Instituto de Tecnología de Massachusetts. Conferencia Curso # 6.858. "Seguridad de los sistemas informáticos". Nikolai Zeldovich, James Mickens. Año 2014
Computer Systems Security es un curso sobre el desarrollo e implementación de sistemas informáticos seguros. Las conferencias cubren modelos de amenazas, ataques que comprometen la seguridad y técnicas de seguridad basadas en trabajos científicos recientes. Los temas incluyen seguridad del sistema operativo (SO), características, gestión del flujo de información, seguridad del idioma, protocolos de red, seguridad de hardware y seguridad de aplicaciones web.
Lección 1: "Introducción: modelos de amenaza"
Parte 1 /
Parte 2 /
Parte 3Lección 2: "Control de ataques de hackers"
Parte 1 /
Parte 2 /
Parte 3Lección 3: “Desbordamientos del búfer: exploits y protección”
Parte 1 /
Parte 2 /
Parte 3Lección 4: “Separación de privilegios”
Parte 1 /
Parte 2 /
Parte 3Lección 5: “¿De dónde vienen los sistemas de seguridad?”
Parte 1 /
Parte 2Lección 6: “Oportunidades”
Parte 1 /
Parte 2 /
Parte 3Lección 7: “Sandbox de cliente nativo”
Parte 1 /
Parte 2 /
Parte 3Lección 8: "Modelo de seguridad de red"
Parte 1 /
Parte 2 /
Parte 3Lección 9: "Seguridad de aplicaciones web"
Parte 1 /
Parte 2 /
Parte 3Lección 10: “Ejecución simbólica”
Parte 1 /
Parte 2 /
Parte 3Lección 11: "Ur / Lenguaje de programación web"
Parte 1 /
Parte 2 /
Parte 3Lección 12: Seguridad de red
Parte 1 /
Parte 2 /
Parte 3Lección 13: "Protocolos de red"
Parte 1 /
Parte 2 /
Parte 3Lección 14: "SSL y HTTPS"
Parte 1 /
Parte 2 /
Parte 3Lección 15: "Software médico"
Parte 1 /
Parte 2 /
Parte 3Lección 16: "Ataques de canal lateral"
Parte 1 /
Parte 2 /
Parte 3Lección 17: "Autenticación de usuario"
Parte 1 /
Parte 2 /
Parte 3Lección 18: "Navegación privada en Internet"
Parte 1 /
Parte 2 /
Parte 3Lección 19: "Redes anónimas"
Parte 1 /
Parte 2 /
Parte 3Lección 20: "Seguridad del teléfono móvil"
Parte 1 /
Parte 2 /
Parte 3Lección 21: “Datos de seguimiento”
Parte 1 /
Parte 2 /
Parte 3 Estudiante: Entonces, ¿el soporte arquitectónico es la solución ideal?
Profesor: sí, también hay métodos para esto. Sin embargo, esto es un poco complicado porque, como puede ver, resaltamos el estado de contaminación al lado de la variable misma. Por lo tanto, si piensa en el soporte proporcionado por el equipo en sí, puede ser muy difícil cambiar el diseño del hardware, porque aquí todo está integrado en silicio. Pero si es posible a un alto nivel en la máquina virtual Dalvic, uno puede imaginar que será posible colocar variables y su infección lado a lado en el nivel de hardware. Entonces, si cambia el diseño en silicio, entonces probablemente pueda hacer el trabajo.
 Estudiante:
Estudiante: ¿qué hace TaintDroid con información que se basa en los permisos de rama git, permisos de rama?
Profesor: volveremos a esto en un segundo, así que agárrate a este pensamiento hasta que lleguemos a él.
Estudiante: Me pregunto si pueden ocurrir desbordamientos del búfer aquí, porque estas cosas, las variables y sus infecciones, se acumulan.
Profesor: Esta es una buena pregunta. Uno esperaría que en un lenguaje como Java no haya desbordamiento de búfer. Pero en el caso del lenguaje C, puede suceder algo catastrófico, porque si de alguna manera hizo un desbordamiento del búfer y luego reescribió las etiquetas contaminantes para las variables, entonces sus valores cero se establecen en las pilas y los datos fluyen libremente en la red.
Estudiante: ¿Creo que todo esto se puede predecir?
Profesor: absolutamente cierto. El problema de los desbordamientos del búfer se puede resolver con la ayuda de "canarios": indicadores de pila, porque si tiene estos datos en la pila, entonces no desea que no se sobrescriban o no desea que los valores ya sobrescritos se rompan de alguna manera. Entonces tiene toda la razón: simplemente puede evitar el desbordamiento del búfer.
En resumen, el seguimiento de la contaminación se puede proporcionar a este bajo nivel x86 / ARM, aunque puede ser un poco costoso y un poco difícil de implementar de la manera correcta. Puede preguntar por qué estamos ante todo resolviendo el problema del seguimiento de infecciones en lugar de monitorear cómo el programa intenta enviar algo a través de la red, simplemente escaneando datos que nos parecen confidenciales. Esto parece bastante fácil, porque entonces no necesitamos monitorear dinámicamente todo lo que hace el programa.

El problema es que esto solo funcionará a nivel heurístico. De hecho, si un atacante sabe que usted está haciendo exactamente eso, puede descifrarlo fácilmente. Si solo te sientas allí e intentas obtener números de seguridad social, un atacante podría usar la codificación de base 64 o hacer algo estúpido, como la compresión. Pasar por alto este tipo de filtro es bastante trivial, por lo que en la práctica esto es completamente insuficiente para garantizar la seguridad.
Ahora volvamos a su pregunta sobre cómo podemos rastrear los flujos que fluyen a través de las ramas de las ramas. Esto nos llevará a un tema llamado Flujos implícitos o Flujos implícitos. Una secuencia implícita generalmente ocurre cuando tiene un valor infectado que afectará la forma en que asigna otra variable, incluso si esa variable de secuencia implícita no asigna variables directamente. Daré un ejemplo concreto.
Suponga que tiene una declaración if que mira su IMEI y dice: "si es mayor que 42, entonces asignaré x = 0, de lo contrario asignaré x = 1."
Curiosamente, primero miramos los datos confidenciales de IMEI y los comparamos con un cierto número, pero luego, al asignar x, no asignamos nada que se obtenga directamente de estos datos confidenciales.
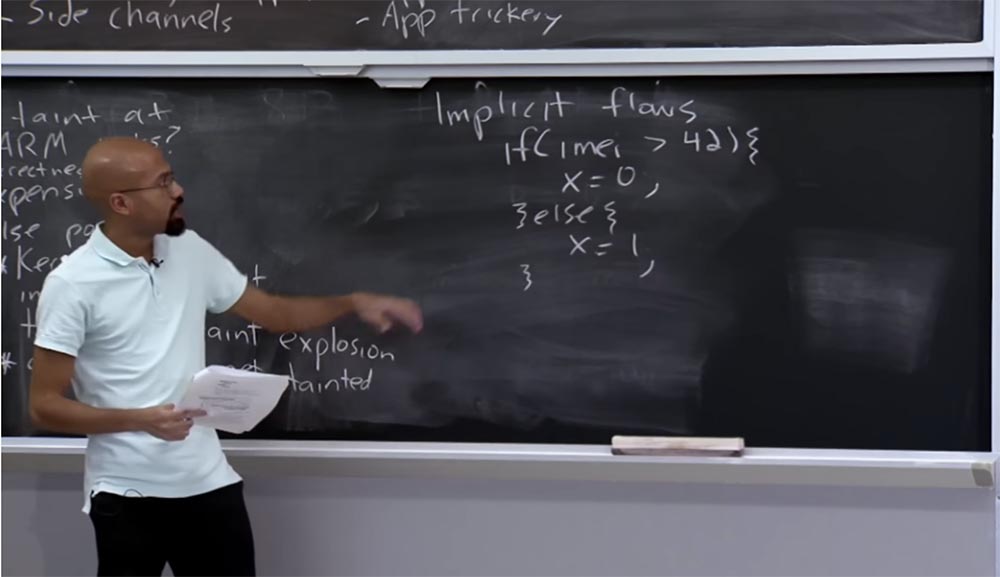
Este es un ejemplo de uno de los hilos implícitos. El valor de x realmente depende de la comparación anterior, pero el adversario, si es inteligente, puede construir su código de tal manera que no se pueda rastrear una conexión directa en él.
Tenga en cuenta que incluso aquí, en lugar de simplemente asignar x = 0, x = 1, simplemente puede poner el comando para enviar algo a través de la red, es decir, puede decir a través de la red que x = 0 o x = 1, o algo así Este es un ejemplo de uno de estos hilos implícitos que un sistema como TaintDroid no puede controlar. Entonces, esto se llama una secuencia implícita, en oposición a una secuencia explícita, por ejemplo, un operador de asignación. Entonces los desarrolladores son conscientes de este problema.
Si entendí correctamente, me preguntaron qué pasaría si tenemos algún tipo de función de máquina que haga algo similar al ejemplo anterior, y por lo tanto, el sistema TaintDroid no necesita saber esto, porque TaintDroid no podrá ver este código de máquina y ver cosas de ese tipo Por cierto, los desarrolladores afirman que controlarán esto usando métodos orientados a la máquina que están determinados por la máquina virtual y considerarán la forma en que se implementa este método. Por ejemplo, tomamos estos dos números y luego devolvemos su valor promedio. En este caso, el sistema TaintDroid confiará en la función de la máquina, por lo que debemos averiguar cuál debería ser la política de infección de contaminación adecuada.
Sin embargo, tiene razón en que si algo como esto estaba oculto dentro del código de la máquina y por alguna razón no fue sometido a una revisión abierta, entonces las políticas manuales inventadas por los autores de TaintDroid pueden no captar esta secuencia implícita. De hecho, esto puede permitir que la información se filtre de alguna manera. Además, incluso puede haber una transmisión directa, que los autores de TaintDroid no notaron, y podemos tener una fuga aún más directa.
 Estudiante:
Estudiante: es decir, en la práctica parece muy peligroso, ¿verdad? Porque literalmente puede borrar todos los valores infectados simplemente mirando las últimas 3 líneas.
Profesor: Tuvimos varias clases que examinaron cómo los flujos implícitos hacen tales cosas. Hay varias formas de arreglar esto. Una forma de evitar que esto suceda es asignar una etiqueta de contaminación a la PC, esencialmente infectándola con la prueba Branch. La idea es que, desde un punto de vista humano, podamos considerar este código y decir que este flujo implícito existe aquí, porque para llegar aquí, tuvimos que buscar datos confidenciales.
Entonces, ¿qué significa esto a nivel de implementación? Esto significa que para llegar aquí, la PC debe tener algo infectado con datos confidenciales. Es decir, podemos decir que recibimos estos datos porque la PC se instaló aquí - x = 0 - o aquí - x = 1.
En general, uno puede imaginar que el sistema llevará a cabo un análisis y descubrirá que los flujos implícitos de la PC no están infectados en este lugar, luego detecta la infección del IMEI, y en este punto donde x = 0, la PC ya está infectada. Al final, lo que sucede es que si x es una variable que se muestra inicialmente sin contaminación, entonces decimos: "OK, en este punto x = 0, obtenemos la infección de la PC, que en realidad estaba infectada arriba, en IMEI". Aquí hay algunas sutilezas, pero en general, puede rastrear cómo se instala la PC y luego intenta propagar la infección a los operadores objetivo.
¿Eso está claro? Si quieres saber más, entonces podemos hablar sobre este tema porque he investigado mucho de este tipo. Sin embargo, el sistema que acabo de describir puede volver a ser demasiado conservador. Imagine que, en lugar de x = 1, aquí, como arriba, también tenemos x = 0. En este caso, no tiene sentido infectar x con algo relacionado con IMEI, por lo tanto, no se puede filtrar información de estas ramas.
Pero si usa un esquema de infección de PC computarizado, puede sobreestimar cuántas variables x se han dañado. Hay algunas sutilezas que puede hacer para tratar de solucionar algunos de estos problemas, pero será un poco difícil.
Estudiante: cuando sale de la declaración if, también sale de Branch y se limpia de infección.
Profesor: como regla, sí, tan pronto como termine el conjunto de variables, la PC se limpiará de infección. La infección se establece solo dentro de estas ramas de x a x. La razón es que cuando bajas aquí lo haces sin importar cuál sea el IMEI.
Hablamos sobre cómo el seguimiento de infecciones en este nivel muy bajo es útil, aunque bastante costoso, porque realmente le permite ver cuál es la vida útil de sus datos. Hace un par de conferencias, hablamos sobre el hecho de que con frecuencia los datos clave viven en la memoria mucho más tiempo de lo que piensas.
Puede imaginar que si bien el seguimiento de infecciones x86 o ARM es bastante costoso, puede usar esto para auditar su sistema. Por ejemplo, puede infectar una clave secreta que un usuario ha ingresado y ver dónde y cómo se mueve en todo el sistema. Este es un análisis fuera de línea, no afecta a los usuarios, por lo que es normal que pueda ser lento. Tal análisis ayudará a descubrir, por ejemplo, que estos datos caen en el búfer del teclado, esto a un servidor externo, esto en otro lugar. Entonces, incluso si es un proceso lento, aún puede ser muy útil.
Como dije, una característica útil de TaintDroid es que limita el "universo" de fuentes de infección y absorbedores de información infectada. Pero como desarrollador, es probable que desee tener un control más preciso sobre las marcas de infección con las que interactúa su programa. Por lo tanto, como programador, querrás hacer lo siguiente.
Entonces, declaras un int de este tipo y lo llamas X, y luego le unes una etiqueta. El significado de esta etiqueta es que Alice es la propietaria de la información que le permite a Bob ver, o que esta información está marcada para que Bob la vea. TaintDroid no le permite hacer esto, porque esencialmente controla este universo de etiquetas, pero como programador, es posible que desee hacer esto.
Suponga que su programa tiene canales de entrada y salida, y también están etiquetados. Estas son las etiquetas que eligió como programador, a diferencia del sistema en sí, tratando de decir que tales cosas están predeterminadas de antemano. Digamos que para los canales de entrada establece valores de lectura que obtienen la etiqueta del canal.
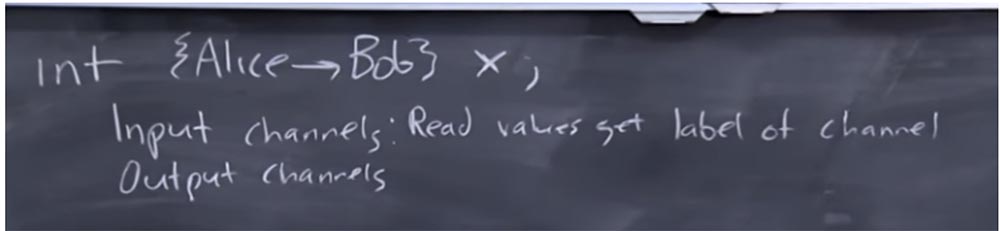
Esto es muy similar a cómo funciona TaintDroid: si se leen los valores del sensor GPS, se marcan con la etiqueta contaminante del canal GPS, pero ahora, como programador, selecciona estas etiquetas usted mismo. En este caso, la etiqueta del canal de salida debe coincidir con el valor de la etiqueta que grabamos.

Aquí se pueden introducir otras políticas, pero la idea principal es que hay administradores de programas que permiten que el desarrollador elija qué tipo de etiquetas son y cuáles podrían ser sus semánticas. Esto requerirá mucho trabajo del programador, cuyo resultado será la capacidad de realizar una verificación estática. Por estático quiero decir una verificación que se realiza en tiempo de compilación y puede "atrapar" muchos tipos de errores de flujo de información.
Entonces, si etiqueta cuidadosamente todos los canales de red y los canales de pantalla con etiquetas con los permisos apropiados, y luego coloca cuidadosamente sus datos, que se dan como ejemplo en el tablero, entonces durante la compilación el compilador podrá decirle: "oye, si ejecuta este programa, entonces puede experimentar una fuga de información porque parte de los datos pasarán por un canal en el que no se confía ".
En un nivel alto, una comprobación estática puede detectar muchos de estos errores, porque tales comentarios int {Alice Bob} x son un poco como los tipos. Del mismo modo que los compiladores pueden detectar errores relacionados con los tipos en un lenguaje de tipos, pueden funcionar igual de bien con el código escrito en el lenguaje anterior, diciendo que si ejecuta este programa, puede ser un problema. Por lo tanto, debe corregir la forma en que funcionan las etiquetas, es posible que deba desclasificar algo, etc.
Por lo tanto, dependiendo del idioma, estas etiquetas pueden asociarse con personas, con puertos de E / S y similares. TaintDroid le brinda la oportunidad de familiarizarse con los principios de funcionamiento de los flujos de información y las fugas de información, sin embargo, existen sistemas más complejos con una semántica más pronunciada para administrar estos procesos.
Tenga en cuenta que cuando hablamos de verificación estática, es preferible que detectemos la mayor cantidad posible de fallas y errores con la ayuda de la verificación estadística, en lugar de la verificación dinámica. Hay una razón muy delicada para esto. Supongamos que posponemos todas las comprobaciones estáticas durante la duración de un programa, lo que definitivamente podemos hacer.
El problema es que el fracaso o el éxito de estas comprobaciones es un canal implícito. Por lo tanto, un atacante puede proporcionar información al programa y luego verificar si esto provocó el bloqueo del programa. Si ocurre una falla, el hacker puede decir: "Sí, pasamos por una verificación dinámica del flujo de información, por lo que aquí hay algún secreto sobre los valores que afectan el proceso de cálculo". Por lo tanto, querrá intentar hacer estas comprobaciones lo más estáticas posible.
Si desea obtener más información sobre estas cosas, debe consultar Jif. Este es un sistema muy poderoso que ha creado etiquetas de métodos de cálculo de etiquetas. Puede comenzar con él y avanzar en esa dirección aún más. Mi colega, el profesor Zeldovich, ha hecho mucho bien en esta área, por lo que puede hablar con él sobre este tema.
Curiosamente, TaintDroid tiene una capacidad muy limitada para ver y describir etiquetas. Hay sistemas que le permiten hacer cosas más poderosas.
Finalmente, me gustaría hablar sobre lo que podemos hacer si queremos rastrear los flujos de información usando programas tradicionales o usando programas escritos en C o C ++ que no admiten todas estas cosas en el proceso de ejecución de código. Existe un sistema TightLip muy razonable, y algunos de los autores del mismo artículo están considerando cómo rastrear las filtraciones de información en un sistema en el que no queremos cambiar nada en la aplicación misma.
La idea básica es que el concepto de procesos doppelganger, o "contrapartes de proceso", se usa aquí. TightLip usa un proceso doble por defecto. Lo primero que hace es escanear periódicamente el sistema de archivos del usuario, buscando tipos de archivos confidenciales. Podría ser algo como archivos de correo electrónico, documentos de texto, etc. Para cada uno de estos archivos, el sistema crea su versión "limpia". Es decir, en el archivo de mensaje de correo electrónico, reemplaza la información "hacia" o "desde" con una cadena de la misma longitud que contiene datos ficticios, por ejemplo, espacios. Esto se ejecuta como un proceso en segundo plano.
Lo segundo que hace TightLip cuando se inicia un proceso es determinar si el proceso está intentando acceder a un archivo confidencial. Si se realiza dicho acceso, TightLip crea un doble de este proceso. Este doble se ve exactamente como el proceso original, que trata de afectar los datos confidenciales, pero la diferencia fundamental es que el doble, lo designaré DG, lee los datos borrados.

Imagine que está en el proceso de intentar acceder a su archivo de correo electrónico. El sistema genera este nuevo proceso, doppelganger, exactamente igual que el original, pero ahora lee los datos limpios en lugar de los datos confidenciales reales. Esencialmente, TightLip ejecuta ambos procesos en paralelo y los observa para ver qué están haciendo. , , , . , , - , , – , , , -, .

, , TightLip , . , . , , , , . , TaintDroid, , : «, , , , - ».
, , , - . TaintDroid, , - , . — , — . , , , , , .
: , - Word, , - .
: , . , . . Word. - , - , . .
: , , ? - .
: , . , , , - , . , . «» , , , .
, , , , , , , .

– , TightLip TCB, , -, . , . . , , . TightLip.
, . taint .
: , ? , ?
: ! - DG , , . , , , -, , .
, .
.
Gracias por quedarte con nosotros. ¿Te gustan nuestros artículos? ¿Quieres ver más materiales interesantes?
Apóyenos haciendo un pedido o recomendándolo a sus amigos, un
descuento del 30% para los usuarios de Habr en un análogo único de servidores de nivel de entrada que inventamos para usted: toda la verdad sobre VPS (KVM) E5-2650 v4 (6 núcleos) 10GB DDR4 240GB SSD 1Gbps de $ 20 o cómo dividir el servidor? (las opciones están disponibles con RAID1 y RAID10, hasta 24 núcleos y hasta 40GB DDR4).
VPS (KVM) E5-2650 v4 (6 Cores) 10GB DDR4 240GB SSD 1Gbps ,
.
Dell R730xd 2 veces más barato? ¡Solo tenemos
2 x Intel Dodeca-Core Xeon E5-2650v4 128GB DDR4 6x480GB SSD 1Gbps 100 TV desde $ 249 en los Países Bajos y los Estados Unidos! Lea sobre
Cómo construir un edificio de infraestructura. clase utilizando servidores Dell R730xd E5-2650 v4 que cuestan 9,000 euros por un centavo?