Instituto de Tecnología de Massachusetts. Conferencia Curso # 6.858. "Seguridad de los sistemas informáticos". Nikolai Zeldovich, James Mickens. Año 2014
Computer Systems Security es un curso sobre el desarrollo e implementación de sistemas informáticos seguros. Las conferencias cubren modelos de amenazas, ataques que comprometen la seguridad y técnicas de seguridad basadas en trabajos científicos recientes. Los temas incluyen seguridad del sistema operativo (SO), características, gestión del flujo de información, seguridad del idioma, protocolos de red, seguridad de hardware y seguridad de aplicaciones web.
Lección 1: "Introducción: modelos de amenaza"
Parte 1 /
Parte 2 /
Parte 3Lección 2: "Control de ataques de hackers"
Parte 1 /
Parte 2 /
Parte 3Lección 3: “Desbordamientos del búfer: exploits y protección”
Parte 1 /
Parte 2 /
Parte 3Lección 4: “Separación de privilegios”
Parte 1 /
Parte 2 /
Parte 3Lección 5: “¿De dónde vienen los sistemas de seguridad?”
Parte 1 /
Parte 2Lección 6: “Oportunidades”
Parte 1 /
Parte 2 /
Parte 3Lección 7: “Sandbox de cliente nativo”
Parte 1 /
Parte 2 /
Parte 3Lección 8: "Modelo de seguridad de red"
Parte 1 /
Parte 2 /
Parte 3Lección 9: "Seguridad de aplicaciones web"
Parte 1 /
Parte 2 /
Parte 3Lección 10: “Ejecución simbólica”
Parte 1 /
Parte 2 /
Parte 3Lección 11: "Ur / Lenguaje de programación web"
Parte 1 /
Parte 2 /
Parte 3Lección 12: Seguridad de red
Parte 1 /
Parte 2 /
Parte 3Lección 13: "Protocolos de red"
Parte 1 /
Parte 2 /
Parte 3Lección 14: "SSL y HTTPS"
Parte 1 /
Parte 2 /
Parte 3Lección 15: "Software médico"
Parte 1 /
Parte 2 /
Parte 3Lección 16: "Ataques de canal lateral"
Parte 1 /
Parte 2 /
Parte 3Lección 17: "Autenticación de usuario"
Parte 1 /
Parte 2 /
Parte 3Lección 18: "Navegación privada en Internet"
Parte 1 /
Parte 2 /
Parte 3Lección 19: "Redes anónimas"
Parte 1 /
Parte 2 /
Parte 3Lección 20: "Seguridad del teléfono móvil"
Parte 1 /
Parte 2 /
Parte 3Lección 21: “Datos de seguimiento”
Parte 1 /
Parte 2 /
Parte 3 Estudiante: ¿por qué es simplemente imposible escanear el código y no verificarlo manualmente?
Profesor: en la práctica, esto es lo que sucede. Los desarrolladores saben que cada vez que el intérprete hace este tipo de trabajo, al devolver el valor de retorno, se utiliza un código especial que asigna automáticamente el valor del sistema infectado a system.arraycopy (), que debería estar asociado a él.
Estudiante: cierto, pero ¿cuál es entonces la parte manual del trabajo?
Profesor: la parte
del manual es principalmente para averiguar cuál debería ser la política de ejecución de la auditoría. En otras palabras, si solo mira TaintDroid estándar o Android estándar, harán algo por usted, pero no podrán asignar Taint automáticamente de la manera correcta. Entonces, alguien debe asignar manualmente una política de seguimiento.

No parece que sea un gran problema en la práctica. Pero si el número de aplicaciones que utilizan métodos orientados a la máquina ha aumentado constantemente, entonces podemos tener pequeños problemas.
Otro tipo de datos de los que preocuparse en términos de asignación de una infección son los mensajes IPC. Los mensajes de IPC se tratan esencialmente como matrices. Por lo tanto, cada uno de estos mensajes estará asociado con una única mancha común, que es la unión de infecciones de todas sus partes constituyentes.
Esto contribuye al rendimiento del sistema porque solo necesitamos almacenar una etiqueta de contaminación para cada uno de estos mensajes. En un caso extremo, simplemente se volverá a evaluar un grado de infección, pero nunca conducirá a una disminución de la seguridad. Lo peor que puede suceder al mismo tiempo es que la red no obtendrá datos que puedan llegar allí sin consecuencias peligrosas para la privacidad.
Entonces, cuando crea un mensaje IPC, recibe la mancha combinada. Cuando lee lo que recibió en este mensaje, los datos extraídos se infectan del mensaje en sí, lo que tiene sentido. Así es como se manejan los mensajes IPC.
También vale la pena preocuparse por cómo se procesa el archivo. Por lo tanto, cada archivo recibe una etiqueta de contaminación, y esta etiqueta se almacena con el archivo en sus metadatos en un medio de almacenamiento estable, como una tarjeta de memoria SD. Aquí tiene lugar el mismo enfoque conservador para la infección que en casos anteriores. La idea principal es que la aplicación obtenga acceso a algunos datos confidenciales, por ejemplo, la ubicación del GPS, y probablemente va a escribir estos datos en un archivo, por lo que TaintDroid actualiza la etiqueta de contaminación de este archivo con el indicador GPS, después de lo cual la aplicación se cierra. Más tarde, se puede incluir alguna otra aplicación que lea este archivo.
Cuando ingresa a la máquina virtual, a la aplicación, TaintDroid ve que tiene este indicador y, por lo tanto, cualquier dato extraído mientras lee este archivo también tendrá este indicador GPS. Creo que es bastante simple.
Entonces, ¿qué cosas podemos infectar desde una perspectiva Java? Básicamente, hay cinco tipos de objetos Java que necesitan indicadores de contaminación. En primer lugar, estas son variables locales Variables locales que se utilizan en el método. Volviendo a los ejemplos anteriores, podemos suponer que char c es una variable de este tipo.
Por lo tanto, debemos asignar banderas a estos elementos. El segundo tipo son los argumentos del método de argumentos Método; también deben tener indicadores de infección. Ambas cosas viven en la pila, por lo que TaintDroid debe realizar un seguimiento del propósito de las banderas y mucho más para este tipo de objetos.
También necesitamos asignar banderas a los campos de instancia de los campos de instancia de Object. Imagine que hay un cierto objeto C, es un círculo, y quiero saber su radio. Por lo tanto, tenemos el campo c.radius, y debemos asociar la información de infección para cada uno de estos campos: con y radio.
El cuarto tipo de objeto Java son los campos de clase estática de los campos de clase estática, que también requieren información corrupta. Puede ser algo como circle.property, es decir, una descripción de las propiedades del círculo para el que asignamos cierta información para contaminar.
El quinto tipo son las matrices de matrices, de las que hablamos anteriormente, y asignamos una pieza común de información de infección para toda la matriz.
La idea básica de implementar banderas de contaminación para estos tipos de objetos Java es tratar de almacenar banderas de contaminación para una variable al lado de la variable misma.

Digamos que tenemos alguna variable entera, y queremos colocar algún tipo de contaminación contaminante. Queremos tratar de mantener este estado tan cerca de la variable como sea posible, posiblemente por razones de asegurar una operación eficiente de caché a nivel de procesador. Si nos mantuvimos contaminados muy lejos de esta variable, esto podría causar problemas, porque después de que el intérprete observe el valor de la memoria para esta variable Java real, querrá familiarizarse con la información sobre su infección lo más rápido posible.
Si observamos la operación move-op, notamos que en estos lugares en el código, dst y src, cuando el intérprete considera los valores, también considera las infecciones contaminantes correspondientes.
Por lo tanto, colocando estas cosas lo más cerca posible entre sí, está tratando de garantizar un uso más eficiente de la memoria caché. Esto es bastante simple Si observa lo que hacen los desarrolladores por los argumentos de los métodos y las variables locales que viven en la pila, puede ver que esencialmente resaltan las banderas de contaminación al lado de donde se encuentran las variables.
Supongamos que tenemos una cosa favorita sobre nuestras conferencias, un diagrama de pila que probablemente odiarás pronto para mencionarlo con frecuencia. Deje que la variable local 0 se ubique en nuestra pila, luego TaintDroid almacenará en la memoria una etiqueta sobre la infección de esta variable justo debajo de ella. Si luego tiene otra variable, su etiqueta también se ubicará directamente debajo de ella, y así sucesivamente. Es bastante simple Todas estas cosas estarán ubicadas en la misma línea de caché, lo que hará que el acceso a la memoria sea menos costoso.
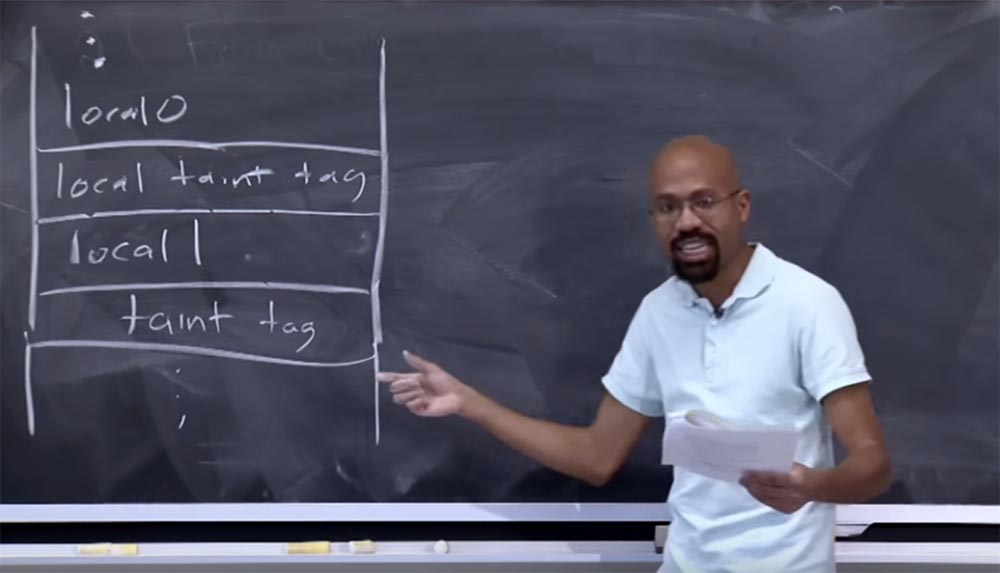 Estudiante:
Estudiante: Me pregunto cómo puede tener un indicador para una matriz completa y diferentes indicadores para cada propiedad de un objeto. ¿Qué sucede si uno de los métodos del objeto puede acceder a los datos almacenados en sus propiedades? Eso sería ... ¿sabes a qué me refiero?
Profesor: ¿Está preguntando por la razón de aplicar tal política?
Estudiante: sí, sobre el motivo por el que se usa dicha política.
Profesor: Creo que esto se hace para garantizar la efectividad de la implementación. Probablemente hay otras reglas, por ejemplo, no informan la longitud de la matriz de datos, ya que es posible la fuga de información, por lo tanto, no extienden la infección a este indicador. Así que creo que algunas decisiones se toman simplemente por razones de eficiencia. En principio, no hay nada que obstaculice al dar acceso a cada elemento de la matriz para indicar que la cosa de la izquierda recibe contaminación solo de cualquier elemento específico.
Sin embargo, no está claro si esto será correcto, porque, aparentemente, si coloca algo en la matriz, esta cosa debería saber algo sobre esta matriz. Por lo tanto, creo que los desarrolladores usan una combinación de ambas políticas. Al ser demasiado conservador, no debe permitir la pérdida de datos que desea proteger, pero al mismo tiempo, para tener acceso a la matriz, debe saber algo al respecto. Y cuando necesitas aprender algo sobre algo, generalmente significa que usas la mancha.
Entonces, este es el esquema básico que utilizan para almacenar toda esta información uno al lado del otro. Uno puede imaginar que se hace lo mismo para los campos de clase y para los campos de objeto. Al declarar una clase, tiene algo de memoria de ranura para una variable en particular, y justo al lado de esta ranura hay información corrupta para esa variable. Así que creo que todo esto es bastante razonable.
Este es el principio de TaintDroid. Cuando el sistema se inicializa o en otros momentos durante el funcionamiento del sistema, TaintDroid analiza todas las fuentes de información potencialmente infectada y asigna una bandera a cada una de estas cosas: sensor GPS, cámara, etc. A medida que se ejecuta el programa, extraerá información confidencial de estas fuentes, después de lo cual el intérprete considerará todos los tipos de funciones de acuerdo con la tabla que se proporciona en el artículo para averiguar cómo propagar la infección contaminante en todo el sistema.
Lo más interesante sucede cuando los datos intentan penetrar en el sistema. TaintDroid puede controlar las interfaces de red y ver todo lo que intenta pasar a través de ellas. Busca etiquetas contaminantes, y si los datos que intentan penetrar en la red tienen una o más de estas banderas, se les prohibirá usar la red. Lo que sucede en este momento realmente depende de la aplicación.

Por ejemplo, TaintDroid puede mostrarle al usuario una advertencia diciendo que alguien está tratando de enviar datos sobre su ubicación a un lado. Es posible que TaintDroid contenga políticas integradas que permitirán que la aplicación acceda a la red, pero al mismo tiempo restablecerá todos los datos confidenciales que intentará transferir, y así sucesivamente. En el artículo, este mecanismo no se describe con suficiente detalle, ya que los autores se preocuparon principalmente por el tema de la "fuga" de datos en la red.
Una sección del artículo titulada "Evaluación" discute algunas de las cosas encontradas en el proceso de estudiar el funcionamiento del sistema. Por lo tanto, los autores del artículo descubrieron que las aplicaciones de Android intentarán extraer datos de formas invisibles para el usuario. Suponga que intentarán usar su ubicación para publicidad, enviarán su número a un servidor remoto, y así sucesivamente. Es importante tener en cuenta que estas aplicaciones, por regla general, no "rompen" el modelo de seguridad de Android en el sentido de que el usuario debe permitirles acceder a la red o permitirles usar la lista de contactos. Sin embargo, las aplicaciones no proporcionan en el acuerdo de licencia EULA que tengan la intención de enviar un número de teléfono a algún servidor de Silk Road 8 o algo así. De hecho, esto es un fraude y engaña a los usuarios sobre las verdaderas intenciones de la aplicación, porque si vieron estos requisitos de EULA y sabían con qué estaban cargados, podrían pensar si instalar una aplicación de este tipo en su teléfono inteligente o no.
Estudiante: se puede suponer que incluso si ponen estos requisitos en el acuerdo de licencia, no funcionaría, porque la gente generalmente no lee el EULA.
Profesor: esta es una suposición muy razonable, porque incluso los informáticos no siempre verifican el acuerdo de licencia. Sin embargo, tal honestidad en EULA aún sería beneficiosa, porque hay personas que realmente leen el acuerdo de licencia. Pero tiene toda la razón al suponer que los usuarios no leerán un montón de páginas escritas en letra pequeña, simplemente hacen clic en "aceptar" e instalan la aplicación.
Entonces, creo que las reglas para pasar información a través del sistema son bastante simples, como ya dijimos, la contaminación simplemente se mueve del lado derecho al lado izquierdo. Sin embargo, a veces estas reglas para el movimiento del flujo de información pueden tener resultados algo conflictivos.
Imagine que una aplicación implementa su propia clase de listas vinculadas. Tenemos una clase simple llamada ListNode, tendrá un campo de objeto para los datos del objeto y un siguiente objeto ListNode que representa la siguiente lista.
Suponga que la aplicación asigna datos infectados al campo de datos Objeto: información confidencial recibida de un sensor GPS u otra cosa. La pregunta es, cuando calculamos la longitud de esta lista, ¿debería estar infectada? Te sorprenderá que la respuesta a la pregunta sea "no", lo que se explica por cómo TaintDroid y algunos de estos sistemas determinan el flujo de información. Veamos qué significa agregar un nodo a una lista vinculada.
Agregar un nodo consta de 3 pasos. Entonces, lo primero que debe hacer es seleccionar un nuevo nodo de lista que contenga los datos que desea agregar: Alloc ListNode. El segundo paso es asignar un campo de datos a este nuevo nodo. Y lo tercero que debe hacer es usar algún tipo de parche para ListNode al lado para fusionar los nodos en una lista: este es el puntero ptr "siguiente".

Curiosamente, el tercer paso no está relacionado con el campo de datos, solo considera el siguiente valor. Tan pronto como se infectan los datos del Objeto, comenzamos a calcular la longitud de la lista, comenzando desde algún nodo principal, revisamos todos los "próximos" punteros ptr y solo contamos cuántos punteros han pasado. Entonces el algoritmo de conteo no toca los datos infectados.
Curiosamente, si tiene una lista vinculada que se llena con datos infectados y luego calcula su longitud, esto no conducirá a la generación de un valor infectado. Esto puede parecer un poco ilógico, aunque al considerar las matrices, ya hemos dicho que la longitud de la matriz tampoco contiene contaminación. Hay el mismo motivo. Hacia el final de la conferencia, discutiremos cómo puede usar un lenguaje que le permita a usted como programador determinar sus propios tipos de infección, y luego puede desarrollar su propia política para tales cosas.
Una buena característica de TaintDroid es que usted, como desarrollador, no tiene que etiquetar nada, TaintDroid lo hace por usted. Señala todas las cosas confidenciales que pueden ser una fuente de información, y todas las cosas que pueden ser "sumideros" de información, por lo que usted, como desarrollador, está listo para trabajar. Pero si desea controlar la adición de nodos, es posible que deba crear algunas políticas usted mismo.
¿Cómo afecta TaintDroid al rendimiento del sistema? Los gastos generales existentes en realidad parecen bastante razonables. La sobrecarga de memoria es almacenar todas las etiquetas de infección. La carga del procesador consistirá principalmente en el destino, la distribución y la verificación de estas infecciones, y debe tenerse en cuenta que el uso de la máquina virtual Dalvik es un trabajo adicional. Entonces, mirando la fuente, mirando esta información de infección de 32 bits, realizamos operaciones que ya hemos considerado. Esta es una sobrecarga computacional.
Estos gastos generales parecen bastante moderados. Según los autores del artículo, el almacenamiento de etiquetas contaminantes requiere del 3% al 5% de memoria adicional, por lo que esto no es tan malo. La carga del procesador es ligeramente mayor y puede alcanzar del 3% al 29% de la potencia informática. Esto se debe al hecho de que cada vez que se ejecuta el bucle, el intérprete debe mirar estas etiquetas y realizar las operaciones correspondientes. Aunque estas son solo operaciones bit a bit, deben realizarse todo el tiempo. Esto no es malo incluso en el caso de una carga del 29%, porque los desarrolladores de Silicon Valley hablan constantemente del hecho de que los teléfonos modernos necesitan procesadores de cuatro núcleos. El único problema puede surgir con la batería, porque incluso si tiene núcleos de procesador adicionales, es poco probable que desee tener un teléfono caliente en su bolsillo que comience a "explotar" cuando intente calcular estas cosas. Pero si su batería no se ve particularmente afectada por tales cálculos, entonces no todo está tan mal.

Así que esta fue una descripción general del trabajo de TaintDroid. Tiene una pregunta
Estudiante: ¿ etiquetas solo lo que hay todo el tiempo? ¿O cada variable está etiquetada?
Profesor: todo está marcado, por lo que, en teoría, nada le impide poner información sobre la infección para cosas que no tienen infección. Creo que tan pronto como algo obtiene al menos un poco de contaminación, debe construir algo como un diseño de cambio dinámico. - , , . taint, , , - , , . , , - . TaintDroid . Dalvik.
– taint x86 ARM? , , , , , , Java . ?
, , , . , , , , , Java- - . x86, , , , , , .
, taint , , , . .

, x86 — . . , - x86, . , , , P, , , !
, taint x86. , , , AD, , .
-, , . -, , . , , , .
, . , . , , , . , « » Taint Explosion.
, , . , Dungeons and Dragons, .
, , - - . , , , .
, - esp esb. , .

, x86, , esp. , , . , , , ebp, , , . , , , taint .
, Linux . , . , - .
: ? , .
: . x86, , . , . Bochs – IBM PC, 86. TaintBochs, x86 . x86, , . , . , , , , , , - .
54:10Curso MIT "Seguridad de sistemas informáticos". Lección 21: Seguimiento de datos, Parte 3La versión completa del curso está disponible aquí .Gracias por quedarte con nosotros. ¿Te gustan nuestros artículos? ¿Quieres ver más materiales interesantes?
Apóyenos haciendo un pedido o recomendándolo a sus amigos, un
descuento del 30% para los usuarios de Habr en un análogo único de servidores de nivel de entrada que inventamos para usted: toda la verdad sobre VPS (KVM) E5-2650 v4 (6 núcleos) 10GB DDR4 240GB SSD 1Gbps de $ 20 o cómo dividir el servidor? (las opciones están disponibles con RAID1 y RAID10, hasta 24 núcleos y hasta 40GB DDR4).
VPS (KVM) E5-2650 v4 (6 núcleos) 10GB DDR4 240GB SSD 1Gbps hasta enero de forma gratuita al pagar por un período de seis meses, puede ordenar aquí .Dell R730xd 2 veces más barato? ¡Solo tenemos
2 x Intel Dodeca-Core Xeon E5-2650v4 128GB DDR4 6x480GB SSD 1Gbps 100 TV desde $ 249 en los Países Bajos y los Estados Unidos! Lea sobre
Cómo construir un edificio de infraestructura. clase utilizando servidores Dell R730xd E5-2650 v4 que cuestan 9,000 euros por un centavo?