
¿Estás listo para nuevos desafíos? ¡Invitamos a todos los aficionados y profesionales al campeonato para el diseño y administración de servicios altamente cargados
HighLoad Cup # 2 !
La competencia comenzó en el último año. Entonces supimos que la HighLoad Cup es exactamente el campeonato que faltaba en varios proyectos de Mail.Ru Group. A la primera competición piloto asistieron 449 personas. Hubo mucho código y mucho sudor tanto de los organizadores como de los participantes (8789 soluciones diferentes). Hubo matices en la implementación técnica, pero lo más importante, ¡a todos les gustó! Los organizadores pasaron muchas noches en el centro de datos, varios días libres en la oficina. Listo para eso otra vez! Al final del artículo encontrará materiales útiles de nosotros y de los participantes que lo ayudarán a comprender la mecánica y encontrar algunas soluciones de mejores prácticas.
Esta vez intentaron preparar para usted un negocio más difícil. Además, hemos ampliado la audiencia, ahora los usuarios de habla inglesa pueden participar en la competencia. Únete a la comunidad de habla rusa en
Telegram . Allí obtendrás muchas ideas sobre la competencia :)
¡Bienvenidos a bordo!
La mecanica
En comparación con el año pasado, nada cambió conceptualmente en la competencia.
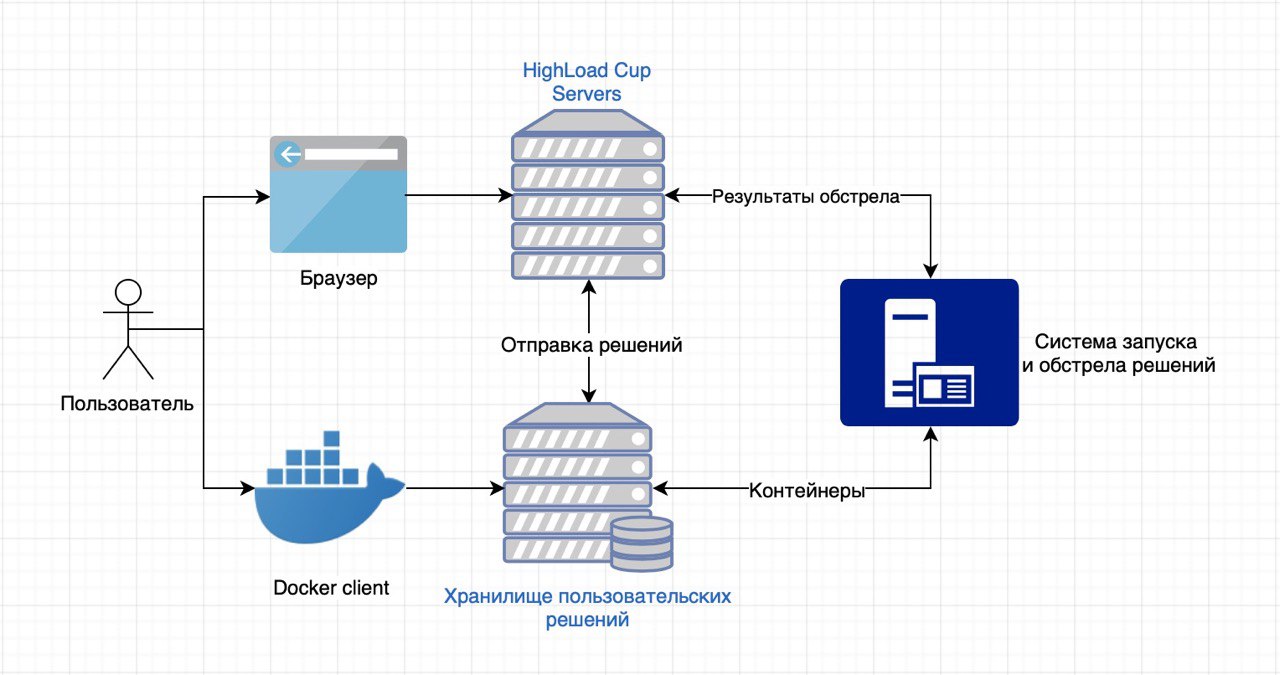
Los participantes tienen la tarea de crear un pequeño servicio web que trabaje con datos de una determinada estructura e implemente una API para estos datos. Un contenedor (Docker) con el servicio implementado se carga en nuestros servidores, donde lo lanzamos y comenzamos a bombardearlo con solicitudes HTTP.
Las soluciones se nos envían utilizando un cliente Docker instalado localmente en un repositorio especial (cada uno tiene el suyo). Luego, el servicio enviado a nosotros es verificado automáticamente por el sistema CodeHub-CodeRunner desarrollado por el personal del Laboratorio Mail.Ru Group Technopark.
Luego comenzamos a "martillar" el contenedor en una máquina de prueba con un procesador Intel Core i7. A la solución se le asignarán 4 núcleos de 2,4 GHz, 2 GB de RAM y 10 GB de espacio en el disco duro. En resumen, se lanza un "tanque" con el motor fantasma, que dispara a múltiples corrientes con un perfil de carga de crecimiento lineal. Antes de que comience el bombardeo, la solución del usuario tiene varios minutos (la cantidad exacta depende de la tarea) para procesar los datos del archivo JSON recibido. El trabajo correcto con estos datos es una condición necesaria para la victoria. Bombardeo solo dos, corto y largo.
En base a los resultados de tales ataques, calculamos el número de respuestas correctas e incorrectas, RPS y velocidad de respuesta, y formamos una tabla de clasificación para una determinada métrica. El autor del servicio más rápido y tolerante a fallas será el ganador.
Utilice cualquier tecnología web que pueda encontrar o crear. Elija su propio lenguaje de programación y marco. Puede ser C ++, Java + Tomcat, Python + Django, Ruby + RoR, GoLang, JavaScript + NodeJs, Haskell, al menos Assembler o algo más, a su discreción. Para almacenamiento de datos: MySQL, PostgreSQL, Redis, MongoDB, cachés. Completa libertad!
Como resultado del bombardeo, se obtienen registros y métricas, que luego se mostrarán a los participantes en forma de gráficos en la página de decisiones. Seguimiento por separado:
- métricas básicas;
- respuesta correcta
- velocidad de respuesta a una solicitud;
- Número de respuestas por segundo.
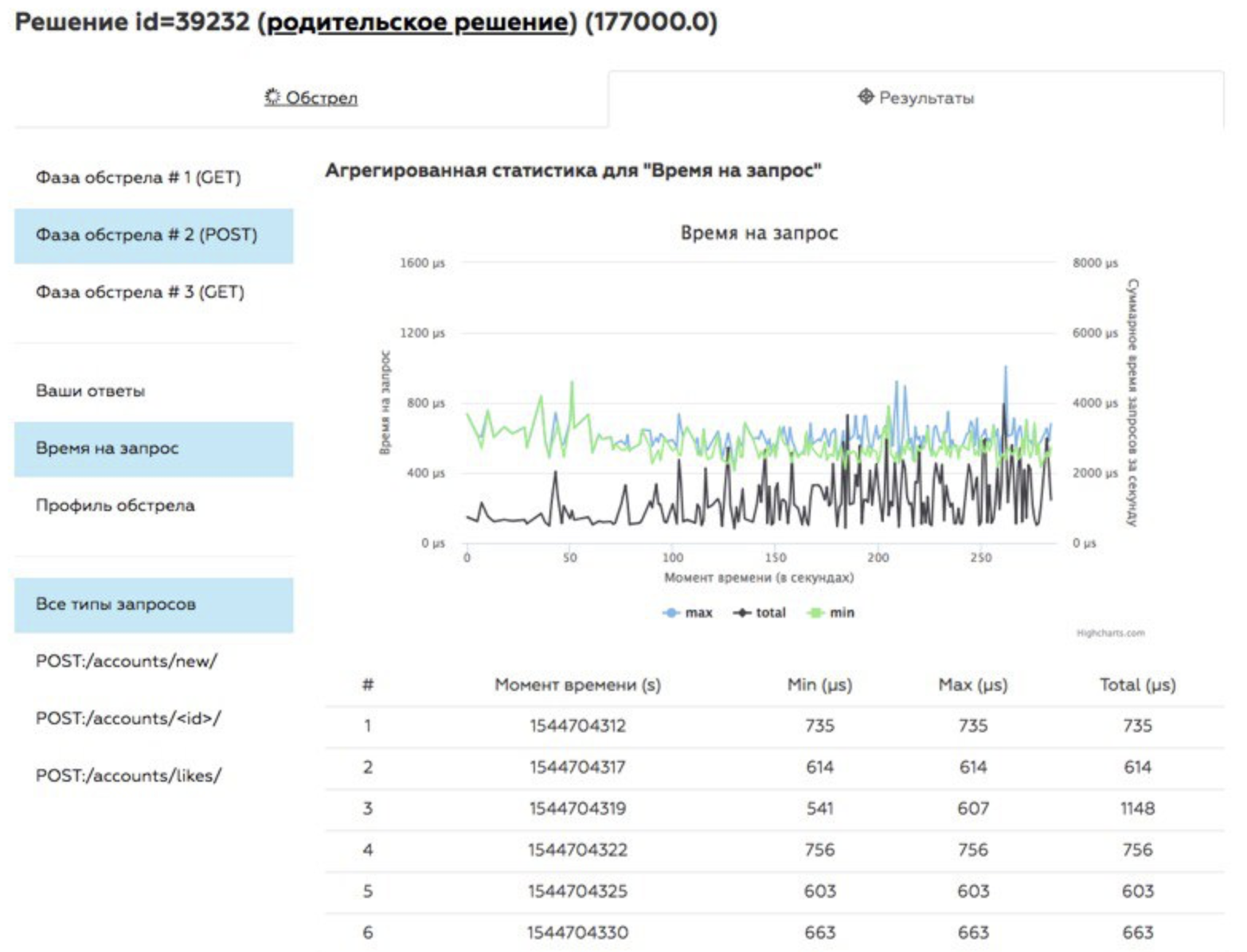
La calificación de la solución se calcula de la siguiente manera: tomamos el tiempo de todas las respuestas correctas que la API logró dar durante el bombardeo, agregamos un tiempo de penalización por cada respuesta o solicitud incorrecta para la que no pudimos recibir una respuesta (el tiempo de penalización siempre es igual al tiempo de espera total de la solicitud). El participante, cuyo tiempo total es menor que otros, es más alto en la tabla de clasificación y tiene la oportunidad de convertirse en el ganador del campeonato.
Desafío
Nuestro equipo pensó durante mucho tiempo qué tarea asignar este año. Querían algo que igualara las posibilidades de la mayoría (para que algunas bicicletas hechas por ellos mismos en C / C ++ no ganaran).
La redacción es la siguiente:
En una realidad alternativa, la humanidad decidió crear y lanzar un sistema de búsqueda global para la "segunda mitad". Está diseñado para reducir la cantidad de personas solteras en el mundo y ayudar a crear familias fuertes.
Tanto en los datos de prueba como de “combate” para varios bombardeos, hay entradas sobre una entidad: Cuenta. Describe toda la información conocida sobre el usuario: su nombre, contactos, intereses, simpatía revelada por otros usuarios. La precisión de los datos proporcionados está garantizada de acuerdo con los tipos y limitaciones que se indican a continuación. Todos los datos fueron generados e inventados por nosotros de acuerdo con ciertas leyes.
Los siguientes datos personales están contenidos en un registro de Cuenta:
- id : identificador externo único del usuario. El sistema de prueba lo instala y luego se utiliza para verificar las respuestas del servidor. El tipo es un entero de 32 bits.
- correo electrónico : la dirección de correo electrónico del usuario. Tipo: cadena Unicode de hasta 100 caracteres de longitud. Unicidad garantizada.
- fname y sname : nombre y apellido, respectivamente. Tipo: cadenas unicode de hasta 50 caracteres de longitud. Los campos son opcionales y pueden no estar presentes en un registro particular.
- teléfono : número de teléfono móvil. El tipo es una cadena unicode de hasta 16 caracteres de longitud. El campo es opcional, pero la unicidad está garantizada para los valores especificados. Se llena muy raramente.
- el sexo es una cadena unicode, "m" significa hombre y "f" significa mujer.
- nacimiento - fecha de nacimiento, registrada como el número de segundos desde el comienzo de la era UNIX en UTC (en otras palabras, esta es una marca de tiempo). Limitado desde abajo 01/01/1950, desde arriba 01/01/2005.
- país - país de residencia. El tipo es una cadena unicode de hasta 50 caracteres de longitud. El campo es opcional.
- ciudad - ciudad de residencia. El tipo es una cadena unicode de hasta 50 caracteres de longitud. El campo es opcional y rara vez se especifica. Cada ciudad está ubicada en un país en particular.
Además, en un registro de cuenta hay campos específicos para el motor de búsqueda para la segunda mitad:
- unido - fecha de registro en el sistema. Tipo: marca de tiempo con restricciones: desde abajo 01.01.2011, desde arriba 01.01.2018.
- estado : el estado actual del usuario en el sistema. Escriba: una línea de las siguientes opciones: "libre", "ocupado", "todo es complicado". No prestes atención a finales extraños :)
- intereses : intereses del usuario en la vida cotidiana. Tipo: una matriz de cadenas unicode, posiblemente vacías. Las líneas no superan los 100 caracteres de longitud.
- premium : el comienzo y el final del período premium en el sistema (cuando los usuarios realmente querían encontrar un "alma gemela" y pagaban por el servicio). En JSON, este campo está representado por un objeto anidado con los campos de inicio y fin, donde las marcas de tiempo con un límite inferior se registran el 01/01/2018.
- Me gusta : un conjunto de Me gusta conocidos del usuario, posiblemente vacío. Todas las simpatías son diferentes y cada una representa un objeto de los siguientes campos:
- id : el identificador de otra cuenta que le gusta al usuario. La cuenta siempre se puede encontrar en los datos de origen por id. Tenga en cuenta que en los datos puede haber varios me gusta con la misma identificación.
- ts : tiempo, es decir, marca de tiempo, cuando se registró la simpatía en el sistema.
Necesita implementar la API.
- Obtener una lista de usuarios: / accounts / filter /
Este método API está planeado para usarse para buscar usuarios en campos previamente conocidos o deseados. Por ejemplo, alguien quería ver a todas las personas de cierta edad y género viviendo en una ciudad en particular. - Agrupación de usuarios: / cuentas / grupo /
Este método API está planeado para usarse para crear informes sobre el funcionamiento del sistema. Los campos utilizados para la agrupación se pasan en las teclas de parámetros GET separadas por comas. No son tan numerosos como en la solicitud de filtrado del usuario. Solo hay cinco campos para agrupar: sexo, estado, intereses, país, ciudad. - Recomendaciones de compatibilidad: / cuentas / id / recomendar /
Esta consulta se utiliza para buscar la "segunda mitad" en los datos de usuario especificados. La solicitud pasa la identificación del usuario para el cual se busca a los que mejor se adaptan por estado, edad e intereses. La decisión debe verificar la compatibilidad solo con el sexo opuesto (no estamos en contra de las minorías sexuales y condenar la discriminación, simplemente sucedió :)). Si el país o la ciudad con las teclas de país y ciudad, respectivamente, se transmiten en la solicitud GET, entonces solo debe buscar entre aquellos que viven en el lugar especificado. - Me gusta similar: / cuentas / id / sugerencia /
Este tipo de consulta es similar a la anterior en que también se trata de la búsqueda de "almas gemelas". También se envía la identificación del usuario para el que estamos buscando un alma gemela, se utiliza el parámetro límite GET. Diferencias en la implementación: buscamos personas como del mismo género con "me gusta" similares y ofrecemos a quienes recientemente les gustaron. Si la solicitud recibe el parámetro GET de país o ciudad, entonces debe buscar "simpatías similares" solo en una ubicación determinada.
Decir todo en un artículo no es posible. Las reglas detalladas se publicarán el día del lanzamiento (hoy) en el sitio web del campeonato y en el repositorio de
GitHub , pero ahora ya sabe lo que le espera.
Horario
Sí, sabemos que las vacaciones (con las próximas), por lo que el campeonato será muy largo :)
- Pruebas beta (los resultados no se tienen en cuenta): comienzan el 13 de diciembre a las 19:00 y finalizan el 21 de diciembre a las 19:00.
- Ronda clasificatoria: del 21 de diciembre de 19:00 a 31 de enero de 19:00.
- Ronda final: hasta el 5 de febrero.
Durante la prueba beta, las reglas y condiciones de la tarea pueden cambiar (en presencia de errores y por otras razones).
Ronda clasificatoria: las reglas no cambian.
La ronda final es completamente automática, pero antes de ella, los finalistas (N usuarios que han pasado los resultados de la ronda de clasificación y al menos 50 personas) eligen una solución que se disparará en varias oleadas. El resultado está formado por el mejor resultado para todas las ondas.
Presenta
El primer lugar es el nuevo MacBook Air.
Segundo y tercer lugar: iPad de Apple.
Cuarto, quinto y sexto lugar: Samsung Gear S3.
El participante tiene derecho a solicitar otro obsequio de valor equivalente a cambio. Todos los participantes que se clasificaron para la final recibirán camisetas de marca de nuestro campeonato.
Comunidad
Si va a nuestra sala de chat de
Telegram , es poco probable que lo deje. ¡Te esperamos y buena suerte!
Agradecimientos
Este artículo no aborda problemas de actualización del sistema. Trabajamos mucho para eliminar los errores de infraestructura, revisamos todos los
problemas de los participantes en GitHub, ya implementamos algo y lo pusimos en la lista TODO para el próximo año. Quiero expresar mi
profunda gratitud a Maxim
@ xammi- Kislenko, Ilya
@liofz Lebedev, Eugene
@gunicorn Ivanov, Irina
@aithelle Lukyanova, Vasily
@vasidmi Dmitriev y todo el equipo que participó en la competencia, incluida toda la comunidad del campeonato. Gracias
Literatura útil sobre los resultados de la HighLoad Cup 2017