Desafío
Una de las grandes tareas de la aplicación para almacenar y analizar compras es buscar productos idénticos o muy cercanos en la base de datos, que contiene nombres de productos variados e incomprensibles obtenidos de los recibos. Hay dos tipos de solicitud de entrada:
- Un nombre específico con abreviaturas, que solo pueden entender los cajeros de un supermercado local o los ávidos compradores.
- Una consulta en lenguaje natural ingresada por el usuario en la cadena de búsqueda.
Las solicitudes del primer tipo, por regla general, provienen de los productos en el cheque en sí, cuando el usuario necesita encontrar productos más baratos. Nuestra tarea es seleccionar el producto análogo más similar del cheque en otras tiendas cercanas. Es importante elegir la marca de producto más adecuada y, si es posible, el volumen.
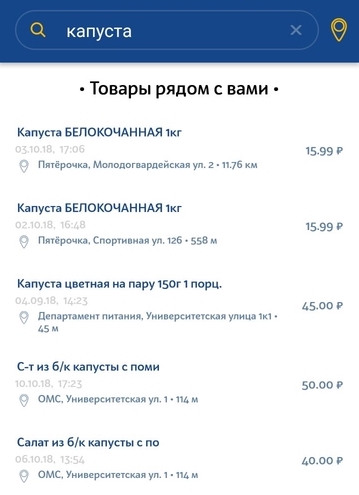
El segundo tipo de solicitud es una simple solicitud del usuario para buscar un producto específico en la tienda más cercana. La solicitud puede ser una descripción muy general y no única del producto. Puede haber ligeras desviaciones de la solicitud. Por ejemplo, si un usuario busca leche 3.2% y en nuestra base de datos solo 2.5% leche, entonces todavía queremos mostrar al menos este resultado.
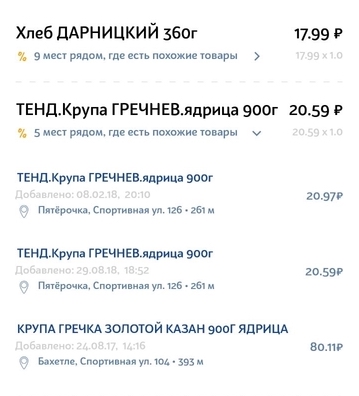
Conjunto de datos de características: problemas a resolver
La información en el recibo del producto está lejos de ser ideal. Tiene muchas abreviaturas no siempre claras, errores gramaticales, errores tipográficos, varias traducciones, letras latinas en el medio del alfabeto cirílico y juegos de caracteres que tienen sentido solo para la organización interna de una tienda en particular.
Por ejemplo, un puré de manzana y plátano con queso cottage se puede escribir fácilmente en el cheque de la siguiente manera:

Acerca de la tecnología
Elasticsearch es una tecnología bastante popular y asequible para implementar búsquedas. Este es un motor de búsqueda JSON REST API que usa Lucene y está escrito en Java. Las principales ventajas de Elastic son velocidad, escalabilidad y tolerancia a fallas. Se utilizan motores similares para búsquedas complejas en la base de datos de documentos. Por ejemplo, una búsqueda que tiene en cuenta la morfología del idioma o una búsqueda por geocoordenadas.
Instrucciones para la experimentación y la mejora.
Para comprender cómo puede mejorar su búsqueda, debe analizar el sistema de búsqueda en sus componentes personalizados. Para nuestro caso, la estructura del sistema se ve así.
- La cadena de entrada para la búsqueda pasa a través del analizador, que de cierta manera divide la cadena en tokens: unidades de búsqueda que buscan entre los datos que también se almacenan como tokens.
- Luego hay una búsqueda directa de estos tokens para cada documento en la base de datos existente. Después de encontrar un token en un documento determinado (que también se presenta en la base de datos como un conjunto de tokens), su relevancia se calcula de acuerdo con el modelo de similitud seleccionado (lo llamaremos el modelo de relevancia). Este puede ser un simple TF / IDF (Término Frecuencia - Frecuencia de documento inversa), o puede ser otros modelos más complejos o específicos.
- En la siguiente etapa, el número de puntos anotados por cada ficha individual se agrega de cierta manera. Los parámetros de agregación se establecen mediante la semántica de consulta. Un ejemplo de tales agregaciones pueden ser pesos adicionales para ciertos tokens (valor agregado), condiciones para la presencia obligatoria de un token, etc. El resultado de esta etapa es Score: la evaluación final de la relevancia de un documento particular de la base de datos en relación con la solicitud inicial.

Se pueden distinguir tres componentes configurables por separado del dispositivo de búsqueda, en cada uno de los cuales puede resaltar sus propias formas y métodos de mejora.
- Analizadores
- Modelo de similitud
- Mejoras en el tiempo de consulta
A continuación, consideraremos cada componente individualmente y analizaremos configuraciones de parámetros específicos que ayudaron a mejorar la búsqueda en el caso de los nombres de productos.
Mejoras en el tiempo de consulta
Para comprender qué podemos mejorar en la solicitud, damos un ejemplo de la solicitud inicial.
{ "query": { "multi_match": { "query": " 105", "type": "most_fields", "fields": ["name"], "minimum_should_match": "70%" } }, “size”: 100, “min_score”: 15 }
Utilizamos el tipo de consulta most_fields, ya que prevemos la necesidad de una combinación de varios analizadores para el campo "nombre del producto". Este tipo de consulta le permite combinar resultados de búsqueda para diferentes atributos del objeto que contiene el mismo texto, analizados de diferentes maneras. Una alternativa a este enfoque es utilizar las consultas best_fields o cross_fields, pero no son adecuadas para nuestro caso, ya que la búsqueda se calcula entre los diversos atributos del objeto (por ejemplo, nombre y descripción). Nos enfrentamos a la tarea de tener en cuenta varios aspectos de un atributo: el nombre del producto.
Lo que se puede configurar:
- Combinación ponderada de diferentes analizadores.
Inicialmente, todos los elementos de búsqueda tienen el mismo peso y, por lo tanto, la misma importancia. Esto se puede cambiar agregando el parámetro 'boost', que toma valores numéricos. Si el parámetro es mayor que 1, el elemento de búsqueda tendrá un mayor impacto en los resultados, respectivamente, menor que 1 - menos. - Separación de analizadores en 'debería' y 'debe'.
Es decir, ciertos analizadores deben coincidir, y algunos son opcionales, es decir, insuficientes. En nuestro caso, el analizador de números puede ser un ejemplo de los beneficios de tal separación. Si solo el número coincide en el nombre del producto en la solicitud y el nombre del producto en la base de datos, entonces esta no es una condición suficiente para su equivalencia. No queremos ver tales productos como resultado. Al mismo tiempo, si la solicitud es "crema 10%", entonces queremos que toda crema con 10% de grasa tenga una gran ventaja sobre la crema con 20% de grasa. - El parámetro minimum_should_match. ¿Cuántos tokens deben coincidir necesariamente en la solicitud y el documento de la base de datos? Este parámetro funciona junto con el tipo de nuestra solicitud (most_fields) y verifica el número mínimo de tokens coincidentes para cada uno de los campos (en nuestro caso, para cada analizador).
- Parámetro min_score. Umbral de documentos de cribado con puntos insuficientes. El problema es que no se conoce la velocidad máxima. El puntaje resultante depende de una solicitud específica y de una base de datos específica de documentos. A veces puede ser 150, y a veces 2, pero ambos valores significarán que el objeto de la base de datos es relevante para la solicitud. No podemos comparar las puntuaciones de los resultados de diferentes consultas.
- Constante
Después de un monitoreo suficiente de los valores finales de la velocidad para diferentes consultas, puede identificar un borde aproximado, después del cual para la mayoría de las consultas los resultados se vuelven inapropiados. Esta es la decisión más fácil, pero también la más estúpida, que conduce a una búsqueda de baja calidad. - Intente analizar los puntajes obtenidos para una solicitud específica después de realizar una búsqueda con mínimo o cero puntaje mínimo.
La idea es que después de un cierto momento, puede observar un salto brusco en la dirección de la disminución de la velocidad. Solo queda determinar este salto para detenerse a tiempo. Tal enfoque funcionaría bien en consultas similares:
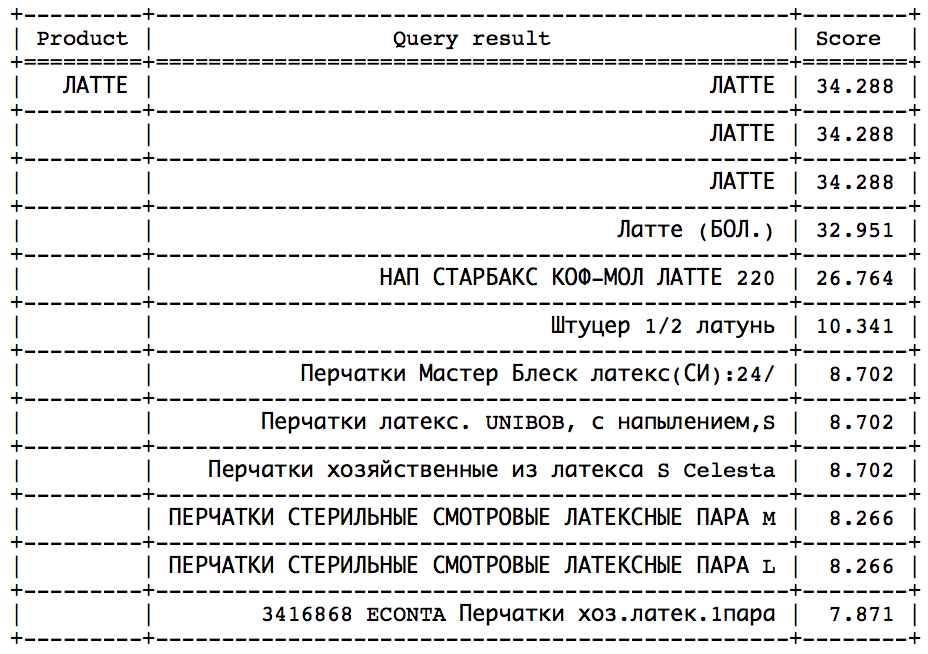
El salto se puede encontrar por métodos estadísticos. Pero, desafortunadamente, no en todas las solicitudes, este salto está presente y es fácilmente identificable. - Calcule la velocidad ideal y establezca min_score como una cierta fracción del ideal, que se puede hacer de dos maneras:
- A partir de la descripción detallada de los cálculos proporcionados por el propio Elastic al establecer la explicación: parámetro verdadero. Esta es una tarea difícil, que requiere una comprensión profunda de la arquitectura de consulta y los algoritmos computacionales utilizados por Elastic.
- Por un pequeño truco. Recibimos una solicitud, agregamos un nuevo producto a nuestra base de datos con el mismo nombre, hacemos una búsqueda y obtenemos la máxima velocidad. Como habrá una coincidencia del 100% en el nombre, el valor resultante será ideal. Es este enfoque el que usamos en nuestro sistema, ya que las preocupaciones sobre el alto costo de esta operación con respecto al tiempo no han sido confirmadas.
- Cambie el algoritmo de puntuación, que es responsable del valor de relevancia final. Esto puede estar tomando en cuenta la distancia a la tienda (dar más puntos a los productos que están más cerca), los precios de los productos (dar más puntos a los productos con el precio más probable), etc.
Analizadores
El analizador analiza la cadena de entrada en tres etapas y genera tokens en las unidades de búsqueda de salida:

Primero, los cambios ocurren en el nivel de caracteres de la cadena. Esto puede ser reemplazar, eliminar o agregar caracteres a una cadena. Luego entra en juego un tokenizer, que está diseñado para dividir la cadena en tokens. El tokenizer estándar divide la cadena en tokens de acuerdo con los signos de puntuación. En el último paso, los tokens recibidos se filtran y procesan.
Considere qué variaciones de los pasos se han vuelto útiles en nuestro caso.
Filtros de carbón
- Según los detalles del idioma ruso, sería útil procesar caracteres como th y e y reemplazarlos con y y e, respectivamente.
- Realizar transliteración: la transferencia de caracteres de una escritura por caracteres de otra escritura. En nuestro caso, este es el procesamiento de nombres escritos en latín o mezclados con ambos alfabetos. La transliteración se puede implementar usando el complemento ( ICU Analysis Plugin ) como filtro de token (es decir, no procesa la cadena original, sino los tokens finales). Decidimos escribir nuestra transliteración, ya que no estábamos muy contentos con el algoritmo en el complemento. La idea es reemplazar primero las ocurrencias del conjunto de cuatro caracteres (por ejemplo, “SHCH => u”), luego las ocurrencias de tres caracteres, etc. El orden en el que se usan los filtros de símbolos es importante porque el resultado dependerá del orden.
- Reemplazar Latin c, rodeado de cirílico, con ruso p. La necesidad de esto se identificó después de analizar los nombres en la base de datos: muchos nombres en cirílico incluían el latín c, que significa cirílico c. Cuando como si el nombre estuviera completamente en latín, el latín C significa cirílico k o c. Por lo tanto, antes de la transliteración, es necesario reemplazar el carácter c.
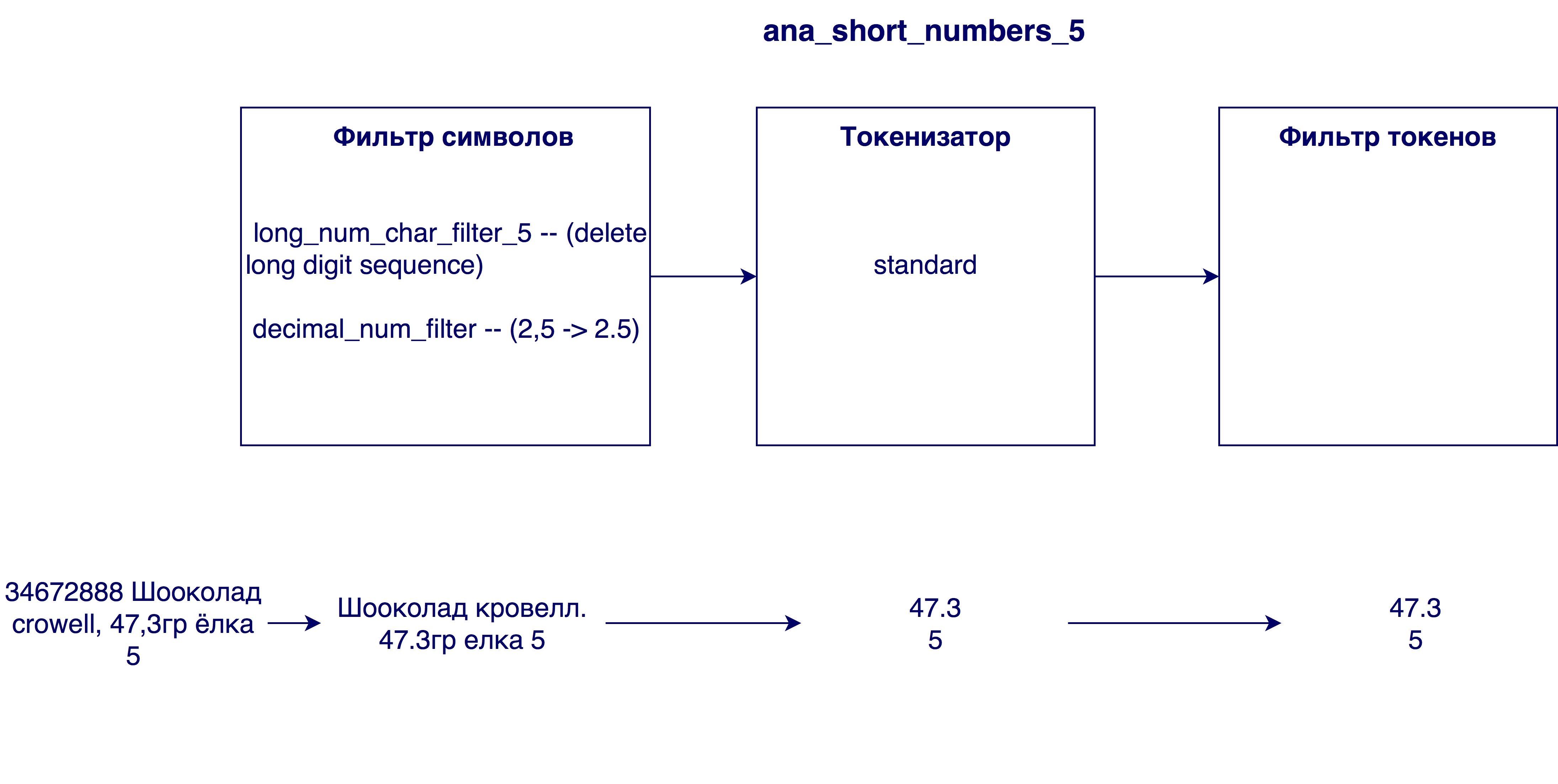
- Eliminar números demasiado grandes de los nombres. A veces, en los nombres de los productos hay un número de identificación interno (por ejemplo, 3387522 K.Ts. Maslo podsoln.raf. 0.9l), que no tiene ningún significado en el caso general.
- Reemplazar comas con puntos. ¿Por qué se necesita esto? Para que los números, por ejemplo, el contenido de grasa de la leche 3.2 y 3.2, sean equivalentes
Tokenizer
- Tokenizador estándar: separa las líneas según el espacio y los signos de puntuación (p. Ej., "Twix extra 2" -> "twix", "extra", "2")
- Tokenizer EdgeNGram: divide cada palabra en tokens de una longitud determinada (generalmente un rango de números), comenzando con el primer carácter (por ejemplo, para N = [3, 6]: "twix extra 2" -> "twee", "tweak", "Twix", "ex", "ext", "ext", "extra")
- Tokenizer para números: selecciona solo números de una cadena buscando una expresión regular (por ejemplo, "twix extra 2 4.5" -> "2", "4.5")
Filtro de fichas
- Filtro en minúscula
- Filtro de tartamudeo: realiza un algoritmo de tartamudeo para cada token. La derivación es determinar la forma inicial de una palabra (por ejemplo, "arroz" -> "arroz")
- Análisis fonético. Es necesario para minimizar la influencia de los errores tipográficos y las diferentes formas de escribir la misma palabra en los resultados de búsqueda. La tabla muestra los diversos algoritmos disponibles para el análisis fonético y el resultado de su trabajo en casos problemáticos. En el primer caso (Champú / champán / champiñón / champiñón) el éxito está determinado por la generación de diferentes codificaciones, en el resto, lo mismo.

Modelo de similitud
El modelo de relevancia es necesario para determinar en qué medida la coincidencia de un token afecta la relevancia del objeto de la base de datos con respecto a la solicitud. Suponga que si el token en la solicitud y el producto de la base de datos coinciden, esto ciertamente no es malo, pero dice poco sobre la conformidad del producto con la solicitud. Por lo tanto, la coincidencia de diferentes tokens conlleva diferentes valores. Para tener esto en cuenta, se necesita un modelo de relevancia. Elastic ofrece muchos modelos diferentes. Si realmente los comprende, puede elegir un modelo muy específico y adecuado para un caso particular. La elección puede basarse en la cantidad de palabras que se usan con frecuencia (como el mismo token), una evaluación de la importancia de los tokens largos (¿más largo significa mejor? ¿Peor? ¿No importa?), ¿Qué resultados queremos ver al final, etc. Ejemplos de modelos que se proponen en Elastic pueden ser TF-IDF (el modelo más simple y más comprensible), Okapi BM25 (TF-IDF mejorado, el modelo predeterminado), Divergencia de aleatoriedad, Divergencia de independencia, etc. Cada modelo también tiene opciones personalizables. Después de varios experimentos con el modelo, el modelo predeterminado Okapi BM25 mostró el mejor resultado, pero con parámetros diferentes a los predefinidos.
Usando categorías
En el curso de trabajar con la búsqueda, se hizo disponible información adicional muy importante sobre el producto, su categoría. Puede leer más sobre cómo implementamos la categorización en el artículo. Según tengo entendido, como muchos dulces, o la clasificación de los productos mediante el cheque en la aplicación . Hasta entonces, basamos nuestra búsqueda solo en una comparación de nombres de productos, ahora es posible comparar la categoría de solicitud y los productos en la base de datos.
Las opciones posibles para usar esta información son una coincidencia obligatoria en el campo de categoría (formateado como un filtro de resultados), una ventaja adicional en forma de puntos para productos con la misma categoría (como en el caso de los números) y la clasificación de los resultados por categoría (primero coincidencia, luego todos los demás). Para nuestro caso, la última opción funcionó mejor. Esto se debe a que nuestro algoritmo de categorización es demasiado bueno para usar el segundo método y no lo suficientemente bueno como para usar el primero. Tenemos suficiente confianza en el algoritmo y queremos que la coincidencia de categorías sea una gran ventaja. En el caso de agregar puntos adicionales a la velocidad (segundo método), los productos con la misma categoría subirán a la lista, pero aún perderán frente a algunos productos que coinciden más por su nombre. Sin embargo, el primer método tampoco nos conviene, ya que los errores en la categorización aún son posibles. A veces, la solicitud puede contener información insuficiente para determinar correctamente la categoría, o hay muy pocos productos en esta categoría en el radio inmediato del usuario. En este caso, todavía queremos mostrar resultados con una categoría diferente, pero aún relevante por nombre de producto.
El segundo método también es bueno porque no "estropea" la velocidad de los productos como resultado de la búsqueda, y le permite continuar usando la velocidad mínima calculada sin obstáculos.
La implementación específica del tipo se puede ver en la consulta final.
Modelo final
La selección del modelo de búsqueda final incluyó la generación de varios motores de búsqueda, su evaluación y comparación. Muy a menudo, la comparación se basó en uno de los parámetros. Supongamos que en un caso específico necesitamos calcular el mejor tamaño para el tokenizer edgeNgram (es decir, elegir el rango más efectivo de N). Para hacer esto, generamos los mismos motores de búsqueda con solo una diferencia en el tamaño de este rango. Después de eso, fue posible determinar el mejor valor para este parámetro.
Los modelos se evaluaron utilizando la métrica nDCG (ganancia acumulada descontada normalizada), una métrica para evaluar la calidad de la clasificación. Se enviaron consultas predefinidas a cada modelo de búsqueda, después de lo cual se calculó la métrica nDCG en función de los resultados de búsqueda recibidos.
Analizadores que ingresaron al modelo final:



El modelo predeterminado (Okapi - BM25) con el parámetro b = 0.5 fue elegido como el modelo de relevancia. El valor predeterminado es 0,75. Este parámetro muestra hasta qué punto la longitud del nombre del producto normaliza la variable tf (frecuencia de término). Un número menor en nuestro caso funciona mejor, ya que un nombre largo a menudo no afecta la importancia de una sola palabra. Es decir, la palabra "chocolate" en el nombre "chocolate con avellanas trituradas en un paquete de 25 piezas" no pierde su valor por el hecho de que el nombre es lo suficientemente largo.
La consulta final se ve así:
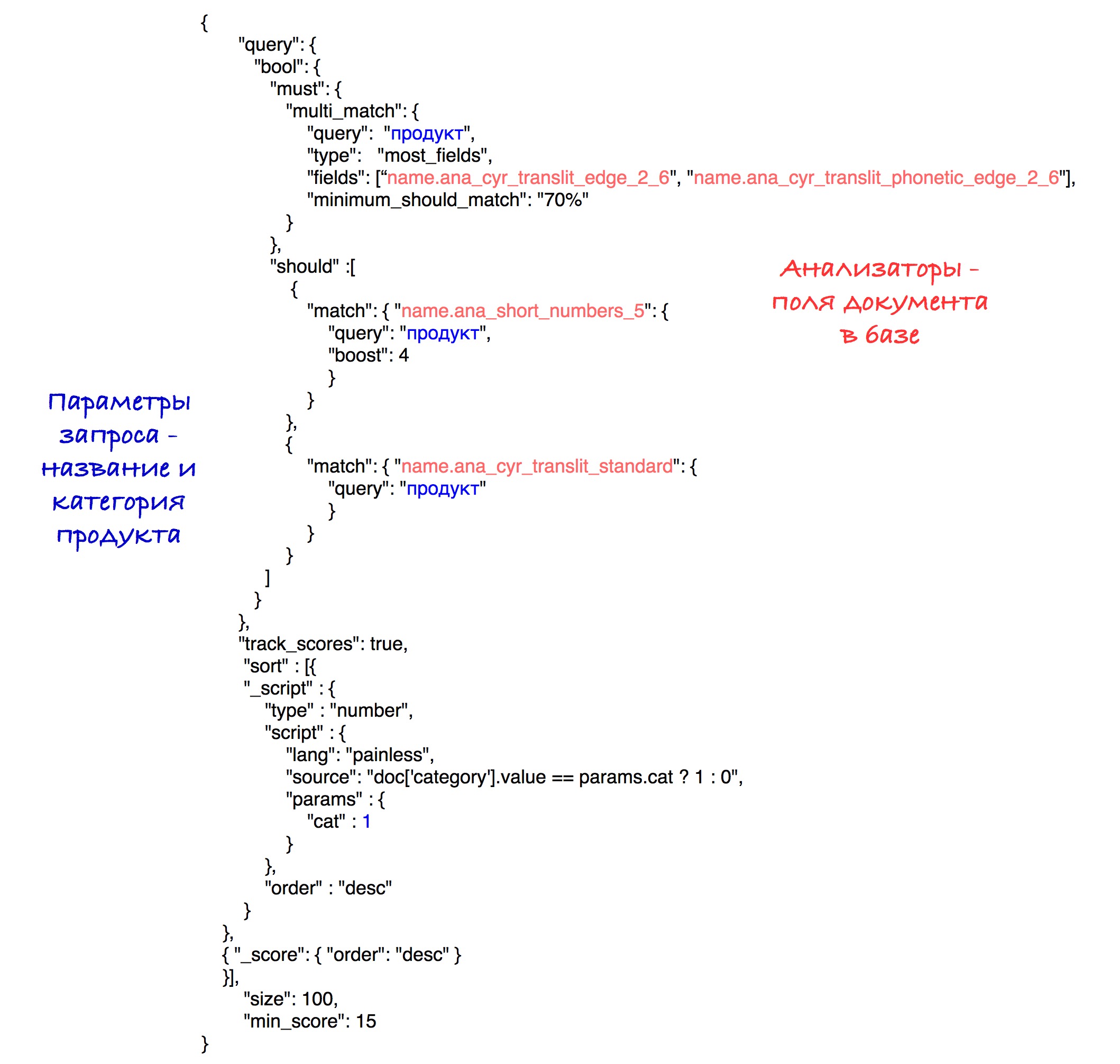
Experimentalmente, se reveló la mejor combinación de analizadores y pesos.
Como resultado de la clasificación, los productos con la misma categoría van al principio de los resultados y luego a todos los demás. La ordenación por el número de puntos (velocidad) se almacena dentro de cada subconjunto.
Para simplificar, el umbral de velocidad se establece en 15 en esta solicitud, aunque en nuestro sistema utilizamos el parámetro calculado que se describió anteriormente.
En el futuro
Se piensa mejorar la búsqueda resolviendo uno de los problemas más vergonzosos de nuestro algoritmo, que es la existencia de un millón y una forma diferente de acortar una palabra de 5 letras. Se puede resolver mediante el procesamiento inicial de nombres para revelar abreviaturas. Una forma de resolver esto es intentar comparar el nombre abreviado de nuestra base de datos con uno de los nombres de la base de datos con los nombres completos "correctos". Esta decisión encuentra sus obstáculos definitivos, pero parece un cambio prometedor.