
17 mil millones de eventos, 60 millones de sesiones de usuarios y una gran cantidad de fechas virtuales tienen lugar en Badoo diariamente. Cada evento se almacena perfectamente en bases de datos relacionales para su posterior análisis en SQL y más allá.
Bases de datos transaccionales distribuidas modernas con docenas de terabytes de datos: un verdadero milagro de la ingeniería. Pero SQL, como la encarnación del álgebra relacional en la mayoría de las implementaciones estándar, todavía no nos permite formular consultas en términos de tuplas ordenadas.
En el último artículo de la serie sobre máquinas virtuales , hablaré sobre un enfoque alternativo para encontrar sesiones interesantes: el motor de expresión regular ( Pig Match ), que se define para secuencias de eventos.
¡La máquina virtual, el código de bytes y el compilador se incluyen de forma gratuita!
Primera parte, introductoria
Segunda parte, optimización
Tercera parte, aplicada (actual)
Sobre eventos y sesiones
Supongamos que ya tenemos un almacén de datos que le permite ver de forma rápida y secuencial los eventos de cada una de las sesiones de usuario.
Queremos encontrar sesiones por solicitudes como "contar todas las sesiones donde hay una subsecuencia específica de eventos", "buscar partes de una sesión descritas por un patrón determinado", "devolver la parte de la sesión que ocurrió después de un patrón determinado" o "contar cuántas sesiones alcanzaron ciertas partes plantilla ". Esto puede ser útil para una variedad de tipos de análisis: búsqueda de sesiones sospechosas, análisis de embudos, etc.
Las subsecuencias deseadas deben de alguna manera ser descritas. En su forma más simple, esta tarea es similar a encontrar una subcadena en un texto; queremos tener una herramienta más poderosa: expresiones regulares. Las implementaciones modernas de motores de expresión regular utilizan con mayor frecuencia (¡lo adivinaste!) Máquinas virtuales.
La creación de pequeñas máquinas virtuales para emparejar sesiones con expresiones regulares se discutirá a continuación. Pero primero, aclararemos las definiciones.
Un evento consta de un tipo de evento, tiempo, contexto y un conjunto de atributos específicos para cada tipo.
El tipo y el contexto de cada evento son enteros de listas predefinidas. Si todo está claro con los tipos de eventos, entonces el contexto es, por ejemplo, el número de la pantalla en la que ocurrió el evento dado.
Un atributo de evento es un entero arbitrario cuyo significado está determinado por el tipo de evento. Un evento puede no tener atributos, o puede haber varios.
Una sesión es una secuencia de eventos ordenados por tiempo.
Pero finalmente vamos al grano. El zumbido, como dicen, disminuyó y salí al escenario.
Compara en una hoja de papel
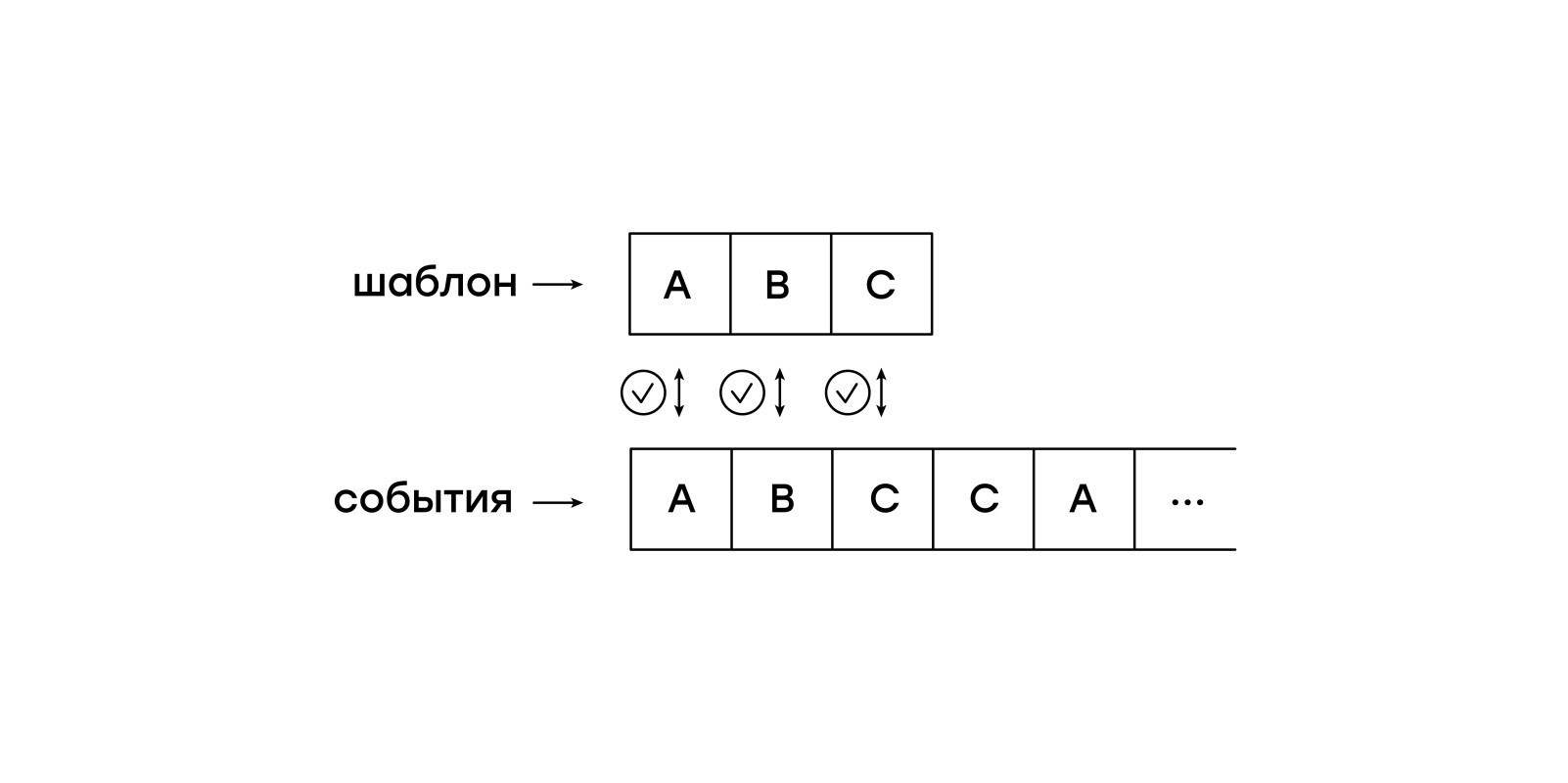
Una característica de esta máquina virtual es la pasividad con respecto a los eventos de entrada. No queremos mantener toda la sesión en la memoria y permitir que la máquina virtual cambie independientemente de un evento a otro. En cambio, alimentaremos los eventos de la sesión a la máquina virtual uno por uno.
Definamos las funciones de la interfaz:
matcher *matcher_create(uint8_t *bytecode); match_result matcher_accept(matcher *m, uint32_t event); void matcher_destroy(matcher *matcher);
Si todo está claro con las funciones matcher_create y matcher_destroy, vale la pena comentar matcher_accept. La función matcher_accept recibe una instancia de la máquina virtual y el siguiente evento (32 bits, donde 16 bits para el tipo de evento y 16 bits para el contexto), y devuelve un código que explica qué debe hacer el código del usuario a continuación:
typedef enum match_result {
Códigos de operación de máquinas virtuales:
typedef enum matcher_opcode {
El bucle principal de una máquina virtual:
match_result matcher_accept(matcher *m, uint32_t next_event) { #define NEXT_OP() \ (*m->ip++) #define NEXT_ARG() \ ((void)(m->ip += 2), (m->ip[-2] << 8) + m->ip[-1]) for (;;) { uint8_t instruction = NEXT_OP(); switch (instruction) { case OP_ABORT:{ return MATCH_ERROR; } case OP_NAME:{ uint16_t name = NEXT_ARG(); if (event_name(next_event) != name) return MATCH_FAIL; break; } case OP_SCREEN:{ uint16_t screen = NEXT_ARG(); if (event_screen(next_event) != screen) return MATCH_FAIL; break; } case OP_NEXT:{ return MATCH_NEXT; } case OP_MATCH:{ return MATCH_OK; } default:{ return MATCH_ERROR; } } } #undef NEXT_OP #undef NEXT_ARG }
En esta versión simple, nuestra máquina virtual coincide secuencialmente con el patrón descrito por bytecode con los eventos entrantes. Como tal, esto simplemente no es una comparación muy concisa de los prefijos de dos líneas: la plantilla deseada y la línea de entrada.
Los prefijos son prefijos, pero queremos encontrar los patrones deseados no solo al principio, sino también en un lugar arbitrario de la sesión. La solución ingenua es reiniciar la coincidencia de cada evento de sesión. Pero esto implica una visualización múltiple de cada uno de los eventos y comer bebés algorítmicos.
El ejemplo del primer artículo de la serie, en efecto, simula reiniciar una partida usando la reversión (retroceso en inglés). El código en el ejemplo parece, por supuesto, más delgado que el que se da aquí, pero el problema no ha desaparecido: cada uno de los eventos tendrá que verificarse muchas veces.
No puedes vivir así.
Yo, yo otra vez y yo otra vez

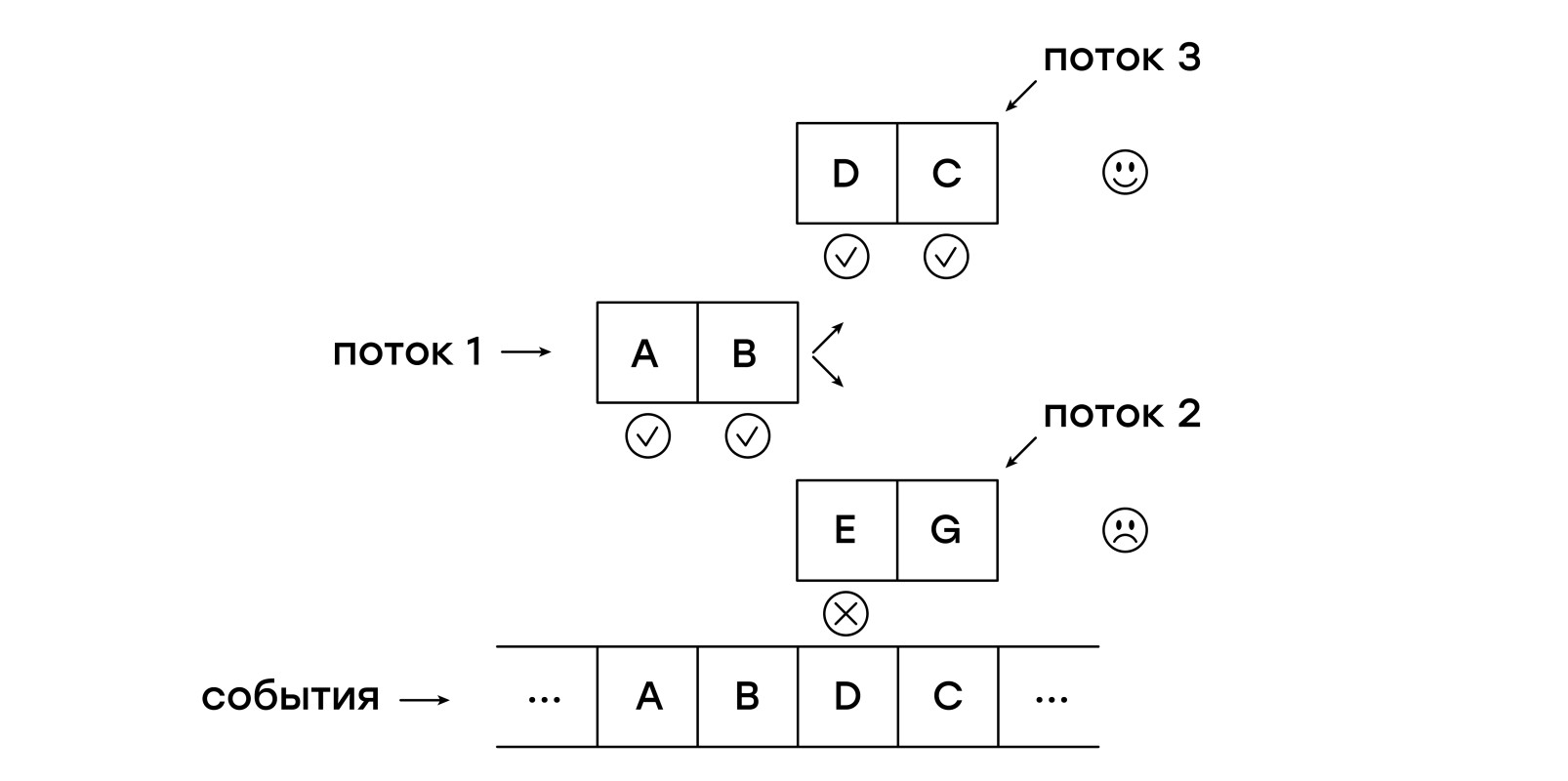
Una vez más, describamos el problema: debemos hacer coincidir la plantilla con los eventos entrantes, comenzando por cada uno de los eventos comenzando una nueva comparación. Entonces, ¿por qué no hacemos exactamente eso? ¡Deje que la máquina virtual camine sobre los eventos entrantes en varios hilos!
Para hacer esto, necesitamos obtener una nueva entidad: una secuencia. Cada hilo almacena un solo puntero - a la instrucción actual:
typedef struct matcher_thread { uint8_t *ip; } matcher_thread;
Naturalmente, ahora en la máquina virtual en sí no almacenaremos el puntero explícito. Será reemplazado por dos listas de hilos (más sobre ellos a continuación):
typedef struct matcher { uint8_t *bytecode; matcher_thread current_threads[MAX_THREAD_NUM]; uint8_t current_thread_num; matcher_thread next_threads[MAX_THREAD_NUM]; uint8_t next_thread_num; } matcher;
Y aquí está el bucle principal actualizado:
match_result matcher_accept(matcher *m, uint32_t next_event) { #define NEXT_OP(thread) \ (*(thread).ip++) #define NEXT_ARG(thread) \ ((void)((thread).ip += 2), ((thread).ip[-2] << 8) + (thread).ip[-1]) /* - */ add_current_thread(m, initial_thread(m)); // for (size_t thread_i = 0; thread_i < m->current_thread_num; thread_i++ ) { matcher_thread current_thread = m->current_threads[thread_i]; bool thread_done = false; while (!thread_done) { uint8_t instruction = NEXT_OP(current_thread); switch (instruction) { case OP_ABORT:{ return MATCH_ERROR; } case OP_NAME:{ uint16_t name = NEXT_ARG(current_thread); // , , // next_threads, if (event_name(next_event) != name) thread_done = true; break; } case OP_SCREEN:{ uint16_t screen = NEXT_ARG(current_thread); if (event_screen(next_event) != screen) thread_done = true; break; } case OP_NEXT:{ // , .. // next_threads add_next_thread(m, current_thread); thread_done = true; break; } case OP_MATCH:{ return MATCH_OK; } default:{ return MATCH_ERROR; } } } } /* , */ swap_current_and_next(m); return MATCH_NEXT; #undef NEXT_OP #undef NEXT_ARG }
En cada evento recibido, primero agregamos un nuevo hilo a la lista current_threads, verificando la plantilla desde el principio, luego de lo cual comenzamos a rastrear la lista current_threads, siguiendo cada puntero siguiendo las instrucciones.
Si se encuentra una instrucción NEXT, el subproceso se coloca en la lista next_threads, es decir, espera a que se reciba el próximo evento.
Si el patrón de hilo no coincide con el evento recibido, dicho hilo simplemente no se agrega a la lista next_threads.
La instrucción MATCH sale inmediatamente de la función, informando un código de retorno que el patrón coincide con la sesión.
Al finalizar el rastreo de la lista de subprocesos, se intercambian las listas actuales y siguientes.
En realidad, eso es todo. Podemos decir que literalmente estamos haciendo lo que queríamos: al mismo tiempo estamos verificando varias plantillas, lanzando un nuevo proceso de coincidencia para cada uno de los eventos de la sesión.
Múltiples identidades y ramas en plantillas
La búsqueda de una plantilla que describa una secuencia lineal de eventos es, por supuesto, útil, pero queremos obtener expresiones regulares completas. Y los flujos que creamos en la etapa anterior también son útiles aquí.
Supongamos que queremos encontrar una secuencia de dos o tres eventos que nos interesen, algo así como una expresión regular en líneas: "a? Bc". En esta secuencia, el símbolo "a" es opcional. ¿Cómo expresarlo en bytecode? Fácil!
Podemos comenzar dos hilos, uno para cada caso: con el símbolo "a" y sin él. Para hacer esto, presentamos una instrucción adicional (del tipo SPLIT addr1, addr2), que inicia dos hilos desde las direcciones especificadas. Además de SPLIT, JUMP también es útil para nosotros, que simplemente continúa la ejecución con la instrucción especificada en el argumento directo:
typedef enum matcher_opcode { OP_ABORT, OP_NAME, OP_SCREEN, OP_NEXT,
El ciclo en sí y el resto de las instrucciones no cambian, solo presentamos dos nuevos controladores:
Tenga en cuenta que las instrucciones agregan hilos a la lista actual, es decir, continúan funcionando en el contexto del evento actual. El hilo dentro del cual se produjo la rama no entra en la lista de los siguientes hilos.
Lo más sorprendente de esta máquina virtual de expresión regular es que nuestros hilos y este par de instrucciones son suficientes para expresar casi todas las construcciones generalmente aceptadas cuando se combinan cadenas.
Expresiones regulares sobre eventos.
Ahora que tenemos una máquina virtual adecuada y herramientas para ello, podemos manejar la sintaxis de nuestras expresiones regulares.
La grabación manual de códigos de operación para programas más serios se cansa rápidamente. La última vez, no hice un analizador completo, pero el usuario verdadero mostró las capacidades de su biblioteca raddsl usando el mini lenguaje PigletC como ejemplo . Estaba tan impresionado con la brevedad del código que, con la ayuda de raddsl, escribí un pequeño compilador de expresiones regulares de cadenas en cien o doscientos en Python. El compilador y las instrucciones para su uso están en GitHub. El resultado del compilador en lenguaje ensamblador es entendido por una utilidad que lee dos archivos (un programa para una máquina virtual y una lista de eventos de sesión para verificación).
Para empezar, nos restringimos al tipo y al contexto del evento. El tipo de evento se denota con un solo número; si necesita especificar un contexto, especifíquelo con dos puntos. El ejemplo más simple:
> python regexp/regexp.py "13" # , 13 NEXT NAME 13 MATCH
Ahora un ejemplo con contexto:
python regexp/regexp.py "13:12" # 13, 12 NEXT NAME 13 SCREEN 12 MATCH
Los sucesivos eventos deben estar separados de alguna manera (por ejemplo, por espacios):
> python regexp/regexp.py "13 11 10:9" 08:40:52 NEXT NAME 13 NEXT NAME 11 NEXT NAME 10 SCREEN 9 MATCH
Plantilla más interesante:
> python regexp/regexp.py "12|13" SPLIT L0 L1 L0: NEXT NAME 12 JUMP L2 L1: NEXT NAME 13 L2: MATCH
Presta atención a las líneas que terminan con dos puntos. Estas son las etiquetas. La instrucción SPLIT crea dos subprocesos que continúan la ejecución desde las etiquetas L0 y L1, y JUMP al final de la primera rama de ejecución simplemente continúa hasta el final de la rama.
Puede elegir entre cadenas de expresiones más verdaderamente agrupando subsecuencias entre paréntesis:
> python regexp/regexp.py "(1 2 3)|4" SPLIT L0 L1 L0: NEXT NAME 1 NEXT NAME 2 NEXT NAME 3 JUMP L2 L1: NEXT NAME 4 L2: MATCH
Un evento arbitrario se indica con un punto:
> python regexp/regexp.py ". 1" NEXT NEXT NAME 1 MATCH
Si queremos mostrar que la subsecuencia es opcional, le ponemos un signo de interrogación:
> python regexp/regexp.py "1 2 3? 4" NEXT NAME 1 NEXT NAME 2 SPLIT L0 L1 L0: NEXT NAME 3 L1: NEXT NAME 4 MATCH
Por supuesto, las repeticiones regulares múltiples (más o asterisco) también son comunes en las expresiones regulares:
> python regexp/regexp.py "1+ 2" L0: NEXT NAME 1 SPLIT L0 L1 L1: NEXT NAME 2 MATCH
Aquí simplemente ejecutamos la instrucción SPLIT muchas veces, comenzando nuevos hilos en cada ciclo.
Del mismo modo con un asterisco:
> python regexp/regexp.py "1* 2" L0: SPLIT L1 L2 L1: NEXT NAME 1 JUMP L0 L2: NEXT NAME 2 MATCH

Perspectiva
Otras extensiones a la máquina virtual descrita pueden ser útiles.
Por ejemplo, se puede expandir fácilmente al verificar los atributos del evento. Para un sistema real, supongo que usar una sintaxis como "1: 2 {3: 4, 5:> 3}", que significa: evento 1 en el contexto 2 con el atributo 3 que tiene el valor 4 y el valor del atributo 5 mayor que 3. Aquí los atributos simplemente puede pasarlo en una matriz a la función matcher_accept.
Si también pasa el intervalo de tiempo entre eventos a matcher_accept, puede agregar una sintaxis al lenguaje de plantilla que le permite omitir el tiempo entre eventos: "1 mindelta (120) 2", que significará: evento 1, entonces el intervalo es de al menos 120 segundos, evento 2 Combinado con la preservación de una subsecuencia, esto le permite recopilar información sobre el comportamiento del usuario entre dos subsecuencias de eventos.
Otras cosas útiles que son relativamente fáciles de agregar son: almacenar subsecuencias de expresiones regulares, separar los operadores de asterisco codiciosos y ordinarios y más, y así sucesivamente. En términos de la teoría de los autómatas, nuestra máquina virtual es un autómata finito no determinista, para cuya implementación no es difícil hacer tales cosas.
Conclusión
Nuestro sistema está desarrollado para interfaces de usuario rápidas, por lo tanto, el motor de almacenamiento de la sesión está escrito y optimizado específicamente para el paso por todas las sesiones. Todos los miles de millones de eventos divididos en sesiones se comparan con patrones en segundos en un solo servidor.
Si la velocidad no es tan crítica para usted, entonces se puede diseñar un sistema similar como una extensión para un sistema de almacenamiento de datos más estándar, como una base de datos relacional tradicional o un sistema de archivos distribuido.
Por cierto, en las últimas versiones del estándar SQL ya apareció una característica similar a la descrita en el artículo, y las bases de datos individuales ( Oracle y Vertica ) ya lo han implementado. Yandex ClickHouse, a su vez, implementa su propio lenguaje tipo SQL, pero también tiene funciones similares .
Distrayendo eventos y expresiones regulares, quiero repetir que la aplicabilidad de las máquinas virtuales es mucho más amplia de lo que parece a primera vista. Esta técnica es adecuada y ampliamente utilizada en todos los casos en que es necesario distinguir claramente entre las primitivas que el motor del sistema comprende y el subsistema "frontal", es decir, por ejemplo, algún lenguaje DSL o de programación.
Esto concluye una serie de artículos sobre los diversos usos de los intérpretes de código de bytes y las máquinas virtuales. Espero que a los lectores de Habr les haya gustado la serie y, por supuesto, estaré encantado de responder cualquier pregunta sobre el tema.
Los intérpretes de código de bytes para lenguajes de programación son un tema específico, y hay relativamente poca literatura sobre ellos. Personalmente, me gustó el libro de Ian Craig, Virtual Machines, aunque describe no tanto la implementación de intérpretes como máquinas abstractas, modelos matemáticos que subyacen a varios lenguajes de programación.
En un sentido más amplio, otro libro está dedicado a las máquinas virtuales: "Máquinas virtuales: plataformas flexibles para sistemas y procesos" ("Máquinas virtuales: plataformas versátiles para sistemas y procesos"). Esta es una introducción a las diversas aplicaciones de virtualización, que abarca la virtualización de lenguajes, procesos y arquitecturas informáticas en general.
Los aspectos prácticos del desarrollo de motores de expresión regular rara vez se discuten en la popular literatura del compilador. Pig Match y el ejemplo del primer artículo se basan en ideas de una sorprendente serie de artículos de Russ Cox, uno de los desarrolladores del motor Google RE2.
La teoría de las expresiones regulares se presenta en todos los libros de texto académicos en compiladores. Es costumbre referirse al famoso "Libro del Dragón" , pero recomendaría comenzar con el enlace de arriba.
Mientras trabajaba en este artículo, utilicé por primera vez un sistema interesante para el rápido desarrollo de compiladores para Python raddsl , que pertenece al bolígrafo del usuario true-grue (¡gracias, Peter!). Si se enfrenta a la tarea de crear prototipos de un lenguaje o desarrollar rápidamente algún tipo de DSL, debe prestarle atención.