Parece que estamos tan profundamente inmersos en la jungla del desarrollo de alta carga que simplemente no pensamos en los problemas básicos. Tomemos, por ejemplo, fragmentos. Qué entender si es posible escribir fragmentos condicionalmente = n en la configuración de la base de datos y todo se hará solo. Así es como es, pero si, más bien, cuando algo sale mal, los recursos comienzan a ser realmente escasos, me gustaría entender cuál es la razón y cómo solucionarlo.
En resumen, si estaba contribuyendo con su implementación alternativa de hash en Cassandra, casi no hay revelaciones para usted. Pero si la carga de sus servicios ya está llegando y el conocimiento del sistema no se mantiene al día, entonces será bienvenido. El gran y terrible
Andrei Aksyonov (
shodan ) en su forma habitual dirá que el
fragmentado es malo, no el fragmentado también es malo y cómo se organiza en el interior. Y por casualidad, una de las partes de la historia sobre los fragmentos no es realmente acerca de los fragmentos, sino que el diablo sabe qué: cómo asignar objetos a fragmentos.

La foto de las focas (aunque accidentalmente resultaron ser cachorros) ya parece responder a la pregunta de por qué esto es todo, pero comencemos en secuencia.
¿Qué es el fragmentación?
Si persiste en google, resulta que hay un borde bastante borroso entre la llamada partición y el llamado fragmentación. Todos llaman todo lo que quiere de lo que quiere. Algunas personas distinguen entre particionamiento horizontal y fragmentación. Otros dicen que el fragmentación es un cierto tipo de partición horizontal.
No encontré un solo estándar terminológico que fuera aprobado por los padres fundadores y certificado en ISO. Una creencia interna personal es algo como esto:
Particionar en promedio es "cortar la base en pedazos" de una manera arbitraria.
- Particionamiento vertical Por ejemplo, hay una tabla gigante con un par de miles de millones de entradas en 60 columnas. En lugar de mantener una de esas tablas gigantescas, mantenemos 60 tablas no menos gigantescas con 2 mil millones de registros cada una, y esto no es a tiempo parcial, sino a una partición vertical (como ejemplo de terminología).
- Particionamiento horizontal : cortamos línea por línea, tal vez dentro del servidor.
El momento incómodo aquí es la sutil diferencia entre particionamiento horizontal y fragmentación. Puedes cortarme en pedazos, pero no te diré con certeza en qué consiste. Existe la sensación de que el fragmentación y la división horizontal son casi lo mismo.
El fragmentación es en general cuando una tabla grande en términos de bases de datos o una colección de documentos, objetos, si no tiene una base de datos, sino un almacén de documentos, se corta específicamente para objetos. Es decir, se seleccionan piezas de 2 mil millones de objetos, sin importar su tamaño. Los objetos por sí mismos dentro de cada objeto no se cortan en pedazos, no se descomponen en columnas separadas, es decir, colocamos paquetes en diferentes lugares.
Enlace a la presentación para completar.Ya se han producido sutiles diferencias terminológicas. Por ejemplo, en términos relativos, los desarrolladores de Postgres pueden decir que el particionamiento horizontal es cuando todas las tablas en las que se divide la tabla principal se encuentran en el mismo esquema, y cuando en máquinas diferentes se fragmenta.
En un sentido general, sin estar atados a la terminología de una base de datos específica y un sistema de gestión de datos específico, existe la sensación de que el fragmentación es solo cortar línea por línea y así sucesivamente, y eso es todo:
Sharding (~ =, \ in ...) La partición horizontal == es típica.
Destaco, típicamente. En el sentido de que hacemos todo esto no solo para cortar 2 mil millones de documentos en 20 tablas, cada uno de los cuales sería más manejable, sino para distribuirlo en muchos núcleos, muchos discos o muchos servidores físicos o virtuales diferentes .
Se entiende que estamos haciendo esto para que cada fragmento, cada shatka de datos, se replique muchas veces. Pero en realidad no.
INSERT INTO docs00 SELECT * FROM documents WHERE (id%16)=0 ... INSERT INTO docs15 SELECT * FROM documents WHERE (id%16)=15
De hecho, si realiza tal corte de datos, y desde una tabla SQL gigante en MySQL, generará 16 tablas pequeñas en su valiente computadora portátil, sin ir más allá de una sola computadora portátil, ni un solo esquema, ni una sola base de datos, etc. etc. - todo, ya tienes fragmentos.
Recordando la ilustración con cachorros, esto lleva a lo siguiente:
- El ancho de banda está aumentando.
- La latencia no cambia, es decir, cada uno, por así decirlo, trabajador o consumidor en este caso, obtiene el suyo. No se sabe qué cachorros aparecen en la imagen, pero las solicitudes se atienden casi al mismo tiempo, como si el cachorro estuviera solo.
- O ambos, y otro, y todavía alta disponibilidad (replicación).
¿Por qué ancho de banda? A veces podemos tener esos volúmenes de datos que no encajan, no está claro dónde, pero no encajan, por 1 {core | conducir | servidor | ...}. Simplemente no hay suficientes recursos y eso es todo. Para trabajar con este gran conjunto de datos, debe cortarlo.
¿Por qué latencia? En un núcleo, escanear una tabla de 2 mil millones de filas es 20 veces más lento que escanear 20 tablas en 20 núcleos, haciendo esto en paralelo. Los datos se procesan demasiado lentamente en un recurso.
¿Por qué alta disponibilidad? O cortamos los datos para hacer uno y otro al mismo tiempo, y al mismo tiempo varias copias de cada fragmento: la replicación proporciona una alta disponibilidad.
Un simple ejemplo de "cómo hacerlo con las manos"
El fragmentación condicional se puede cortar utilizando la tabla de prueba test.documents para 32 documentos, y generando a partir de esta tabla 16 tablas de prueba para aproximadamente 2 documentos test.docs00, 01, 02, ..., 15 cada uno.
INSERT INTO docs00 SELECT * FROM documents WHERE (id%16)=0 ... INSERT INTO docs15 SELECT * FROM documents WHERE (id%16)=15
¿Por qué? Debido a que a priori no sabemos cómo se distribuye la identificación, si hay de 1 a 32 inclusive, habrá exactamente 2 documentos cada uno, de lo contrario no.
Estamos haciendo esto para qué. Después de haber hecho 16 tablas, podemos "atrapar" 16 de lo que necesitamos. Independientemente de lo que descansemos, podemos paralelizar estos recursos. Por ejemplo, si no hay suficiente espacio en disco, tendrá sentido descomponer estas tablas en discos separados.
Todo esto, desafortunadamente, no es gratis. Sospecho que en el caso del estándar SQL canónico (no he vuelto a leer el estándar SQL durante mucho tiempo, tal vez no se ha actualizado durante mucho tiempo), no hay una sintaxis estandarizada oficial para decir a ningún servidor SQL: "Estimado servidor SQL, hazme 32 fragmentos y ponerlos en 4 discos ". Pero en implementaciones individuales, a menudo hay una sintaxis específica para hacer lo mismo en principio. PostgreSQL tiene mecanismos para particionar, MySQL MariaDB lo tiene, Oracle probablemente haya hecho todo esto hace mucho tiempo.
Sin embargo, si hacemos esto a mano, sin soporte de base de datos y dentro del marco del estándar, entonces
pagamos condicionalmente la complejidad del acceso a los datos . Donde había un simple SELECT * FROM documentos WHERE id = 123, ahora 16 x SELECT * FROM docsXX. Y bueno, si intentáramos obtener el registro por clave. Significativamente más interesante si tratamos de obtener un rango temprano de registros. Ahora (si, enfatizo, como si fuera tonto, y permanezca dentro del estándar), los resultados de estos 16 SELECT * FROM deberán combinarse en la aplicación.
¿Qué cambio de rendimiento esperar?- Intuitivamente lineal.
- Teóricamente - sublineal, porque la ley de Amdahl .
- En la práctica, tal vez casi linealmente, tal vez no.
De hecho, la respuesta correcta es desconocida. Mediante la aplicación inteligente de la técnica de fragmentación, puede lograr un deterioro súper lineal significativo en el funcionamiento de su aplicación, e incluso el DBA se ejecutará con un póker al rojo vivo.
Veamos cómo se puede lograr esto. Está claro que solo establecer la configuración en fragmentos de PostgreSQL = 16, y luego despegó solo, esto no es interesante. Pensemos en cómo podríamos lograr que
disminuiríamos a 32 veces el fragmentación , lo cual es interesante desde el punto de vista de cómo no hacer esto.
Nuestros intentos de acelerar o frenar siempre estarán en contra de los clásicos: la buena ley de Amdahl, que dice que no hay una paralelización perfecta de ninguna solicitud, siempre hay una parte coherente.
Ley de Amdahl
Siempre hay una parte serializada.
Siempre hay una parte de la ejecución de la solicitud que es paralela, y siempre hay una parte que no es paralela. Incluso si le parece que una consulta perfectamente paralela, al menos recolectando una fila del resultado que va a enviar al cliente, desde las filas recibidas de cada fragmento, siempre existe, y siempre es consistente.
Siempre hay algún tipo de parte secuencial. Puede ser pequeño, absolutamente invisible en el contexto general, puede ser gigantesco y, en consecuencia, afectar fuertemente la paralelización, pero siempre está ahí.
Además, su influencia está
cambiando y puede crecer significativamente, por ejemplo, si reducimos nuestra tabla - aumentemos las tasas - de 64 registros a 16 tablas de 4 registros, esta parte cambiará. Por supuesto, a juzgar por esas enormes cantidades de datos, trabajamos en un teléfono móvil y un procesador de 86 MHz, no tenemos suficientes archivos que puedan mantenerse abiertos al mismo tiempo. Aparentemente, con tal entrada, abrimos un archivo a la vez.
- Fue Total = Serial + Paralelo . Donde, por ejemplo, paralelo es todo el trabajo dentro de la base de datos, y en serie está enviando el resultado al cliente.
- Se convirtió en Total2 = Serial + Paralelo / N + Xserial. Por ejemplo, cuando el ORDER BY general, Xserial> 0.
Con este simple ejemplo, trato de mostrar que aparece algo de Xserial. Además del hecho de que siempre hay una parte serializada, y el hecho de que estamos tratando de trabajar con datos en paralelo, una parte adicional parece asegurar esta división de datos. En términos generales, es posible que necesitemos:
- encuentre estas 16 tablas en el diccionario interno de la base de datos;
- abrir archivos;
- asignar memoria;
- reubicar memoria;
- manchar los resultados;
- sincronizar entre núcleos;
Cualquier efecto fuera de sincronización siempre aparece. Pueden ser insignificantes y ocupar una billonésima parte del tiempo total, pero siempre son distintos de cero y siempre existen. Con su ayuda, podemos perder dramáticamente la productividad después de fragmentar.
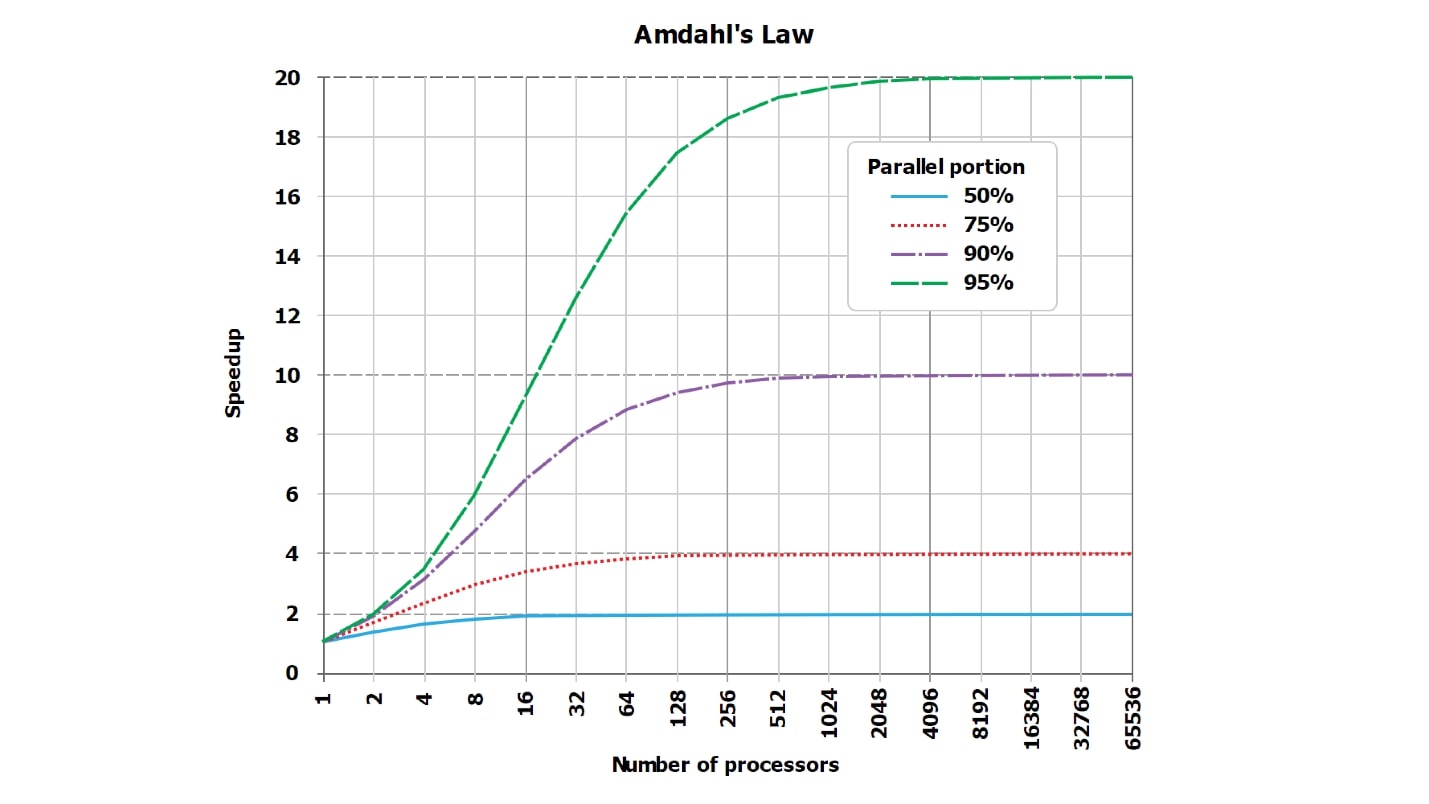
Esta es una imagen estándar sobre la ley de Amdahl. No es muy legible, pero es importante que las líneas, que idealmente deben ser rectas y crecer linealmente, colinden con la asíntota. Pero como el gráfico de Internet es ilegible, creé, en mi opinión, más tablas visuales con números.
Supongamos que tenemos una parte serializada del procesamiento de la solicitud, que solo requiere un 5%:
serial = 0.05 = 1/20.Intuitivamente, parece que con la parte serializada, que toma solo 1/20 del procesamiento de la solicitud, si paralelizamos el procesamiento de la solicitud a 20 núcleos, se volverá aproximadamente 20, en el peor de los casos, 18 veces más rápido.
De hecho, las
matemáticas son una cosa despiadada :
wall = 0.05 + 0.95/num_cores, speedup = 1 / (0.05 + 0.95/num_cores)Resulta que si calcula cuidadosamente, con una parte serializada del 5%, la aceleración será 10 veces (10.3), y esto es 51% en comparación con el ideal teórico.
| 8 núcleos | = 5.9 | = 74% |
| 10 núcleos | = 6,9 | = 69% |
| 20 núcleos | = 10,3 | = 51% |
| 40 núcleos | = 13,6 | = 34% |
| 128 núcleos | = 17.4 | = 14% |
Usando 20 núcleos (20 discos, si lo desea) para la tarea en la que uno trabajó antes, en teoría nunca obtendremos aceleración más de 20 veces, pero prácticamente mucho menos. Además, con un aumento en el número de paralelos, la ineficiencia está creciendo rápidamente.
Cuando solo queda el 1% del trabajo en serie, y el 99% está en paralelo, los valores de aceleración mejoran de alguna manera:
| 8 núcleos | = 7.5 | = 93% |
| 16 núcleos | = 13,9 | = 87% |
| 32 núcleos | = 24,4 | = 76% |
| 64 núcleos | = 39,3 | = 61% |
Para una consulta completamente termonuclear, que naturalmente se ejecuta durante horas, y el trabajo preparatorio y el ensamblaje del resultado toman muy poco tiempo (serial = 0.001), ya veremos una buena eficiencia:
| 8 núcleos | = 7,94 | = 99% |
| 16 núcleos | = 15,76 | = 99% |
| 32 núcleos | = 31.04 | = 97% |
| 64 núcleos | = 60,20 | = 94% |
Tenga en cuenta que
nunca veremos el 100% . En casos particularmente buenos, puede ver, por ejemplo, 99.999%, pero no exactamente 100%.
¿Cómo barajar y romper en N veces?
Puedes barajar y romper exactamente N veces:
- Enviar docs00 ... docs15 solicitudes de forma secuencial , no en paralelo.
- En consultas simples, no seleccione por clave , DONDE algo = 234.
En este caso, la parte serializada (serial) no ocupa el 1% y no el 5%, sino alrededor del 20% en las bases de datos modernas. Puede obtener el 50% de la parte serializada si accede a la base de datos utilizando un protocolo binario extremadamente eficiente o lo vincula como una biblioteca dinámica a un script de Python.
El resto del tiempo de procesamiento para una solicitud simple estará ocupado por operaciones no paralelizadas de análisis de la solicitud, preparación del plan, etc. Es decir, se ralentiza al no leer el registro.
Si dividimos los datos en 16 tablas y los ejecutamos secuencialmente, como es habitual en el lenguaje de programación PHP, por ejemplo, (no sabe cómo ejecutar procesos asincrónicos muy bien), entonces solo tenemos una desaceleración de 16 veces. Y, quizás, aún más, porque también se agregarán viajes de ida y vuelta a la red.
De repente, al fragmentar, la elección de un lenguaje de programación es importante.
Recordamos la elección de un lenguaje de programación, porque si envía consultas a la base de datos (o al servidor de búsqueda) secuencialmente, ¿de dónde viene la aceleración? Más bien, aparecerá una desaceleración.
Bicicleta de la vida
Si elige C ++,
escriba en subprocesos POSIX , no Boost I / O. Vi una excelente biblioteca de desarrolladores experimentados de Oracle y MySQL, quienes escribieron la comunicación con el servidor MySQL en Boost. Aparentemente, se vieron obligados a escribir en C puro en el trabajo, pero luego lograron dar la vuelta, tomar Boost con E / S asincrónicas, etc. Un problema: esta E / S asíncrona, que teóricamente debería haber conducido 10 solicitudes en paralelo, por alguna razón tenía un punto de sincronización invisible en su interior. Al iniciar 10 solicitudes en paralelo, se ejecutaron exactamente 20 veces más lento que uno, porque 10 veces a las solicitudes mismas y una vez al punto de sincronización.
Conclusión: escriba en idiomas que implementen la ejecución paralela y esperen bien las diferentes solicitudes. No sé, para ser honesto, qué hay exactamente para aconsejar además de Go. No solo porque realmente amo Go, sino porque no sé nada más adecuado.
No escriba en idiomas inadecuados en los que no pueda ejecutar 20 consultas paralelas a la base de datos. O en cada oportunidad, no lo haga todo con las manos: comprenda cómo funciona, pero no lo haga manualmente.
Bicicleta de prueba A / B
A veces puede disminuir la velocidad porque está acostumbrado al hecho de que todo funciona y no se dio cuenta de que la parte serializada, en primer lugar, es grande.
- Inmediatamente ~ 60 fragmentos de índice de búsqueda, categorías
- Estos son fragmentos correctos y correctos, debajo de un área temática.
- Había hasta 1000 documentos, y había 50,000 documentos.
Esta es una bicicleta de producción, cuando las consultas de búsqueda se modificaron ligeramente y comenzaron a seleccionar muchos más documentos de 60 fragmentos del índice de búsqueda. Todo funcionó rápidamente y según el principio: "Funciona, no lo toques", todos lo olvidaron, que en realidad está dentro de 60 fragmentos. Aumentamos el límite de muestreo para cada fragmento de mil a 50 mil documentos. De repente, comenzó a disminuir y el paralelismo cesó. Las solicitudes en sí, que se ejecutaron de acuerdo con fragmentos, volaron bastante bien, y el escenario se ralentizó, cuando se recogieron 50 mil documentos de 60 fragmentos. Estos 3 millones de documentos finales en un núcleo se fusionaron, ordenaron, se seleccionaron los 3 millones y se entregaron al cliente. La misma parte serial disminuyó, la misma ley despiadada de Amdal funcionó.
Entonces quizás no debas hacer fragmentos con tus manos, sino solo humanamente
dígale a la base de datos: "¡Hazlo!"
Descargo de responsabilidad: realmente no sé cómo hacer algo bien. ¡Soy del piso equivocado!
He estado promoviendo una religión llamada "fundamentalismo algorítmico" a lo largo de toda mi vida consciente. Se formula brevemente de manera muy simple:
Realmente no quieres hacer nada con las manos, pero es extremadamente útil saber cómo está organizado en el interior. De modo que en el momento en que algo sale mal en la base de datos, al menos entiendes lo que salió mal allí, cómo está organizado dentro y aproximadamente cómo se puede reparar.
Veamos las opciones:
- "Manos" . Anteriormente, dividimos manualmente los datos en 16 tablas virtuales y reescribimos todas las consultas con nuestras manos; esto es extremadamente incómodo. Si existe la oportunidad de no barajar las manos, ¡no baraje las manos! Pero a veces esto no es posible, por ejemplo, tienes MySQL 3.23 y luego tienes que hacerlo.
- "Automático". Sucede que puede barajar automáticamente o casi automáticamente, cuando la base de datos puede distribuir los datos en sí, solo necesita escribir aproximadamente en algún lugar una configuración específica. Hay muchas bases y tienen muchas configuraciones diferentes. Estoy seguro de que en cada base de datos en la que es posible escribir fragmentos = 16 (cualquiera que sea la sintaxis), el motor pega muchas otras configuraciones a este caso.
- "Semiautomático" : un modo completamente cósmico, en mi opinión, y brutal. Es decir, la base en sí misma no parece ser capaz, pero hay parches externos adicionales.
Es difícil decir algo sobre la máquina, excepto enviarlo a la documentación en la base de datos correspondiente (MongoDB, Elastic, Cassandra, ... en general, el llamado NoSQL). Si tiene suerte, simplemente presione el interruptor "hazme 16 fragmentos" y todo funcionará. En ese momento, cuando no funciona, el resto del artículo puede ser necesario.
Sobre dispositivo semiautomático
En algunos lugares, las sofisticadas tecnologías de la información inspiran horror ctónico. Por ejemplo, MySQL listo para usar no tenía implementación de fragmentación para ciertas versiones, sin embargo, el tamaño de las bases operadas en la batalla creció a valores indecentes.
El sufrimiento de la humanidad frente a los DBA individuales ha sido atormentado durante años y escribe varias soluciones de fragmentación malas construidas sin ninguna razón. Después de eso, se escribe una solución de fragmentación más o menos decente llamada ProxySQL (MariaDB / Spider, PG / pg_shard / Citus, ...). Este es un ejemplo bien conocido de este mismo manto.
ProxySQL en su conjunto, por supuesto, es una solución completa de clase empresarial para código abierto, para enrutamiento y más. Pero una de las tareas a resolver es fragmentar una base de datos, que en sí misma no sabe fragmentar humanamente. Verá, no hay un interruptor de "fragmentos = 16", o debe reescribir cada solicitud en la aplicación, y hay muchos lugares, o poner una capa intermedia entre la aplicación y la base de datos que se ve: "Hmm ... ¿SELECCIONAR * DE los documentos? Sí, debe dividirse en 16 pequeños SELECT * FROM server1.document1, SELECT * FROM server2.document2 - a este servidor con ese nombre de usuario / contraseña, a este con otro. Si uno no respondió, entonces ... "etc.
Exactamente esto se puede hacer mediante parches intermedios. Son un poco menos que para todas las bases de datos. Para PostgreSQL, según tengo entendido, al mismo tiempo hay algunas soluciones integradas (PostgresForeign Data Wrappers, en mi opinión, está integrado en PostgreSQL), hay parches externos.
La configuración de cada parche específico es un tema gigante separado que no cabe en un informe, por lo que discutiremos solo conceptos básicos.
Mejor hablemos un poco sobre la teoría del zumbido.
¿Automatización perfecta absoluta?
Toda la teoría del zumbido en el caso de los fragmentos en esta letra F (), el principio básico es
siempre el mismo crudo:
shard_id = F(object).Sharding es generalmente sobre qué? Tenemos 2 mil millones de registros (o 64). Queremos dividirlos en varias piezas. Surge una pregunta inesperada: ¿cómo? ¿Por qué principio debo dispersar mis 2 mil millones de registros (o 64) en 16 servidores disponibles para mí?
El matemático latente en nosotros debería sugerir que al final siempre hay una cierta función mágica que, para cada documento (objeto, línea, etc.), determinará en qué pieza colocarla.
Si profundizamos en las matemáticas, esta función siempre depende no solo del objeto en sí (la línea en sí), sino también de configuraciones externas como el número total de fragmentos. La función, que para cada objeto debe decir dónde colocarla, no puede devolver un valor más de lo que hay servidores en el sistema. Y las funciones son un poco diferentes:
- shard_func = F1 (objeto);
- shard_id = F2 (shard_func, ...);
- shard_id = F2 ( F1 (objeto), current_num_shards, ...).
Pero además no profundizaremos en estas selvas de funciones individuales, solo hablaremos de qué son las funciones mágicas F ().
¿Qué son F ()?
Pueden proponer muchos mecanismos de implementación diferentes y diferentes. Resumen de muestra:
- F = rand ()% nums_shards
- F = somehash (object.id)% num_shards
- F = object.date% num_shards
- F = object.user_id% num_shards
- ...
- F = shard_table [somehash () | ... object.date | ...]
Un hecho interesante, naturalmente puede dispersar todos los datos al azar, arrojamos el siguiente registro en un servidor arbitrario, en un núcleo arbitrario, en una tabla arbitraria. No habrá mucha felicidad en esto, pero funcionará.
Hay métodos un poco más inteligentes de estafa para funciones hash reproducibles o incluso consistentes, o estafando para algún atributo. Veamos cada método.
F = rand ()
Dispersarse no es un método muy correcto. Un problema: dispersamos nuestros 2 mil millones de registros por cada mil servidores al azar, y no sabemos dónde se encuentra el registro. Necesitamos extraer user_1, pero no sabemos dónde está. Vamos a mil servidores y clasificamos todo, de alguna manera es ineficiente.
F = somehash ()
Dispersemos a los usuarios de manera adulta: lea la función hash reproducida de user_id, tome el resto de la división por el número de servidores y acceda al servidor deseado de inmediato.
¿Por qué estamos haciendo esto? Y luego, que tenemos una gran carga y no obtenemos nada en un servidor. Si es intermedio, la vida sería tan simple.Bueno, la situación ya ha mejorado, para obtener un registro, vamos a un servidor conocido. Pero si tenemos un rango de claves, entonces en todo este rango necesitamos clasificar todos los valores de clave y, en el límite, ir a tantos fragmentos como tengamos claves en el rango o a cada servidor en general. La situación, por supuesto, ha mejorado, pero no para todas las solicitudes. Algunas solicitudes han sido afectadas.
Fragmentación natural (F = object.date% num_shards)
A veces, es decir, el 95% del tráfico y el 95% de la carga son solicitudes que tienen algún tipo de fragmentación natural. , 95% - 1 , 3 , 7 , 5% . 95% , , , .
, , , - .
— , . , , , , . 5 % .
, :
- , 95% .
- 95% , , . , . , .
, — , - .
, , , , . « - ».
«». , .
1. :
, , .
, / , , , PM ( , PM ), . .
, . , , 100 . .
, , , , - .
2. «» : , join
, ?
- «» … WHERE randcol BETWEEN aaa AND bbb?
- «» … users_32shards JOIN posts_1024 shards?
: , !
, , , . . (, , document store ), , .
—
- . . , . , , , . - , , , , — .
, .
3. / :
: , .
, .
, , , . , , , 10 , - 30, 100 . . — , - — , - .
, : 16 -, 32. , 17, 23 — . , , - ?
: , , .
, «», « ».
#1.
- NewF(object), .
- NewF()=OldF() .
- .
- Ouch
, 2 , , . : 17 , 6 , 2 , 17 23 . 10 , , . .
#2.
— — 17 23, 16 32 ! , .
- NewF(object), .
- 2^N, 2^(N+1) .
- NewF()=OldF() 0,5.
- 50% .
- , .
, , . , , .
, . , 16 16, — .
, — .
#3. Consistent hashing
, consistent hashing
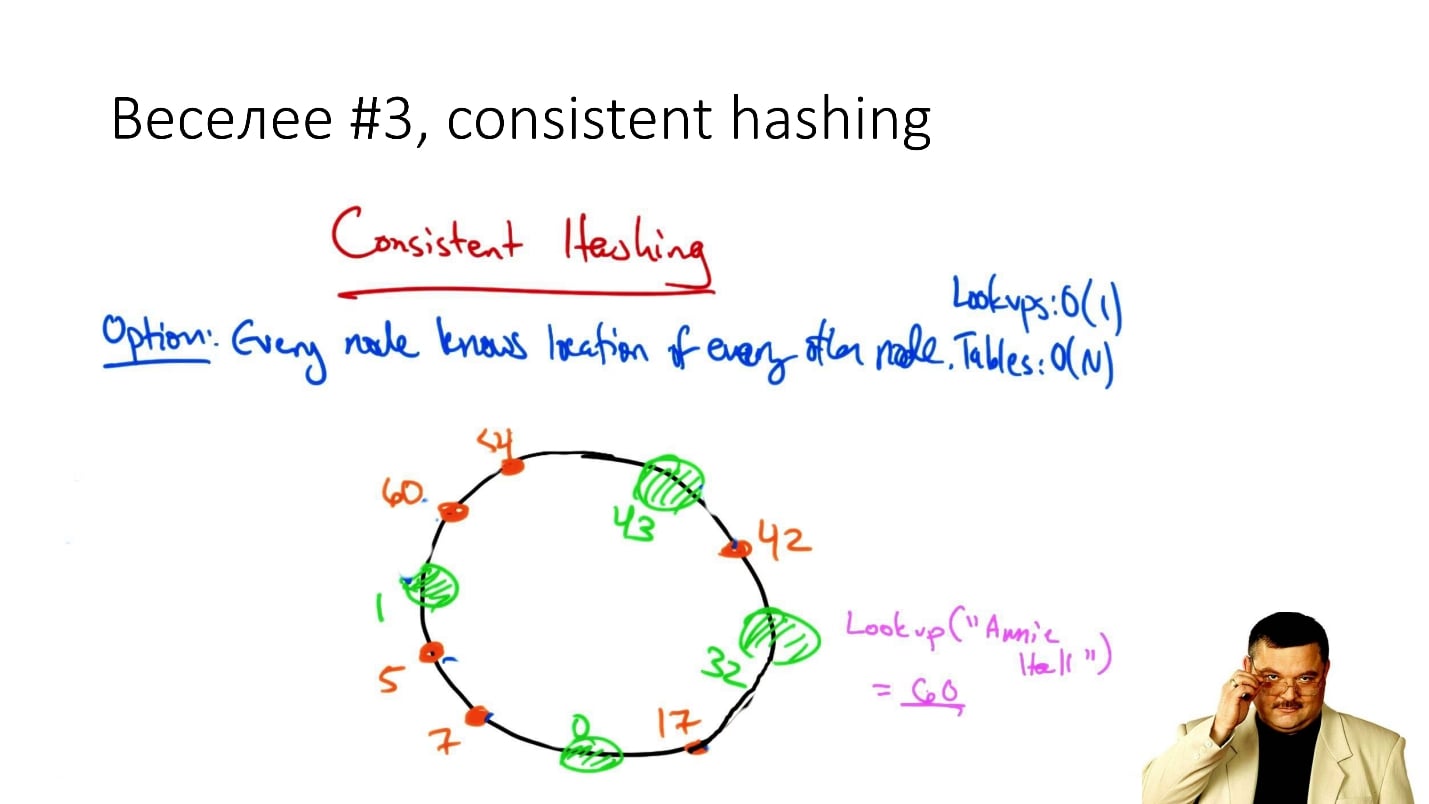
«consistent hashing», , .
: () , . , , , ( , ), .
, . , , , : , .
. , . , .., . , - , , .
, , , Cassandra . , , , , , .
, — / , , .
, : ? ? — , !
#4. Rendezvous/HRW
( , ):
shard_id = arg max hash(object_id, shard_id).Rendezvous hashing, , , Highest Random Weight. :
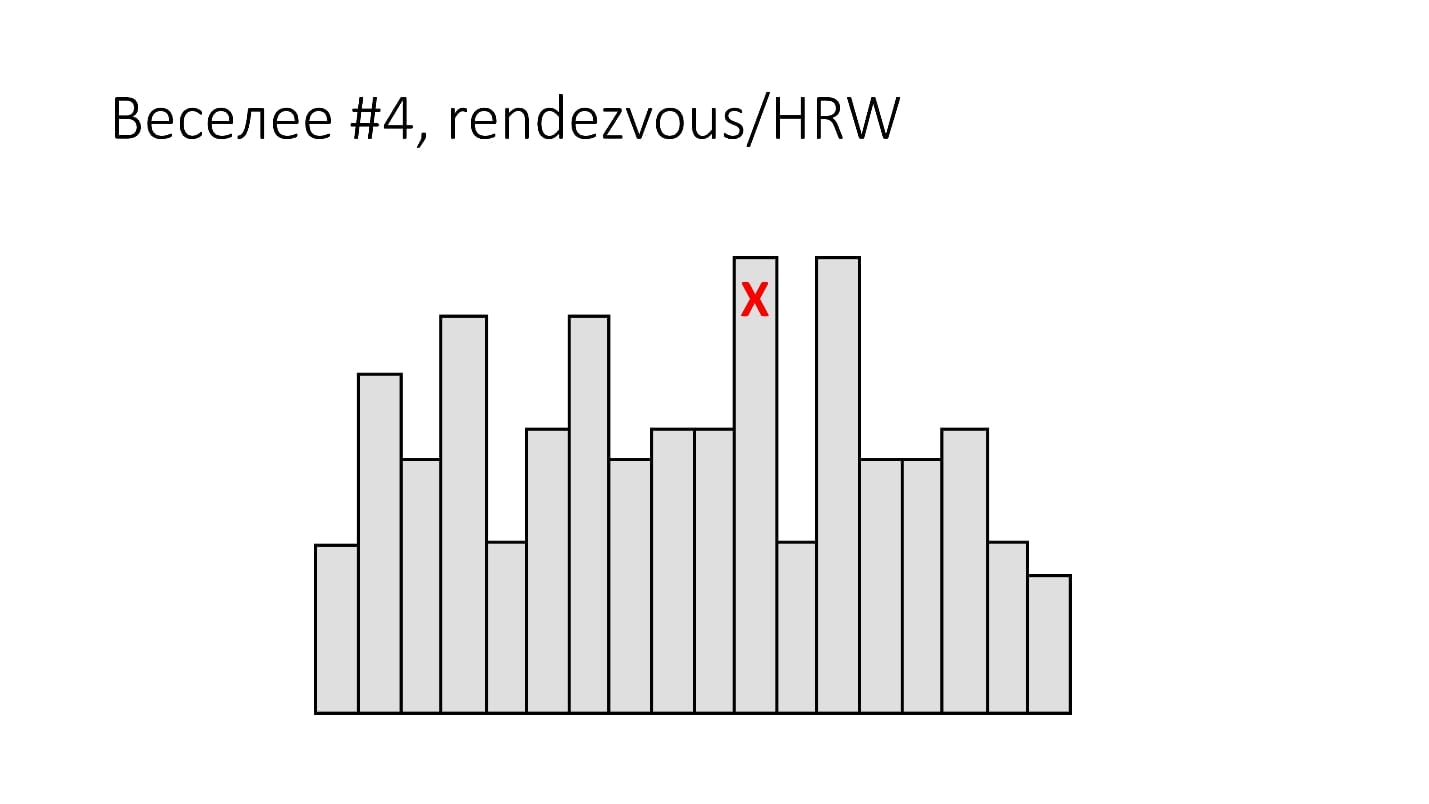
, , 16 . (), - , 16 , . -, .
HRW-hashing, Rendezvous hashing. , -, , .
, . , - - . .
, .
#5.
, Google - :
- Jump Hash — Google '2014.
- Multi Probe —Google '2015.
- Maglev — Google '2016.
, . , , , -, . .
#6.
— . ? , 2 , object_id 2 , .
, ? ?
. , - , , . , , , , .
:
- 1 .
- / / / : min/max_id => shard_id.
- 8 4 (4 !) — 20 .
- - , 20 — .
- 20 — .
2 - 16 — 100 - . : , , — 1 . , , .
, , , - , .
Conclusiones
: « , !». , 20 .
, , . ,
— . 100$ , . -, . — .
, , «» (, DFS, ...) . , , highload - . , , - . —
, .
F() , , , .. , , 2
.
, , .
HighLoad++ , , —Sphinx—highload , .
Highload User Group. , .
, ,
HighLoad++ . , , . , , .
highload-, .
, , , . , , , .
24 - «», « ». , . ,
.
, , 8 9 - HighLoad++ early bird .