada, todo se rompe así:
 Los módulos de doble procesador están interconectados a través de una red XQPI con un rendimiento de 14 GT / s (miles de millones de transacciones por segundo)
Los módulos de doble procesador están interconectados a través de una red XQPI con un rendimiento de 14 GT / s (miles de millones de transacciones por segundo)Las ranuras se adaptan a cualquier procesador de la familia E7, con la excepción de E7-8893, que solo se puede usar en configuraciones de doble procesador. En comparación con el acceso a la memoria local, el retraso del sistema NUMA alcanza aproximadamente x1.5 dentro del módulo y aproximadamente x4 entre los módulos. El controlador host gestiona la partición de hardware y le permite crear hasta 8 particiones separadas que se ejecutan en el sistema operativo en los servidores Bullion S.
Como resultado, podemos alojar hasta 384 núcleos de procesador en un servidor. En cuanto a la RAM, aquí el techo es de 384 módulos DDR4 de 64 GB. En total, obtenemos 24 terabytes.
La configuración descrita es relevante para nuestros caballos de batalla: servidores Bullion S. Además de eso, tenemos la línea BullSequana S, que puede incluir hasta 32 procesadores físicos basados en la plataforma Intel Purley y las arquitecturas Skylake y Cascadelake (Q1 2019).
Ejemplos de integración
Bullion S está diseñado para tareas exigentes: SAP HANA, Oracle, MS SQL, Datalake (certificado por Cloudera en BullSequana S), virtualización / VDI en VMware y soluciones hiperconvergentes basadas en VMware vSAN. Parcialmente en los servidores Bullion S, Siemens creó la plataforma SAP HANA más grande del mundo. También basado en Bullion S, PWC ha creado una gran solución para Hadoop y análisis. En total, alrededor de 300 empresas en el mundo usan soluciones Bull.
Para que pueda descubrir las capacidades de nuestros servidores, presentaremos un plan para migrar una base de datos Oracle de Power a x86 en las sucursales de un operador de telecomunicaciones ruso:

Conclusión
Gracias al almacenamiento en caché del procesador, la arquitectura pegada permite a los procesadores comunicarse directamente con otros procesadores en el nodo. Y enlaces rápidos: no disminuya la velocidad al interactuar con otros clústeres. Hoy, hasta 16 procesadores (384 núcleos) y hasta 24 TB de RAM caben en un servidor Bullion S. El paso de escala es de dos procesadores: esto facilita la distribución de la carga financiera al crear una infraestructura de TI.
En futuros materiales, planeamos analizar nuestros servidores con más detalle. Estaremos encantados de responder sus preguntas en los comentarios.