¿Has notado cómo cualquier nicho de mercado, que se ha hecho popular, atrae a los vendedores del comercio de seguridad de la información con miedo? Te convencen de que en caso de un ciberataque, la compañía no podrá hacer frente a ninguna de las tareas para responder al incidente. Y aquí, por supuesto, aparece un amable asistente: un proveedor de servicios que está listo para una cierta cantidad para salvar al cliente de cualquier molestia y la necesidad de tomar cualquier decisión. Explicamos por qué este enfoque puede ser peligroso no solo para la billetera, sino también para el nivel de seguridad de la empresa, qué beneficios prácticos puede aportar la participación de un proveedor de servicios y qué decisiones deben permanecer siempre en el área de responsabilidad del cliente.

En primer lugar, trataremos la terminología. Cuando se trata de la gestión de incidentes, a menudo se escuchan dos abreviaturas, SOC y CSIRT, cuya importancia es importante comprender para evitar manipulaciones de marketing.
SOC (centro de operaciones de seguridad): una unidad dedicada a las tareas operativas de seguridad de la información. La mayoría de las veces, cuando se habla de las funciones de SOC, las personas quieren decir monitorear e identificar incidentes. Sin embargo, generalmente la responsabilidad del SOC incluye cualquier tarea relacionada con los procesos de seguridad de la información, incluida la respuesta y la eliminación de las consecuencias de incidentes, actividades metodológicas para mejorar la infraestructura de TI y aumentar el nivel de seguridad de la empresa. Al mismo tiempo, el SOC con frecuencia es una unidad de personal independiente, que incluye especialistas de varios perfiles.
CSIRT (equipo de respuesta a incidentes de seguridad cibernética): un grupo o equipo formado temporalmente o unidad responsable de responder a incidentes emergentes. CSIRT generalmente tiene una red troncal permanente, compuesta por profesionales de seguridad de la información, administradores de SZI y un grupo de forenses. Sin embargo, la composición final del equipo en cada caso está determinada por el vector de amenaza y puede complementarse con el servicio de TI, los propietarios de los sistemas comerciales e incluso la administración de la empresa con un servicio de relaciones públicas (para nivelar los antecedentes negativos en los medios).
A pesar del hecho de que en sus actividades CSIRT a menudo se guía por el estándar NIST, que incluye un ciclo completo de gestión de incidentes, actualmente el énfasis en el espacio de marketing se coloca con mayor frecuencia en las actividades de respuesta, negando esta función a SOC y contrastando estos dos términos.
¿Es el concepto de SOC más amplio en relación con CSIRT? En mi opinión, si. En sus actividades, el SOC no se limita a incidentes, puede confiar en datos de inteligencia cibernética, pronósticos y análisis del nivel de seguridad de la organización e incluir tareas de seguridad más amplias.
Pero volvamos al estándar NIST, como uno de los enfoques más populares que describen el procedimiento y las fases de la gestión de incidentes. El procedimiento general del estándar NIST SP 800-61 es el siguiente:
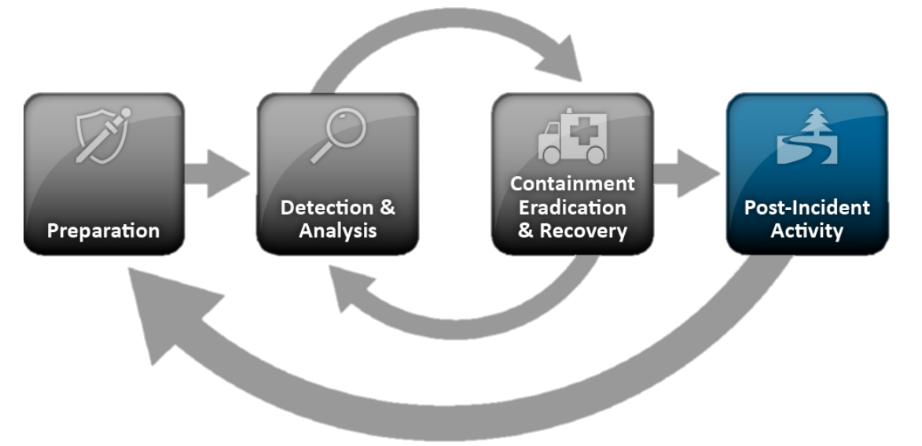
- Preparación:
- Crear la infraestructura técnica necesaria para trabajar con incidentes.
- Crear reglas de detección de incidentes
- Identificación y análisis de incidentes:
- Monitoreo e identificación
- Análisis de incidentes.
- Priorización
- Alerta
- Localización, neutralización y recuperación:
- Localización de incidentes
- Recolección, almacenamiento y documentación de señales de incidentes.
- Mitigación de desastres
- Recuperación posterior al incidente
- Actividad metódica:
- Resumen de incidentes
- Base de conocimiento Relleno + Inteligencia de amenazas
- Medidas organizativas y técnicas.
A pesar de que el estándar NIST está dedicado a la respuesta a incidentes, una parte importante de la respuesta está ocupada por la sección "Detección y análisis de incidentes", que en realidad describe las tareas clásicas de monitoreo y procesamiento de incidentes. ¿Por qué se les da tanta atención? Para responder la pregunta, echemos un vistazo más de cerca a cada uno de estos bloques.
Preparación
La tarea de identificar incidentes comienza con la creación y el "aterrizaje" de un modelo de amenaza y un modelo de intrusos sobre las reglas para identificar incidentes. Puede detectar incidentes analizando eventos de seguridad de la información (registros) de varias herramientas de protección de información, componentes de infraestructura de TI, sistemas de aplicaciones, elementos de sistemas tecnológicos (ACS) y otros recursos de información. Por supuesto, puede hacerlo manualmente, con scripts, informes, pero para la detección efectiva en tiempo real de incidentes de seguridad de la información, aún se necesitan soluciones especializadas.
Los sistemas SIEM vienen al rescate aquí, pero su operación no es menos una búsqueda que el análisis de registros "en bruto", y en cada etapa, desde conectar las fuentes hasta crear reglas de incidentes. Las dificultades están relacionadas con el hecho de que los eventos que provienen de diferentes fuentes deben tener una apariencia uniforme, y los parámetros clave de los eventos deben mapearse en los mismos campos de eventos en SIEM, independientemente de la clase / fabricante del sistema o hardware.
Las reglas para detectar incidentes, listas de indicadores de compromiso, tendencias de amenazas cibernéticas forman el llamado "contenido" de SIEM. Debe realizar las tareas de recopilar perfiles de red y de actividad del usuario, recopilar estadísticas sobre eventos de varios tipos e identificar incidentes típicos de seguridad de la información. La lógica para activar las reglas para detectar incidentes debe tener en cuenta la infraestructura particular y los procesos comerciales de una empresa en particular.
Como no hay una infraestructura estándar de la empresa y los procesos comerciales que tienen lugar en ella, tampoco puede haber contenido unificado del sistema SIEM. Por lo tanto, todos los cambios en la infraestructura de TI de la compañía deben reflejarse de manera oportuna tanto en la configuración y ajuste del equipo de seguridad como en SIEM. Si el sistema se configuró solo una vez, al comienzo de la prestación de servicios, o se actualiza una vez al año, esto reduce las posibilidades de detectar incidentes militares y filtrar con éxito falsos positivos varias veces.
Por lo tanto, configurar características de seguridad, conectar fuentes al sistema SIEM y adaptar el contenido de SIEM son tareas primordiales para responder a incidentes, una base sin la cual es imposible seguir adelante. Después de todo, si el incidente no se registró de manera oportuna y no pasó por las fases de identificación y análisis, ya no estamos hablando de ninguna respuesta, solo podemos trabajar con sus consecuencias.
Detección y análisis de incidencias.
El servicio de monitoreo debe trabajar con incidentes en modo de tiempo real durante todo el día y los siete días de la semana. Esta regla, como los principios básicos de seguridad, está escrita en sangre: aproximadamente la mitad de los ataques cibernéticos críticos comienzan por la noche, muy a menudo el viernes (este fue el caso, por ejemplo, con el virus del ransomware WannaCry). Si no toma medidas de protección dentro de la primera hora, ya puede ser cursi demasiado tarde. En este caso, simplemente transfiera todos los incidentes registrados al siguiente paso descrito en el estándar NIST, es decir en la etapa de localización, no es práctico, y he aquí por qué:
- Obtener información adicional sobre lo que está sucediendo o filtrar un falso positivo es más fácil y más correcto en la etapa de análisis, en lugar de localizar el incidente. Esto le permite minimizar la cantidad de incidentes referidos a las siguientes etapas del proceso de Respuesta a incidentes, donde los especialistas de nivel superior deben participar en su consideración: gerentes de gestión de incidentes, equipos de respuesta, sistemas de TI y administradores de SIS. Es más lógico construir el proceso de tal manera que no se escalen todos los detalles, incluidos los falsos positivos, al nivel CISO.
- La respuesta y "supresión" de un incidente siempre conlleva riesgos comerciales. Responder a un incidente puede incluir trabajar para bloquear el acceso sospechoso, aislar al host y escalar al nivel de liderazgo. En el caso de un falso positivo, cada uno de estos pasos afectará directamente la disponibilidad de elementos de infraestructura y obligará al equipo de gestión de incidentes a "extinguir" su propia escalada durante mucho tiempo con informes y memorandos de varias páginas.
Por lo general, la primera línea de ingenieros está trabajando en el servicio de monitoreo las 24 horas, los 7 días de la semana, quienes están directamente involucrados en el procesamiento de posibles incidentes registrados por el sistema SIEM. El número de incidentes de este tipo puede alcanzar varios miles por día (de nuevo, ¿tanto más en la etapa de localización?), Pero, afortunadamente, la mayoría de ellos se ajustan a patrones bien conocidos. Por lo tanto, para aumentar la velocidad de su procesamiento, puede usar secuencias de comandos e instrucciones que describen paso a paso las acciones necesarias.
Esta es una práctica comprobada que permite reducir la carga en la línea 2 y la línea 3 de los analistas: se transferirán solo aquellos incidentes que no encajen en ninguno de los scripts disponibles. De lo contrario, la escalada de incidentes en la segunda y tercera línea de monitoreo alcanzará el 80%, o en la primera línea será necesario contar con especialistas caros con alta experiencia y un largo período de capacitación.
Por lo tanto, además de los empleados de primera línea, se necesitan analistas y arquitectos que crearán guiones e instrucciones, capacitarán a especialistas de primera línea, crearán contenido en SIEM, conectarán fuentes, mantendrán operatividad e integrarán SIEM con los sistemas de clase IRP, CMDB y más.
Una tarea de monitoreo importante es la búsqueda, el procesamiento y la implementación de varias bases de reputación, informes APT, boletines y suscripciones en el sistema SIEM, que finalmente se convierten en indicadores de compromiso (IoC). Son ellos los que hacen posible identificar los ataques encubiertos de los atacantes en la infraestructura, el malware que los proveedores de antivirus no detectan y mucho más. Sin embargo, al igual que la conexión de orígenes de eventos al sistema SIEM, agregar toda esta información sobre amenazas primero requiere resolver una serie de tareas:
- Automatización de agregar indicadores
- Evaluación de su aplicabilidad y relevancia.
- Priorización y contabilidad de la obsolescencia de la información.
- Y lo más importante: una comprensión de los medios de protección para obtener información para verificar estos indicadores. Si todo es bastante simple con los de red, verificando los firewalls y proxies, entonces con los host es más difícil: con qué comparar los hashes, cómo en todos los hosts verificar los procesos en ejecución, las ramas de registro y los archivos escritos en el disco duro.
Arriba, mencioné solo una parte de los aspectos del proceso de monitoreo y análisis de incidentes que cualquier empresa que construya un proceso de respuesta a incidentes tendrá que enfrentar. En mi opinión, esta es la tarea más importante en todo el proceso, pero sigamos y avancemos al bloque de trabajo con incidentes de seguridad de la información ya registrados y analizados.
Localización, neutralización y recuperación.
Este bloque, según algunos expertos en seguridad de la información, es el determinante en la diferencia entre el equipo de monitoreo y el equipo de respuesta a incidentes. Echemos un vistazo más de cerca a lo que NIST pone en él.
Localización de incidentes
Según el NIST, la tarea principal en el proceso de localización de incidentes es desarrollar una estrategia, es decir, determinar medidas para prevenir la propagación del incidente dentro de la infraestructura de la compañía. El complejo de estas medidas puede incluir varias acciones: aislar los hosts involucrados en el incidente a nivel de red, cambiar los modos operativos de las herramientas de protección de la información e incluso detener los procesos comerciales de la empresa para minimizar el daño del incidente. De hecho, la estrategia es un libro de jugadas, que consiste en una matriz de acciones dependiendo del tipo de incidente.
La implementación de estas acciones puede estar relacionada con el área de responsabilidad del cambio del soporte técnico de TI, los propietarios y administradores de sistemas (incluidos los sistemas comerciales), una empresa contratista externa y el servicio de seguridad de la información. Las acciones se pueden realizar manualmente, por componentes EDR, e incluso scripts auto-escritos utilizados por comando.
Dado que las decisiones tomadas en esta etapa pueden afectar directamente los procesos comerciales de la compañía, la decisión de aplicar una estrategia específica en la gran mayoría de los casos sigue siendo tarea de un gerente interno de seguridad de la información (que a menudo involucra a propietarios de sistemas comerciales), y
esta tarea no puede ser subcontratada empresa El papel del proveedor de servicios de seguridad de la información en la localización del incidente se reduce a la aplicación operativa de la estrategia elegida por el cliente.
Recolección, almacenamiento y documentación de señales de incidentes.
Una vez que se han tomado medidas operativas para localizar el incidente, se debe llevar a cabo una investigación exhaustiva, reuniendo toda la información para evaluar el alcance. Esta tarea se divide en dos subtareas:
- Transferir información adicional al equipo de monitoreo, conectando fuentes adicionales de eventos de seguridad de la información involucrados en el incidente con el sistema de recopilación y análisis de eventos.
- Conectando al equipo forense para analizar imágenes del disco duro, analizar volcados de memoria, muestras de malware y herramientas utilizadas por los ciberdelincuentes en este incidente.
También se debe designar a una persona para coordinar las actividades de todas las unidades en el marco de la investigación del incidente. Este especialista debe tener la autoridad y los contactos de todo el personal involucrado en la investigación. ¿Puede un empleado contratista desempeñar este papel? Más probablemente no que sí. Es más lógico confiar este rol a un especialista o al jefe del servicio de seguridad de la información del cliente.
Mitigación de desastres
Habiendo recibido una imagen completa del incidente de varios departamentos, el coordinador desarrolla medidas para eliminar las consecuencias del incidente. Este procedimiento puede incluir:
- Eliminación de indicadores identificados de compromiso y rastros de la presencia de malware / intrusos.
- "Recargar" hosts infectados y cambiar las contraseñas de los usuarios.
- Instalar las últimas actualizaciones y desarrollar medidas compensatorias para eliminar las vulnerabilidades críticas utilizadas en el ataque.
- Cambiar los perfiles de seguridad de SIG.
- Control sobre la integridad de las acciones realizadas por las unidades involucradas y la ausencia de compromiso de los sistemas por parte de intrusos.
Al desarrollar medidas, recomendamos que el coordinador consulte con las unidades especializadas responsables de sistemas específicos, los administradores del sistema de seguridad de la información, el grupo forense y el servicio de monitoreo de incidentes IS. Pero, nuevamente, la decisión final sobre la aplicación de ciertas medidas la toma el coordinador del grupo de análisis de incidentes.
Recuperación posterior al incidente
En esta sección, NIST en realidad habla sobre las tareas del departamento de TI y el servicio de operaciones de sistemas comerciales. Todo el trabajo se reduce a restaurar y verificar el rendimiento de los sistemas de TI y los procesos comerciales de la empresa. No tiene sentido detenerse en este punto, ya que la mayoría de las empresas se enfrentan a la solución de estos problemas, si no como resultado de incidentes de seguridad de la información, al menos después de fallas que ocurren periódicamente, incluso en las instalaciones de sistemas más estables y tolerantes a fallas.
Actividad metódica
La cuarta sección de la metodología de Respuesta a Incidentes está dedicada a trabajar en errores y mejorar las tecnologías de seguridad de la compañía.
Para la preparación de un informe de incidentes, llenando la base de conocimiento y TI, por regla general, el equipo forense es responsable junto con el servicio de monitoreo. Si no se desarrolló una estrategia de localización en el momento de este incidente, su escritura se incluye en este bloque.
Bueno, es obvio que un punto muy importante para trabajar en los errores es desarrollar una estrategia para prevenir incidentes similares en el futuro:
- Cambiar la arquitectura de la infraestructura de TI y los SIG existentes.
- La introducción de nuevas herramientas de seguridad de la información.
- Introducción del proceso de gestión de parches y monitoreo de incidentes de seguridad de la información (si está ausente).
- Corrección de procesos de negocio de la empresa.
- Personal adicional en el departamento de seguridad de la información.
- Cambio de autoridad de los empleados de seguridad de la información.
Rol del proveedor de servicios
Por lo tanto, la posible participación del proveedor de servicios en varias etapas de respuesta a incidentes puede representarse en forma de matriz:
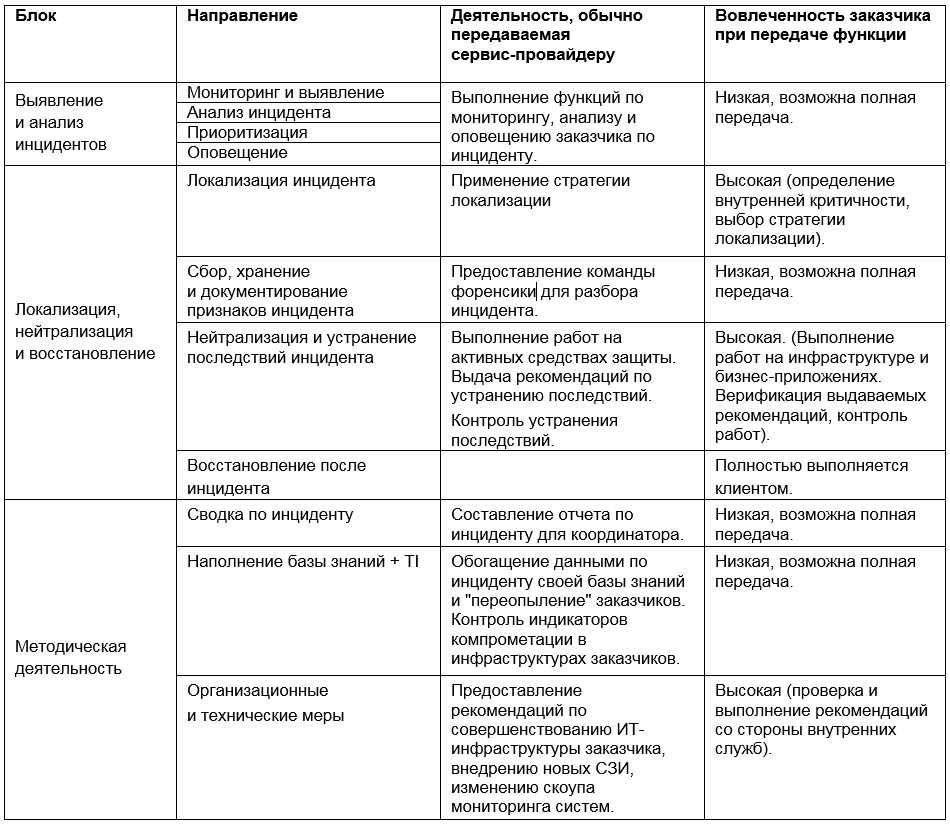
La elección de herramientas y enfoques para la gestión de incidentes es una de las tareas más difíciles de la seguridad de la información. La tentación de confiar en las promesas de un proveedor de servicios y darle todas las funciones puede ser grande, pero aconsejamos una evaluación sólida de la situación y un equilibrio entre el uso de recursos internos y externos, en aras de la eficiencia económica y de los procesos.