Recientemente, el desarrollo web se ha dividido. Ahora no todos somos programadores completos, somos front-end y back-end. Y lo más difícil de esto, como en otros lugares, es el problema de interacción e integración.
El frontend con el backend interactúa a través de la API. Y todo el resultado del desarrollo depende de qué API es, qué tan bueno o malo han acordado el backend y la interfaz. Si todos comenzamos a discutir juntos cómo hacer la actualización, y pasamos todo el día reelaborando, entonces es posible que no lleguemos a las tareas comerciales.
Para no resbalar y generar holivars sobre los nombres de las variables, necesita una buena especificación. Hablemos de cómo debería ser facilitar la vida de todos. Al mismo tiempo, nos convertiremos en expertos en cobertizos para bicicletas.

Comencemos desde lejos, con el problema que estamos resolviendo.
Hace mucho tiempo, en 1959,
Cyril Parkinson (que no debe confundirse con la enfermedad, es escritor y una figura económica) propuso varias leyes interesantes. Por ejemplo, que los gastos crecen con los ingresos, etc. Una de ellas se llama la Ley de la trivialidad:
El tiempo dedicado a discutir el artículo es inversamente proporcional a la cantidad considerada.
Parkinson era economista, por lo que explicó sus leyes en términos económicos, algo así. Si viene a la junta directiva y dice que necesita $ 10 millones para construir una planta de energía nuclear, lo más probable es que este tema se discuta mucho menos que la asignación de 100 libras para un cobertizo de bicicletas para los empleados. Como todos saben cómo construir un cobertizo para bicicletas, todos tienen su propia opinión, todos se sienten importantes y quieren participar, y la planta de energía nuclear es algo abstracto y distante, 10 millones tampoco se han visto nunca; hay menos preguntas.
En 1999, la ley de la trivialidad de Parkinson apareció en la programación, que luego se desarrolló activamente. En programación, esta ley se encontró principalmente en literatura en inglés y sonaba como una metáfora. Se llamaba
el efecto Bikeshed (el efecto de un cobertizo para bicicletas), pero la esencia es la misma: estamos listos para un cobertizo para bicicletas y queremos discutir mucho más que la construcción de una planta de energía.
Este término fue acuñado por el desarrollador danés Poul-Henning Kamp, quien participó en la creación de FreeBSD. Durante el proceso de diseño, el equipo pasó mucho tiempo discutiendo cómo debería funcionar la función del sueño. Esta es una cita de una
carta de Poul-Henning Kamp (el desarrollo se llevó a cabo por correo electrónico):
Fue una propuesta para hacer dormir (1) DTRT Si se le da un argumento no entero que desencadenó este incendio de césped en particular, no voy a decir nada más al respecto que eso, porque es un elemento mucho más pequeño de lo que uno podría esperar de la longitud del hilo, y ya ha recibido mucha más atención que algunos de los * problemas * que tenemos por aquí.
En esta carta, dice que hay muchos problemas sin resolver mucho más importantes: "¡No tratemos con el cobertizo para bicicletas, haremos algo con esto y seguiremos adelante!"
Entonces, Poul-Henning Kamp en 1999 introdujo el término efecto bikeshed en la literatura en inglés, que puede reformularse como:
La cantidad de ruido creado por el cambio en el código es inversamente proporcional a la complejidad del cambio.
Cuanto más simple sea la adición o el cambio que hagamos, más opiniones debemos escuchar al respecto. Creo que muchos se han encontrado con esto. Si resolvemos una pregunta simple, por ejemplo, cómo nombrar variables, no importa para una máquina: esta pregunta causará una gran cantidad de holivares. Pero los problemas serios, realmente importantes para los negocios no se discuten y pasan a un segundo plano.
¿Qué crees que es más importante: cómo nos comunicamos entre el backend y la interfaz, o las tareas comerciales que hacemos? Todos piensan de manera diferente, pero cualquier cliente, una persona que espera que le traigas dinero, dirá: "¡Haz mis tareas comerciales ya!" Absolutamente no le importa cómo transfieres datos entre el backend y el frontend. Quizás ni siquiera sabe lo que son un backend y una interfaz.
Para resumir la introducción, me gustaría decir:
API es un cobertizo para bicicletas.Enlace de presentaciónSobre el orador: Alexey Avdeev (
Avdeev ) trabaja para la empresa Neuron.Digital, que se ocupa de las neuronas y hace una interfaz genial para ellas. Alex también presta atención a OpenSource y aconseja a todos. Ha estado involucrado en el desarrollo durante mucho tiempo: desde 2002, descubrió la antigua Internet, cuando las computadoras eran grandes, Internet era pequeña y la ausencia de JS no molestaba a nadie y a todos inventaban sitios en las mesas.
¿Cómo lidiar con cobertizos para bicicletas?
Después de que el respetado Cyril Parkinson dedujera la ley de la trivialidad, fue muy discutido. Resulta que el efecto de un cobertizo para bicicletas aquí se puede evitar fácilmente:
- No escuches los consejos. Creo que la idea es regular: si no escucha los consejos, puede hacer tal cosa, especialmente en programación, y especialmente si es un desarrollador novato.
- Haz lo que quieras. "Soy un artista, ¡ya lo veo!" - sin efecto bikeshed, todo lo que necesita está hecho, pero aparecen cosas muy extrañas en la salida. Esto a menudo se encuentra en forma independiente. Seguramente te encontraste con tareas que tenías que completar para otros desarrolladores y la implementación de las cuales te causó desconcierto.
- ¿Es importante preguntarte a ti mismo? Si no, simplemente no puede discutirlo, pero es una cuestión de conciencia personal.
- Utiliza criterios objetivos. Hablaré sobre este punto en el informe. Para evitar el efecto de un cobertizo para bicicletas, puede usar criterios que digan objetivamente cuál es mejor. Ellos existen
- No hable de lo que no quiere escuchar consejos. En nuestra compañía, los desarrolladores principiantes de back-end son introvertidos, por lo que sucede que hacen algo de lo que no se lo dicen a otros. Como resultado, nos encontramos con sorpresas. Este método funciona, pero en la programación no es la mejor opción.
- Si no le importa el problema, simplemente puede dejarlo pasar o elegir cualquiera de las opciones propuestas que surgieron en el proceso de holivarov.
Herramienta anti-bikeshedding
Quiero hablar sobre
herramientas objetivas para resolver el problema de un cobertizo para bicicletas. Para demostrar qué es una herramienta anti-bikeshedding, te contaré una pequeña historia.
Imagine que tenemos un desarrollador backend novato. Recientemente llegó a la empresa y se le indicó que diseñara un pequeño servicio, por ejemplo, un blog, para el que debe escribir un protocolo REST.
 Roy Fielding, autor de REST
Roy Fielding, autor de RESTEn la foto, Roy Fielding, quien en el año 2000 defendió su tesis "Estilos arquitectónicos y diseño de arquitecturas de software de red" e introdujo el término REST. Además, inventó HTTP y, de hecho, es uno de los fundadores de Internet.
REST es un conjunto de principios arquitectónicos que dicen cómo diseñar protocolos REST, API REST, servicios RESTful. Estos son principios arquitectónicos bastante abstractos y complejos. Estoy seguro de que ninguno de ustedes ha visto una API hecha completamente de acuerdo con todos los principios RESTful.
Requisitos de arquitectura REST
Daré algunos requisitos para los protocolos
REST , a los que luego me referiré y en los que confiaré. Hay bastantes, puedes leer más sobre esto en Wikipedia.
1.
El modelo cliente-servidor.El principio más importante de REST, es decir, nuestra interacción con el backend. Según REST, el backend es un servidor, el front-end es un cliente y nos comunicamos en un formato cliente-servidor. Los dispositivos móviles también son clientes. Los desarrolladores de relojes, refrigeradores y otros servicios también desarrollan la parte del cliente. La API RESTful es el servidor al que accede el cliente.
2.
Falta de condición.No debe haber estado en el servidor, es decir, todo lo que se necesita para una respuesta viene en la solicitud. Cuando una sesión se almacena en el servidor, y dependiendo de esta sesión, se obtienen diferentes respuestas, esto es una violación del principio REST.
3.
Uniformidad de la interfaz.Este es uno de los principios subyacentes clave sobre los que se debe construir la API REST. Incluye lo siguiente:
- La identificación de recursos es cómo debemos construir una URL. En REST, recurrimos al servidor en busca de algún tipo de recurso.
- Manipulación de recursos mediante presentación. El servidor nos devuelve una vista diferente de la que se encuentra en la base de datos. No importa si almacena la información en MySQL o PostgreSQL, tenemos una vista.
- Mensajes de autodescripción, es decir, el mensaje contiene id, enlaces donde puede obtener este mensaje nuevamente, todo lo que se necesita para trabajar con este recurso nuevamente.
- Hypermedia es un enlace a las siguientes acciones con un recurso. Me parece que ni una sola API REST lo hace, pero Roy Fielding lo describe.
Hay 3 principios más que no cito porque no son importantes para mi historia.
Blog RESTful
Volver al desarrollador backend inicial, a quien se le pidió que hiciera un servicio para el blog en RESTful. A continuación se muestra un ejemplo de un prototipo.
Este es un sitio en el que hay artículos, puede comentar sobre ellos, el artículo y los comentarios tienen un autor, una historia estándar. Nuestro desarrollador backend novato hará una API RESTful para este blog.
Trabajamos con todos los datos del blog sobre la base de
CRUD .
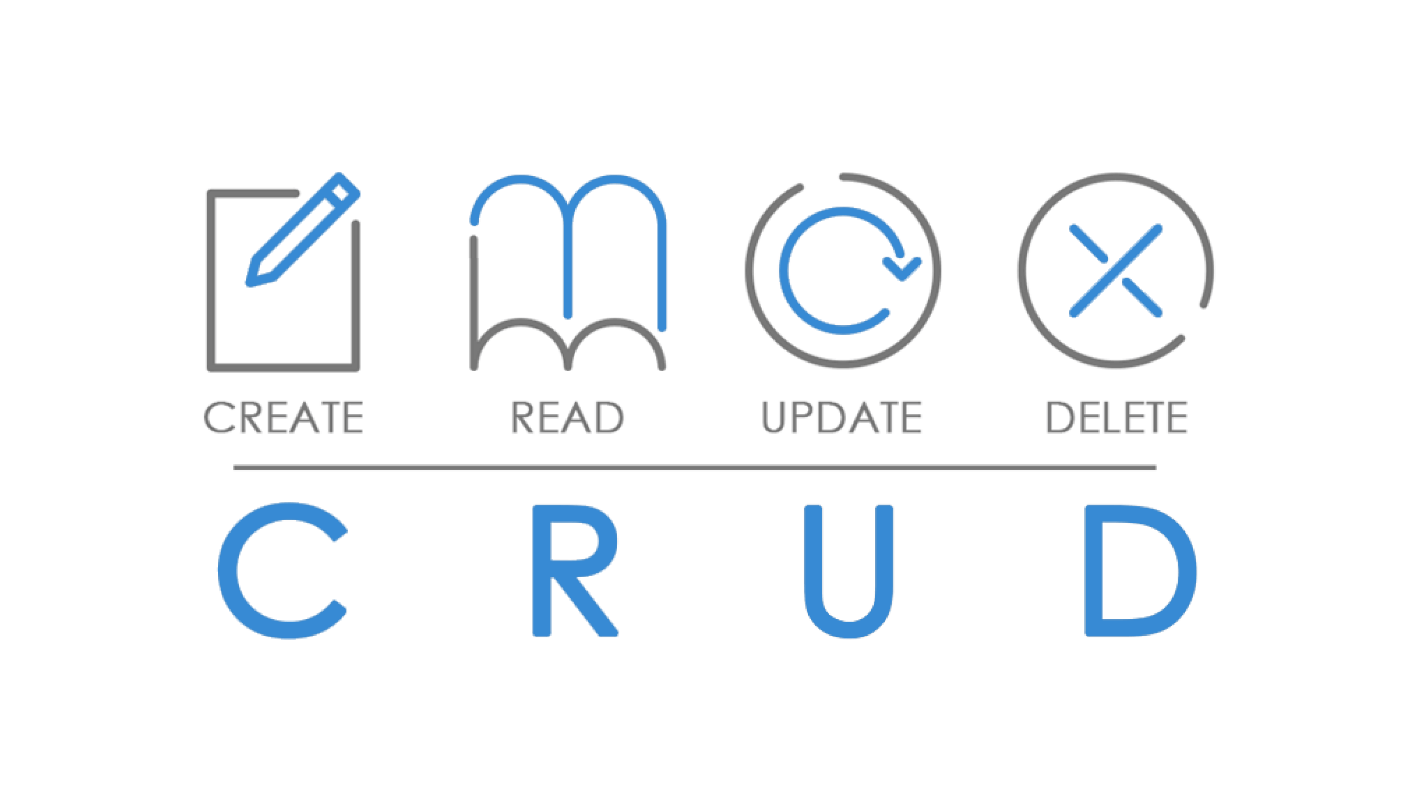
Debería ser posible crear, leer, actualizar y eliminar cualquier recurso. Intentemos pedirle a nuestro desarrollador de back-end que cree un AP RESTful basado en el principio de CRUD. Es decir, escribir métodos para crear artículos, obtener una lista de artículos o un solo artículo, actualizar y eliminar.
Veamos cómo pudo hacerlo.
 Aquí todo está mal con respecto a todos los principios de REST
Aquí todo está mal con respecto a todos los principios de REST . Lo más interesante es que funciona. De hecho, obtuve API que se veían así. Para el cliente es un cobertizo para bicicletas, para los desarrolladores es una ocasión para relajarse y discutir, y para un desarrollador novato es solo un mundo enorme y valiente en el que tropieza cada vez, cae, se golpea la cabeza. Tiene que rehacerlo una y otra vez.

Esta es una opción REST. Con base en los principios de identificación de recursos, trabajamos con recursos, con artículos y utilizamos los métodos HTTP que propuso Roy Fielding. No pudo evitar usar su trabajo anterior en su próximo trabajo.
Para actualizar artículos, muchos usan el método PUT; tiene una semántica ligeramente diferente. El método PATCH actualiza los campos que se pasaron y el PUT simplemente reemplaza un artículo por otro. Por semántica, PATCH se fusiona y PUT se reemplaza.
Nuestro desarrollador backend novato se cayó, lo recogieron y dijeron: "Todo está en orden, hazlo así", y honestamente lo rehizo. Pero luego encontrará un gran camino a través de las espinas.
¿Por qué es tan correcto?- porque Roy Fielding lo dijo;
- porque es REST;
- porque estos son los principios arquitectónicos en los que se basa nuestra profesión ahora.
Sin embargo, este es un "cobertizo para bicicletas", y el método anterior funcionará. Las computadoras se comunicaron antes de REST, y todo funcionó. Pero ahora ha aparecido un estándar en la industria.
Eliminar el articulo
Considere el ejemplo de eliminar un artículo. Supongamos que hay un método de recurso normal DELETE / articles, que elimina el artículo por id. HTTP contiene encabezados. El encabezado Aceptar acepta el tipo de datos que el cliente desea recibir en respuesta. Nuestro junior escribió un servidor que devuelve 200 OK, Content-Type: application / json, y pasa un cuerpo vacío:
01. DELETE /articles/ 1 /1.1
02. Accept: application/json01. HTTP/1.1 200 OK
02. Content-Type: application/json
03. null
Aquí se ha cometido un error muy
común: un cuerpo vacío . Todo parece ser lógico: el artículo se ha eliminado, 200 OK, el encabezado de la aplicación / json está presente, pero lo más probable es que el cliente se caiga. Lanzará un error porque un cuerpo vacío no es válido. Si alguna vez has intentado analizar una cadena vacía, entonces te enfrentas al hecho de que cualquier analizador json tropieza y falla.
¿Cómo arreglar esta situación? Probablemente la mejor opción es pasar json. Si dijimos: "Aceptar, danos json", el servidor dice: "Tipo de contenido, te doy json", da json. Un objeto vacío, una matriz vacía, coloque algo allí, esta será la solución y funcionará.
Todavía hay una solución. Además de 200 OK, hay un código de respuesta 204: sin contenido. Con él, no puedes transmitir el cuerpo. No todos saben sobre esto.
Así que conduje a los tipos de medios.
Tipos de mimo
Los tipos de medios son como una extensión de archivo, solo en la web. Cuando transmitimos datos, debemos informar o solicitar qué tipo de respuesta queremos recibir.
- Por defecto, esto es texto / simple, solo texto.
- Si no se especifica nada, lo más probable es que el navegador signifique aplicación / flujo de octetos, solo un flujo de bits.
Puede especificar solo un tipo específico:
- aplicación / pdf;
- imagen / png;
- aplicación / json;
- aplicación / xml;
- application / vnd.ms-excel.
Los encabezados Content-Type y Accept son y son importantes.
La API y el cliente deben pasar los encabezados Content-Type y Accept.
Si su API está construida en JSON, siempre pase Aceptar: aplicación / json y Aplicación de tipo de contenido / json.
Tipos de archivos de ejemplo.

Los tipos de medios son similares a estos tipos de archivos, solo en Internet.
Códigos de respuesta
El siguiente ejemplo de las aventuras de nuestro desarrollador junior son los códigos de respuesta.

La tasa de respuesta más divertida es 200 OK. Todos lo aman, significa que todo salió bien. Incluso tuve un caso: recibí
errores 200 OK . Algo realmente cayó en el servidor, en respuesta a la respuesta llega una página HTML en la que se ha compilado un error HTML. Solicité una aplicación json con el código 200 OK, y pensé cómo trabajar con ella. Vas por respuesta, buscas la palabra "error", crees que esto es un error.
Esto funciona, sin embargo, en HTTP hay muchos otros códigos que puede usar, y REST recomienda que los use en REST. Por ejemplo, la creación de una entidad (artículo) se puede responder:
- 201 Created es un código exitoso. Se crea el artículo, en respuesta necesita devolver el artículo creado.
- 202 Aceptado significa que la solicitud ha sido aceptada, pero su resultado será posterior. Estas son operaciones de larga duración. En Aceptado, ningún cuerpo puede ser devuelto. Es decir, si no proporciona el Tipo de contenido en la respuesta, entonces el cuerpo también puede no estarlo. O texto / plano de tipo contenido: eso es todo, sin preguntas. Una cadena vacía es un texto / plano válido.
- 204 Sin contenido : el cuerpo puede estar completamente ausente.
- 403 Prohibido : no puede crear este artículo.
- 404 Not Found : subiste a algún lugar equivocado, por ejemplo, no existe tal cosa.
- 409 El conflicto es un caso extremo que pocas personas usan. A veces es necesario si está generando una identificación en el cliente, y no en el backend, y en ese momento alguien ya logró crear este artículo. El conflicto es la respuesta correcta en este caso.
Creación de entidad
El siguiente ejemplo: creamos una entidad, digamos Content-Type: application / json, y pasamos esta aplicación / json. Esto convierte al cliente en nuestro frontend. Creemos este mismo artículo:
01. POST /articles /1.1
02. Content-Type: application/json
03. { "id": 1, "title": " JSON API"}El código puede venir en respuesta:
- 422 Entidad no procesable: una entidad no procesada. Todo parece ser genial: semántica, hay código;
- 403 prohibido
- 500 Error interno del servidor.
Pero es absolutamente incomprensible lo que sucedió exactamente: qué tipo de entidad no se procesa, ¿por qué no debería ir allí y qué pasó finalmente con el servidor?
Errores de retorno
Asegúrate (y los junior no saben sobre esto) en respuesta, devuelve errores. Esto es semántico y correcto. Por cierto, Fielding no escribió sobre esto, es decir, fue inventado más tarde y construido sobre REST.
El backend puede devolver una matriz con errores en respuesta, puede haber varios.
01. HTTP/1.1 422 Unprocessable Entity
02. Content-Type: application/json
03.
04. { "errors": [{
05. "status": "422",
06. "title": "Title already exist",
07. }]}Cada error puede tener su propio estado y título. Esto es genial, pero ya va al nivel de la convención además de REST. Esta podría ser nuestra herramienta anti-bikeshedding para dejar de discutir y hacer una buena API correcta de inmediato.
Agregar paginación
El siguiente ejemplo: los diseñadores se acercan a nuestro desarrollador backend inicial y dicen: “Tenemos muchos artículos, necesitamos paginación. Dibujamos este ".

Consideremos con más detalle. En primer lugar, 336 páginas son sorprendentes. Cuando vi esto, pensé en cómo obtener esta cifra. Dónde obtener 336, porque cuando solicito una lista de artículos obtengo una lista de artículos. Por ejemplo, hay 10 mil de ellos, es decir, necesito descargar todos los artículos, dividirlos por el número de páginas y averiguar este número. Durante mucho tiempo cargaré estos artículos, necesito una forma de obtener el número de entradas rápidamente. Pero si nuestra API devuelve una lista, entonces dónde colocar este número de registros en general, porque una serie de artículos viene en respuesta. Resulta que, dado que el número de registros no se coloca en ningún lado, debe agregarse a cada artículo para que cada artículo diga: "¡Y hay tantos de nosotros!"
Sin embargo, existe una convención sobre la API REST que resuelve este problema.
Solicitud de lista
Para hacer que la API sea extensible, puede usar de inmediato los parámetros GET para la paginación: el tamaño de la página actual y su número, de modo que se nos devuelva exactamente la parte de la página que solicitamos. Esto es conveniente En respuesta, no puede dar inmediatamente una matriz, sino agregar anidamiento adicional. Por ejemplo, la clave de datos contendrá una matriz, los datos que solicitamos y la metaclave, que no estaba allí antes, contendrá el total.
01. GET /articles? page[size]=30&page[number]=2
02. Content-Type: application/json
01. HTTP/1.1 200 OK
02. {
03. "data": [{ "id": 1, "title": "JSONAPI"}, ...],
04. "meta": { "count": 10080 }
05. }
De esta manera, la API puede devolver información adicional. Además de contar, puede haber otra información: es extensible. Ahora, si el junior no lo hizo de inmediato, y solo después de que se le pidió que hiciera la pajinización,
hizo el cambio incompatible hacia atrás , rompió la API y todos los clientes tuvieron que rehacerlo, generalmente duele mucho.
La pajinización es diferente. Ofrezco varios trucos de vida que puedes usar.
[desplazamiento] ... [límite]
01. GET /articles? page[offset]=30&page[limit]=30
02. Content-Type: application/json
01. HTTP/1.1 200 OK
02. {
03. "data": [{ "id": 1, "title": "JSONAPI"}, ...],
04. "meta": { "count": 10080 }
05. }
Quienes trabajan con bases de datos ya pueden tener una subcorteza [offset] ... [limit]. Usarlo en lugar de página [tamaño] ... página [número] será más fácil. Este es un enfoque ligeramente diferente.
Posicionamiento del cursor
01. GET /articles? page[published_at]=1538332156
02. Content-Type: application/json01. HTTP/1.1 200 OK
02. {
03. "data": [{ "id": 1, "title": "JSONAPI"}, ...],
04. "meta": { "count": 10080 }
05. }La ubicación del cursor utiliza un puntero a la entidad con la que comenzar a cargar registros. Por ejemplo, es muy conveniente cuando usa paginación o carga en listas que cambian con frecuencia. Digamos que constantemente se escriben nuevos artículos en nuestro blog. La tercera página ahora no es la misma tercera página que estará en un minuto, pero si vamos a la cuarta página, obtendremos algunos registros de la tercera página, porque toda la lista se moverá.
Este problema se resuelve con la paginación del cursor. Decimos: "Cargue los artículos que vienen después del artículo publicado en ese momento" - ya no puede haber cambio puramente tecnológicamente, y esto es genial.
Problema N +1
El siguiente problema que nuestro desarrollador junior definitivamente encontrará es el problema N + 1 (los backenders lo entenderán). Suponga que desea enumerar una lista de 10 artículos. Subimos una lista de artículos, cada artículo tiene un autor, y para cada uno necesita descargar un autor. Enviamos:
- 1 solicitud de una lista de artículos;
- 10 solicitudes para los autores de cada artículo.
Total: 11 consultas para mostrar una pequeña lista.
Agregar enlaces
En el backend, este problema se resuelve en todos los ORM; solo debe recordar agregar esta conexión. Estas conexiones también se pueden usar en el extremo frontal. Esto se hace de la siguiente manera:
01. GET /articles? include =author
02. Content-Type: application/json
Puede usar un parámetro GET especial, llámelo include (como en el backend), indicando qué enlaces debemos cargar junto con los artículos. Supongamos que cargamos artículos y queremos obtener de inmediato al autor junto con los artículos. La respuesta se ve así:
01. /1.1 200
02. { "data": [{
03. { attributes: { "id": 1, "title": "JSON API" },
04. { relationships: {
05. "author": { "id": 1, "name": "Avdeev" } }
06. }, ...
07. }]}Los atributos del artículo propio se transfirieron a los datos y se agregaron las relaciones clave. Ponemos todas las conexiones en esta clave. Por lo tanto, con una solicitud, recibimos todos los datos que anteriormente recibían 11 solicitudes. Este es un truco de vida genial que resuelve bien el problema con N + 1 en el extremo frontal.
El problema de la duplicación de datos.
Suponga que desea mostrar 10 artículos que indican el autor, todos los artículos tienen un autor, pero el objeto con el autor es muy grande (por ejemplo, un apellido muy largo, que toma un megabyte). Se incluye un autor en la respuesta 10 veces, y 10 inclusiones del mismo autor en la respuesta tomarán 10 MB.
Como todos los objetos son iguales, el problema de que un autor se incluya 10 veces (10 MB) se resuelve con la ayuda de la normalización, que se utiliza en las bases de datos. En la parte frontal, también puede usar la normalización al trabajar con la API; esto es muy bueno.
01. /1.1 200
02. { "data": [{
03. "id": "1″, "type": "article",
04. "attributes": { "title": "JSON API" },
05. "relationships": { ... }
06. "author": { "id": 1, "type": "people" } }
07. }, ... ]
08. }Marcamos todas las entidades con algún tipo (este es un tipo de representación, un tipo de recurso). Roy Fielding introdujo el concepto de un recurso, es decir, solicitaron artículos, recibieron un "artículo". En las relaciones, ponemos un enlace al tipo de personas, es decir, todavía tenemos el recurso de personas en otro lugar. Y el recurso en sí lo tomamos en una clave separada incluida, que se encuentra en el mismo nivel que los datos.
01. /1.1 200
02. {
03. "data": [ ... ],
04. "included": [{
05. "id": 1, "type": "people",
06. "attributes": { "name": "Avdeev" }
07. }]
08. }Por lo tanto, todas las entidades relacionadas en una sola instancia caen en la clave especial incluida. Solo almacenamos enlaces, y las entidades mismas se almacenan incluidas.
Tamaño de solicitud disminuido. Este es un truco de vida sobre el que el back-end no sabe. Lo descubrirá más tarde cuando necesite romper la API.
No todos los campos de recursos son necesarios
El siguiente truco de vida se puede aplicar cuando no se necesitan todos los campos de recursos. Esto se realiza utilizando un parámetro GET especial, que enumera los atributos que se devolverán, separados por comas. Por ejemplo, el artículo es grande, y puede haber megabytes en el campo de contenido, y necesitamos mostrar solo la lista de encabezados; no necesitamos el contenido en la respuesta.
GET /articles ?fields[article]=title /1.101. /1.1 200 OK
02. { "data": [{
03. "id": "1″, "type": "article",
04. "attributes": { "title": " JSON API" },
05. }, ... ]
06. }Si necesita, por ejemplo, también la fecha de publicación, puede escribir una "fecha de publicación" separada por comas. En respuesta, dos campos vendrán en atributos. Esta es una convención que se puede usar como una herramienta anti-bikeshedding.
Buscar por articulos
A menudo necesitamos búsquedas y filtros. Hay convenciones para esto: filtros especiales para obtener parámetros:
●
GET /articles ?filters[search]=api HTTP/1.1 - buscar;
●
GET /articles ?fiIters[from_date]=1538332156 HTTP/1.1 - descargue artículos desde una fecha específica;
●
GET /articles ?filters[is_published]=true HTTP/1.1 : descargue los artículos que se acaban de publicar;
●
GET /articles ?fiIters[author]=1 HTTP/1.1 - descargue artículos con el primer autor.
Ordenar artículos
●
GET /articles ?sort=title /1.1 - por título;
●
GET /articles ?sort=published_at HTTP/1.1 - por fecha de publicación;
●
GET /articles ?sort=-published_at HTTP/1.1 - por fecha de publicación en la dirección opuesta;
●
GET /articles ?sort=author,-publisbed_at HTTP/1.1 : primero por autor, luego por fecha de publicación en la dirección opuesta, si los artículos son del mismo autor.
Necesito cambiar las URL
Solución: hipermedia, que ya mencioné, se puede hacer de la siguiente manera. Si queremos que el objeto (recurso) se describa a sí mismo, el cliente podría entender a través de hipermedia lo que se puede hacer con él, y el servidor podría desarrollarse independientemente del cliente, entonces podemos agregar enlaces a la lista de artículos, al artículo mismo usando teclas de enlaces especiales :
01. GET /articles /1.1
02. {
03. "data": [{
04. ...
05. "links": { "self": "http://localhost/articles/1" },
06. "relationships": { ... }
07. }],
08. "links": { "self": " http://localhost/articles " }
09. }
O relacionado, si queremos decirle al cliente cómo cargar un comentario en este artículo:
01. ...
02. "relationships": {
03. "comments": {
04. "links": {
05. "self": "http://localhost/articles/l/relationships/comments ",
06. "related": " http://localhost/articles/l/comments "
07. }
08. }
09. }El cliente ve que hay un enlace, lo sigue, carga un comentario. Si no hay un enlace, entonces no hay comentarios. Esto es conveniente, pero muy pocos lo hacen. Fielding presentó los principios de REST, pero no todos ingresaron a nuestra industria. Utilizamos principalmente dos o tres.
En 2013, todos los trucos de la vida que te conté, Steve Klabnik se combinaron en la especificación JSON API y se registraron como un
nuevo tipo de medio además de JSON . Entonces, nuestro desarrollador backend junior, que evolucionó gradualmente, llegó a la API JSON.
API JSON
Todo se describe en detalle en
http://jsonapi.org/implementations/ : incluso hay una lista de 170 implementaciones de especificaciones diferentes para 32 lenguajes de programación, y estas solo se agregan al catálogo. Ya se han escrito bibliotecas, analizadores, serializadores, etc.
Dado que esta especificación es de código abierto, todos están invirtiendo en ella. Yo, entre otras cosas, escribí algo yo mismo. Estoy seguro de que hay muchas personas así. Puedes unirte a este proyecto tú mismo.
JSON API Pros
La especificación JSON API resuelve una serie de problemas, un
acuerdo común para todos . Como existe un acuerdo general,
no discutimos dentro del equipo : el cobertizo para bicicletas está documentado. Tenemos un acuerdo sobre qué materiales hacer un cobertizo para bicicletas y cómo pintarlo.
Ahora, cuando el desarrollador hace algo mal y lo veo, no comienzo la discusión, pero digo: "¡No por la API JSON!" y mostrar en su lugar en la especificación. Me odian en la empresa, pero poco a poco se acostumbraron, y a todos les empezó a gustar la API JSON. Hacemos nuevos servicios predeterminados de acuerdo con esta especificación. Tenemos una clave de fecha, estamos listos para agregar meta, incluir claves. Hay filtros de parámetros GET reservados para filtros. No discutimos cómo llamar a un filtro; utilizamos esta especificación. Describe cómo hacer una URL.
Como no estamos discutiendo, sino haciendo tareas comerciales, la
productividad del desarrollo es mayor . Tenemos las especificaciones descritas, el desarrollador leyó el backend, creó la API, la atornillamos: el cliente está contento.
Los problemas populares ya se han resuelto , por ejemplo, con la paginación. Hay muchas pistas en la especificación.
Como se trata de JSON (gracias a Douglas Crockford por este formato), es más conciso que XML, es bastante
fácil de leer y comprender .
El hecho de que esto sea
Open Source puede ser tanto un plus como un menos, pero me encanta Open Source.
Contras API JSON
El objeto ha crecido (fecha, atributos, incluidos, etc.): la
interfaz necesita analizar las respuestas: poder iterar sobre las matrices, recorrer el objeto y saber cómo funciona la reducción. No todos los desarrolladores novatos conocen estas cosas complejas. Hay bibliotecas de serializadores / deserializadores, puede usarlos. En general, esto solo funciona con datos, pero los objetos son grandes.
Y el
motor tiene dolor:
- Control de anidamiento: incluir se puede escalar muy lejos;
- La complejidad de las consultas de la base de datos: a veces se crean automáticamente y resultan muy difíciles;
- Seguridad: puedes subir a la jungla, especialmente si conectas algún tipo de biblioteca;
- La especificación es difícil de leer. Ella está en inglés y asustó a algunos, pero poco a poco todos se acostumbraron;
- No todas las bibliotecas implementan bien la especificación; este es un problema de código abierto.
Errores JSON API
Un poco de hardcore.
El número de relaciones en el tema no está limitado. Si incluimos, solicitamos artículos, agregamos comentarios a ellos, en respuesta recibiremos todos los comentarios de este artículo. Hay 10,000 comentarios - obtenga todos los 10,000 comentarios:
GET /articles/1?include=comments /1.101. ...
02. "relationships": {
03. "comments": {
04. "data": [0 ... ∞]
05. }
06. }Por lo tanto, en realidad 5 MB llegaron a nuestra solicitud en respuesta: "Está escrito en la especificación; es necesario reformular la solicitud correctamente:
GET /comments? filters[article]=1& page[size]=30 HTTP/1.101. {
02. "data": [0 ... 29]
03. }Solicitamos comentarios con un filtro por artículo, diga: "30 piezas, por favor" y obtenga 30 comentarios. Esto es ambigüedad.
Las mismas cosas pueden formularse de manera ambigua :
●
GET /articles/1 ?include=comments HTTP/1.1 : solicite un artículo con comentarios;
●
GET /articles/1/comments HTTP/1.1 : solicite comentarios sobre el artículo;
●
GET /comments ?filters[article]=1 HTTP/1.1 - solicita comentarios con un filtro por artículo.
Este es uno y el mismo: los mismos datos, que se obtienen de diferentes maneras, hay cierta ambigüedad. Este escollo no es inmediatamente visible.
Las relaciones polimórficas de uno a muchos se arrastran a REST muy rápidamente.
01. GET /comments?include=commentable /1.1
02.
03. ...
04. "relationships": {
05. "commentable" : {
06. "data": { "type": "article", "id": "1″ }
07. }
08. }Hay una conexión polimórfica comentable en el backend: se arrastra hacia REST. Entonces debería suceder, pero se puede disfrazar. No puedes disfrazarlo en la API JSON: saldrá a la luz.
Complejas relaciones de muchos a muchos con opciones avanzadas . Además, salen todas las tablas de conexión:
01. GET /users?include =users_comments /1.1
02.
03. ...
04. "relationships": {
05. "users_comments": {
06. "data": [{ "type": "users_comments", "id": "1″ }, ...]
07. },
08. }Swagger
Swagger es una herramienta de escritura de documentación en línea.
Digamos que se le pidió a nuestro desarrollador de backend que escribiera documentación para su API, y él la escribió. Esto es fácil si la API es simple. Si se trata de una API JSON, Swagger no se puede escribir tan fácilmente.
Ejemplo: tienda de mascotas Swagger. Cada método se puede abrir, ver respuesta y ejemplos.
Este es un ejemplo de un modelo de mascota. Aquí hay una interfaz genial, todo es fácil de leer.
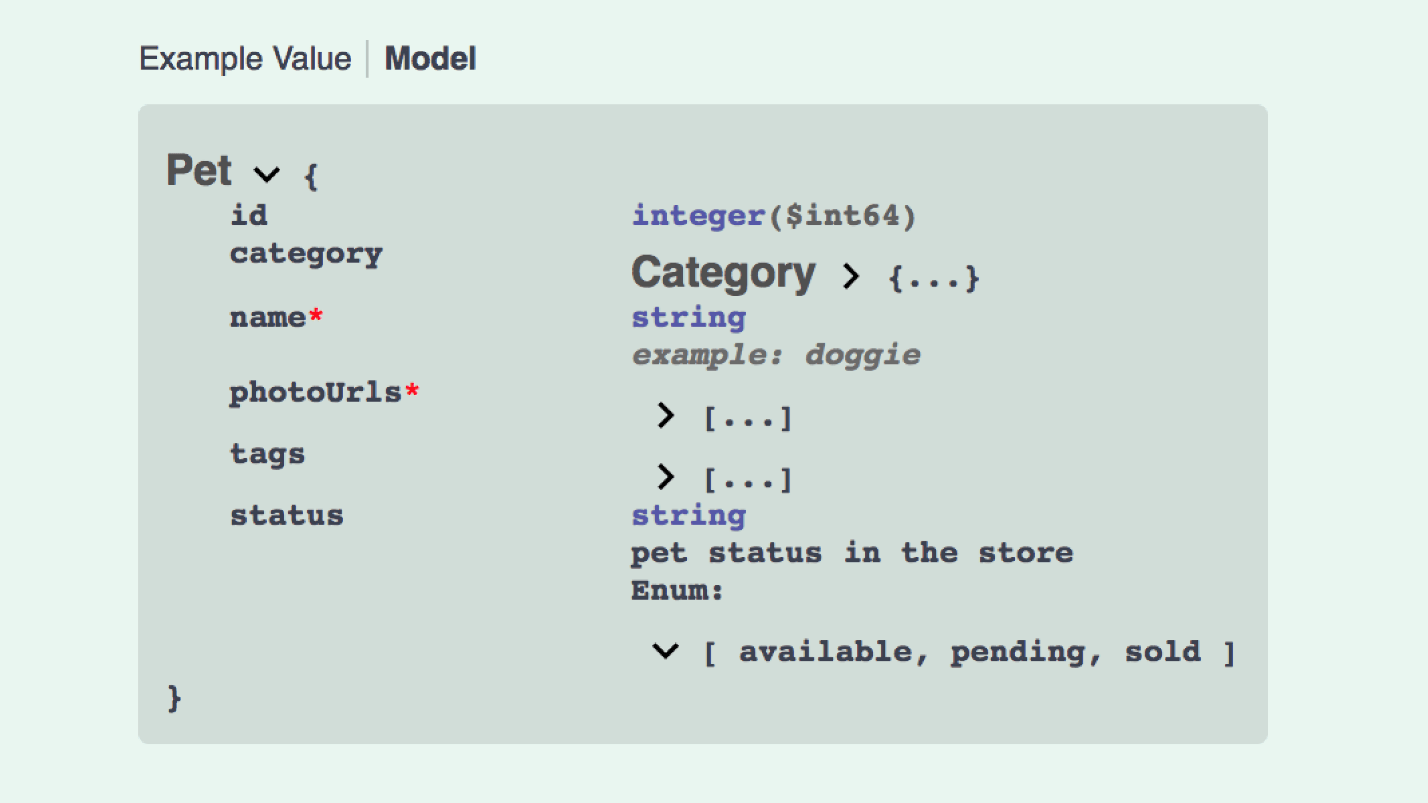
Y así es como se ve la creación del modelo API JSON:

Esto no es tan bueno. Necesitamos datos, en datos algo con relaciones, incluido contiene 5 tipos de modelos, etc. Puedes escribir Swagger, la API abierta es algo poderoso, pero complicado.
Alternativa
Hay una especificación OData, que apareció un poco más tarde, en 2015. Esta es "La mejor manera de DESCANSAR", como asegura el sitio web oficial. Se ve así:
01. GET http://services.odata.org/v4/TripRW/People HTTP/1.1 - Solicitud GET;
02. OData-Version: 4.0 - encabezado especial con versión;
03. OData-MaxVersion: 4.0 - Segundo encabezado de versión especial
La respuesta se ve así:
01. HTTP/1.1 200 OK
02. Content-Type: application/json; odata.metadata=minimal
03. OData-Version: 4.0
04. {
05. '@odata.context': 'http://services.odata.org/V4/
06. '@odata.nextLink' : 'http://services.odata.org/V4/
07. 'value': [{
08. '@odata.etag': 1W/108D1D5BD423E51581′,
09. 'UserName': 'russellwhyte',
10. ...
Aquí está la aplicación extendida / json y el objeto.
No usamos OData, en primer lugar, ya que es lo mismo que la API JSON, pero no es conciso. Hay objetos enormes y me parece que todo es mucho peor de leer. OData también salió en código abierto, pero es más complicado.
¿Qué hay de GraphQL?
Naturalmente, cuando estábamos buscando un nuevo formato de API, nos encontramos con esta exageración.
●
Umbral de entrada alto.Desde el punto de vista de la interfaz, todo parece genial, pero no puede hacer que el nuevo desarrollador escriba GraphQL, porque primero debe estudiarlo. Es como SQL: no puede escribir SQL inmediatamente, al menos debe leer lo que es, seguir los tutoriales, es decir, el umbral de entrada aumenta.
●
El efecto del big bang.Si no había API en el proyecto y comenzamos a usar GraphQL, después de un mes nos dimos cuenta de que no nos conviene, será demasiado tarde. Tienes que escribir muletas. Puede evolucionar con JSON API u OData: el RESTful más simple, que mejora progresivamente, se convierte en una API JSON.
●
Infierno en el backend.GraphQL llama al infierno en el backend, uno a uno, al igual que la API JSON completamente implementada, porque GraphQL obtiene el control total sobre las consultas, y esta es una biblioteca, y deberá resolver un montón de preguntas:
- control de anidamiento;
- recursividad
- limitación de frecuencia;
- control de acceso.
En lugar de conclusiones
Recomiendo dejar de discutir sobre el cobertizo de la bicicleta, y tomar la herramienta anti-bikeshedding como especificación y simplemente hacer una API con una buena especificación.
Para encontrar su estándar para resolver el problema de un cobertizo para bicicletas, puede consultar estos enlaces:
●
http://jsonapi.org●
http://www.odata.org●
https://graphgl.org●
http://xmlrpc.scripting.com●
https://www.jsonrpc.org: alexey-avdeev.com github .
, Frontend Conf , 27 28 ++ . , .
? ? ? , ? !
, , , , .