La estructura interna de los diccionarios en Python no se limita solo al depósito y al hashing privado. Este es un mundo increíble de claves compartidas, almacenamiento en caché de hash, DKIX_DUMMY y comparaciones rápidas, que se pueden hacer aún más rápido (a costa de un error con una probabilidad aproximada de 2 ^ -64).
Si no conoce la cantidad de elementos en el diccionario que acaba de crear, cuánta memoria se gasta para cada elemento, por qué ahora (CPython 3.6 en adelante) el diccionario se implementa en dos matrices y cómo se relaciona con el mantenimiento del orden de inserción, o simplemente no vio la presentación de Raymond Hettinger "Modern Python Diccionarios Una confluencia de una docena de grandes ideas ". Entonces bienvenido.
Sin embargo, las personas que están familiarizadas con la conferencia también pueden encontrar algunos detalles e información nueva, y para los recién llegados que no están familiarizados con el cubo y el hash cerrado, el artículo también será interesante.
Los diccionarios en CPython están en todas partes, las clases, las variables globales, los parámetros de kwargs se basan en ellos, el
intérprete crea miles de diccionarios , incluso si usted mismo no agregó ningún paréntesis a su secuencia de comandos. Pero para resolver muchos problemas aplicados, también se utilizan diccionarios, no es sorprendente que su implementación continúe mejorando y que cada vez más se conviertan en diferentes trucos.
Implementación básica de diccionarios (a través de Hashmap)
Si está familiarizado con el trabajo del Hashmap estándar y el hashing privado, puede pasar al siguiente capítulo.
La idea subyacente en los diccionarios es simple: si tenemos una matriz en la que se almacenan objetos del mismo tamaño, entonces fácilmente tenemos acceso al objeto deseado, conociendo el índice.
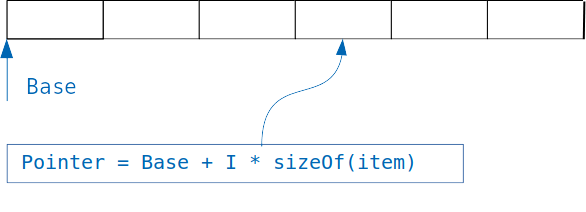
Simplemente agregamos un índice multiplicado por el tamaño del objeto al desplazamiento de la matriz, y obtenemos la dirección del objeto deseado.
Pero, ¿qué sucede si queremos organizar una búsqueda no por un índice entero, sino por una variable de otro tipo, por ejemplo, para encontrar usuarios en su dirección de correo?
En el caso de una matriz simple, tendremos que revisar los correos electrónicos de todos los usuarios de la matriz y compararlos con la búsqueda, este enfoque se llama búsqueda lineal y, obviamente, es mucho más lento que acceder al objeto por índice.
La búsqueda lineal puede acelerarse significativamente si limitamos el tamaño del área en la que desea buscar. Esto generalmente se logra tomando el resto del
hash . El campo que se busca es la clave.
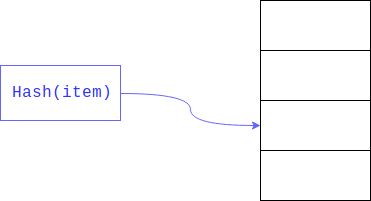
Como resultado, se realiza una búsqueda lineal no en todo el conjunto grande, sino a lo largo de su parte.
Pero, ¿y si ya hay un elemento allí? Esto podría suceder muy bien, ya que nadie garantizó que los residuos de dividir el hash fueran únicos (como el hash mismo). En este caso, el objeto se colocará en el siguiente índice; si está ocupado, cambiará por otro índice y así sucesivamente hasta que encuentre uno libre. Al recuperar un elemento, se verán todas las claves con el mismo hash.
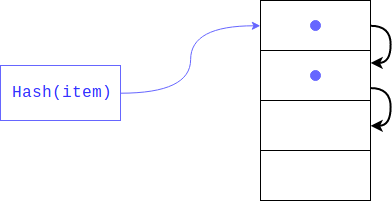
Este tipo de hashing se llama privado. Si hay pocas celdas libres en el diccionario, entonces dicha búsqueda amenaza con degenerar en una lineal, por lo que perderemos todas las ganancias, para las cuales se creó el diccionario, para evitar esto, el intérprete mantiene el conjunto lleno 1/2 - 2/3. Si no hay suficientes celdas libres, se crea una nueva matriz dos veces más grande que la anterior, y los elementos de la antigua se transfieren a la nueva a la vez.
¿Qué hacer si el artículo ha sido eliminado? En este caso, se forma una celda vacía en la matriz y el algoritmo de búsqueda por clave no puede distinguir, esta celda está vacía porque un elemento con dicho hash no estaba en el diccionario o porque se eliminó. Para evitar la pérdida de datos durante la eliminación, la celda está marcada con un indicador especial (DKIX_DUMMY). Si se encuentra este indicador durante una búsqueda de elementos, la búsqueda continúa, la celda se considera ocupada, si se inserta, la celda se sobrescribirá.
Características de implementación en Python
Cada elemento del diccionario debe contener un enlace al objeto y la clave de destino. La clave debe almacenarse para el procesamiento de colisión, el objeto, por razones obvias. Dado que tanto la clave como el objeto pueden ser de cualquier tipo y tamaño, no podemos almacenarlos directamente en la estructura, se encuentran en la memoria dinámica y los enlaces a ellos se almacenan en la estructura del elemento de la lista. Es decir, el tamaño de un elemento debe ser igual al tamaño mínimo de dos punteros (16 bytes en sistemas de 64 bits). Sin embargo, el intérprete también almacena el hash, esto se hace para no volver a calcularlo con cada aumento en el tamaño del diccionario. En lugar de calcular el hash de cada clave de una manera nueva y tomar el resto de la división por el número de cubos, el intérprete simplemente lee el valor ya guardado. Pero, ¿qué pasa si se cambia el objeto clave? En este caso, el hash debe recalcularse y el valor almacenado será incorrecto. Tal situación es imposible, ya que los tipos mutables no pueden ser claves de diccionario.
La estructura del elemento del diccionario se define de la siguiente manera:
typedef struct { Py_hash_t me_hash;
El tamaño mínimo del diccionario es declarado por la constante PyDict_MINSIZE, que es 8. Los desarrolladores decidieron que este es el tamaño óptimo para evitar el desperdicio innecesario de memoria para almacenar valores vacíos y tiempo para la expansión dinámica de la matriz. Por lo tanto, al crear un diccionario (hasta la versión 3.6), necesitaba un mínimo de 8 elementos en el diccionario * 24 bytes en la estructura = 192 bytes (esto no tiene en cuenta el resto de los campos: el costo de la variable del diccionario en sí, el contador del número de elementos, etc.)
Los diccionarios también se utilizan para implementar campos de clase personalizados. Python le permite cambiar dinámicamente el número de atributos, esta dinámica no requiere costos adicionales, ya que agregar / eliminar un atributo es esencialmente equivalente a la operación correspondiente en el diccionario. Sin embargo, una minoría de programas usa esta funcionalidad; la mayoría están limitados a campos declarados en __init__. Pero cada objeto debe almacenar su propio diccionario, con sus claves y hashes, a pesar de que coinciden con otros objetos. Una mejora lógica aquí es el almacenamiento de claves compartidas en un solo lugar, que es exactamente lo que se implementó en el
PEP 412 - Diccionario de intercambio de claves . La capacidad de cambiar dinámicamente el diccionario no desapareció: si se cambia el orden o el número de claves, el diccionario se convierte de las claves de división a la normal.
Para evitar colisiones, la "carga" máxima del diccionario es 2/3 del tamaño actual de la matriz.
#define USABLE_FRACTION(n) (((n) << 1)/3)
Por lo tanto, la primera extensión ocurrirá cuando se agregue el sexto elemento.
La matriz resulta bastante descargada, durante la operación del programa, de la mitad a un tercio de las celdas permanecen vacías, lo que conduce a un mayor consumo de memoria. Para evitar esta limitación y, si es posible, almacenar solo los datos necesarios, se agregó un nuevo
nivel de abstracción de matriz.
En lugar de almacenar una matriz dispersa, por ejemplo:
d = {'timmy': 'red', 'barry': 'green', 'guido': 'blue'}
A partir de la versión 3.6, los diccionarios se organizan de la siguiente manera:
indices = [None, 1, None, None, None, 0, None, 2] entries = [[-9092791511155847987, 'timmy', 'red'], [-8522787127447073495, 'barry', 'green'], [-6480567542315338377, 'guido', 'blue']]
Es decir solo se almacenan aquellos registros que son realmente necesarios, se sacan de la tabla hash en una matriz separada y solo los índices de los registros correspondientes se almacenan en la tabla hash. Si inicialmente la matriz tomó 192 bytes, ahora es solo 80 (3 * 24 bytes para cada registro + 8 bytes para los índices). Compresión alcanzada al 58%. [2]
El tamaño de un elemento en los índices también cambia dinámicamente, inicialmente es igual a un byte, es decir, toda la matriz se puede colocar en un registro, cuando el índice comienza a caber en 8 bits, luego los elementos se expanden a 16, luego a 32 bits. Hay constantes especiales DKIX_EMPTY y DKIX_DUMMY para elementos vacíos y eliminados, respectivamente, la expansión del índice a 16 bytes se produce cuando hay más de 127 elementos en el diccionario.
Se agregan nuevos objetos a las entradas, es decir, cuando se expande el diccionario, no es necesario moverlos, solo necesita aumentar el tamaño de los índices y sobrecargarlo con índices.
Al iterar sobre un diccionario, la matriz de índices no es necesaria, los elementos se devuelven secuencialmente desde las entradas, porque Cada vez que se agregan elementos al final de las entradas, el diccionario guarda automáticamente el orden de aparición de los elementos. Por lo tanto, además de reducir la memoria necesaria para almacenar el diccionario, recibimos una expansión dinámica más rápida y la preservación del orden de las teclas. Reducir la memoria es bueno en sí mismo, pero al mismo tiempo puede aumentar el rendimiento, ya que permite que ingresen más registros en la memoria caché del procesador.
A los desarrolladores de CPython les gustó tanto esta implementación que ahora se requieren diccionarios para mantener el orden de inserción por especificación. Si antes se determinó el orden de los diccionarios, es decir estaba estrictamente definido por un hash y no se modificó de principio a inicio, luego se agregó un poco de aleatoriedad para que las claves fueran diferentes cada vez, ahora se requieren las teclas del diccionario para preservar el orden. No está claro cuánto fue necesario y qué hacer si aparece una implementación aún más efectiva del diccionario pero no conserva el orden de inserción.
Sin embargo, hubo solicitudes para implementar un mecanismo para preservar la declaración de atributos en
clases y
kwargs , y esta implementación le permite cerrar estos problemas sin mecanismos especiales.
Así es como se ve en el
código CPython :
struct _dictkeysobject { Py_ssize_t dk_refcnt; Py_ssize_t dk_size; dict_lookup_func dk_lookup; Py_ssize_t dk_usable; Py_ssize_t dk_nentries; char dk_indices[]; };
Pero la iteración es más complicada de lo que inicialmente podría pensar, hay mecanismos de verificación adicionales de que el diccionario no se cambió durante la iteración, uno de ellos es una
versión de 64 bits
del diccionario que almacena cada diccionario.
Finalmente, consideramos el mecanismo para resolver colisiones. La cuestión es que, en Python, los valores hash son fácilmente predecibles:
>>>[hash(i) for i in range(4)] [0, 1, 2, 3]
Y dado que al crear un diccionario a partir de estos hashes, se toma el resto de la división, luego, de hecho, determinan a qué depósito irá el registro, solo los últimos bits de la clave (si es un número entero). Puede imaginar una situación en la que muchos objetos "quieren" entrar en cubos vecinos, en cuyo caso tendrá que mirar muchos objetos que están fuera de lugar al buscar. Para reducir el número de colisiones y aumentar el número de bits que determinan a qué depósito irá el registro, se implementó el siguiente mecanismo:
perturb es una variable entera inicializada por un hash. Cabe señalar que en el caso de una gran cantidad de colisiones, se restablece a cero y la fórmula calcula el siguiente índice:
j = (5 * j + 1) % n
Al extraer un elemento del diccionario, se realiza la misma búsqueda: se calcula el índice de la ranura en la que debe ubicarse el elemento, si la ranura está vacía, se lanza la excepción "valor no encontrado". Si hay un valor en esta ranura, debe verificar que su clave coincida con la que está buscando, esto puede no ser posible si se produce una colisión. Sin embargo, la clave puede ser casi cualquier objeto, incluido uno para el que la operación de comparación lleva un tiempo considerable. Para evitar una larga operación de comparación, se utilizan varios trucos en Python:
primero, se comparan los punteros, si el puntero clave del objeto deseado es igual al puntero del objeto que se está buscando, es decir, apuntan a la misma área de memoria, entonces la comparación devuelve inmediatamente verdadero. Pero eso no es todo. Como sabe, los objetos iguales deben tener hashes iguales, lo que significa que los objetos con hashes diferentes no son iguales. Después de verificar los punteros, se verifican los hashes; si no son iguales, se devolverá falso. Y solo si los hashes son iguales, se llamará a una comparación honesta.
¿Cuál es la probabilidad de tal resultado? Aproximadamente 2 ^ -64, por supuesto, debido a la fácil previsibilidad del valor hash, puede elegir fácilmente ese ejemplo, pero en realidad, esta verificación a menudo no llega a cuánto. Raymond Hettinger ensambló el intérprete cambiando la última operación de comparación con un simple retorno verdadero. Es decir el intérprete consideraba iguales los objetos si sus hashes son iguales. Luego estableció pruebas automatizadas de muchos proyectos populares en este intérprete, que finalizaron con éxito. Puede parecer extraño considerar que los objetos con hashes iguales sean iguales, no para verificar adicionalmente su contenido, y depender únicamente del hash, pero lo hace regularmente cuando usa los protocolos git o torrent. Consideran que los archivos (bloques de archivos) son iguales si sus hashes son iguales, lo que bien puede conducir a errores, pero sus creadores (y todos nosotros) esperamos que valga la pena señalar, sin razón, que la probabilidad de una colisión es extremadamente pequeña.
Ahora finalmente deberías entender la estructura del diccionario, que se ve así:
typedef struct { PyObject_HEAD Py_ssize_t ma_used; uint64_t ma_version_tag; PyDictKeysObject *ma_keys; PyObject **ma_values; } PyDictObject;
Cambios futuros
En el capítulo anterior, consideramos lo que ya se ha implementado y puede ser utilizado por todos en su trabajo, pero las mejoras, por supuesto, no se limitan a: los planes para la versión 3.8 incluyen
soporte para diccionarios invertidos . De hecho, nada impide en lugar de iterar desde el principio de una serie de elementos y aumentar los índices, comenzando desde el final y disminuyendo los índices.
Materiales adicionales
Para una inmersión más profunda en el tema, se recomienda familiarizarse con los siguientes materiales:
- Registro del informe al comienzo del artículo.
- Propuesta para una nueva implementación de diccionarios
- Código fuente del diccionario en CPython