Hola de nuevo
En diciembre, comenzaremos a capacitarnos para el próximo
grupo de Data Scientist , por lo que cada vez hay más lecciones abiertas y otras actividades. Por ejemplo, el otro día, se realizó un seminario web con el nombre largo "Ingeniería de características en el ejemplo del clásico conjunto de datos Titanic". Fue realizado por
Alexander Sizov , un desarrollador experimentado, Ph.D., experto en Machine / Deep learning, y participante en varios proyectos comerciales internacionales relacionados con inteligencia artificial y análisis de datos.
Una lección abierta tomó aproximadamente una hora y media. Durante el seminario web, el maestro habló sobre la selección de características, la transformación de datos de origen (codificación, escalado), la configuración de parámetros, la capacitación del modelo y mucho más. Durante la lección, a los participantes se les mostró un cuaderno Jupyter. Para el trabajo, utilizamos datos abiertos de la plataforma
Kaggle (el conjunto de datos clásico sobre el Titanic, del cual muchos comienzan a familiarizarse con Data Science). A continuación, ofrecemos un video y una transcripción del evento anterior, y
aquí puede recoger la presentación y los códigos en una computadora portátil Jupiter.
Selección de funciones
El tema fue elegido, aunque clásico, pero aún un poco sombrío. En particular, era necesario resolver el problema de clasificación binaria y predecir a partir de los datos disponibles si el pasajero sobrevivirá o no. Los datos en sí se dividieron en dos muestras de Entrenamiento y Prueba. La variable clave es Supervivencia (sobrevivido / no sobrevivido; 0 = No, 1 = Sí).
Datos de entrenamiento de entrada:
- clase de boleto
- edad y sexo del pasajero;
- estado civil (si hay parientes a bordo);
- precio del boleto;
- número de cabina;
- puerto de embarque.
Como puede ver, los tipos de variables son diferentes: numéricos, de texto. A partir de este caleidoscopio, fue necesario formar un conjunto de datos para el próximo entrenamiento modelo.
Resumimos:
- train.csv - conjunto de entrenamiento - conjunto de datos de entrenamiento. La respuesta se conoce en ellos: supervivencia: un signo binario 0 (no sobrevivió) / 1 (sobrevivió);
- test.csv - conjunto de prueba - conjunto de datos de prueba. La respuesta es desconocida. Esta es una muestra para enviar a la plataforma kaggle para calcular la métrica de calidad del modelo;
- gender_submission.csv es un ejemplo del formato de los datos que se enviarán a kaggle.
Algoritmo de trabajo
- El trabajo se realizó por etapas:
- Análisis de datos de train.csv.
- Manejo de valores perdidos.
- Escalado
- Codificación de características categóricas.
- Crear un modelo y seleccionar parámetros, elegir el mejor modelo en los datos convertidos de train.csv.
- Método de transformación, fijación y modelo.
- Aplicando las mismas conversiones a test.csv usando pipeline.
- Aplicación del modelo en test.csv.
- Guardar el archivo de resultados de la aplicación en el mismo formato que en gender_submission.csv.
- Envío de resultados a la plataforma kaggle.
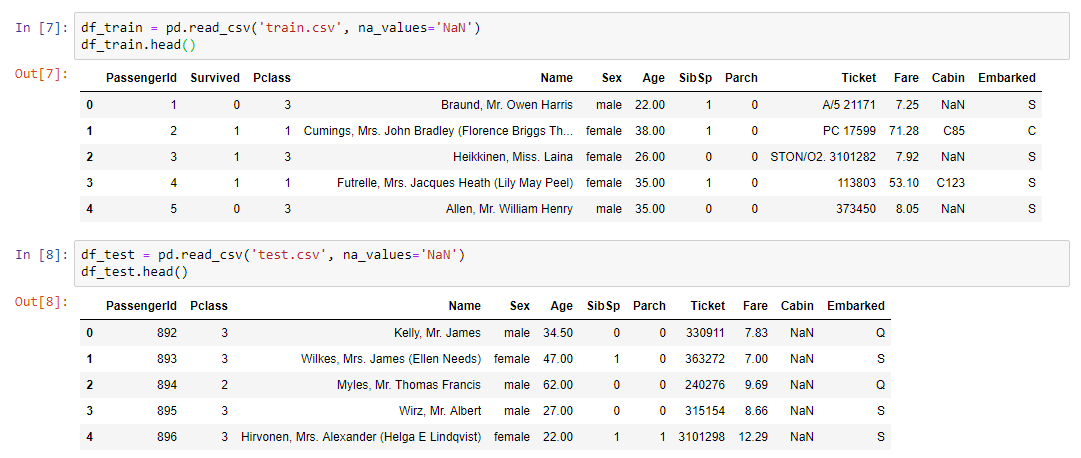
La parte práctica del seminario web.Lo primero que debía hacerse era leer el conjunto de datos y mostrar nuestros datos en la pantalla:
Para el análisis de datos, se utilizó una biblioteca de perfiles poco conocida pero bastante útil:
pandas_profiling.ProfileReport(df_train)Más sobre perfilesEsta biblioteca hace todo lo que se puede hacer a priori sin conocer los detalles sobre los datos. Por ejemplo, muestre estadísticas sobre los datos (cuántas variables y de qué tipo son, cuántas filas, valores faltantes, etc.). Además, se proporcionan estadísticas separadas para cada variable con un mínimo y un máximo, un gráfico de distribución y otros parámetros.
Como sabe, para hacer un buen modelo, necesita profundizar en el proceso que estamos tratando de modelar y comprender cuáles son los atributos clave. Además, lejos de siempre en nuestros datos hay todo lo que se necesita y, más precisamente, casi nunca en ellos hay todo lo necesario, determinando y determinando completamente nuestro proceso. Como regla general, siempre necesitamos combinar algo, tal vez agregar características adicionales que no están representadas en el conjunto de datos (por ejemplo, el pronóstico del tiempo). Es para comprender el proceso que necesitamos el análisis de datos, que se puede hacer usando la biblioteca de perfiles.
Valores perdidosEl siguiente paso es resolver el problema de los valores perdidos, porque en la mayoría de los casos los datos no están completamente llenos.
Las siguientes soluciones están disponibles para este problema:
- eliminar filas con valores perdidos (tenga en cuenta que puede perder algunos valores importantes);
- eliminar un signo (relevante si hay muy pocos datos en él);
- reemplace los valores faltantes con algo más (mediana, promedio ...).
Un ejemplo de una conversión simple usando el método fillna, que asigna los valores de la variable mediana solo a aquellas celdas que no están llenas:

Además, el maestro mostró ejemplos del uso de Imputer y pipeline.
Escalado de característicasEl funcionamiento del modelo y la decisión final dependen de la escala de las características. El hecho es que no es un hecho que cualquier característica que tenga una escala mayor sea más importante que una característica que tenga una escala menor. Es por eso que el modelo necesita enviar características que se escalen de forma idéntica, es decir, que tengan el mismo peso para el modelo.
Existen diferentes técnicas de escalado, sin embargo, el formato de la lección abierta nos permitió considerar solo dos de ellas con más detalle:
 Combinaciones de funciones
Combinaciones de funcionesLas combinaciones de características existentes que utilizan operaciones aritméticas (suma, multiplicación, división) le permiten obtener cualquier característica que haga que el modelo sea más eficiente. Esto no siempre es exitoso, y no sabemos qué combinación dará el efecto deseado, pero la práctica muestra que tiene sentido intentarlo. Es conveniente aplicar transformaciones de características utilizando la canalización.
CodificaciónEntonces, tenemos datos de diferentes tipos: numéricos y de texto. Actualmente, la mayoría de los modelos en el mercado no pueden funcionar con datos de texto. Como resultado, todos los signos categóricos (textuales) deben convertirse en una representación numérica, para la cual se utiliza la codificación.
Codificación de etiquetas . Este es un mecanismo implementado dentro del marco de muchas bibliotecas que se puede invocar y aplicar:

La codificación de etiquetas asigna un identificador único a cada valor único. Menos: introducimos el orden en una determinada variable que no se ordenó, lo que no es bueno.
OneHotEncoder. Los valores únicos de la variable de texto se expanden en forma de columnas que se agregan a los datos de origen, donde cada columna es una variable binaria en forma de 0 y 1. Este enfoque está libre de defectos de codificación de etiquetas, pero tiene su propio signo negativo: si hay muchos valores únicos, agregamos demasiadas columnas y en algunos casos el método simplemente no es aplicable (el conjunto de datos crece demasiado).
Entrenamiento modeloDespués de realizar los pasos anteriores, se compila una canalización final con un conjunto de todas las operaciones necesarias. Ahora es suficiente tomar el conjunto de datos de origen y aplicar la tubería resultante a estos datos mediante la operación fit_transform:
x_train = vec.fit_transform(df_train)Como resultado, obtenemos el conjunto de datos x_train, que está listo para usar en el modelo. Lo único que debe hacer es separar el valor de nuestra variable objetivo para que podamos realizar el entrenamiento.
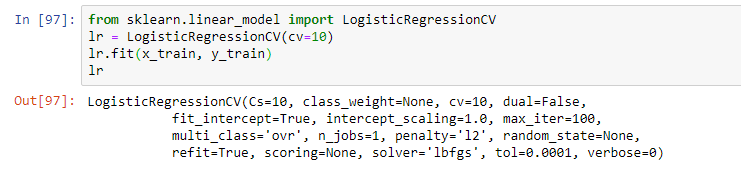
Luego, seleccione el modelo. Como parte del seminario web, el profesor propuso una regresión logística simple. El modelo fue entrenado utilizando la operación de ajuste, lo que resultó en un modelo en forma de regresión logística con ciertos parámetros:
Sin embargo, en la práctica, generalmente se utilizan varios modelos que parecen ser los más efectivos. Y la solución final es a menudo una combinación de estos modelos usando técnicas de apilamiento y otros enfoques para modelos de conjunto (usando múltiples modelos dentro del mismo modelo híbrido).
Después del entrenamiento, el modelo se puede aplicar a los datos de prueba, evaluando su calidad en el marco de alguna métrica. En nuestro caso, la calidad dentro del precision_score fue 0.8:

Esto significa que en los datos obtenidos la variable se predice correctamente en el 80% de los casos. Una vez recibidos los resultados de la capacitación, podemos mejorar el modelo (si la precisión no es satisfactoria) o proceder directamente al pronóstico.
Este fue el tema principal de la lección, pero la maestra habló con más detalle sobre las características del modelo en diferentes tareas y respondió preguntas de la audiencia. Entonces, si no quiere perderse nada, vea el seminario web completo si está interesado en este tema.
Como siempre, estamos esperando sus comentarios y preguntas que puede dejar aquí o preguntárselos a
Alexander yendo a él en un
día abierto.