Comencemos una serie de artículos sobre seguridad de aplicaciones web con una explicación de lo que hacen los navegadores y cómo lo hacen. Dado que la mayoría de sus clientes interactuarán con su aplicación web a través de navegadores, debe comprender los conceptos básicos de cómo funcionan estos excelentes programas.
 Cromo y lince
Cromo y linceUn navegador es un
motor de renderizado . Su trabajo es descargar una página web y presentarla de manera legible.
Aunque esto es casi una simplificación criminal, pero por ahora esto es todo lo que necesitamos saber en este momento.
- El usuario ingresa la dirección en la línea de entrada del navegador.
- El navegador descarga el "documento" en esta URL y lo muestra.
Es posible que esté acostumbrado a trabajar con uno de los navegadores más populares, como Chrome, Firefox, Edge o Safari, pero esto no significa que no haya otros navegadores en el mundo.
Por ejemplo,
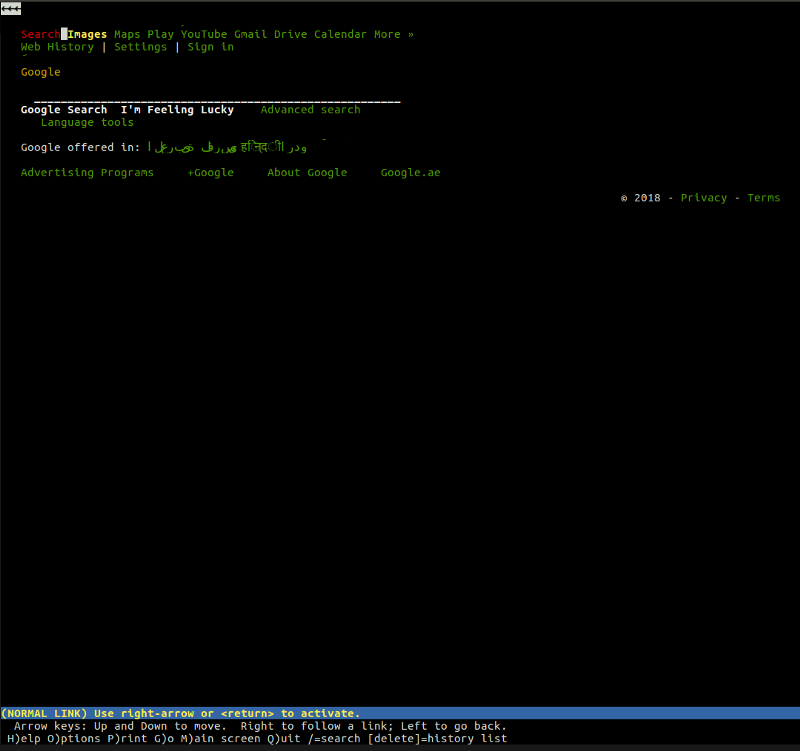
lynx es un navegador de texto de línea de comandos ligero. En el corazón de Lynx se encuentran los mismos principios que encontrará en cualquier otro navegador convencional. El usuario ingresa una dirección web (URL), el navegador descarga el documento y lo muestra; la única diferencia es que lynx no usa el motor de representación gráfica, sino la interfaz de texto, gracias a que sitios como Google se ven así:
En general, tenemos una idea de lo que hace el navegador, pero echemos un vistazo más de cerca a las acciones que realizan estas ingeniosas aplicaciones para nosotros.
¿Qué hace el navegador?
En resumen, el navegador consiste básicamente en
- Resolución DNS
- Intercambio HTTP
- Renderizado
- Restablecer y repetir
Resolución DNS
Este proceso ayuda al navegador a saber a qué servidor debe conectarse cuando un usuario ingresa una URL. El navegador se pone en contacto con el servidor DNS y detecta que
google.com coincide con el conjunto de dígitos
216.58.207.110 , la dirección IP a la que se puede conectar el navegador.
Intercambio HTTP
Tan pronto como el navegador determine qué servidor atenderá nuestra solicitud, establecerá una conexión TCP con él y comenzará el
intercambio HTTP . Esto no es más que una forma de comunicarse entre el navegador y el servidor que necesita, y para el servidor, es la forma de responder a las solicitudes del navegador.
HTTP es simplemente el nombre del protocolo más popular para comunicarse en la red, y los navegadores en su mayoría eligen HTTP cuando se comunican con los servidores. El intercambio HTTP implica que el cliente (nuestro navegador) envía una
solicitud y el servidor envía una
respuesta .
Por ejemplo, después de que el navegador se conecta con éxito al servidor que sirve
google.com , enviará una solicitud similar a esta
GET / HTTP/1.1
Host: google.com
AcceptAnalicemos la consulta línea por línea:
- GET / HTTP / 1.1 : con esta primera línea, el navegador le pide al servidor que recupere el documento de la ubicación de / , y luego agrega que el resto de la solicitud se realizará a través de HTTP / 1.1 (o también puede usar la versión 1.0 o 2)
- Host: google.com : este es el único encabezado HTTP requerido para el protocolo HTTP / 1.1 . Dado que el servidor puede servir varios dominios (google.com, google.co.uk , etc.), el Cliente aquí menciona que la solicitud fue para este host en particular.
- Aceptar: * / * : un encabezado opcional en el que el navegador le dice al servidor que aceptará cualquier respuesta. El servidor puede tener un recurso disponible en JSON, XML o HTML, por lo que puede elegir cualquier formato que prefiera
Después de que el navegador que actúa como
cliente completa su solicitud, el servidor enviará una respuesta. Aquí está la respuesta:
HTTP/1.1 200 OK Cache-Control: private, max-age=0 Content-Type: text/html; charset=ISO-8859-1 Server: gws X-XSS-Protection: 1; mode=block X-Frame-Options: SAMEORIGIN Set-Cookie: NID=1234; expires=Fri, 18-Jan-2019 18:25:04 GMT; path=/; domain=.google.com; HttpOnly <!doctype html><html"> ... ... </html>
Wow, esta vez hay mucha información que necesita ser digerida. El servidor nos dice que la solicitud fue exitosa (
200 OK ) y agrega varios encabezados a la
respuesta , por ejemplo, puede averiguar qué servidor procesó nuestra solicitud (
Servidor: gws ), cuál es la política de
Protección X-XSS para esta respuesta, etc. más allá y similares.
En este momento no necesita comprender cada línea de la respuesta. Más adelante en esta serie de publicaciones, hablaremos más sobre el protocolo HTTP, sus encabezados, etc.
Por el momento, todo lo que necesita saber es que el cliente y el servidor intercambian información y que lo hacen a través del protocolo HTTP.
Renderizado
Por último, pero no menos importante, el proceso de renderizado está en marcha. ¿Qué tan bueno es el navegador si lo único que muestra al usuario es una lista de personajes divertidos?
<!doctype html><html"> ... ... </html>
En el cuerpo de la
respuesta, el servidor incluye la presentación del documento solicitado de acuerdo con el encabezado
Content-Type . En nuestro caso, el tipo de contenido se configuró en
text / html , por lo que esperamos un marcado HTML en la respuesta, y eso es lo que encontramos en el cuerpo del documento.
Este es exactamente el momento en el que el navegador realmente muestra sus habilidades. Lee y analiza el código HTML, carga recursos adicionales incluidos en el marcado (por ejemplo, los archivos JavaScript o documentos CSS pueden especificarse allí para cargar) y los presenta al usuario lo antes posible.
Una vez más, el resultado final debería ser lo que es accesible para el Vasya promedio.
Si necesita una explicación más detallada de lo que realmente sucede cuando presionamos la tecla Intro en la barra de direcciones del navegador, le sugiero que lea el artículo
"Qué sucede cuando ..." , un intento muy meticuloso de explicar los mecanismos que subyacen a este proceso.
Dado que esta serie es sobre seguridad, voy a dar una pista sobre lo que acabamos de descubrir: los atacantes se ganan la vida fácilmente de las
vulnerabilidades en términos de intercambio y renderizado HTTP . Las vulnerabilidades, los usuarios malintencionados y otras criaturas fantásticas se encuentran en otros lugares, pero un enfoque más efectivo para proporcionar protección en los niveles mencionados ya le permite tener éxito en mejorar su estado de seguridad.
Vendedores
Los 4 navegadores más populares pertenecen a diferentes proveedores:
- Google Chrome
- Firefox por Mozilla
- Safari de manzana
- Microsoft Edge
Además de luchar entre sí para aumentar su penetración en el mercado, los proveedores también interactúan entre sí para mejorar los estándares web, que son una especie de "requisitos mínimos" para los navegadores.
W3C es la piedra angular del desarrollo de estándares, pero los navegadores a menudo desarrollan sus propias funciones, que eventualmente se convierten en estándares web, y la seguridad no es una excepción.
Por ejemplo,
las cookies de SameSite se introdujeron en Chrome 51, una característica que permitía a las aplicaciones web eliminar un cierto tipo de vulnerabilidad conocida como CSRF (más sobre esto más adelante). Otros fabricantes decidieron que era una buena idea y siguieron su ejemplo, lo que llevó a que el enfoque SameSite se convirtiera en el estándar web: Safari es actualmente el único navegador importante
sin soporte de cookies SameSite .

Esto nos dice dos cosas:
- Safari no parece preocuparse lo suficiente por la seguridad de sus usuarios (es broma: las cookies de SameSite estarán disponibles en Safari 12, que tal vez ya se hayan lanzado al momento de leer este artículo)
- arreglar las vulnerabilidades en un navegador no significa que todos sus usuarios estén seguros
El primer punto es un tiro a Safari (como dije, ¡estoy bromeando!), Y el segundo punto es realmente importante. Al desarrollar aplicaciones web, no solo debemos asegurarnos de que tengan el mismo aspecto en diferentes navegadores, sino que también proporcionen la misma protección para nuestros usuarios en diferentes plataformas.
Su estrategia de seguridad de red debe variar según las capacidades que nos proporcione el proveedor del navegador. La mayoría de los navegadores actualmente admiten el mismo conjunto de características y rara vez se desvían de su hoja de ruta general, pero todavía ocurren casos como el anterior, y esto es algo que debemos considerar al definir nuestra estrategia de seguridad.
En nuestro caso, si decidimos que solo neutralizaremos los ataques CSRF con las cookies de SameSite, deberíamos saber que estamos poniendo en riesgo a nuestros usuarios de Safari. Y nuestros usuarios también deberían saber esto.
Y por último, pero no menos importante, debe recordar que puede decidir si admite la versión del navegador o no: el soporte para cada versión del navegador no será práctico (recuerde Internet Explorer 6). A pesar de esto, el soporte seguro para varias versiones recientes de los principales navegadores suele ser una buena solución. Sin embargo, si no planea proporcionar protección en una plataforma en particular, es muy recomendable que sus usuarios lo sepan.
Consejo para los profesionales : nunca debe alentar a sus usuarios a usar navegadores obsoletos o apoyarlos activamente. Incluso si tomaste todas las precauciones necesarias, otros desarrolladores web no lo hicieron. Aliente a los usuarios a usar la última versión compatible de uno de sus principales navegadores.
Proveedor o error estándar?
El hecho de que un usuario regular acceda a nuestra aplicación a través de la ayuda de un software cliente (navegador) de terceros agrega otro nivel que complica el camino hacia una navegación web conveniente y segura: el navegador en sí puede ser una fuente de vulnerabilidad de seguridad.
Los proveedores suelen proporcionar recompensas (también conocidas como recompensas de errores) a los investigadores de seguridad que pueden estar buscando vulnerabilidades en el navegador. Estos errores no están relacionados con su aplicación web, sino con la forma en que el navegador administra la seguridad de forma independiente.
Por ejemplo,
el programa de recompensas de Chrome permite a los investigadores de seguridad ponerse en contacto con el equipo de seguridad de Chrome para informar vulnerabilidades que han descubierto. Si se confirma el hecho de la vulnerabilidad, se emitirá una solución y, por regla general, se publicará un aviso de seguridad, y el investigador recibirá una recompensa (generalmente financiera) del programa.
Empresas como Google han invertido una considerable cantidad de capital en sus programas Bug Bounty, ya que esto les permite atraer a muchos investigadores, prometiéndoles beneficios financieros si encuentran algún problema con el software probado.
Todos ganan el programa Bug Bounty: el proveedor logra aumentar la seguridad de su software, y los investigadores reciben un pago por sus hallazgos. Discutiremos estos programas más tarde, ya que creo que las iniciativas de Bug Bounty merecen una sección separada en el panorama de seguridad.
Jake Archibald es un defensor de Google que descubrió una vulnerabilidad que afecta a varios navegadores. Documentó sus esfuerzos para detectarlo, el proceso de contactar a varios proveedores afectados por la vulnerabilidad y la reacción de los representantes de los proveedores en una interesante publicación de blog , que recomiendo que lea.
Navegador de desarrollador
En este momento, deberíamos haber entendido un concepto muy simple pero bastante importante: los navegadores son solo clientes HTTP creados para un usuario de Internet "promedio".
Los navegadores son definitivamente más potentes que un simple cliente HTTP para cualquier plataforma (por ejemplo, recuerde que NodeJS
depende de 'http'), pero, al final, son "solo" el producto de la evolución natural de los clientes HTTP más simples.
En cuanto a los desarrolladores, nuestro cliente HTTP es probablemente
cURL de Daniel Stenberg, uno de los programas más populares que los desarrolladores web usan a diario. Nos permite realizar un intercambio HTTP sobre la marcha enviando una solicitud HTTP desde nuestra línea de comando:
$ curl -I localhost:8080 HTTP/1.1 200 OK server: ecstatic-2.2.1 Content-Type: text/html etag: "23724049-4096-"2018-07-20T11:20:35.526Z"" last-modified: Fri, 20 Jul 2018 11:20:35 GMT cache-control: max-age=3600 Date: Fri, 20 Jul 2018 11:21:02 GMT Connection: keep-alive
En el ejemplo anterior, solicitamos un documento en
localhost: 8080 / , y el servidor local lo respondió con éxito.
En lugar de descargar el cuerpo de respuesta a la línea de comando, usamos el indicador
-I , que le dice a cURL que solo estamos interesados en los encabezados de respuesta. Dando un paso más, podemos darle al comando cURL un poco más de información, incluida la solicitud real que se ejecuta, para que podamos examinar mejor todo este intercambio HTTP. La opción que deberíamos usar:
-v (
detallado , más):
$ curl -I -v localhost:8080 * Rebuilt URL to: localhost:8080/ * Trying 127.0.0.1... * Connected to localhost (127.0.0.1) port 8080 (#0) > HEAD / HTTP/1.1 > Host: localhost:8080 > User-Agent: curl/7.47.0 > Accept: */* > < HTTP/1.1 200 OK HTTP/1.1 200 OK < server: ecstatic-2.2.1 server: ecstatic-2.2.1 < Content-Type: text/html Content-Type: text/html < etag: "23724049-4096-"2018-07-20T11:20:35.526Z"" etag: "23724049-4096-"2018-07-20T11:20:35.526Z"" < last-modified: Fri, 20 Jul 2018 11:20:35 GMT last-modified: Fri, 20 Jul 2018 11:20:35 GMT < cache-control: max-age=3600 cache-control: max-age=3600 < Date: Fri, 20 Jul 2018 11:25:55 GMT Date: Fri, 20 Jul 2018 11:25:55 GMT < Connection: keep-alive Connection: keep-alive < * Connection #0 to host localhost left intact
La misma información está disponible en navegadores populares a través de sus DevTools.
Como hemos visto, los navegadores no son más que sofisticados clientes HTTP. Por supuesto, agregan una gran cantidad de funciones (por ejemplo, gestión de credenciales, marcadores, historial, etc.), pero la verdad es que nacieron como clientes HTTP para las personas. Esto es importante, porque en la mayoría de los casos no necesita un navegador para verificar la seguridad de su aplicación web, cuando simplemente puede "fumarlo" y mirar la respuesta.
Y lo último que me gustaría señalar: el
navegador puede ser cualquier cosa. Si tiene una aplicación móvil que usa API a través de HTTP, entonces esta aplicación es su navegador, simplemente la configura usted en un pedido individual, que reconoce solo un cierto tipo de respuestas HTTP (de su propia API).
Buceo HTTP
Como ya mencionamos, vamos a cubrir las fases de
intercambio y
renderización HTTP con el mayor detalle, ya que proporcionan la mayor cantidad
de vectores de ataque para los atacantes.
En el
próximo artículo, analizaremos más de cerca el protocolo HTTP e intentaremos comprender qué medidas debemos tomar para garantizar la seguridad del intercambio HTTP.
La traducción fue respaldada por EDISON Software , una compañía profesional de desarrollo de sitios web para grandes clientes, así como también por el desarrollo web C # y .NET .