Al desarrollar un producto, rara vez prestan la debida atención a su rendimiento con una alta intensidad de solicitudes entrantes. Poco o nada de hacer esto: no hay suficiente tiempo, especialistas, o se justifican con la frase típica: "Todo funciona rápidamente con nosotros en la producción, entonces, ¿por qué verificar otra cosa?" En tales casos, puede llegar un momento en que una producción que funcione bien caiga repentinamente debido al flujo creciente de visitantes, por ejemplo, bajo el efecto Habrae. Entonces queda claro que hacer investigación sobre productividad es realmente necesario.
Esta tarea es desconcertante para muchos porque hay una necesidad, pero no hay una comprensión clara de qué y cómo medir y cómo interpretar el resultado, a veces no hay requisitos no funcionales formados. A continuación, hablaré sobre por dónde comenzar si decides seguir esta ruta, y explicaré qué métricas son importantes en la investigación de desempeño y cómo usarlas.
Poco de teoría
Imagine que tenemos una aplicación esférica en el vacío: recibe solicitudes y les da respuestas. Por simplicidad, puede ser un microservicio con un método que no va a ninguna parte y que no depende de otros componentes o aplicaciones. En este caso, no estamos muy interesados en lo que está escrito, cómo funciona y en qué entorno se inicia.
¿Qué queremos saber sobre el rendimiento en general? Probablemente sea bueno saber el flujo máximo de solicitudes entrantes en el que el servicio es estable, su rendimiento con este flujo y el tiempo que lleva completar una solicitud. Es muy bueno si puede determinar las razones que limitan un mayor crecimiento de la productividad.
Obviamente, debe medir el tiempo de respuesta a la solicitud, respectivamente, por el flujo de solicitudes entrantes o la intensidad, nos referiremos a la cantidad de solicitudes por unidad de tiempo, generalmente por segundo, y el rendimiento, la cantidad de respuestas a esta unidad de tiempo. Los tiempos de respuesta pueden estar dispersos en un amplio rango, por lo que para empezar tiene sentido presentarlos como un promedio por segundo.
Además, pueden surgir problemas en varios niveles: comenzando con el hecho de que el servicio responde con un error (y es bueno si son quinientos, y no "200 OK {" estado ":" error "}", y termina con el hecho de que deja de responder o las respuestas comienzan a perderse a nivel de red. Las solicitudes fallidas deben poder capturarse, y es conveniente presentarlas como un porcentaje del total. El gráfico de rendimiento, tiempo de respuesta y tasa de error versus intensidad es algo así:
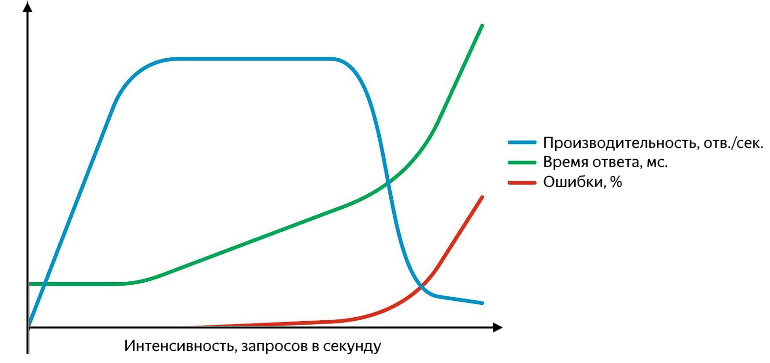
Al aumentar la intensidad de la consulta, el tiempo de respuesta y la tasa de error aumentan
Si bien la productividad crece linealmente con intensidad, el servicio está funcionando bien. Procesa con éxito toda la secuencia de solicitud entrante, el tiempo de respuesta no cambia, no hay errores. Continuando aumentando la intensidad, obtenemos una desaceleración en el crecimiento de la productividad hasta la saturación, en la cual la productividad alcanza su máximo y el tiempo de respuesta comienza a crecer. Un aumento posterior en la intensidad conducirá a una confusión: un aumento significativo en el tiempo de respuesta y una caída en la productividad, comenzará un crecimiento activo de errores. En la etapa de crecimiento y saturación, hay dos puntos importantes: rendimiento normal y máximo.
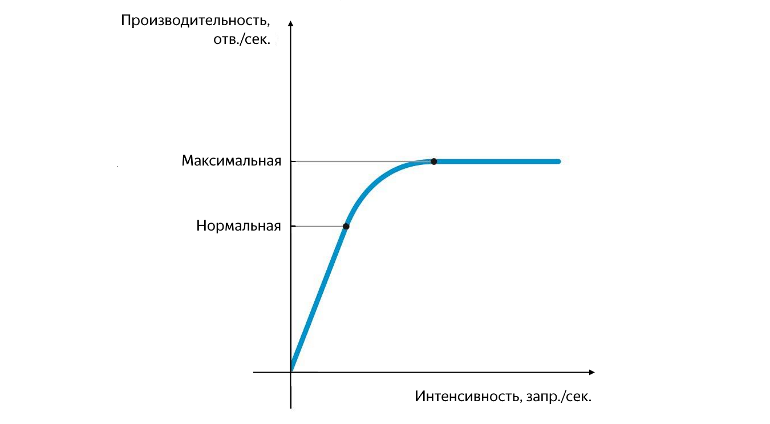
Posición de rendimiento normal y máximo
La productividad normal se logra en el momento en que su tasa de crecimiento comienza a disminuir, y la máxima, en el momento en que su tasa de crecimiento se convierte en cero. Separar el rendimiento entre normal y máximo es muy importante. A una intensidad que corresponde al rendimiento normal, la aplicación debe funcionar de manera estable, y el valor del rendimiento normal caracteriza el umbral después del cual comienza a aparecer el cuello de botella del servicio, lo que tiene un impacto negativo en su funcionamiento. Cuando se alcanza el rendimiento máximo, el cuello de botella comienza a limitar por completo el crecimiento, el servicio es inestable y, como regla, en este momento comienza a aparecer un fondo pequeño pero estable de errores.
El problema puede deberse a varias razones: las colas están bloqueadas, no hay suficientes subprocesos, el grupo se ha agotado, la CPU o la RAM se han utilizado por completo, la velocidad de lectura / escritura insuficiente del disco y similares. Es importante comprender que corregir un cuello de botella provocará que el rendimiento se vea limitado por el siguiente, etc. Es imposible deshacerse por completo de un cuello de botella, solo se puede mover.
Los experimentos
En primer lugar, es necesario determinar la magnitud de la intensidad a la que el servicio alcanza el rendimiento normal y máximo, y el tiempo de respuesta promedio correspondiente. Para hacer esto, en un experimento, es suficiente simplemente aumentar el flujo de solicitudes entrantes. Es más difícil determinar el valor de la intensidad máxima y el tiempo del experimento.
Puede comenzar desde lo que está escrito en los requisitos no funcionales (si corresponde), desde la carga máxima del usuario de la venta, o simplemente tomar valores desde el techo. Si la intensidad de la transmisión entrante no es suficiente, el servicio no tendrá tiempo para alcanzar la saturación y será necesario repetir el experimento. Si la intensidad es demasiado alta, el servicio alcanzará rápidamente la saturación y luego la depuración. En tal caso, es conveniente tener monitoreo para que con un aumento significativo en el número de errores, no pierdas el tiempo en vano y detengas el experimento.
En nuestros experimentos, aumentamos gradualmente la intensidad de 0 a 1000 solicitudes por segundo durante 10 minutos. Esto es suficiente para que el servicio alcance la saturación, y luego, si es necesario, ajustamos el tiempo y la intensidad en el próximo experimento para obtener un resultado más preciso. En los gráficos anteriores, todo fue suave y hermoso, pero en el mundo real puede ser difícil a primera vista determinar el valor del rendimiento normal.
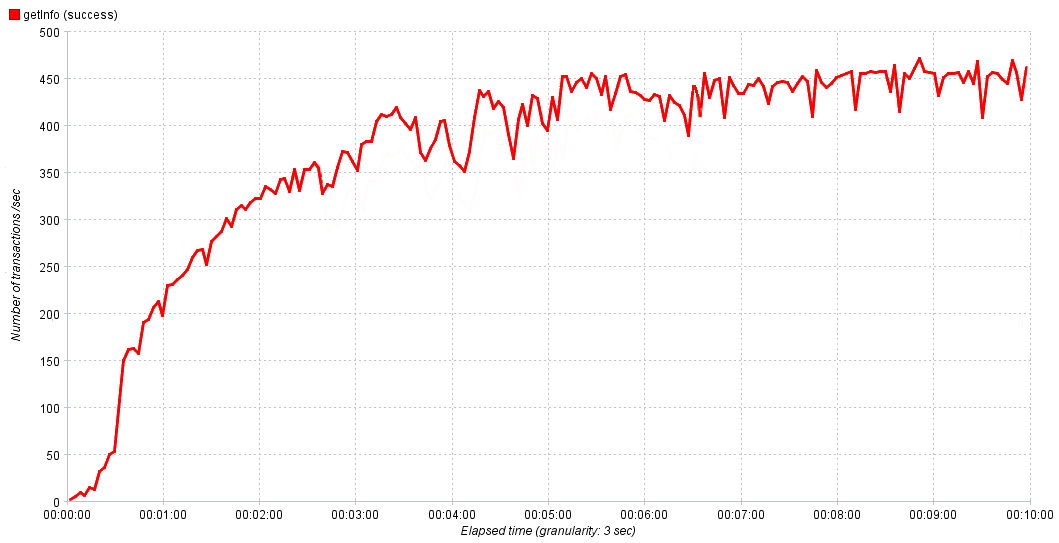
La dependencia real del desempeño del servicio en el tiempo
En este caso, tomamos 80-90% del máximo para un rendimiento normal. Si observamos un crecimiento activo de errores después de alcanzar la saturación, tiene sentido investigarlos, ya que son el resultado de un cuello de botella, estudiarlos ayudará a localizarlo y transmitirlo para su corrección.
Entonces, se obtienen los primeros resultados. Ahora conocemos el rendimiento normal y máximo de la aplicación, así como los tiempos de respuesta correspondientes. ¿Eso es todo? Por supuesto que no! Con un rendimiento normal, el servicio debería funcionar de manera estable, lo que significa que debe verificar su funcionamiento bajo carga normal durante un tiempo. Cual? Puede volver a ver los requisitos no funcionales, preguntar a los analistas o controlar la duración de los períodos de máxima actividad en el producto. En nuestros experimentos, aumentamos linealmente la carga de 0 a normal y nos paramos durante 10-15 minutos. Esto es suficiente si la carga máxima del usuario es significativamente menor de lo normal, pero si son comparables, se debe aumentar el tiempo del experimento.
Para evaluar rápidamente el resultado de un experimento, es conveniente agregar los datos obtenidos en la forma de las siguientes métricas:
- tiempo de respuesta promedio
- mediana
- Percentil 90%
- % de errores
- rendimiento
El tiempo de respuesta promedio es comprensible, pero el promedio es una medida adecuada solo en el caso de una distribución normal de la muestra, ya que es demasiado sensible a los "valores atípicos", valores demasiado grandes o demasiado pequeños que están fuertemente desplazados de la tendencia general. La mediana es la mitad de la muestra completa de tiempos de respuesta, la mitad de los valores son menores, el resto es mayor. ¿Por qué es necesario?
En primer lugar, según su definición, es menos sensible a los valores atípicos, es decir, es una métrica más adecuada y, en segundo lugar, al compararlo con el promedio, se puede evaluar rápidamente las características de distribución de la respuesta. En una situación ideal, son iguales: la distribución de los tiempos de respuesta es normal y el servicio está bien.
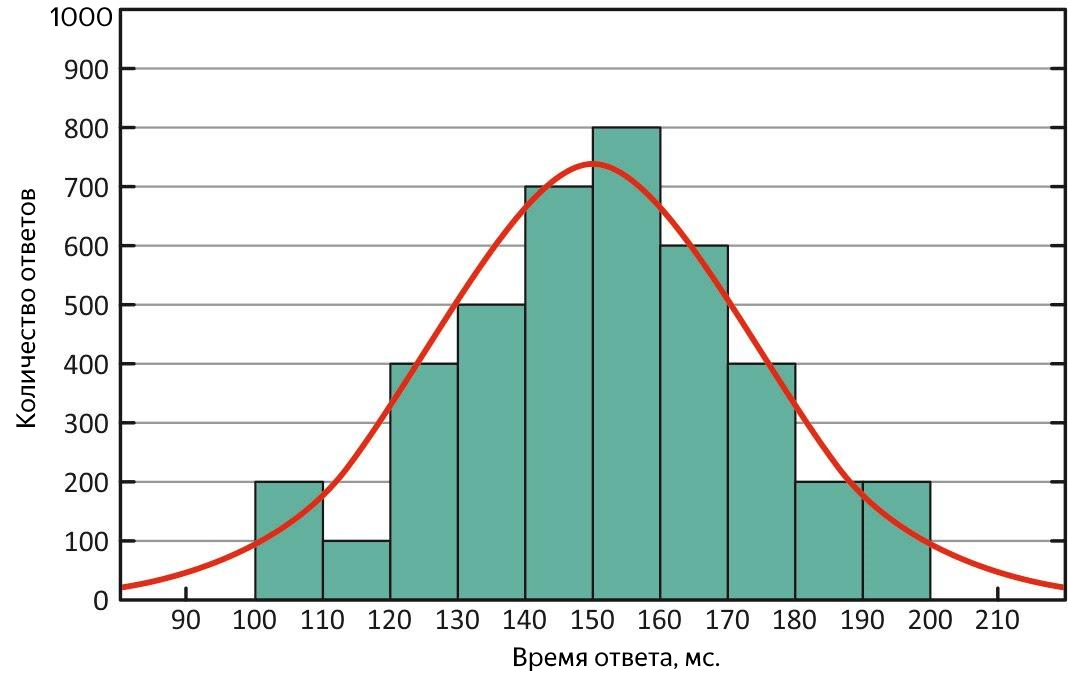
Distribución normal de tiempos de respuesta. Con esta distribución, la media y la mediana son equivalentes.
Si el promedio es muy diferente de la mediana, entonces la distribución es asimétrica y podrían estar presentes "valores atípicos" durante el experimento. Si el promedio es mayor, hubo períodos en los que el servicio respondió muy lentamente, en otras palabras, se desaceleró.
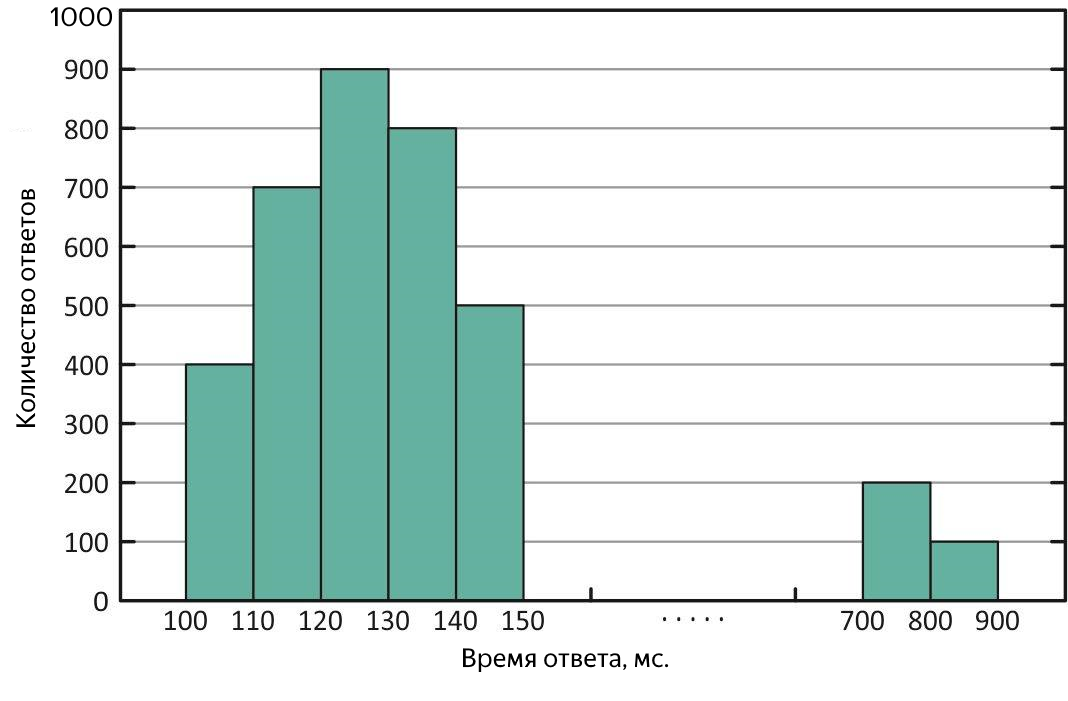
Distribución de tiempos de respuesta con "valores atípicos" de respuestas largas. Con esta distribución, el promedio es mayor que la mediana.
Tales casos requieren un análisis adicional. Para estimar la escala de "emisiones", los cuantiles o percentiles vienen al rescate.
Un cuantil, en el contexto de la muestra obtenida, es el valor del tiempo de respuesta, al que se ajusta la parte correspondiente de todas las solicitudes. Si usa el% de consultas, entonces este es el percentil (por cierto, la mediana es el 50% del percentil). Es conveniente utilizar un percentil del 90% para estimar las emisiones. Por ejemplo, como resultado del experimento, se obtuvo una mediana de 100 ms, y el promedio - 250 ms, ¡supera la mediana en 2,5 veces! Obviamente, esto no es del todo bueno, nos fijamos en un cuantil del 90%, y hay 1000 ms: tanto como el 10% de todas las solicitudes exitosas se completaron durante más de un segundo, un desastre, debe resolverlo. Para buscar consultas largas, puede morder el archivo con los resultados del experimento o inmediatamente en los registros del servicio, pero es aún mejor presentar el tiempo de respuesta promedio en forma de gráfico versus tiempo, inmediatamente mostrará tanto el tiempo como la naturaleza de los "valores atípicos" disponibles.
Resumen
Entonces, realizó con éxito los experimentos y obtuvo los resultados. Si es bueno o malo, depende de los requisitos para el servicio, pero no los números obtenidos son más importantes, sino por qué son estos números y entender qué crecimiento adicional está limitado. Si logra encontrar un cuello de botella, muy bueno, de lo contrario, tarde o temprano la necesidad de productividad puede aumentar, y todavía tiene que buscarlo, por lo que a veces es más fácil evitar la situación.
En esta nota, di un enfoque básico para investigar el desempeño respondiendo preguntas que tenía al principio. No tengas miedo de investigar el rendimiento, ¡es necesario!
PS
Visite nuestra acogedora sala de chat de telegramas donde puede hacer preguntas, ayudar con consejos y simplemente hablar sobre la investigación del rendimiento.