Nota perev. : Este artículo continúa la serie de materiales sobre el dispositivo básico de redes en Kubernetes, que se describe de forma accesible y con ilustraciones ilustrativas (sin embargo, prácticamente no había ilustraciones en esta parte del concreto todavía). Traduciendo las dos partes anteriores de esta serie, las combinamos en una publicación , que hablaba sobre el modelo de red K8 (interacción dentro de los nodos y entre nodos) y redes superpuestas. Su lectura preliminar es deseable (recomendada por el propio autor). La continuación está dedicada a los servicios de Kubernetes y al procesamiento del tráfico saliente y entrante.
NB : Para la conveniencia del autor, el texto del autor se complementa con enlaces (principalmente a la documentación oficial de K8).
Dinámica de clúster
Debido a la naturaleza cambiante y dinámica de Kubernetes y de los sistemas distribuidos en general, los pods (y, como resultado, sus direcciones IP) también cambian constantemente. Las razones de esto varían desde las actualizaciones entrantes para lograr el estado deseado y los eventos que conducen a la escala, hasta bloqueos imprevistos del pod o nodo. Por lo tanto, las direcciones IP del pod no se pueden usar directamente para la comunicación.
El
servicio en Kubernetes entra en juego: una IP virtual con un grupo de direcciones IP de pod que se utilizan como puntos finales e identificados a través de
selectores de etiquetas . Dicho servicio funciona como un equilibrador de carga virtual, cuya dirección IP permanece constante y, al mismo tiempo, las direcciones IP del pod que presenta pueden cambiar constantemente.
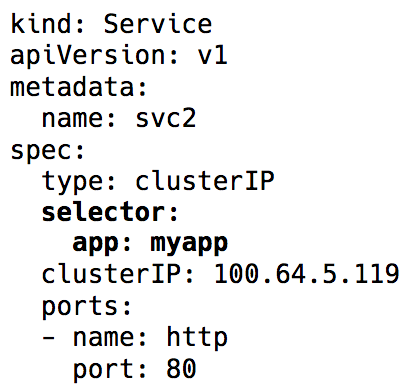 Selector de etiquetas en objeto de servicio en Kubernetes
Selector de etiquetas en objeto de servicio en KubernetesDetrás de toda la implementación de esta IP virtual hay reglas de iptables (las últimas versiones de Kubernetes también tienen
la capacidad de usar IPVS, pero este es un tema para otra discusión), que están controladas por un componente de Kubernetes llamado
kube-proxy . Sin embargo, tal nombre es engañoso en las realidades de hoy. Kube-proxy se usó realmente como proxy en los días previos al lanzamiento de Kubernetes v1.0, pero esto condujo a un gran consumo de recursos y frenos debido a las constantes operaciones de copia entre el espacio del kernel y el espacio del usuario. Ahora es solo un controlador, como muchos otros controladores en Kubernetes. Supervisa el servidor API en busca de cambios en los puntos finales y actualiza las reglas de iptables en consecuencia.
De acuerdo con estas reglas de iptables, si el paquete está destinado a la dirección IP del servicio, se realiza una Traducción de dirección de red de destino (DNAT): esto significa que su dirección IP cambiará de la IP del servicio a uno de los puntos finales, es decir. una de las direcciones IP del pod, que iptables selecciona aleatoriamente. Esto asegura que la carga se distribuya uniformemente entre las vainas.
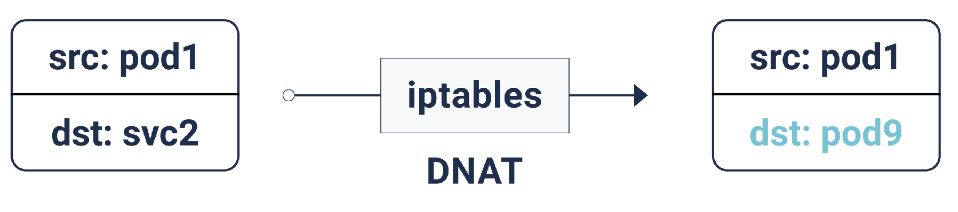 DNAT en iptables
DNAT en iptablesEn el caso de tal DNAT, la información necesaria se almacena en
conntrack : la tabla de contabilidad de conexión en Linux (almacena las traducciones de cinco pares realizadas por iptables:
protocol ,
srcIP ,
srcPort ,
dstIP ,
dstPort ). Todo está organizado de tal manera que cuando se devuelve una respuesta, puede ocurrir una operación inversa de DNAT (un-DNAT), es decir, Reemplazar la fuente de IP de Pod IP a Service IP. Gracias a este cliente, no hay absolutamente ninguna necesidad de saber cómo trabajar con paquetes detrás de escena.
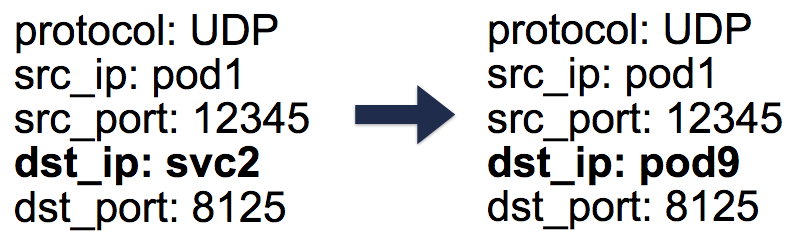 Entradas de cinco pares (5 tuplas) en la tabla conntrack
Entradas de cinco pares (5 tuplas) en la tabla conntrackEntonces, utilizando los servicios de Kubernetes, podemos trabajar con los mismos puertos sin ningún conflicto (porque es posible la reasignación de puertos a puntos finales). Esto hace que el descubrimiento de servicios sea muy fácil. Es suficiente usar el DNS interno y codificar el host de los servicios. Incluso puede usar las variables preconfiguradas de Kubernetes con el host y el puerto de servicio.
Sugerencia : ¡Al elegir la segunda ruta, ahorrará muchas llamadas DNS innecesarias!
Tráfico saliente
Los servicios de Kubernetes descritos anteriormente funcionan dentro de un clúster. En la práctica, las aplicaciones generalmente necesitan acceso a algunos API / sitios externos.
En general, los hosts pueden tener direcciones IP privadas y públicas. Para acceder a Internet, se proporciona un NAT uno a uno para estas direcciones IP privadas y públicas; esto es especialmente cierto para entornos de nube.
Para la interacción normal del host con la dirección IP externa, la IP de origen cambia de la IP del host privado a la IP pública para los paquetes salientes y los paquetes entrantes, en la dirección opuesta. Sin embargo, en los casos en que el pod inicia la conexión a la IP externa, la dirección IP de origen es el IP Pod, que el mecanismo NAT del proveedor de la nube desconoce. Por lo tanto, simplemente descartará los paquetes con direcciones IP de origen que sean diferentes de las direcciones IP del host.
Y aquí, lo has adivinado, ¡necesitaremos iptables aún más! Esta vez, las reglas, que también son agregadas por kube-proxy, son realizadas por SNAT (traducción de dirección de red de origen), también conocida como
IP MASQUERADE (enmascarado). En lugar de indicar la dirección IP de origen, se le dice al núcleo que use la interfaz IP de la que proviene el paquete. En conntrack, también aparece un registro para una mayor ejecución de la operación inversa (un-SNAT) en la respuesta.
Tráfico entrante
Hasta ahora, todo estaba bien. Las cápsulas pueden comunicarse entre sí y con Internet. Sin embargo, todavía nos falta lo principal: servir el tráfico de usuarios. Actualmente hay dos formas de implementarlo:
1. NodePort / Cloud Load Balancer (nivel L4: IP y puerto)
Establecer
NodePort como el tipo de servicio asignará el servicio
NodePort en el rango de 30,000–33,000. Este
nodePort abierto en todos los nodos, incluso cuando no se está ejecutando ningún pod en el nodo. El tráfico entrante en este
NodePort dirige a uno de los pods (¡que incluso puede aparecer en otro nodo!), Nuevamente usando iptables.
El tipo de servicio
LoadBalancer en
LoadBalancer en la nube crea un equilibrador de carga en la nube (por ejemplo, ELB) frente a todos los nodos, trabajando más con el mismo
NodePort .
2. Ingreso (nivel L7: HTTP / TCP)
Muchas otras implementaciones también realizan mapeo de host / ruta HTTP con backends correspondientes, por ejemplo, nginx, traefik, HAProxy, etc. Con ellos, LoadBalancer y NodePort nuevamente se convierten en el punto de entrada para el tráfico, pero aquí existe la ventaja de que solo necesitamos un Ingress para atender el tráfico entrante de todos los servicios en lugar de numerosos NodePort / LoadBalancers.
Políticas de red
Las políticas de red pueden considerarse grupos de seguridad / ACL para pods.
NetworkPolicy reglas de
NetworkPolicy permiten / niegan el tráfico entre pods. Su implementación exacta depende de la capa de red / CNI, pero la mayoría de ellos simplemente usan iptables.
...
Eso es todo En las
entregas anteriores, aprendimos los conceptos básicos de las redes en Kubernetes y cómo funcionan las superposiciones. Ahora sabemos cómo la abstracción del servicio ayuda en un clúster dinámico y hace que el descubrimiento de servicios sea realmente simple. También examinamos cómo fluye el tráfico saliente / entrante y qué políticas de red pueden ser útiles para proteger un clúster.
PD del traductor
Lea también en nuestro blog: