Un quinteto es una forma de registrar datos atómicos que indican su papel en nuestras vidas. Los quintetos pueden describir cualquier dato, mientras que cada uno de ellos contiene información exhaustiva sobre usted y sobre las relaciones con otros quintetos. Representa los términos del dominio, independientemente de la plataforma utilizada. Su tarea es simplificar el almacenamiento de datos y mejorar la visibilidad de su presentación.

Hablaré sobre un nuevo enfoque para almacenar y procesar información y compartiré mis pensamientos sobre la creación de una plataforma de desarrollo en este nuevo paradigma.
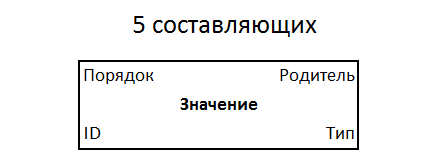
El quinteto tiene propiedades: tipo, valor, padre, orden entre hermanos. Con el identificador, solo se obtienen 5 componentes. Esta es la forma universal más simple de registrar información, un nuevo estándar que podría adaptarse a todos. Los quintetos se almacenan en un sistema de archivos de una sola estructura, en un campo de información indexada monótono continuo.
Para registrar información, hay un número infinito de estándares, enfoques y reglas, cuyo conocimiento es necesario para trabajar con estos registros. Las normas se describen por separado y no se relacionan directamente con los datos. En el caso de los quintetos, al tomar cualquiera de ellos, puede obtener información relevante sobre su naturaleza, propiedades y reglas de trabajo con su área temática. Su estándar es uniforme y sin cambios para todas las áreas. El quinteto está oculto para el usuario: los metadatos y los datos están disponibles para él en la forma familiar para muchos.
Un quinteto no es solo información, sino también comandos ejecutables. Pero, sobre todo, son los datos que desea almacenar, registrar y recuperar. Como en nuestro caso están directamente dirigidos, conectados e indexados, los almacenaremos en una especie de base de datos. Para probar el prototipo de un sistema de almacenamiento de datos de quinteto, por ejemplo, utilizamos una base de datos relacional regular.
Estructura de quinteto
La idea principal de este artículo es reemplazar los tipos de máquina con términos humanos y reemplazar las variables con objetos. No por aquellos objetos que necesitan un constructor, destructor, interfaces y un recolector de basura, sino por unidades de información de cristal puro en las que opera un cliente. Es decir, si el cliente dice "Aplicación", para guardar la
esencia de esta información en los medios no requeriría la experiencia de un programador.
Es útil enfocar la atención del usuario solo en el valor del objeto, y su tipo, padre, orden (entre iguales en subordinación) e identificador deben ser obvios por el contexto o simplemente ocultos. Esto significa que el
usuario no sabe nada sobre quintetos , simplemente establece su tarea, se asegura de que se acepte correctamente y luego comienza su ejecución.
Conceptos basicos
Hay un conjunto de tipos de datos que cualquiera puede entender: cadena, número, archivo, texto, fecha, etc. Un conjunto tan simple es suficiente para formular el problema y para "programarlo" y los tipos necesarios para su implementación. Los tipos básicos representados por quintetos pueden verse así:

En este caso, algunos de los componentes del quinteto no se usan, y se usa como el tipo base. Esto hace que el núcleo del sistema sea más fácil de navegar cuando se navega en metadatos.
Antecedentes
Debido a la brecha analítica entre el usuario y el programador, se produce una deformación significativa de los conceptos en la etapa de establecimiento del problema. La subestimación, la incomprensibilidad y la iniciativa no solicitada a menudo convierten un pensamiento simple y comprensible del cliente en una mezcla lógicamente imposible, a juzgar desde el punto de vista del usuario.

La transferencia de conocimiento debe ocurrir sin pérdida o distorsión. Además, en el futuro, al organizar el almacenamiento de este conocimiento, es necesario deshacerse de las restricciones impuestas por el sistema de gestión de datos seleccionado.
Cómo almacenar datos
Como regla, hay muchas bases de datos en el servidor; cada una de ellas contiene una descripción de la estructura de la entidad con un conjunto específico de atributos: datos interconectados. Se almacenan en un orden específico, idealmente óptimo para el muestreo.
El sistema de almacenamiento de información propuesto es un compromiso entre varios métodos conocidos: columna, cadena y NoSQL. Está diseñado para resolver las tareas generalmente realizadas por uno de estos métodos.
Por ejemplo, la teoría de las bases de columnas se ve hermosa: leemos solo la columna deseada, y no todas las filas de registros en su conjunto. Sin embargo, en la práctica, es poco probable que los datos se coloquen en los medios para que sean aplicables a docenas de secciones diferentes del análisis. Tenga en cuenta que los atributos y las métricas analíticas se pueden agregar y eliminar, a veces más rápido de lo que podemos reconstruir esta economía de columnas. Sin mencionar el hecho de que los datos en la base de datos se pueden ajustar, lo que también violará la belleza del plan de muestreo debido a la fragmentación inevitable.
Metadatos
Introdujimos un concepto, un término, para describir cualquier objeto con el que operamos: entidad, propiedad, solicitud, archivo, etc. Definiremos todos los términos que usamos en nuestra área temática. Y con su ayuda, describiremos todas las entidades que tienen detalles, incluso en forma de relaciones entre entidades. Por ejemplo, accesorios: un enlace a una entrada de directorio de estado. El término está escrito en un quinteto de datos.
Un conjunto de descripciones de términos son metadatos que definen la estructura de tablas y campos en una base de datos normal. Por ejemplo, existe la siguiente estructura de datos: una aplicación desde una fecha que tiene contenido (texto de la aplicación) y un Estado, a la cual los participantes en el proceso de producción agregan comentarios que indican la fecha. En el constructor de base de datos tradicional, se verá así:

Dado que decidimos ocultar al usuario todos los detalles no esenciales, como las ID de enlace, por ejemplo, el esquema se simplificará un poco: se eliminan las menciones de ID y se combinan los nombres de entidades y sus valores clave.
El usuario "dibuja" la tarea: una solicitud de la fecha de hoy que tiene un estado (valor de referencia) y al que puede agregar comentarios que indican la fecha:

Ahora vemos 6 campos de datos diferentes en lugar de 9, y todo el esquema nos ofrece leer y comprender 7 palabras en lugar de 13. Aunque, por supuesto, esto está lejos de ser lo principal.
Los siguientes son los quintetos generados por el núcleo de control para describir esta estructura:

Se proporcionan explicaciones en lugar de los valores de quinteto resaltados en gris para mayor claridad. Estos campos no se completan porque toda la información necesaria está determinada únicamente por los componentes restantes.
Vea cómo se relacionan los quintetos Datos del usuario
Considere almacenar dicho conjunto de datos para la tarea anterior:

Los datos en sí se almacenan en quintetos de acuerdo con la estructura que indica la membresía en ciertos términos en la forma de dicho conjunto:
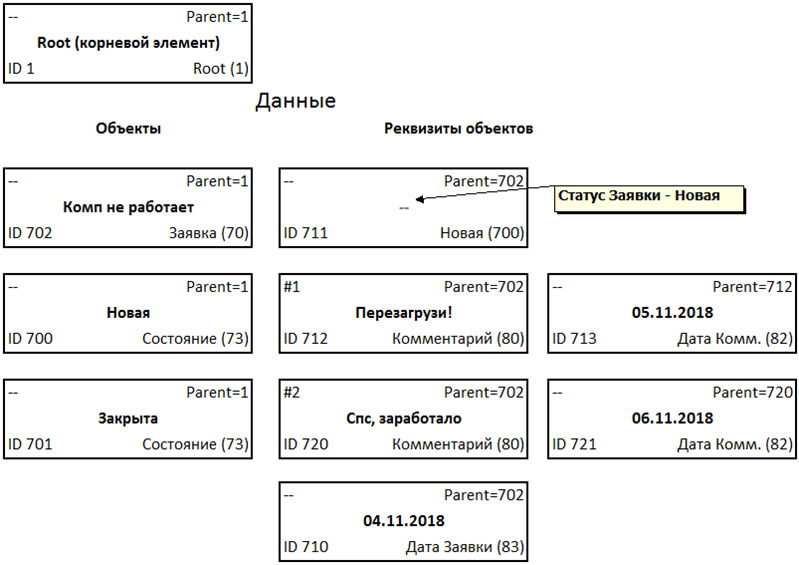
Vemos una estructura jerárquica familiar que se almacena utilizando el método de Lista de adyacencia también conocido.
Rendimiento
El ejemplo anterior es muy simple, pero ¿qué sucederá cuando la estructura sea miles de veces más compleja y los datos sean gigabytes?
Necesitaremos:
- La estructura jerárquica considerada anteriormente es 1 pc.
- B-tree para buscar por ID, padre y tipo - 3 piezas.
Por lo tanto, todos los registros en nuestra base de datos serán indexados, incluidos los datos y metadatos. Dicha indexación es necesaria para preservar las propiedades de una base de datos relacional, la herramienta más simple y popular. El índice principal es en realidad compuesto (ID principal + tipo). Un índice por tipo también es compuesto (tipo + valor) para la búsqueda rápida de objetos de un tipo dado.
Los metadatos nos permiten deshacernos de la recursividad: por ejemplo, para encontrar todos los detalles de un objeto determinado, utilizamos el índice por ID principal. Si necesita buscar objetos de cierto tipo, se utiliza un índice por ID de tipo. Un tipo es un análogo de un nombre de tabla y un campo en un DBMS relacional.

En cualquier caso, no escaneamos todo el conjunto de datos, e incluso con una gran cantidad de valores de cualquier tipo, el valor deseado se puede encontrar en una pequeña cantidad de pasos.
La base de la plataforma de desarrollo.
De por sí, dicha base de datos no es autosuficiente para la programación de aplicaciones y no está completa, como dicen, según Turing. Pero no estamos hablando aquí solo de la base de datos, sino que estamos tratando de cubrir todos los aspectos: los objetos son, entre otras cosas, algoritmos de control arbitrarios que se pueden iniciar y funcionarán.
Como resultado, en lugar de estructuras de bases de datos complejas y algoritmos de código fuente de control almacenados por separado, obtenemos un campo de información uniforme, limitado por el volumen del medio y marcado con metadatos. Los datos en sí se presentan al usuario de una manera que él comprende: la estructura del área temática y las entradas correspondientes en ella. El usuario cambia arbitrariamente la estructura y los datos, incluida la realización de operaciones masivas con ellos.
No hemos inventado nada nuevo: todos los datos ya están almacenados en el sistema de archivos y la búsqueda en ellos se realiza utilizando B-trees, en el sistema de archivos, en las bases de datos. Acabamos de reorganizar la presentación de los datos para que sea más fácil y más visual trabajar con ellos.
Para trabajar con esta representación de datos, necesitará un núcleo muy compacto: nuestro motor de base de datos es un orden de magnitud más pequeño que el BIOS de la computadora y, por lo tanto, se puede hacer si no en hardware, al menos lo más rápido y lo más fácil posible. Por razones de seguridad, también es de solo lectura.
Al agregar una nueva clase al ensamblaje de mi amado .Net, podemos observar la pérdida de 200-300 MB de RAM solo para la descripción de esta clase. Estos megabytes no caben en el caché del nivel correcto, lo que hace que el sistema se meta en un lío con las consecuencias resultantes. Una situación similar con Java. Describir la misma clase con quintetos tomará decenas o cientos de bytes, ya que la clase usa solo trucos primitivos para trabajar con datos que ya son familiares para el núcleo.
Cómo lidiar con diferentes formatos: RDBMS, NoSQL, bases de columnasEl enfoque descrito cubre dos áreas principales: RDBMS y NoSQL. Al resolver problemas que aprovechan las bases de datos en columnas, debemos decirle al núcleo que ciertos objetos deben almacenarse, teniendo en cuenta la optimización del muestreo en masa de los valores de un determinado tipo de datos (nuestro término). Por lo tanto, el kernel podrá colocar datos en el disco de la manera más rentable.
Por lo tanto, para la base de la columna, podemos ahorrar significativamente el espacio ocupado por los quintetos: use solo uno o dos de sus componentes para almacenar datos útiles en lugar de cinco, y también use el índice solo para indicar el comienzo de las cadenas de datos. En muchos casos, solo el índice se usará para muestras de nuestra base de columnas analógicas, sin la necesidad de acceder a los datos de la tabla misma.
Cabe señalar que la idea no establece un objetivo para recopilar todos los desarrollos avanzados de estos tres tipos de bases de datos. Por el contrario, el motor del nuevo sistema se reducirá tanto como sea posible, incorporando solo el mínimo necesario de funciones, todo lo que cubre las consultas DDL y DML en el concepto descrito aquí.
Paradigma de programación
El uso del enfoque descrito no se limita solo a los quintetos, sino que promueve un paradigma diferente al que están acostumbrados los programadores. En lugar de un lenguaje imperativo, declarativo u objeto, el lenguaje de consulta se propone como más familiar para los humanos y nos permite establecer la tarea directamente en la computadora, evitando los programadores y la capa impenetrable de los entornos de desarrollo existentes.
Por supuesto, un traductor de un idioma de usuario gratuito a un idioma de requisitos claros seguirá siendo necesario en la mayoría de los casos.Este tema se describirá con más detalle en artículos separados con ejemplos y desarrollos existentes.
Entonces, en resumen, funciona de la siguiente manera:
- Una vez describimos con quintetos tipos de datos primitivos: cadena, número, archivo, texto y otros, y también capacitamos al núcleo para trabajar con ellos. La capacitación se reduce a la presentación correcta de los datos y la implementación de operaciones simples con ellos.
- Ahora describimos en quintetos los términos de usuario (tipos de datos), en forma de metadatos. La descripción se reduce a especificar un tipo de datos primitivo para cada tipo de usuario y determinar la subordinación.
- Ingrese los quintetos de datos de acuerdo con la estructura especificada por los metadatos. Cada quinteto de datos contiene un enlace a su tipo y padre, que le permite encontrarlo rápidamente en el almacén de datos.
- Las tareas principales se reducen a buscar datos y realizar operaciones simples con ellos para implementar algoritmos arbitrariamente complejos descritos por el usuario.
- El usuario gestiona datos y algoritmos utilizando una interfaz visual que presenta visualmente tanto el primero como el segundo.
La completitud de todo el sistema está garantizada por la realización de los requisitos básicos: el núcleo puede realizar operaciones secuenciales, ramificar condicionalmente, procesar conjuntos de datos y detener el trabajo cuando se logra un cierto resultado.
Para una persona, el beneficio es la simplicidad de la percepción, por ejemplo, en lugar de declarar un ciclo que involucra variables
for (i=0; i<length(A); i++) if A[i] meets a condition do something with A[i]
se utiliza una construcción más amigable para los humanos, como
with every A, that match a condition, do something
Soñamos con abstraernos de las sutilezas de bajo nivel de implementar un sistema de información: bucles, constructores, funciones, manifiestos, bibliotecas: todo esto ocupa demasiado espacio en el cerebro de un programador, dejando poco espacio para el trabajo creativo y el desarrollo.
Escalamiento
Una aplicación moderna es inconcebible sin medios de ampliación: se requiere una capacidad ilimitada para ampliar la capacidad de carga de un sistema de información. En el enfoque descrito, en vista de la extrema simplicidad de la organización de datos, el escalado se organiza no más complicado que en las arquitecturas existentes.
En el ejemplo anterior con aplicaciones, puede separarlas, por ejemplo, por su ID, haciendo que la generación de ID con bytes altos fijos para diferentes servidores. Es decir, cuando se usan 32 bits para el almacenamiento de ID, los dos, tres, cuatro o más bits más significativos, según sea necesario, indicarán el servidor en el que se almacenan estas aplicaciones. Por lo tanto, cada servidor tendrá su propio grupo de ID.
El núcleo de un solo servidor puede funcionar independientemente de otros servidores, sin saber nada sobre ellos. Al crear una aplicación, se le dará alta prioridad al servidor con el número mínimo de ID utilizados, asegurando una distribución de carga uniforme.
Dado un conjunto limitado de posibles variaciones de solicitudes y respuestas con una sola organización de datos, necesitará un despachador bastante compacto que distribuya las solicitudes entre los servidores y agregue sus resultados.