Haciendo un boleto en el sistema de gestión de proyectos y seguimiento de tareas, cada uno de nosotros está contento de ver los términos aproximados de la decisión sobre nuestra apelación.
Al recibir un flujo de boletos entrantes, una persona / equipo necesita alinearlos en prioridad y tiempo, lo que tomará para resolver cada apelación.
Todo esto le permite planificar su tiempo de manera más efectiva para ambas partes.
Bajo el corte, hablaré sobre cómo analicé y entrené a los modelos de ML que predicen el tiempo que lleva resolver los boletos emitidos a nuestro equipo.
Yo mismo trabajo para el puesto de SRE en un equipo llamado LAB. Estamos recibiendo llamadas tanto de desarrolladores como de control de calidad con respecto al despliegue de nuevos entornos de prueba, sus actualizaciones a las últimas versiones de lanzamiento, soluciones a varios problemas que surgen y mucho más. Estas tareas son bastante heterogéneas y, lógicamente, requieren una cantidad diferente de tiempo para completarse. Existe nuestro equipo durante varios años y durante este tiempo se logró acumular una buena base de solicitudes. Decidí analizar esta base y en base a ella, con la ayuda del aprendizaje automático, elaborar un modelo que aborde la predicción del tiempo probable de cierre de una apelación (ticket).
En nuestro trabajo, utilizamos JIRA, sin embargo, el modelo que presento en este artículo no tiene ninguna relación con un producto específico; no es un problema obtener la información necesaria de ninguna base de datos.
Entonces, pasemos de las palabras a los hechos.
Análisis de datos preliminares.
Cargamos todo lo que necesitamos y mostramos las versiones de los paquetes utilizados.
Código fuenteimport warnings warnings.simplefilter('ignore') %matplotlib inline import matplotlib.pyplot as plt import pandas as pd import numpy as np import datetime from nltk.corpus import stopwords from sklearn.model_selection import train_test_split from sklearn.metrics import mean_absolute_error, mean_squared_error from sklearn.neighbors import KNeighborsRegressor from sklearn.linear_model import LinearRegression from datetime import time, date for package in [pd, np, matplotlib, sklearn, nltk]: print(package.__name__, 'version:', package.__version__)
pandas version: 0.23.4 numpy version: 1.15.0 matplotlib version: 2.2.2 sklearn version: 0.19.2 nltk version: 3.3
Descargue los datos del archivo csv. Contiene información sobre boletos cerrados en los últimos 1,5 años. Antes de escribir los datos en un archivo, fueron ligeramente preprocesados. Por ejemplo, se han eliminado comas y puntos de los campos de texto con descripciones. Sin embargo, esto es solo un procesamiento preliminar y en el futuro el texto se borrará más.
Veamos qué hay en nuestro conjunto de datos. En total, ingresaron 10783 boletos.
Explicación de campo| Creado | Fecha y hora de creación del ticket |
| Resuelto | Fecha y hora de cierre del boleto |
| Resolución_hora | El número de minutos transcurridos entre la creación y el cierre de un ticket. Se considera la hora del calendario, porque La compañía tiene oficinas en diferentes países, trabajando en diferentes zonas horarias y no hay un horario fijo para todo el departamento. |
| Ingeniero_N | Nombres "codificados" de ingenieros (para no dar información inadvertida o confidencial en el futuro, habrá una gran cantidad de datos "codificados" en el artículo, que de hecho simplemente se renombrarán). Estos campos contienen el número de tickets en el modo “en progreso” al momento de recibir cada uno de los tickets en el conjunto de fechas presentado. Me detendré en estos campos por separado hacia el final del artículo, porque Merecen atención extra. |
| Cesionario | El empleado que estuvo involucrado en la resolución del problema. |
| Issue_type | Tipo de boleto. |
| Medio ambiente | El nombre del entorno de trabajo de prueba para el que se realizó el ticket (puede significar un entorno específico o la ubicación en su conjunto, por ejemplo, un centro de datos). |
| Prioridad | Prioridad de entradas. |
| Tipo de trabajo | El tipo de trabajo que se espera para este ticket (agregar o quitar servidores, actualizar el entorno, trabajar con monitoreo, etc.) |
| Descripción | Descripción |
| Resumen | Título del boleto. |
| Vigilantes | El número de personas que "miran" el boleto, es decir reciben notificaciones por correo electrónico para cada actividad en el boleto. |
| Votos | El número de personas que "votaron" por el boleto, lo que demuestra su importancia y su interés en él. |
| Reportero | La persona que emitió el boleto. |
| Engineer_N_vacation | Si el ingeniero estaba de vacaciones al momento de emitir el boleto. |
df.info()
<class 'pandas.core.frame.DataFrame'> Index: 10783 entries, ENV-36273 to ENV-49164 Data columns (total 37 columns): Created 10783 non-null object Resolved 10783 non-null object Resolution_time 10783 non-null int64 engineer_1 10783 non-null int64 engineer_2 10783 non-null int64 engineer_3 10783 non-null int64 engineer_4 10783 non-null int64 engineer_5 10783 non-null int64 engineer_6 10783 non-null int64 engineer_7 10783 non-null int64 engineer_8 10783 non-null int64 engineer_9 10783 non-null int64 engineer_10 10783 non-null int64 engineer_11 10783 non-null int64 engineer_12 10783 non-null int64 Assignee 10783 non-null object Issue_type 10783 non-null object Environment 10771 non-null object Priority 10783 non-null object Worktype 7273 non-null object Description 10263 non-null object Summary 10783 non-null object Watchers 10783 non-null int64 Votes 10783 non-null int64 Reporter 10783 non-null object engineer_1_vacation 10783 non-null int64 engineer_2_vacation 10783 non-null int64 engineer_3_vacation 10783 non-null int64 engineer_4_vacation 10783 non-null int64 engineer_5_vacation 10783 non-null int64 engineer_6_vacation 10783 non-null int64 engineer_7_vacation 10783 non-null int64 engineer_8_vacation 10783 non-null int64 engineer_9_vacation 10783 non-null int64 engineer_10_vacation 10783 non-null int64 engineer_11_vacation 10783 non-null int64 engineer_12_vacation 10783 non-null int64 dtypes: float64(12), int64(15), object(10) memory usage: 3.1+ MB
En total, tenemos 10 campos de "objeto" (es decir, que contienen un valor de texto) y 27 campos numéricos.
En primer lugar, busque inmediatamente las emisiones en nuestros datos. Como puede ver, existen dichos tickets en los que el tiempo de decisión se estima en millones de minutos. Claramente, esta no es información relevante, tales datos solo interferirán con la construcción del modelo. Llegaron aquí, porque la recopilación de datos de JIRA se realizó mediante una consulta en el campo Resuelto, y no se creó. En consecuencia, los boletos que se cerraron en los últimos 1,5 años llegaron aquí, pero podrían haberse abierto mucho antes. Es hora de deshacerse de ellos. Descartaremos los tickets que se crearon antes del 1 de junio de 2017. Tendremos 9493 boletos restantes.
En cuanto a las razones: creo que en cada proyecto puede encontrar fácilmente solicitudes que han estado pendientes durante bastante tiempo debido a diversas circunstancias y que a menudo se cierran no resolviendo el problema en sí, sino "venciendo el plazo de prescripción".
Código fuente df[['Created', 'Resolved', 'Resolution_time']].sort_values('Resolution_time', ascending=False).head()

Código fuente df = df[df['Created'] >= '2017-06-01 00:00:00'] print(df.shape)
(9493, 33)
Entonces, comencemos a ver lo que podemos encontrar interesante en nuestros datos. Para comenzar, descubramos lo más simple: los entornos más populares entre nuestros tickets, los "reporteros" más activos y similares.
Código fuente df.describe(include=['object'])

Código fuente df['Environment'].value_counts().head(10)
Environment_104 442 ALL 368 Location02 367 Environment_99 342 Location03 342 Environment_31 322 Environment_14 254 Environment_1 232 Environment_87 227 Location01 202 Name: Environment, dtype: int64
Código fuente df['Reporter'].value_counts().head()
Reporter_16 388 Reporter_97 199 Reporter_04 147 Reporter_110 145 Reporter_133 138 Name: Reporter, dtype: int64
Código fuente df['Worktype'].value_counts()
Support 2482 Infrastructure 1655 Update environment 1138 Monitoring 388 QA 300 Numbers 110 Create environment 95 Tools 62 Delete environment 24 Name: Worktype, dtype: int64
Código fuente df['Priority'].value_counts().plot(kind='bar', figsize=(12,7), rot=0, fontsize=14, title=' ');
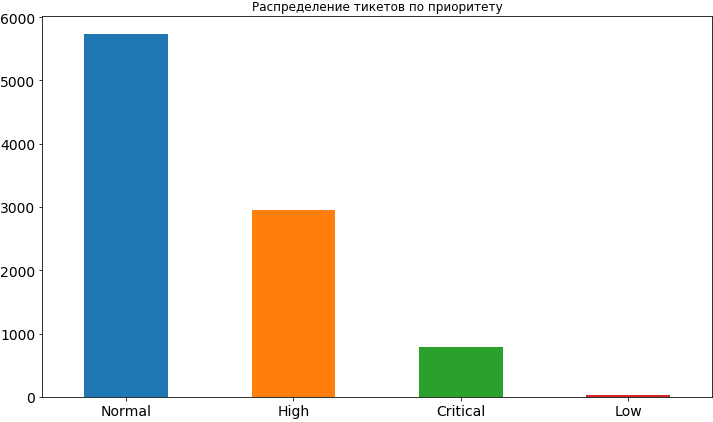
Bueno, algo que ya hemos aprendido. La mayoría de las veces, la prioridad para las entradas es normal, aproximadamente 2 veces menos alta e incluso menos crítica. Muy rara vez hay una baja prioridad, aparentemente las personas tienen miedo de exponerla, creyendo que en este caso quedará suspendido durante un tiempo bastante largo en la cola y el tiempo para su decisión puede retrasarse. Más tarde, cuando ya construiremos el modelo y analicemos sus resultados, veremos que tales temores pueden no ser infundados, ya que una baja prioridad realmente afecta el marco de tiempo para la tarea y, por supuesto, no en la dirección de la aceleración.
De las columnas para los entornos más populares y los reporteros más activos, vemos que Reporter_16 tiene un amplio margen, y Environment_104 ocupa el primer lugar en los entornos. Incluso si aún no lo ha adivinado, le contaré un pequeño secreto: este reportero es del equipo que trabaja en este entorno en particular.
Veamos de qué tipo de entorno provienen los tickets más críticos.
Código fuente df[df['Priority'] == 'Critical']['Environment'].value_counts().index[0]
'Environment_91'
Ahora imprimiremos información sobre cuántos tickets con diferentes prioridades provienen del mismo entorno "crítico".
Código fuente df[df['Environment'] == df[df['Priority'] == 'Critical']['Environment'].value_counts().index[0]]['Priority'].value_counts()
High 62 Critical 57 Normal 46 Name: Priority, dtype: int64
Veamos el tiempo de ejecución del ticket en el contexto de las prioridades. Por ejemplo, es divertido notar que el tiempo promedio de ejecución de un ticket con baja prioridad es más de 70 mil minutos (casi 1.5 meses). La dependencia del tiempo de ejecución del ticket de su prioridad también se puede rastrear fácilmente.
Código fuente df.groupby(['Priority'])['Resolution_time'].describe()
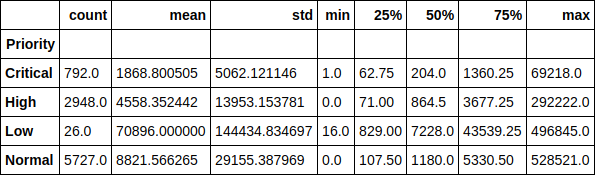
O aquí como un gráfico, el valor medio. Como puede ver, la imagen no ha cambiado mucho, por lo tanto, las emisiones no afectan en gran medida la distribución.
Código fuente df.groupby(['Priority'])['Resolution_time'].median().sort_values().plot(kind='bar', figsize=(12,7), rot=0, fontsize=14);

Ahora veamos el tiempo promedio de solución de boletos para cada uno de los ingenieros, dependiendo de cuántos boletos tenía el ingeniero en ese momento. De hecho, estos gráficos, para mi sorpresa, no muestran una sola imagen. Para algunos, el tiempo de ejecución aumenta a medida que aumentan los tickets actuales en el trabajo, mientras que para algunos esta relación es lo contrario. Para algunos, la adicción no es del todo rastreable.
Sin embargo, mirando hacia el futuro nuevamente, diré que la presencia de esta característica en el conjunto de datos aumentó la precisión del modelo en más de 2 veces y definitivamente hay un efecto en el tiempo de ejecución. Simplemente no lo vemos. Y el modelo ve.
Código fuente engineers = [i.replace('_vacation', '') for i in df.columns if 'vacation' in i] cols = 2 rows = int(len(engineers) / cols) fig, axes = plt.subplots(nrows=rows, ncols=cols, figsize=(16,24)) for i in range(rows): for j in range(cols): df.groupby(engineers[i * cols + j])['Resolution_time'].mean().plot(kind='bar', rot=0, ax=axes[i, j]).set_xlabel('Engineer_' + str(i * cols + j + 1)) del cols, rows, fig, axes
Imagen larga como resultado Hagamos una pequeña matriz de interacción por pares de las siguientes características: tiempo de solución del ticket, número de votos y número de observadores. Con una bonificación diagonal, tenemos la distribución de cada atributo.
De lo interesante, se puede ver la dependencia de reducir el tiempo de solución del ticket en el creciente número de observadores. También se ve que las personas no son muy activas en el uso de los votos.
Código fuente pd.scatter_matrix(df[['Resolution_time', 'Watchers', 'Votes']], figsize=(15, 15), diagonal='hist');
Entonces, realizamos un pequeño análisis preliminar de los datos, vimos las dependencias existentes entre el atributo objetivo, que es el tiempo que lleva resolver el boleto, y signos tales como el número de votos para el boleto, el número de "observadores" detrás de él y su prioridad. Seguimos adelante.
Construyendo un modelo. Señales de construcción
Es hora de pasar a construir el modelo en sí. Pero primero, necesitamos llevar nuestras características a una forma que sea comprensible para el modelo. Es decir descomponga los signos categóricos en vectores dispersos y elimine el exceso. Por ejemplo, no necesitamos los campos con la hora en que se creó y cerró el ticket en el modelo, así como el campo Asignatario, porque finalmente utilizaremos este modelo para predecir el tiempo de ejecución de un ticket que aún no ha sido asignado a nadie ("asesinado").
El signo objetivo, como acabo de mencionar, es el momento de resolver el problema para nosotros, por lo que lo tomamos como un vector separado y también lo eliminamos del conjunto de datos generales. Además, algunos de los campos estaban vacíos debido a que los reporteros no siempre completan el campo de descripción al emitir un ticket. En este caso, los pandas establecen sus valores en NaN, simplemente los reemplazamos con una cadena vacía.
Código fuente y = df['Resolution_time'] df.drop(['Created', 'Resolved', 'Resolution_time', 'Assignee'], axis=1, inplace=True) df['Description'].fillna('', inplace=True) df['Summary'].fillna('', inplace=True)
Descomponemos signos categóricos en vectores dispersos ( codificación One-hot ). Hasta que toquemos los campos con la descripción y la tabla de contenido del ticket. Los usaremos un poco diferente. Algunos nombres de reportero contienen una [X]. Entonces, JIRA marca a los empleados inactivos que ya no trabajan en la empresa. Decidí dejarlos entre los signos, aunque es posible borrar los datos de ellos, porque en el futuro, cuando usemos el modelo, no veremos boletos de estos empleados.
Código fuente def create_df(dic, feature_list): out = pd.DataFrame(dic) out = pd.concat([out, pd.get_dummies(out[feature_list])], axis = 1) out.drop(feature_list, axis = 1, inplace = True) return out X = create_df(df, df.columns[df.dtypes == 'object'].drop(['Description', 'Summary'])) X.columns = X.columns.str.replace(' \[X\]', '')
Y ahora nos ocuparemos del campo de descripción en el ticket. Trabajaremos con él de una de las formas más simples: recopilaremos todas las palabras utilizadas en nuestros tickets, contaremos las más populares, descartaremos las palabras "extra", aquellas que obviamente no pueden afectar el resultado, como, por ejemplo, la palabra "por favor" (por favor, toda la comunicación en JIRA se realiza estrictamente en inglés), que es el más popular. Sí, estas son nuestras personas educadas.
También eliminamos las " palabras de detención ", de acuerdo con la biblioteca nltk, y limpiamos más a fondo el texto de caracteres innecesarios. Permíteme recordarte que esto es lo más simple que se puede hacer con el texto. No " estampamos " palabras, también puede contar los N-gramos de palabras más populares, pero nos limitaremos a eso.
Código fuente all_words = np.concatenate(df['Description'].apply(lambda s: s.split()).values) stop_words = stopwords.words('english') stop_words.extend(['please', 'hi', '-', '0', '1', '2', '3', '4', '5', '6', '7', '8', '9', '(', ')', '=', '{', '}']) stop_words.extend(['h3', '+', '-', '@', '!', '#', '$', '%', '^', '&', '*', '(for', 'output)']) stop_symbols = ['=>', '|', '[', ']', '#', '*', '\\', '/', '->', '>', '<', '&'] words_series = pd.Series(list(all_words)) del all_words words_series = words_series[~words_series.isin(stop_words)] for symbol in stop_symbols: words_series = words_series[~words_series.str.contains(symbol, regex=False, na=False)]
Después de todo esto, obtuvimos el objeto pandas.Series que contiene todas las palabras utilizadas. Veamos los más populares y tomemos los primeros 50 de la lista para usarlos como signos. Para cada uno de los tickets, veremos si esta palabra se usa en la descripción y, de ser así, coloque 1 en la columna correspondiente, de lo contrario 0.
Código fuente usefull_words = list(words_series.value_counts().head(50).index) print(usefull_words[0:10])
['error', 'account', 'info', 'call', '{code}', 'behavior', 'array', 'update', 'env', 'actual']
Ahora, en nuestro conjunto de datos generales, crearemos columnas separadas para las palabras que hemos seleccionado. En esto, puede deshacerse del campo de descripción en sí.
Código fuente for word in usefull_words: X['Description_' + word] = X['Description'].str.contains(word).astype('int64') X.drop('Description', axis=1, inplace=True)
Haremos lo mismo para el campo del título del boleto.
Código fuente all_words = np.concatenate(df['Summary'].apply(lambda s: s.split()).values) words_series = pd.Series(list(all_words)) del all_words words_series = words_series[~words_series.isin(stop_words)] for symbol in stop_symbols: words_series = words_series[~words_series.str.contains(symbol, regex=False, na=False)] usefull_words = list(words_series.value_counts().head(50).index) for word in usefull_words: X['Summary_' + word] = X['Summary'].str.contains(word).astype('int64') X.drop('Summary', axis=1, inplace=True)
Veamos con qué terminamos en la matriz de características X y el vector de respuesta y.
((9493, 1114), (9493,))
Ahora dividiremos estos datos en una muestra de entrenamiento (entrenamiento) y una muestra de prueba en la proporción porcentual de 75/25. Total tenemos 7119 ejemplos en los que entrenaremos, y 2374 en los que evaluaremos nuestros modelos. Y la dimensión de nuestra matriz de atributos aumentó a 1114 debido a la disposición de signos categóricos.
Código fuente X_train, X_holdout, y_train, y_holdout = train_test_split(X, y, test_size=0.25, random_state=17) print(X_train.shape, X_holdout.shape)
((7119, 1114), (2374, 1114))
Entrenamos al modelo.
Regresión lineal
Comencemos con el modelo más ligero y (menos esperado) menos preciso: la regresión lineal. Evaluaremos tanto la precisión de los datos de entrenamiento como la muestra demorada (reservada), datos que el modelo no vio.
En el caso de la regresión lineal, el modelo más o menos aceptable se muestra en los datos de entrenamiento, pero la precisión en la muestra retrasada es monstruosamente baja. Incluso mucho peor que predecir el promedio habitual para todas las entradas.
Aquí debe tomar un breve descanso y contar cómo el modelo evalúa la calidad utilizando su método de puntuación.
La evaluación se realiza por el coeficiente de determinación :
Donde Es el resultado predicho por el modelo a - el valor promedio para toda la muestra.
No nos detendremos demasiado en el coeficiente ahora. Solo notamos que no refleja completamente la precisión del modelo que nos interesa. Por lo tanto, al mismo tiempo, utilizaremos el error absoluto medio (MAE) para evaluarlo y confiar en él.
Código fuente lr = LinearRegression() lr.fit(X_train, y_train) print('R^2 train:', lr.score(X_train, y_train)) print('R^2 test:', lr.score(X_holdout, y_holdout)) print('MAE train', mean_absolute_error(lr.predict(X_train), y_train)) print('MAE test', mean_absolute_error(lr.predict(X_holdout), y_holdout))
R^2 train: 0.3884389470220214 R^2 test: -6.652435243123196e+17 MAE train: 8503.67256637168 MAE test: 1710257520060.8154
Aumento de gradiente
Bueno, ¿dónde sin él, sin aumento de gradiente? Intentemos entrenar al modelo y ver qué sucede. Usaremos el notorio XGBoost para esto. Comencemos con la configuración estándar de hiperparámetros.
Código fuente import xgboost xgb = xgboost.XGBRegressor() xgb.fit(X_train, y_train) print('R^2 train:', xgb.score(X_train, y_train)) print('R^2 test:', xgb.score(X_holdout, y_holdout)) print('MAE train', mean_absolute_error(xgb.predict(X_train), y_train)) print('MAE test', mean_absolute_error(xgb.predict(X_holdout), y_holdout))
R^2 train: 0.5138516547636054 R^2 test: 0.12965507684512545 MAE train: 7108.165167471887 MAE test: 8343.433260957032
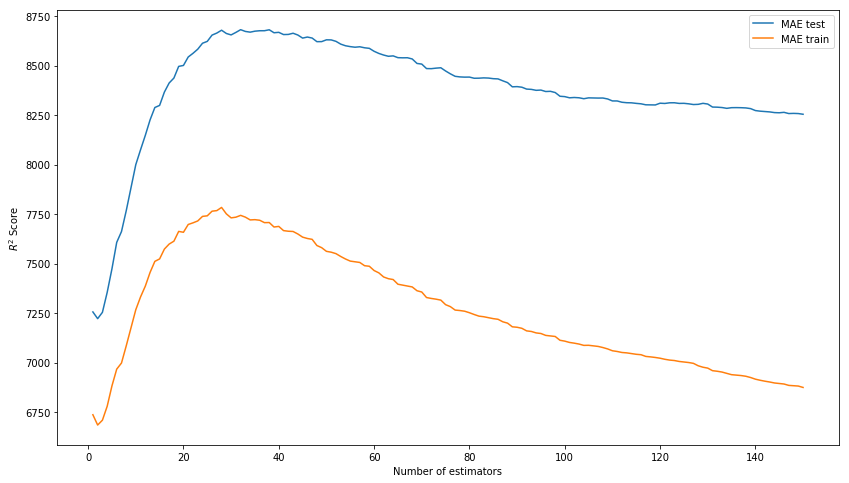
El resultado fuera de la caja ya no es malo. Intentemos modelar el modelo seleccionando hiperparámetros: n_estimators, learning_rate y max_depth. Como resultado, nos detenemos en los valores de 150, 0.1 y 3, respectivamente, que muestran el mejor resultado en la muestra de prueba en ausencia de sobreentrenamiento del modelo en los datos de entrenamiento.
Seleccionamos n_estimators* En lugar de R ^ 2, la puntuación en la imagen debe ser MAE.
xgb_model_abs_testing = list() xgb_model_abs_training = list() rng = np.arange(1,151) for i in rng: xgb = xgboost.XGBRegressor(n_estimators=i) xgb.fit(X_train, y_train) xgb.score(X_holdout, y_holdout) xgb_model_abs_testing.append(mean_absolute_error(xgb.predict(X_holdout), y_holdout)) xgb_model_abs_training.append(mean_absolute_error(xgb.predict(X_train), y_train)) plt.figure(figsize=(14, 8)) plt.plot(rng, xgb_model_abs_testing, label='MAE test'); plt.plot(rng, xgb_model_abs_training, label='MAE train'); plt.xlabel('Number of estimators') plt.ylabel('$R^2 Score$') plt.legend(loc='best') plt.show();
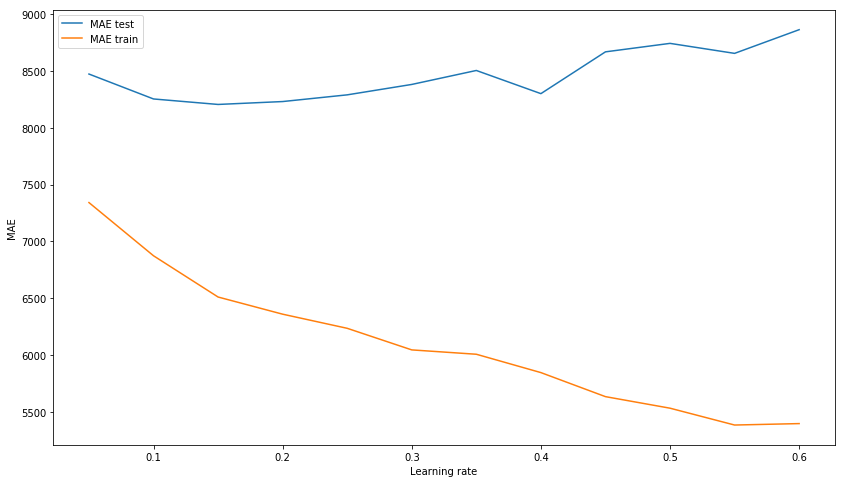
Seleccionamos learning_rate xgb_model_abs_testing = list() xgb_model_abs_training = list() rng = np.arange(0.05, 0.65, 0.05) for i in rng: xgb = xgboost.XGBRegressor(n_estimators=150, random_state=17, learning_rate=i) xgb.fit(X_train, y_train) xgb.score(X_holdout, y_holdout) xgb_model_abs_testing.append(mean_absolute_error(xgb.predict(X_holdout), y_holdout)) xgb_model_abs_training.append(mean_absolute_error(xgb.predict(X_train), y_train)) plt.figure(figsize=(14, 8)) plt.plot(rng, xgb_model_abs_testing, label='MAE test'); plt.plot(rng, xgb_model_abs_training, label='MAE train'); plt.xlabel('Learning rate') plt.ylabel('MAE') plt.legend(loc='best') plt.show();
Seleccionamos max_depth xgb_model_abs_testing = list() xgb_model_abs_training = list() rng = np.arange(1, 11) for i in rng: xgb = xgboost.XGBRegressor(n_estimators=150, random_state=17, learning_rate=0.1, max_depth=i) xgb.fit(X_train, y_train) xgb.score(X_holdout, y_holdout) xgb_model_abs_testing.append(mean_absolute_error(xgb.predict(X_holdout), y_holdout)) xgb_model_abs_training.append(mean_absolute_error(xgb.predict(X_train), y_train)) plt.figure(figsize=(14, 8)) plt.plot(rng, xgb_model_abs_testing, label='MAE test'); plt.plot(rng, xgb_model_abs_training, label='MAE train'); plt.xlabel('Maximum depth') plt.ylabel('MAE') plt.legend(loc='best') plt.show();

Ahora entrenaremos el modelo con hiperparámetros seleccionados.
Código fuente xgb = xgboost.XGBRegressor(n_estimators=150, random_state=17, learning_rate=0.1, max_depth=3) xgb.fit(X_train, y_train) print('R^2 train:', xgb.score(X_train, y_train)) print('R^2 test:', xgb.score(X_holdout, y_holdout)) print('MAE train', mean_absolute_error(xgb.predict(X_train), y_train)) print('MAE test', mean_absolute_error(xgb.predict(X_holdout), y_holdout))
R^2 train: 0.6745967150462303 R^2 test: 0.15415143189670344 MAE train: 6328.384400466232 MAE test: 8217.07897417256
El resultado final con los parámetros seleccionados y la función de visualización son importantes: la importancia de los signos según el modelo. En primer lugar, es el número de observadores de boletos, pero luego 4 ingenieros van de inmediato. En consecuencia, el tiempo de empleo de un boleto puede verse muy afectado por el empleo de un ingeniero. Y es lógico que el tiempo libre de algunos de ellos sea más importante. Al menos porque el equipo tiene ingenieros superiores y medios (no tenemos juniors en el equipo). Por cierto, nuevamente en secreto, el ingeniero en primer lugar (barra naranja) es realmente uno de los más experimentados de todo el equipo. Además, los 4 de estos ingenieros tienen un prefijo senior en su puesto. Resulta que el modelo una vez más confirmó esto.
Código fuente features_df = pd.DataFrame(data=xgb.feature_importances_.reshape(1, -1), columns=X.columns).sort_values(axis=1, by=[0], ascending=False) features_df.loc[0][0:10].plot(kind='bar', figsize=(16, 8), rot=75, fontsize=14);
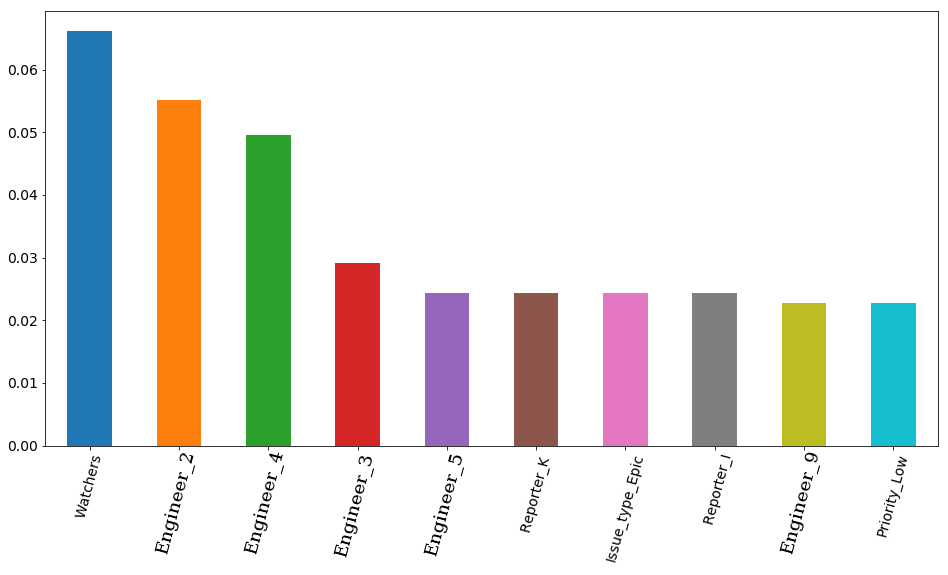
Red neuronal
Pero no nos detendremos en un aumento de gradiente e intentaremos entrenar la red neuronal, o más bien el perceptrón multicapa, una red neuronal de distribución directa totalmente conectada. Esta vez no comenzaremos con la configuración estándar de hiperparámetros, como en la biblioteca sklearn, que usaremos, por defecto solo hay una capa oculta con 100 neuronas y durante el entrenamiento el modelo da una advertencia sobre el desacuerdo para las 200 iteraciones estándar. Inmediatamente utilizamos 3 capas ocultas con 300, 200 y 100 neuronas, respectivamente.
Como resultado, vemos que el modelo no está sobreentrenado en la muestra de entrenamiento, lo que, sin embargo, no evita que muestre un resultado decente en la muestra de prueba. Este resultado es bastante inferior al resultado del aumento de gradiente.
Código fuente from sklearn.neural_network import MLPRegressor nn = MLPRegressor(random_state=17, hidden_layer_sizes=(300, 200 ,100), alpha=0.03, learning_rate='adaptive', learning_rate_init=0.0005, max_iter=200, momentum=0.9, nesterovs_momentum=True) nn.fit(X_train, y_train) print('R^2 train:', nn.score(X_train, y_train)) print('R^2 test:', nn.score(X_holdout, y_holdout)) print('MAE train', mean_absolute_error(nn.predict(X_train), y_train)) print('MAE test', mean_absolute_error(nn.predict(X_holdout), y_holdout))
R^2 train: 0.9771443840549647 R^2 test: -0.15166596239118246 MAE train: 1627.3212161350423 MAE test: 8816.204561947616
Veamos qué podemos lograr al tratar de elegir la mejor arquitectura de nuestra red. , , 200 , , . .
plt.figure(figsize=(14, 8)) for i in [(500,), (750,), (1000,), (500,500)]: nn = MLPRegressor(random_state=17, hidden_layer_sizes=i, alpha=0.03, learning_rate='adaptive', learning_rate_init=0.0005, max_iter=200, momentum=0.9, nesterovs_momentum=True) nn.fit(X_train, y_train) plt.plot(nn.loss_curve_, label=str(i)); plt.xlabel('Iterations') plt.ylabel('MSE') plt.legend(loc='best') plt.show()

. 3 10 .
plt.figure(figsize=(14, 8)) for i in [(500,300,100), (80, 60, 60, 60, 40, 40, 40, 40, 20, 10), (80, 60, 60, 40, 40, 40, 20, 10), (150, 100, 80, 60, 40, 40, 20, 10), (200, 100, 100, 100, 80, 80, 80, 40, 20), (80, 40, 20, 20, 10, 5), (300, 250, 200, 100, 80, 80, 80, 40, 20)]: nn = MLPRegressor(random_state=17, hidden_layer_sizes=i, alpha=0.03, learning_rate='adaptive', learning_rate_init=0.001, max_iter=200, momentum=0.9, nesterovs_momentum=True) nn.fit(X_train, y_train) plt.plot(nn.loss_curve_, label=str(i)); plt.xlabel('Iterations') plt.ylabel('MSE') plt.legend(loc='best') plt.show()
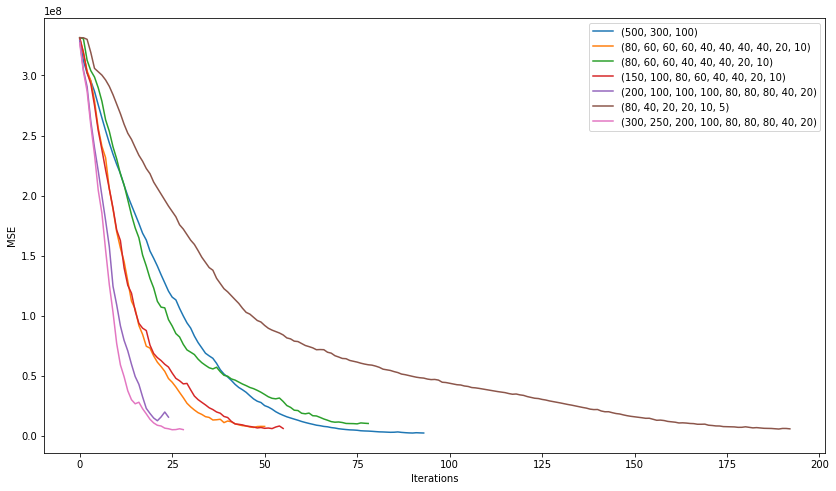
"" (200, 100, 100, 100, 80, 80, 80, 40, 20) :
2506
7351
, , . learning rate .
nn = MLPRegressor(random_state=17, hidden_layer_sizes=(200, 100, 100, 100, 80, 80, 80, 40, 20), alpha=0.1, learning_rate='adaptive', learning_rate_init=0.007, max_iter=200, momentum=0.9, nesterovs_momentum=True) nn.fit(X_train, y_train) print('R^2 train:', nn.score(X_train, y_train)) print('R^2 test:', nn.score(X_holdout, y_holdout)) print('MAE train', mean_absolute_error(nn.predict(X_train), y_train)) print('MAE test', mean_absolute_error(nn.predict(X_holdout), y_holdout))
R^2 train: 0.836204705204337 R^2 test: 0.15858607391959356 MAE train: 4075.8553476632796 MAE test: 7530.502826043687
, . , . , , .
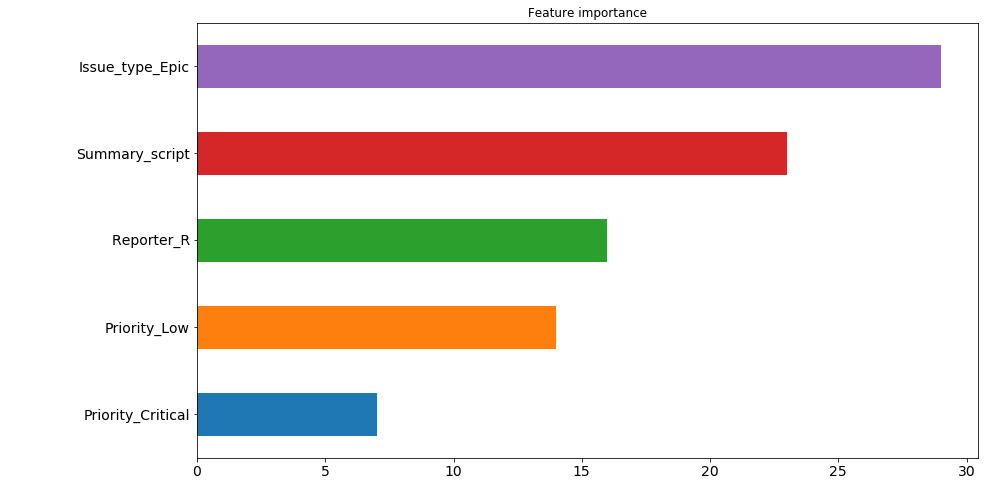
. : ( , 200 ). , "" . , 30 200 , issue type: Epic . , .. , , , , . 4 5 . , . , .
— 9 , . , , , .
pd.Series([X_train.columns[abs(nn.coefs_[0][:,i]).argmax()] for i in range(nn.hidden_layer_sizes[0])]).value_counts().head(5).sort_values().plot(kind='barh', title='Feature importance', fontsize=14, figsize=(14,8));
. Por qué 7530 8217. (7530 + 8217) / 2 = 7873, , , ? No, no asi. , . , 7526.
, kaggle . , , .
nn_predict = nn.predict(X_holdout) xgb_predict = xgb.predict(X_holdout) print('NN MSE:', mean_squared_error(nn_predict, y_holdout)) print('XGB MSE:', mean_squared_error(xgb_predict, y_holdout)) print('Ensemble:', mean_squared_error((nn_predict + xgb_predict) / 2, y_holdout)) print('NN MAE:', mean_absolute_error(nn_predict, y_holdout)) print('XGB MSE:', mean_absolute_error(xgb_predict, y_holdout)) print('Ensemble:', mean_absolute_error((nn_predict + xgb_predict) / 2, y_holdout))
NN MSE: 628107316.262393 XGB MSE: 631417733.4224195 Ensemble: 593516226.8298339 NN MAE: 7530.502826043687 XGB MSE: 8217.07897417256 Ensemble: 7526.763569558157
? 7500 . Es decir 5 . . . , .
( ):
((nn_predict + xgb_predict) / 2 - y_holdout).apply(np.abs).sort_values(ascending=False).head(10).values
[469132.30504392, 454064.03521379, 252946.87342439, 251786.22682697, 224012.59016987, 15671.21520735, 13201.12440327, 203548.46460229, 172427.32150665, 171088.75543224]
. , .
df.loc[((nn_predict + xgb_predict) / 2 - y_holdout).apply(np.abs).sort_values(ascending=False).head(10).index][['Issue_type', 'Priority', 'Worktype', 'Summary', 'Watchers']]
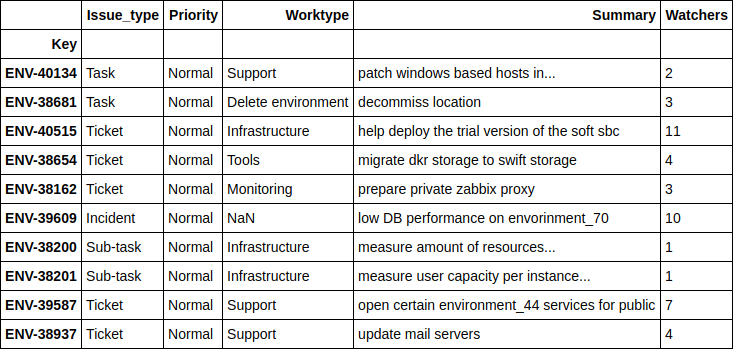
, - , . 4 .
, .
print(((nn_predict + xgb_predict) / 2 - y_holdout).apply(np.abs).sort_values().head(10).values) df.loc[((nn_predict + xgb_predict) / 2 - y_holdout).apply(np.abs).sort_values().head(10).index][['Issue_type', 'Priority', 'Worktype', 'Summary', 'Watchers']]
[ 1.24606014, 2.6723969, 4.51969139, 10.04159236, 11.14335444, 14.4951508, 16.51012874, 17.78445744, 21.56106258, 24.78219295]
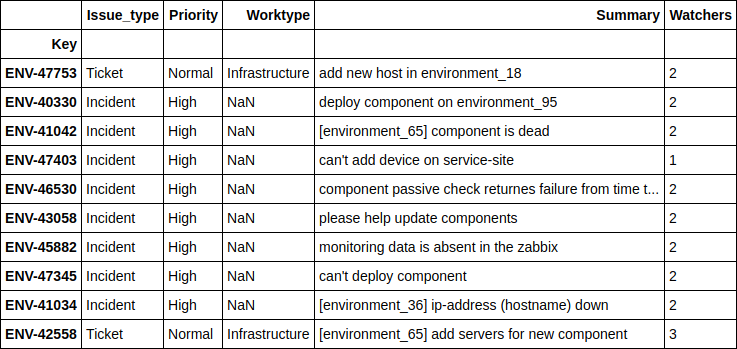
, , - , - . , , , .
Engineer
, 'Engineer', , , ? .
, 2 . , , , , . , , , "" , ( ) , , , . , " ", .
, . , , 12 , ( JQL JIRA):
assignee was engineer_N during (ticket_creation_date) and status was "In Progress"
10783 * 12 = 129396 , … . , , , .. 5 .
, , , , 2 . .
. SLO , .
, , ( : - , - , - ) , .