
Nos esforzamos por garantizar que, después de ordenar un taxi al usuario, le llegue al usuario un automóvil limpio y útil de la marca, el color y el número que aparece en la aplicación. Y para esto usamos control remoto de calidad (DCC).
Hoy les contaré a los lectores de Habr cómo usar el aprendizaje automático para reducir el costo del control de calidad en un servicio en rápido crecimiento con cientos de miles de máquinas y no poner en línea una máquina que no cumple con las reglas del servicio.
¿Cómo se organizó DCC antes del aprendizaje automático?
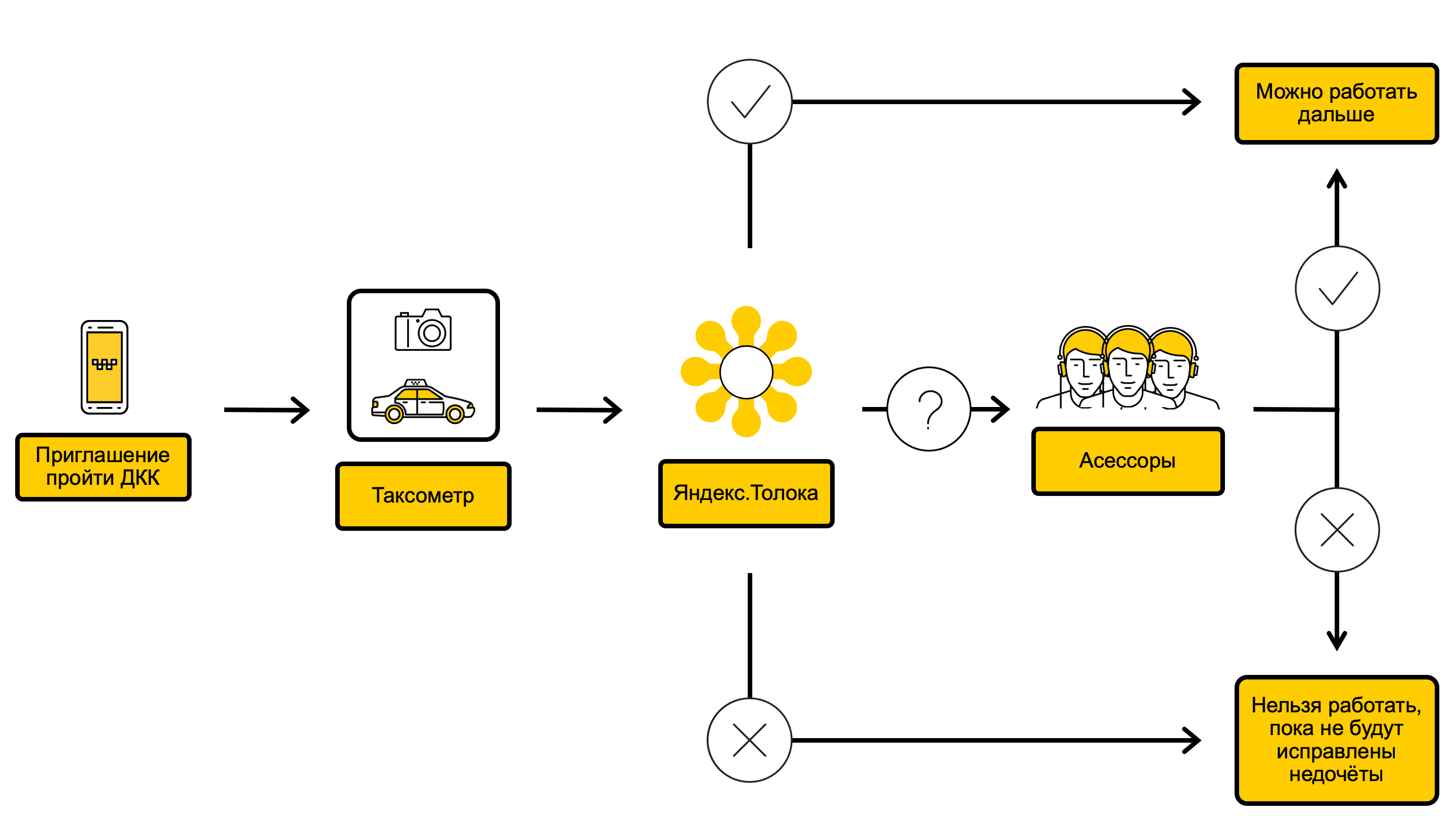
Diagrama de proceso DCC
En el proceso de DCC, verificamos las fotos del automóvil y tomamos una decisión sobre si es posible cumplir con los pedidos de dicho automóvil o, por ejemplo, si se debe lavar antes. Todo comienza con el hecho de que a través de la aplicación de taxímetro Taximeter llamamos al controlador en el DCC. Esto generalmente ocurre una vez cada 10 días, pero a veces con menos frecuencia o con mayor frecuencia, dependiendo de qué tan exitosamente el conductor haya pasado las comprobaciones anteriores. Inmediatamente después de una llamada al DCC, el conductor recibe un mensaje invitándolo a someterse a un control fotográfico. Tan pronto como el conductor aceptó la invitación, en la misma solicitud, fotografía el exterior y el interior del automóvil desde diferentes ángulos y le envía fotos Yandex.Taxi. El conductor puede tomar pedidos mientras el DCC está encendido.

Pantalla de inicio de DCC en la aplicación de taxímetro

Pantalla para fotografiar un automóvil en la aplicación Taxímetro
Las fotos resultantes caen en Yandex.Toloka , un servicio en el que, utilizando crowdsourcing, puede realizar rápidamente tareas simples, pero de gran volumen. Sobre cómo funciona y por qué se necesita Yandex.Tolok, escribimos en nuestro blog .
En Yandex.Tolok, en el transcurso de una verificación, al menos tres artistas responden preguntas sobre el estado del automóvil, y si los artistas aceptan de acuerdo con sus respuestas, se decide si el conductor puede aceptar pedidos. Los cheques en Yandex.Tolok tienen dos resultados:
- Si todo está bien visualmente con el automóvil, el conductor continúa tomando órdenes.
- Si el automóvil está sucio, dañado o su marca, color o número no coincide con los indicados en la tarjeta del conductor, Yandex.Taxi limita temporalmente la capacidad del conductor para aceptar pedidos.
Si los artistas intérpretes o ejecutantes no llegan a un consenso, las fotos se envían a los empleados de Yandex.Taxi: asesores que revisan el automóvil más a fondo y luego toman la decisión final. Los evaluadores se someten a un programa de capacitación especial y tienen más experiencia.

Así ve el ejecutor de DCC Yandex.Tolki
Desafío
Con el crecimiento de Yandex.Taxi, el número de inspecciones de DCC también está creciendo, lo que significa que los costos de los tolkers y asesores están aumentando. Además, la velocidad de revisar el auto disminuye. Mientras el DCC está en progreso, puede permitir que los conductores acepten pedidos o no. Ambas opciones tienen sus inconvenientes: en el primer caso, un conductor inescrupuloso tendrá tiempo para aceptar varias órdenes de un automóvil que no cumpla con los estándares, en el segundo: todos los conductores que solicitan el control de la fotografía no podrán trabajar hasta que se complete la verificación. Por lo tanto, es importante revisar los automóviles rápidamente para que tanto los usuarios como los conductores no encuentren ningún inconveniente.
Al observar cómo crecen los gráficos de costos y el tiempo promedio de escaneo, nos dimos cuenta de que queremos reducir el costo de Toloka, descargar evaluadores y reducir el tiempo promedio de escaneo, en otras palabras, para automatizar parte de las verificaciones. Naturalmente, no queríamos sacrificar la calidad del servicio y perder más autos que no cumplían con los estándares de calidad de la línea, y tampoco queríamos limitar la aceptación de pedidos por parte de conductores de buena fe. Necesitábamos automatizar el DCC y, al mismo tiempo, no aumentar la proporción de errores en el flujo general de verificaciones.
Cómo implementamos el aprendizaje automático en DCC
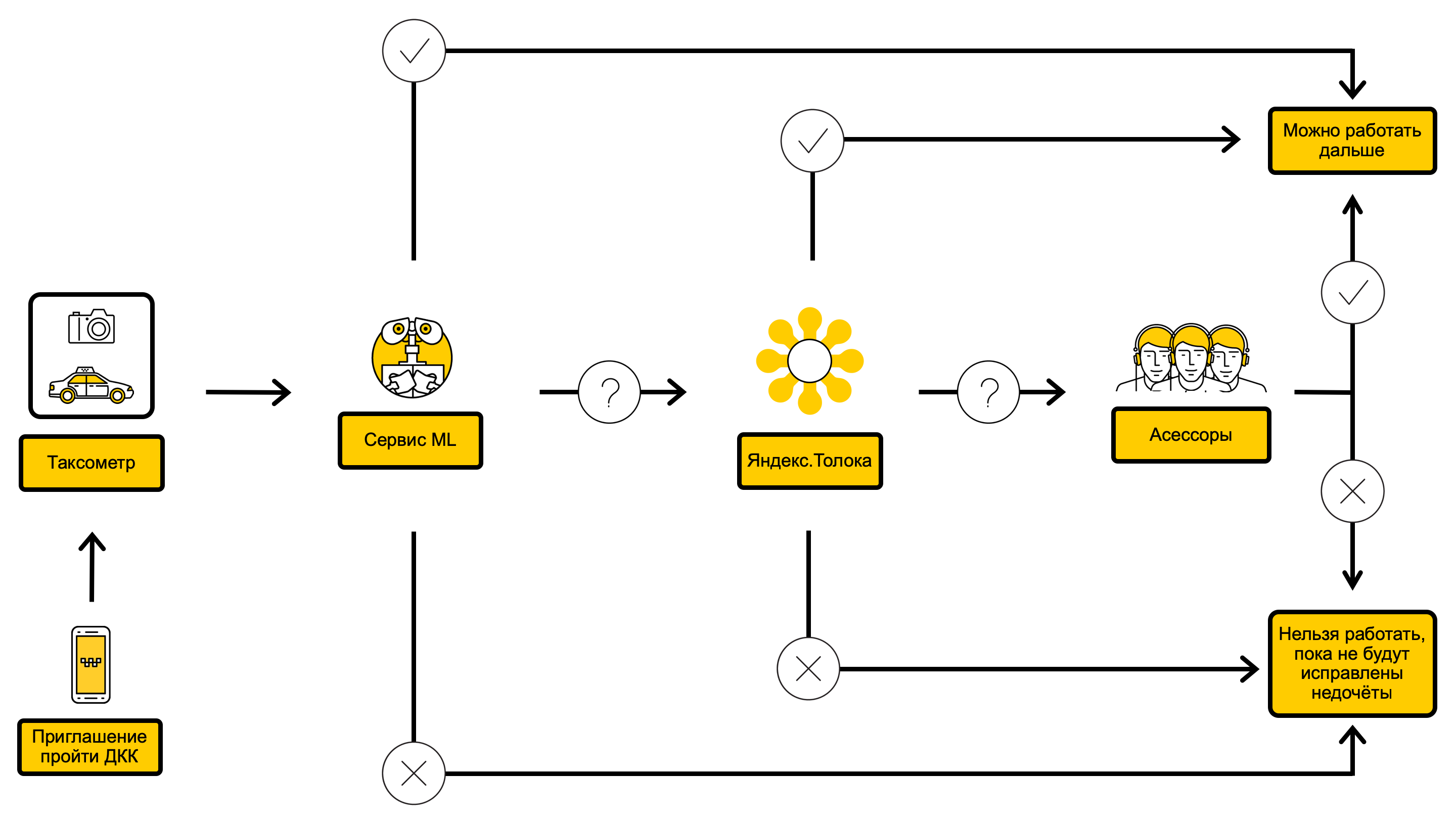
Diagrama de proceso DCC con ML dentro
Para empezar, decidimos sobre el planteamiento del problema: automatizar tantas verificaciones como sea posible, sin aumentar la tasa de error en el flujo general.
Veamos qué errores hay en nuestra tarea. Vienen en dos formas: falso positivo y falso negativo . En nuestra terminología, negativo es el resultado de un cheque con el que el conductor puede continuar trabajando, y positivo es el resultado que implica un límite de tiempo en la recepción de pedidos. Entonces falso negativo es un caso en el que nos vimos obligados a permitir que un conductor con un auto en mal estado acepte pedidos, y falso positivo , por el contrario, cuando no permitimos que un conductor trabaje con un automóvil que está bien. Resulta que la tasa de falsos negativos (FNR, por sus siglas en inglés) es la proporción de conductores con automóviles “malos” que nos permitieron aceptar pedidos, y la tasa de falsos positivos (FPR) es el porcentaje de conductores con los que no se nos permitió trabajar, aunque están bien con los automóviles. Por lo tanto, desde la introducción del aprendizaje automático en el sistema, queríamos lo siguiente: automatizar tantas comprobaciones como fuera posible, sin aumentar el FPR y el FNR en comparación con un sistema sin aprendizaje automático.
Además, era necesario comprender qué métricas deben guiarse al elegir modelos y umbrales para tomar decisiones basadas en sus predicciones. A partir de las condiciones del problema, está claro que estamos interesados en tres cantidades:
- La fracción del hilo que los modelos de aprendizaje automático pueden responder automáticamente.
- Sistemas FNR.
- Sistemas FPR.
Maximizamos el primer valor mientras observamos las restricciones en el segundo y el tercero.
Esto puede plantear la pregunta: ¿por qué no maximizar el ahorro de dinero o minimizar el tiempo promedio de exploración directamente, y no a través de la participación de cheques automáticos? La optimización del dinero es una idea muy atractiva, pero generalmente difícil de implementar. En nuestro caso, los ahorros consisten en dos factores: el primero es el ahorro de cada cheque automatizado, porque cada cheque en los asesores o en Yandex.Tolok cuesta dinero; el segundo: ahorrar al reducir la cantidad de errores, porque cada error le cuesta dinero a Yandex.Taxi. Calcular objetivamente cuánto nos cuestan los errores es una tarea muy difícil, por lo tanto, estamos limitados a calcular los ahorros solo por el primer factor. Este valor aumenta monotónicamente en la proporción de controles automáticos, de modo que esta fracción se puede maximizar en lugar de ahorrar. El mismo razonamiento se aplica al tiempo promedio de DCC; también disminuye de manera monótona de acuerdo con la proporción de controles automáticos.
Selección de modelo
Podemos decir que la verificación DCC se reduce a la elección de opciones de respuesta para una serie de preguntas sobre el estado del automóvil a partir de sus fotografías, y esto suena como una tarea de clasificación de imágenes. Dichas tareas se resuelven mediante visión artificial y, en nuestro tiempo, una herramienta específica, redes neuronales convolucionales. Decidimos usarlos para la automatización DCC.
La primera solución o enfoque "todo a la vez"
Ahora que hemos entendido qué optimizar y por qué, es hora de recopilar datos y entrenar modelos en ellos. Fue fácil recopilar datos, porque todas las comprobaciones de DCC se registran y almacenan de forma conveniente. En la primera versión de la solución, las fotos del exterior e interior del automóvil desde cuatro ángulos, la marca, el modelo y el color del automóvil, así como los resultados de 10 inspecciones anteriores de DCC, se usaron como signos. Como variables objetivo, tomamos las respuestas a todas las preguntas de verificación, por ejemplo: "¿Está dañado el automóvil?" o "¿El color del automóvil coincide con el de la tarjeta del conductor?" La variable objetivo principal fue la respuesta a la pregunta principal: "¿Es necesario limitar la capacidad del conductor para tomar órdenes?" Enseñamos un modelo grande, muy similar a VGG con atención SENet, para responder todas las preguntas al mismo tiempo y, como resultado, encontramos varios problemas.

Enfoque todo en uno
Problemas del enfoque "todo a la vez":
- No pudimos responder la pregunta sobre la correspondencia del número de automóvil en la foto indicada en la tarjeta del conductor. Una gran red para clasificar imágenes no podría hacer frente a esta tarea, para esto necesitamos un modelo especial de reconocimiento óptico de caracteres (OCR), afilado para reconocer las placas.
- La variable objetivo era incompleta y ruidosa. Al encontrar una falla grave en la apariencia del automóvil, que fue suficiente para tomar una decisión, los asesores a menudo se olvidaron de responder otras preguntas. Entonces, si el auto en la foto estaba sucio y roto, entonces con alta probabilidad observamos solo una de las marcas: “auto sucio” o “auto con daños”, mientras que ambos modelos eran necesarios para nuestro modelo.
- No hubo interpretabilidad de la solución modelo. El modelo podría responder la pregunta de verificación principal con una precisión mayor que la aleatoria, pero esta respuesta se correlacionó débilmente con las respuestas a otras preguntas. En otras palabras, si la respuesta fue: "Es necesario limitar la capacidad de tomar órdenes", casi nunca vimos la razón de tal decisión en las respuestas restantes del modelo. En general, la precisión de las respuestas a todas las preguntas, excepto la principal, fue casi aleatoria. No pudimos explicarle al conductor qué era exactamente lo que debía arreglarse para tomar órdenes nuevamente, lo que significa que no podíamos limitar la capacidad del conductor para tomar órdenes.
- El número de errores falsos negativos en la respuesta a la pregunta: "¿Es necesario limitar la capacidad del conductor para tomar pedidos?" - era demasiado grande para comenzar a aprobar cheques automáticamente. No pudimos proporcionar el mismo FNR que en un sistema que se ejecuta sin aprendizaje automático, y este fue uno de los requisitos en nuestra tarea.
Juntas, estas cuatro razones no nos permitieron poner en práctica la primera solución, pero no nos desanimamos y se nos ocurrió la segunda.
La segunda solución, o el enfoque de "todo menos gradualmente"
Decidimos centrarnos en verificar el exterior del automóvil, ya que representan aproximadamente el 70% del flujo total. Además, decidimos dividir la tarea general en subtareas y aprender a responder todas las preguntas de DCC por separado.

Enfoque "todo, pero poco a poco"
Érase una vez, nuestro servicio ya se dedicaba a la automatización de DCC y logró introducir un modelo que le permite filtrar fotos oscuras e irrelevantes. Continuamos usando este modelo para responder la pregunta: "¿Están presentes las siguientes fotos reales del automóvil: delantero, izquierdo, derecho, trasero?".
Nuestro trabajo en la segunda solución comenzó con el hecho de que usamos el modelo Yandex. Busque el modelo de servicio de visión por computadora (de las mismas personas que fabricaron DeepHD ) para reconocer las matrículas de los automóviles. Entonces pudimos responder la pregunta: "¿El número y el código de la región del automóvil se corresponden totalmente con los indicados en la tarjeta del conductor?" Si hablamos de esto con más detalle, comparamos el resultado del reconocimiento con el número indicado en la tarjeta del conductor y, dependiendo de la distancia de Levenshtein entre ellos, elegimos una de las opciones de respuesta: "el número coincide", "el número no coincide" o "la pregunta no se puede responder exactamente".
Luego, capacitamos a los clasificadores de automóviles para que reconozcan las marcas y modelos, así como los colores. A partir de este momento podríamos responder la pregunta: "¿La marca, el modelo y el color del automóvil están indicados en la tarjeta del conductor?"
En conclusión, capacitamos a los clasificadores para encontrar autos dañados y sucios, esto nos permitió cerrar las preguntas: "¿Hay daños o defectos en la carrocería del automóvil?" y "¿Qué tan sucia está la carrocería del automóvil?"
El enfoque "todo menos gradual" nos permitió resolver el problema de verificar el número de matrícula de un automóvil. También pudimos deshacernos del carácter incompleto y ruidoso de la variable objetivo, porque ahora teníamos una selección en la que los objetos de clase negativos eran verificaciones completamente exitosas, y los objetos de clase positivos verificaban dónde el evaluador o los tres ejecutores de Yandex.Tolki encontraron un cierto defecto, por ejemplo, daños en el caso . Después de resolver los dos primeros problemas, nuestros modelos se volvieron interpretables, y pudimos explicarle al conductor la razón de la limitación, de modo que en la próxima prueba corregiría los defectos. La calidad general de las respuestas a las preguntas también ha crecido significativamente, y FPR y FNR para algunas combinaciones de umbrales de confianza del modelo han caído al nivel Yandex.Tolki, lo que permitió que los modelos se introdujeran en producción.
Implementación en producción
Teníamos una opción: lanzar un proceso regular que aplicará los modelos a los cheques acumulados en la cola, o hacer un servicio separado donde pueda ir a través de la API y recibir respuestas del modelo en tiempo real. Como es importante para nosotros encontrar rápidamente automóviles "malos", elegimos la segunda opción. Tan pronto como se escribió la parte principal del servicio y pudo soportar la funcionalidad necesaria, comenzamos a agregarle modelos.
Para aprobar completamente la verificación, debe poder responder todas las preguntas de la instrucción, pero para limitar el acceso de los conductores sin escrúpulos al servicio, en algunos casos es suficiente para poder responder al menos una pregunta. Por lo tanto, decidimos no esperar hasta que todos los modelos estén listos, sino agregarlos a medida que estén disponibles. Una línea generalizada de agregar un modelo se ve así:
- Recoge la muestra.
- Entrenar a la modelo.
- Mida la calidad y elija umbrales fuera de línea.
- Agregue un modelo al servicio en segundo plano y mida la calidad en línea.
- Incluya el modelo en la producción y comience a tomar decisiones basadas en sus predicciones.
Este enfoque nos permitió no solo encontrar instantáneamente más y más automóviles "malos" a medida que se introducían nuevos modelos, sino también medir la calidad en línea sin costos de tiempo adicionales mientras los modelos trabajaban en segundo plano.
Al final, llegó el momento en que agregamos al servicio y probamos el último modelo. Ahora podríamos responder a todas las preguntas de las inspecciones, lo que significa que se aprobarán automáticamente. Dado que hay muchos más autos "buenos" en Yandex.Taxi que "malos", la aprobación automática de las inspecciones ha llevado a un fuerte aumento en nuestra métrica principal, parte del flujo de inspecciones automáticas. Solo podíamos elegir los umbrales correctos que maximizaran la participación de las verificaciones automáticas, mientras se mantenía el FPR y FNR generales de todo el sistema al mismo nivel. Para seleccionar los umbrales, utilizamos una muestra que fue marcada independientemente por los ejecutivos, asesores de Yandex.Tolkey y un empleado de Yandex.Taxi que capacitó a los asesores para revisar los automóviles. Utilizamos su marcado como los valores verdaderos de la variable objetivo.
Resultados
Tan pronto como incluimos modelos en la producción, fue necesario medir la calidad en línea de las decisiones tomadas en función de sus respuestas. Y aquí están los números que vimos:
- El 30% de los controles exteriores del vehículo ahora recibió una respuesta automática.
- FNR se mantuvo en el mismo nivel, mientras que FPR cayó, y comenzamos a restringir con menos frecuencia el acceso al servicio a aquellos que no lo merecían.
- La carga sobre los evaluadores disminuyó en un 14%, y pudieron dedicar más tiempo a pruebas complejas que el servicio de aprendizaje automático no pudo realizar.
- El tiempo de detección para automóviles con fallas graves durante la inspección se redujo de unas pocas horas a unos segundos.
Por lo tanto, la introducción del aprendizaje automático no solo ayudó a ahorrar dinero, sino que también hizo que el servicio fuera más seguro y cómodo para los usuarios. Sin embargo, esto está lejos del final de la historia. Nuestro equipo de rápido crecimiento continuará trabajando activamente para automatizar aún más controles y hacer que Yandex.Taxi sea aún más conveniente, cómodo y seguro.
Moraleja de la historia
Mientras trabajábamos en la automatización DCC en Yandex.Taxi, encontramos muchos problemas, encontramos varias soluciones exitosas y sacamos seis conclusiones importantes:
- No siempre es posible resolver el problema de frente (incluso si tiene un aprendizaje profundo).
- El modelo es tan bueno como los datos en los que fue entrenado (suena cursi, pero lo es).
- Al resolver cualquier problema, es importante aprovechar las necesidades reales del negocio y no minimizar la entropía cruzada.
- Al resolver algunos problemas, las personas siguen siendo importantes, a pesar de la introducción del aprendizaje automático (hola, Yandex.Toloka!).
- Es posible que las decisiones basadas en predicciones de modelos de aprendizaje automático no se tomen en todos los casos, sino solo en la parte en que los modelos tienen mucha confianza en sus respuestas. En otros casos, probablemente valga la pena tomar decisiones a la antigua usanza, con la ayuda de las personas.
- Además de la elección de la arquitectura y la capacitación en modelos, hay muchas más etapas del proyecto que pueden afectar en gran medida la forma en que se resuelve un problema empresarial. Estas etapas son: recopilación de datos, selección de métricas de calidad, opciones de implementación del modelo, lógica de toma de decisiones del producto basada en predicciones del modelo y mucho más.
Más de interesante sobre tecnología Taxi
Precios dinámicos, o cómo Yandex.Taxi predice una alta demanda .
Cómo Yandex.Taxi predice los tiempos de entrega de automóviles utilizando el aprendizaje automático .