Creemos un prototipo de agente de aprendizaje de refuerzo (RL) que dominará la habilidad comercial.
Dado que la implementación del prototipo funciona en el lenguaje R, animo a los usuarios y programadores de R a que se acerquen a las ideas presentadas en este artículo.
Esta es una traducción de mi artículo en inglés:
¿Puede el refuerzo de aprendizaje negociar acciones? Implementación en R.Quiero advertir a los cazadores de códigos que en esta nota solo hay un código para una red neuronal adaptada para R.Si no me distinguí en buen ruso, señale los errores (el texto fue preparado con la ayuda de un traductor automático).
Introducción al problema.
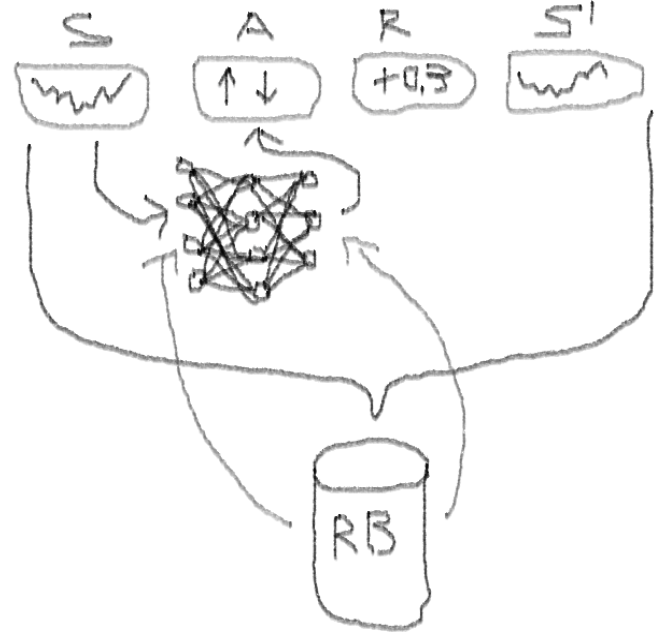
Te aconsejo que comiences a sumergirte en el tema con este artículo:
DeepMindElla le presentará la idea de utilizar la red Q profunda (DQN) para aproximar la función de valor que es crítica en los procesos de toma de decisiones de Markov.
También recomiendo profundizar en las matemáticas utilizando la preimpresión de este libro de Richard S. Sutton y Andrew J. Barto:
aprendizaje por refuerzoA continuación, presentaré una versión extendida del DQN original, que incluye más ideas que ayudan al algoritmo a converger de manera rápida y eficiente, a saber:
Deep Double Dueling Noisy NN con selección de prioridad del búfer de reproducción de experiencia.
¿Qué hace que este enfoque sea mejor que el DQN clásico?
- Doble: hay dos redes, una de las cuales está entrenada y la otra evalúa los siguientes valores de Q
- Duelo: hay neuronas que claramente valoran y benefician
- Ruidoso: hay matrices de ruido aplicadas a los pesos de las capas intermedias, donde las desviaciones medias y estándar son pesos entrenados
- Prioridad de muestreo: los lotes de observación del búfer de reproducción contienen ejemplos, debido a que el entrenamiento previo de funciones condujo a grandes residuos que pueden almacenarse en la matriz auxiliar.
Bueno, ¿qué pasa con el comercio realizado por el agente DQN? Este es un tema interesante como tal.
Hay razones por las que esto es interesante:
- Absoluta libertad de elección de representaciones de estatus, acciones, premios y arquitectura de NN. Puede enriquecer el espacio de entrada con todo lo que considere digno de probar, desde noticias hasta otras acciones e índices.
- La correspondencia de la lógica de negociación con la lógica de aprendizaje de refuerzo es que: el agente realiza acciones discretas (o continuas), rara vez es recompensado (después de que se cierra la transacción o expira el período), el entorno es parcialmente observable y puede contener información sobre los próximos pasos, la negociación es un juego episódico.
- Puede comparar los resultados de DQN con varios puntos de referencia, como índices y sistemas técnicos de negociación.
- El agente puede aprender continuamente nueva información y, por lo tanto, adaptarse a las reglas cambiantes del juego.
Para no estirar el material, mire el código de este NN, que quiero compartir, ya que esta es una de las partes misteriosas de todo el proyecto.
Código R para una red neuronal de valor usando Keras para construir nuestro agente RL
Utilicé esta fuente para adaptar el código de Python para la parte de ruido de la red:
github repoEsta red neuronal se ve así:
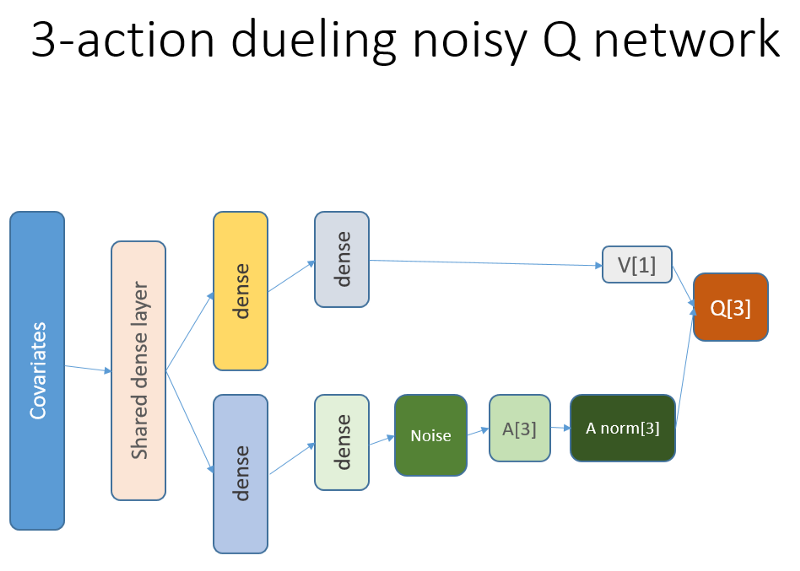
Recordemos que en la arquitectura de duelo usamos igualdad (ecuación 1):
Q = A '+ V, donde
A '= A - promedio (A);
Q = valor de estado-acción;
V = valor del estado;
A = ventaja.
Otras variables en el código hablan por sí mismas. Además, esta arquitectura solo es buena para una tarea específica, por lo que no debe darse por sentado.
El resto del código probablemente será lo suficientemente genérico para su publicación, y será interesante que el programador lo escriba usted mismo.
Y ahora, los experimentos. Las pruebas del trabajo del agente se llevaron a cabo en una caja de arena, lejos de las realidades del comercio en un mercado en vivo, con un corredor real.
Fase I
Ejecutamos nuestro agente contra un conjunto de datos sintético. Nuestro costo de transacción es 0.5:
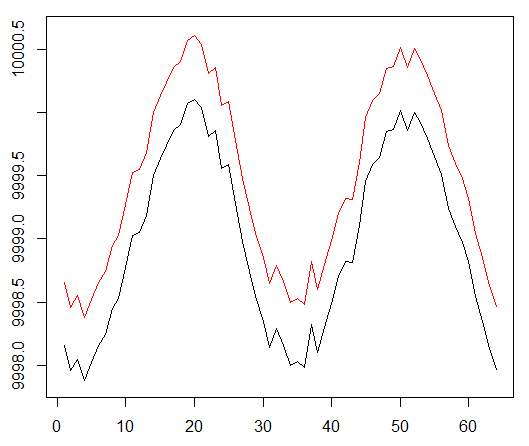
El resultado es excelente. La recompensa episódica promedio máxima en este experimento
debe ser 1.5.
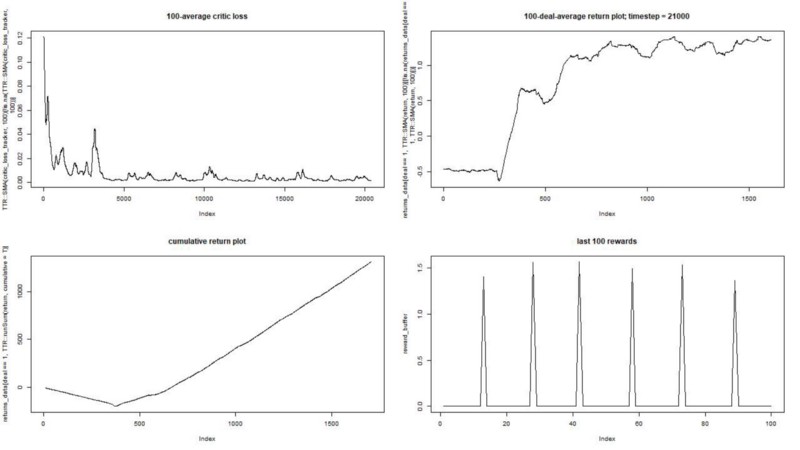
Vemos: pérdida de críticas (la llamada red de valor en el enfoque actor-crítico), recompensa promedio por un episodio, recompensa acumulada, muestra de recompensas recientes.
Fase II
Le enseñamos a nuestro agente un símbolo bursátil elegido arbitrariamente que demuestra un comportamiento interesante: un comienzo plano, un crecimiento rápido en el medio y un final triste. En nuestro kit de entrenamiento unos 4300 días. El costo de la transacción se establece en 0.1 dólares estadounidenses (intencionalmente bajo); La recompensa es USD Ganancias / Pérdidas después de cerrar un acuerdo para comprar / vender 1.0 acciones.
Fuente:
finance.yahoo.com/quote/algn?ltr=1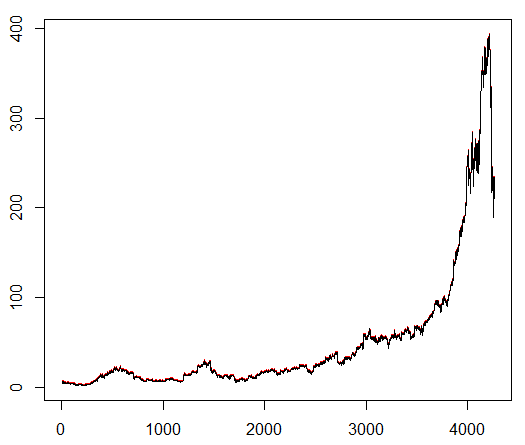 NASDAQ: ALGN
NASDAQ: ALGNDespués de establecer algunos parámetros (dejando la arquitectura NN igual), llegamos al siguiente resultado:

Resultó que no estaba mal, ya que al final el agente aprendió a obtener ganancias presionando tres botones en su consola.
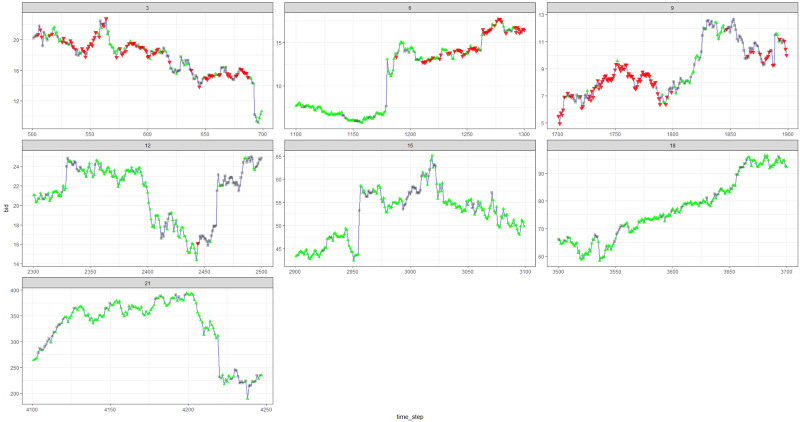 marcador rojo = vender, marcador verde = comprar, marcador gris = no hacer nada.
marcador rojo = vender, marcador verde = comprar, marcador gris = no hacer nada.Tenga en cuenta que en su apogeo, la recompensa promedio por episodio excedió el valor de transacción realista que se puede encontrar en el comercio real.
Es una pena que las acciones estén cayendo como locas debido a las malas noticias ...
Observaciones finales
Comerciar con RL no solo es difícil, sino que también es útil. Cuando su robot lo hace mejor que usted, es hora de pasar su tiempo personal para obtener educación y salud.
Espero que este haya sido un viaje interesante para ti. Si te gustó esta historia, agita tu mano. Si hay mucho interés, puedo continuar y mostrarle cómo funcionan los métodos de gradiente de políticas utilizando el lenguaje R y la API de Keras.
También quiero agradecer a mis amigos que están interesados en las redes neuronales por sus consejos.
Si todavía tienes preguntas, siempre estoy aquí.