Queremos compartir la historia que sucedió en uno de nuestros proyectos para el Año Nuevo. La esencia del proyecto es que automatiza el trabajo de los médicos en instituciones médicas. Durante la visita del paciente, el médico escribe información en la grabadora, luego se transcribe el audio. Después del proceso de transcripción, es decir Convertir la grabación de audio en texto: se forma un documento médico de acuerdo con los estándares relevantes y se envía de vuelta a la clínica, de donde proviene la grabación de audio, donde el médico remitente la recibe, la verifica y aprueba. Después de pasar los controles obligatorios, el documento se envía a los pacientes finales.
Todas las instituciones médicas que usan el producto pueden dividirse condicionalmente en dos grandes grupos:
- Hospedaje en el centro de datos de nuestro cliente, que es totalmente responsable de la funcionalidad de la aplicación, tanto de software como de hardware. Por ejemplo, si se agota el espacio en disco o no hay suficiente rendimiento del servidor en la CPU;
- Autohospedado: colocan todo el equipo directamente en casa y son responsables de su propio desempeño. Nuestro cliente les proporciona la aplicación y su soporte.
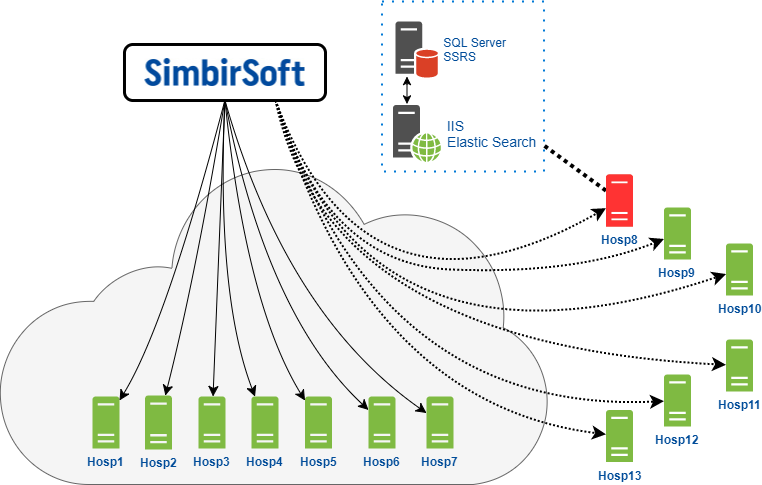
Así es como nuestro equipo interactúa con los servidores finales que están alojados directamente en la nube de nuestro cliente.

Tenemos acceso a estos servidores para llevar a cabo todo el trabajo programado y el mantenimiento que se requiere.
El segundo grupo, los clientes autohospedados, para ellos, la nube del cliente actúa como una puerta de enlace a través de la cual nos conectamos a estos servidores. En este caso, tenemos derechos limitados, a menudo no podemos realizar ninguna operación debido a la configuración de seguridad. Nos conectamos a los servidores a través de RDP, el Protocolo de escritorio remoto en el sistema operativo Windows. Naturalmente, todo esto funciona a través de una VPN.
Debe tenerse en cuenta que cada servidor representado en el diagrama es en realidad una combinación de un servidor de aplicaciones y un servidor de bases de datos. En el servidor de la base de datos, respectivamente, se instalan el DBMS de MS SQL Server y el servicio de informes SSRS. Además, la versión del servidor MSSQL es diferente en todas las clínicas: 2008, 2012, 2014. Además de las versiones en sí, se instalan diferentes Service Packs y parches en todas partes. En general, un zoológico completo.
En el servidor de aplicaciones hemos instalado el servidor web IIS y ElasticSearch. ElasticSearch es un motor de búsqueda que también implementa la búsqueda de texto completo.
La esencia principal en términos de nuestro producto es el "trabajo". El trabajo es una entidad abstracta que vincula toda la información relacionada con la recepción de un paciente en particular. Esta información incluye:
- datos sobre el médico;
- datos del paciente;
- datos sobre la visita;
- archivo de audio (discurso del médico);
- documentos (varias versiones);
- historial de procesamiento del trabajo;
- información de sucursal, etc.
Este diagrama muestra un esquema de base de datos simplificado desde el cual puede ver las relaciones entre las tablas principales. Esta es solo la parte básica, de hecho, la base de datos tiene más de 200 tablas.

Un poco sobre la clínica donde ocurrió el incidente:
- 1500-2000 trabajos por día;
- Más de 1000 usuarios activos (médicos + secretarios);
- Autohospedado.
DB:
- Tamaño: 800+ Gb (750K + obras, 2M + documentos);
- DBMS: MS SQL Server 2008 R2;
- Modelo de recuperación: simple.
Aquí quiero hacer una pequeña explicación. Hay 3 modelos de recuperación en SQL Server: simple, de registro masivo y completo. No hablaré sobre el tercero ahora, explicaré sobre el primero y el segundo. La principal diferencia es que en el modelo simple no almacenamos el historial de transacciones en el registro: tan pronto como se haya confirmado la transacción, se eliminará el registro del registro de transacciones. Cuando se utiliza el modo de recuperación completa, todo el historial de cambios de datos se almacena en un registro de transacciones. ¿Qué nos da esto? En el caso de una situación imprevista, cuando necesitamos revertir la base de datos de las copias de seguridad, podemos volver no solo a una copia de seguridad específica, sino que podemos regresar a cualquier punto en el tiempo, hasta una determinada transacción, es decir, tenemos en las copias de seguridad, no solo un cierto estado de la base de datos en el momento de la copia de seguridad, sino que también hay un historial completo de cambios de datos.
Creo que no vale la pena explicar que el modo simple solo se usa en desarrollo, en servidores de prueba y su uso en producción es inaceptable. De ninguna manera.
Pero la clínica, aparentemente, tenía sus propios pensamientos sobre este tema;)
Inicio
Unos días después, el Año Nuevo, todos se preparan para las vacaciones, compran regalos, decoran árboles de Navidad, pasan fiestas corporativas y esperan un largo fin de semana.
22 de diciembre (viernes) 1 día
14:31 El cliente dijo que no recibió el siguiente informe diario. El informe llega por correo dos veces al día en un horario; es necesario para controlar el envío de datos a un sistema de integración externo, lo cual no es demasiado crítico.
Podría haber varias razones:
- Problemas con SMTP, las cartas simplemente no fueron entregadas (cambiaron la contraseña, por ejemplo, y no se lo dijeron a nadie);
- Problemas en el lado del servidor de los informes;
- Algo le sucedió a la base de datos.
16:03 La clínica a veces cambia la contraseña a SMTP, sin avisar a nadie al respecto, por lo tanto, después de completar las tareas actuales, verificamos el informe manualmente con calma al iniciarlo a través de la interfaz web; obtenemos un error que indica problemas en la base de datos.
Un ejemplo del error que recibimos al iniciar el informe.
SQL Server detected a logical consistency-based I/O error: incorrect checksum (expected: 0x9876641f; actual: 0xa3255fbf). It occurred during a read of page (1:876) in database ID 7 at offset 0x000000006d8000 in file 'D:\Program Files\Microsoft SQL Server\MSSQL10_50.MSSQLSERVER\MSSQL\DATA\ServerLive.mdf'.
Esto indica que la base de datos tiene páginas corruptas. Teníamos una ligera sensación de ansiedad.
20:53 Para evaluar la extensión del daño, ejecutamos una verificación de la base de datos utilizando el comando especial
DBCC CHECKDB . Dependiendo del tamaño del daño, el comando de prueba puede tomar bastante tiempo, por lo que ejecutamos el comando por la noche. Aquí tenemos la suerte de que esto sucedió el viernes por la tarde, es decir, tuvimos al menos todos los días libres para resolver este problema.
En ese momento, la situación era la siguiente:
23 de diciembre (sábado) 2do día
10:02 En la mañana, encontramos que verificar la base de datos con CHECKDB es flexible, esto se debió a la falta de espacio libre en el disco, porque durante el proceso de verificación, la base de datos temporal tempdb se usa activamente, y en algún momento el espacio libre en el disco simplemente se agotó.
Por lo tanto, decidimos, en lugar de verificar toda la base de datos, iniciar inmediatamente un escaneo de tabla. Para hacer esto, use el
comando DBCC CHECKTABLE .
10:46 Decidimos comenzar con la tabla JobHistory, que probablemente está dañada, ya que fue la que se utilizó para generar el informe. Esta tabla, como su nombre lo indica, conserva la historia de todas las obras, es decir, las transiciones de trabajo entre etapas.
Ejecute
DBCC CHECKTABLE ('dbo.JobHistory') .
La comprobación de esta tabla revela tablas dañadas en la base de datos, lo que se esperaba en principio.
12:00 En este momento, si la base de datos usara el modelo de recuperación completa, podríamos restaurar las páginas dañadas de la copia de seguridad, y eso estaría terminado, pero nuestra base de datos estaba en modo simple. Por lo tanto, la única opción para reparar daños sigue siendo el lanzamiento del mismo comando con el parámetro especial
REPAIR_ALLOW_DATA_LOSS . Esto puede provocar la pérdida de datos.
Empezamos La verificación nuevamente finaliza con un error: obtenemos el error de que la restauración de esta tabla es imposible hasta que se restauran las tablas relacionadas. La tabla de historial se refiere a la tabla de trabajo (Jobs) por la clave externa, por lo tanto, concluimos que también hay daños en la tabla de trabajo principal (Jobs).
13:30 El siguiente paso es verificar la tabla de trabajos, al mismo tiempo, esperamos que el daño esté en el índice y no en los datos. En este caso, será suficiente para nosotros simplemente reconstruir el índice para la recuperación de datos.
17:33 Después de un tiempo, descubrimos que nuestro servidor no está disponible a través de RDP. Probablemente se apagó, la verificación no se completó, el trabajo se suspendió. Informamos a la clínica que el servidor no está disponible, levántelo.
La ansiedad leve adquiere formas muy específicas.
24 de diciembre (domingo) 3er día
14:31 Más cerca de la cena, el servidor está elevado, volvemos a ejecutar la verificación de la tabla de trabajos.
DBCC CHECKTABLE ('dbo.Jobs')16:05 La verificación no se completó, el servidor no está disponible. De nuevo
Después de un tiempo, el servidor ya no está disponible, antes de que pudiéramos terminar de verificar la tabla. En este punto, el servicio de TI de la clínica realiza una serie de verificaciones del servidor. Estamos esperando la finalización del trabajo.
Debido a las vacaciones, la comunicación entre nosotros y el cliente fue lenta: esperábamos respuestas a las preguntas durante varias horas.
25 de diciembre (lunes - Navidad) 4to día
16:00 Al día siguiente se levantó el servidor, el cliente tiene Navidad, y nuevamente comenzamos a verificar la tabla, pero esta vez excluimos los índices del escaneo, y dejamos solo la verificación de datos. Y después de un tiempo, el servidor no estará disponible nuevamente.
Que esta pasando
En este momento, los pensamientos comienzan a aparecer, que esto no es solo una coincidencia, y existe la sospecha de que podría ser un daño a nivel de hierro (se cayó un disco duro). Suponemos que hay sectores defectuosos en el disco y cuando el escaneo intenta leer datos de estos sectores, el sistema se bloquea. Informamos a nuestro cliente sobre nuestra suposición.
El cliente ejecuta una comprobación de disco en la máquina host.
17:19 El servicio de TI de la clínica informó que el archivo de la máquina virtual está dañado, ¡esto es malo!
Todavía no podemos trabajar, y estamos esperando una señal cuando solucionen el problema y podamos continuar nuestro trabajo.
26 de diciembre (martes) Día 5
14:05 El servicio de clínica de TI lanza otro proceso de recuperación de disco. Nos dijeron que podemos ejecutar CHECKTABLE en paralelo para verificar la tabla. Comenzamos la prueba nuevamente: la máquina virtual falla nuevamente, informamos al cliente que el archivo de la máquina virtual todavía está dañado.
En estos días, todas las comunicaciones con el cliente son muy lentas con un gran retraso debido a las vacaciones.
27 de diciembre (miércoles) Día 6
14:00 Comenzamos la verificación del disco usando Windows -
checkdisk dentro de la máquina virtual - no se detectaron problemas.
La base de datos está en modo Simple, por lo que las posibilidades de arreglar la base de datos actual con las herramientas DBMS tienden a cero, porque No podemos recuperar páginas dañadas individuales.
Estamos comenzando a considerar la opción de retroceder y restaurar la base de datos desde la copia de seguridad.
Verificamos las copias de seguridad de la base de datos y descubrimos que las copias de seguridad no se hicieron utilizando los medios DBMS, la última copia de seguridad fue en 2014, es decir. No hay copias de seguridad de la base de datos. Por qué no lo hicieron es un tema aparte, es responsabilidad de la clínica garantizar la eficiencia y la seguridad de la base de datos.
Existe una alta probabilidad de que no funcione para restaurar la base de datos actual, comenzamos a considerar otras opciones para la reversión.
Analicemos con más detalle la situación con las copias de seguridad en la clínica.
La situación con las copias de seguridad:
- No hay copias de seguridad de la base de datos (!!!)
- No hay instantáneas de la máquina virtual (!?)
- Pero hay copias de seguridad de disco (full + inc)
La base de datos está en el disco D, respectivamente, hicieron copias de seguridad completas semanales y copias de seguridad incrementales diarias.
- todos los viernes a las 20:00 respaldo completo
- copia de seguridad incremental todos los días
- hay una copia de seguridad completa de los días 15 y 22
- hay copias de seguridad diarias hasta el 21
Es decir en principio, podemos regresar al estado antes de que ocurra el problema.
Estamos esperando una actualización de la clínica para iniciar la reversión de la base de datos desde la copia de seguridad.
Al mismo tiempo, la clínica envió una solicitud al proveedor de hierro (HP) marcada como "urgente".
28 de diciembre (jueves) Día 7
13:13 El servicio de TI de la clínica comienza a configurar una nueva máquina virtual, como No es posible reparar el daño en el archivo de la vieja máquina virtual.
19:09 Una nueva
máquina virtual
está disponible con SQL Server instalado.
El siguiente paso es restaurar la base de datos desde la copia de seguridad del disco. Para comenzar, decidimos retroceder al día 22, si el problema aún está presente, luego retrocedemos al 21, 20 y así sucesivamente, hasta que lleguemos a un estado de trabajo.
Era el día 28 en el patio, estábamos en la fiesta corporativa, y aquí nos dicen que la clínica tiene problemas para restaurar las copias de seguridad, ¡porque los BACKUPS están VACÍOS!
Aquí está la noticia!
Al restaurar una copia de seguridad de la unidad D desde el 21, resulta que está vacía, como todos los demás. Se obtienen copias de seguridad directas de la destructora, parecen estar allí, pero al mismo tiempo no lo están. No está completamente claro cómo sucedió esto, pero, por lo que pudimos entender, el punto es que no hay suficiente espacio en el disco para almacenar las copias de seguridad del disco. Asignaron 500 Gb de copias de seguridad para el almacenamiento, pero en el momento del incidente, la base de datos ya pesaba 800 Gb, por lo tanto, en principio, la copia de seguridad no podría tener éxito. Es decir las copias de seguridad se realizaron regularmente de acuerdo con el cronograma, pero debido a la falta de espacio, terminaron con un error y, en consecuencia, estaban vacías, y el servicio de TI de la clínica ni siquiera tuvo la idea de verificar que todo estuviera bien con ellas. No hagas eso.
29 de diciembre (viernes) Día 8
13:11 Discusión de otras acciones. Posibles opciones:
- Intentar copiar archivos de base de datos (archivos .ldf + .two): las posibilidades de éxito son muy bajas;
- Intentar hacer una copia de seguridad de la base de datos vuelve a tener muy pocas posibilidades;
- Configurar la replicación: puede funcionar.
Se asignó una unidad de 1 Tb en el nuevo servidor, lo que obviamente no es suficiente si intentamos hacer una copia de seguridad y restaurar desde él, porque en el peor de los casos, sin compresión, las copias de seguridad ocuparán tanto espacio como la base de datos original, es decir 800 Gb.
Agregue lugares en el nuevo servidor y proceda a copiar los archivos de la base de datos.
Se creó una base de datos en el nuevo servidor y se restauró el esquema de la base de datos; esto permitirá al menos procesar nuevos trabajos. La clínica al menos podrá aceptar nuevos pacientes que utilicen dicho sistema.
14:36 Por lo tanto, procedemos a la opción número uno, aunque no esperamos mucho éxito.
Detenga SQL Server, comience a copiar el archivo de datos (mdf) y el registro (ldf).
16:13 Después de la mitad del archivo de registro, se copió con éxito (48 Gb) y ya se copiaron 50 GB del archivo de datos (quedan 795 de 846 GB). A esta velocidad, tomará aproximadamente 12 horas completar la copia.
16:30 El antiguo servidor de la base de datos se apagó al copiar el archivo, lo cual es bastante esperado.
17:09 Por lo tanto, pasamos a la siguiente opción: configurar la replicación, mientras que podemos especificar qué datos se replicarán, es decir, primero podemos excluir las tablas dañadas deliberadamente y primero copiar los datos no dañados y luego transferir las tablas problemáticas en partes. Pero esta opción, desafortunadamente, tampoco funciona, porque ni siquiera podemos crear una publicación con ciertas tablas debido a la corrupción de la base de datos.
También estamos considerando opciones de transferencia de datos.
20:01 Como resultado, comenzamos simplemente a transferir datos del servidor antiguo al nuevo mediante la importación y exportación en orden de prioridad.
21:35 Primero, los datos más críticos, luego archivados y menos críticos (~ 300 GB). En la primera ola de exportación, quedaban menos de 300 GB de datos. La tabla Documentos (300 GB) también está excluida. Comenzamos el proceso de copia por la noche.
30 de diciembre (sábado) Día 9
15:00 Seguimos transfiriendo datos. La tabla de trabajos no está disponible en absoluto. La mayoría de las tablas fueron copiadas por este tiempo.
Pero sin
Jobs, todo es inútil, porque es el enlace principal entre todos los datos y les da significado y valor desde el punto de vista comercial. Sin él, solo tenemos un conjunto de datos dispares que simplemente no podemos usar.
Además, en este punto, la recuperación del esquema de la base de datos se ha completado.
Las consecuencias del incidente:En este punto, tenemos una gran pérdida de datos en vivo.
Es decir formalmente, tenemos algunos datos en la base de datos, pero, de hecho, no hay forma de usarlos o conectarlos, por lo que podemos hablar sobre la pérdida completa de datos.
Datos perdidos en más de 750,000 ingresos de pacientes.
Esto es realmente triste!
- Este es un gran golpe para la reputación de nuestro cliente, que puede resultar ser un gran problema para ellos en los negocios al concluir nuevos contratos y encontrar nuevos clientes.
- La pérdida de tantos datos para la clínica puede generar serios problemas y multas, porque Estos son datos confidenciales que contienen confidencialidad médica y, en sentido literal, dependen de la vida de las personas.
Comenzamos a pensar qué podemos hacer en esta situación. Comenzaron a clasificar el sistema por huesos para encontrar pistas.
15:16 Analizando todos los aspectos del sistema, entendemos que podemos intentar extraer los datos que faltan del índice ElasticSearch. La cuestión es que, debido a la configuración incorrecta de los índices de ElasticSearch, almacena no solo los campos por los que se realiza la búsqueda de texto completo, sino en general todo, es decir, de hecho hay una copia completa de los datos y teóricamente podemos extraer datos de allí sobre trabajos y volver a ponerlos en nuestra base de datos. Se espera que los datos aún puedan recuperarse.
¡Un error al que puedes poner un monumento!
 18:00
18:00 Se escribió rápidamente una utilidad para extraer los datos, y después de unas horas nos aseguramos de que el enfoque funcione y que los datos puedan restaurarse.
20:00 Ha comenzado la restauración del trabajo de ElasticSearch con la ayuda de una utilidad escrita. El enfoque funcionó, podemos restaurar los datos en el trabajo. Paralelamente, comenzamos a extraer las últimas versiones del documento para cada trabajo.
31 de diciembre (domingo - Año nuevo) Día 10
14:09 Durante la noche, se restauraron 188 811 obras.
20:13 Al ver nuestro éxito, la clínica decide posponer la transferencia del servidor al servicio de HP para darnos tiempo para extraer los datos máximos del servidor anterior.
Con tales noticias, celebramos el Año Nuevo))
01 de enero (lunes) día 11
11:23 Preparación para iniciar el sistema después del incidente:
- IIS reconfigurado en el servidor de aplicaciones;
- reconfiguró todos los servicios necesarios para trabajar con el nuevo servidor de base de datos;
- disparadores, procedimientos almacenados, funciones restauradas.
14:28 Luego comenzaron a copiar la tabla de documentos, que se omitió debido al gran tamaño durante la transferencia inicial.
- El viejo servidor DB se apaga nuevamente. Obviamente, la tabla Documentos también está dañada, es con ella que se almacena toda la información del paciente. Afortunadamente, no está completamente dañado, podemos hacerle solicitudes, y cuando una solicitud nos devuelve un registro dañado, en ese momento el servidor se bloquea y se apaga. Podemos extraer algunos de los datos.
En consecuencia, le enviamos una señal al cliente, ellos levantan el servidor y, en paralelo, continuamos preparando la nueva base de datos para el lanzamiento del sistema.
18:01 Recuperación de todas las restricciones de integridad después de la transferencia de la parte principal de los datos.
22:02 Restauración de restricciones completada. Simplemente transferimos los datos sin procesar al máximo. La presencia de restricciones de integridad complicaría enormemente nuestra tarea.
02 de enero (martes) Día 12
05:52 El antiguo servidor de base de datos se apagó nuevamente al copiar el documento. Él es criado rápidamente para que podamos continuar trabajando.
09:00 Fue posible recuperar por lotes aproximadamente 200,000 documentos (aproximadamente 20%)
Comenzamos a usar diferentes métodos de recuperación: ordenando por diferentes columnas para obtener datos desde el final o el comienzo de la tabla, hasta que nos topamos con alguna parte dañada de la tabla.
13:42 Comenzó a copiar trabajos de archivo en la tabla; afortunadamente, no está dañado.
17:08 Restaurado todo el trabajo de archivo (491 380 piezas).
El sistema está listo para iniciarse: los usuarios pueden crear y procesar nuevos trabajos.
Desafortunadamente, debido a un daño parcial en la tabla de documentos, no puede simplemente transferir todos los datos de ella, como con otras tablas, porque La mesa está parcialmente dañada. Por lo tanto, al intentar recuperar todos los datos, la solicitud se bloquea al intentar leer páginas corruptas. Por lo tanto, extraemos los datos puntuales utilizando diferentes tipos y tamaños de muestra:
- Ordenar por diferentes campos (ID, DateTime);
- Ordenar ascendente, descendente;
- Trabajar con pequeños grupos de líneas (1000, 100);
- Obteniendo trabajos por ID.
03 de enero (miércoles) Día 13
08:58 Continúa el proceso de restauración de documentos. Los documentos se restauraron solo para trabajo activo e incompleto. En este punto, 1000 trabajos (activos) sin documentos.
11:38 Migró todos los trabajos de SQL
13:17 5 funciona sin documentos, 231 no funciona, pero hay un archivo de audio, debe volver a sincronizarlo.
04 de enero (jueves) Día 14
La recuperación manual y la verificación del trabajo restante ha comenzado.
El sistema funciona, monitoreando y reparando errores en línea.
05 de enero (viernes) Día 15
Informe la migración a SSRS planificada.
La transferencia a un nuevo servidor no es posible porque la clínica instaló una versión anterior de SQL Server y no funcionará para transferir la base de datos del servidor anterior.
Opciones:
- Actualice SQL Server de 2008 a 2008 R2;
- Configura todo desde cero.
Se decidió esperar la actualización de SQL Server.
09:21 Ha comenzado la restauración de antecedentes de documentos para el trabajo completado: el proceso es largo y tomará varios días.
13:28 Cambio de prioridad de restauración de documentos por departamentos.
18:18 La clínica dio acceso a SMTP, configuración de correo
Resultado:
- Se restauraron casi todos los datos (solo se perdieron 5 trabajos);
- Se emitieron recomendaciones sobre el mantenimiento de la base de datos para prevenir tales situaciones;
- Las copias de seguridad de la base de datos se configuran utilizando SQL Server;
- Monitoreo adicional de respaldos de nuestra parte, alertas en caso de falla.