Hola Habr! Me llamo Pavel Lipsky. Soy ingeniero, trabajo para Sberbank-Technology. Mi especialización es probar la tolerancia a fallas y el rendimiento de los servidores de grandes sistemas distribuidos. En pocas palabras, rompo los programas de otras personas. En esta publicación hablaré sobre la inyección de fallas, un método de prueba que le permite encontrar problemas en el sistema creando fallas artificiales. Comenzaré con cómo llegué a este método, luego hablaremos sobre el método en sí y cómo lo usamos.
El artículo tendrá ejemplos de Java. Si no está programando en Java, está bien, solo comprenda el enfoque en sí y los principios básicos. Apache Ignite se usa como la base de datos, pero los mismos enfoques se aplican a cualquier otro DBMS. Todos los ejemplos se pueden descargar desde mi
GitHub .
¿Por qué necesitamos todo esto?
Comenzaré con la historia. En 2005, trabajé para Rambler. En ese momento, el número de usuarios de Rambler estaba creciendo rápidamente, y nuestra arquitectura de dos niveles "servidor - base de datos - servidor - aplicaciones" dejó de funcionar. Pensamos en cómo resolver problemas de rendimiento y llamamos la atención sobre la tecnología memcached.
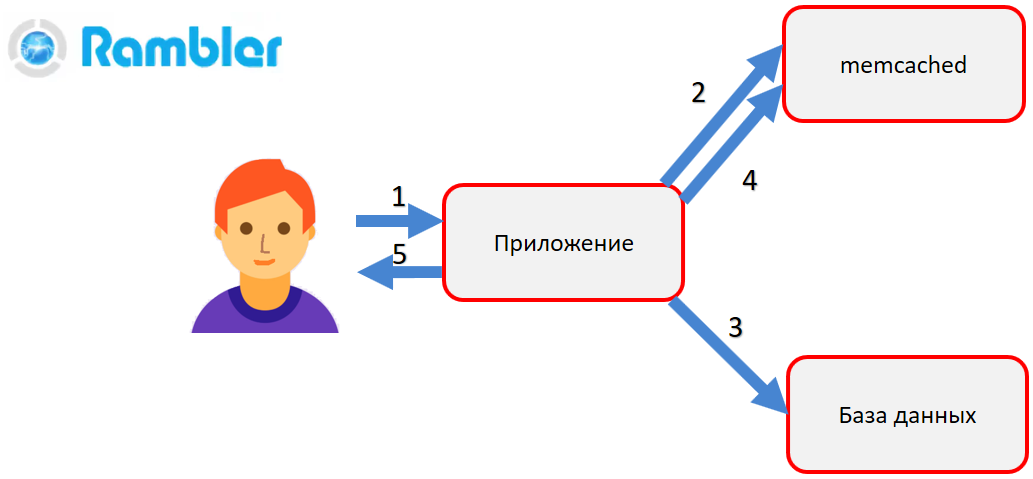
¿Qué es memcached? Memcached: una tabla hash en la memoria de acceso aleatorio con acceso a los objetos almacenados por clave. Por ejemplo, necesita obtener un perfil de usuario. La aplicación accede a memcached (2). Si hay un objeto en él, se devuelve inmediatamente al usuario. Si no hay ningún objeto, se hace una apelación a la base de datos (3), el objeto se forma y se coloca en memcached (4). Luego, en la próxima llamada, ya no necesitamos hacer una llamada costosa de recursos a la base de datos, obtendremos un objeto listo de RAM, memcached.
Debido a memcached, descargamos notablemente la base de datos y nuestras aplicaciones comenzaron a funcionar mucho más rápido. Pero, resultó que era demasiado temprano para alegrarse. Junto con una mayor productividad, tenemos nuevos desafíos.
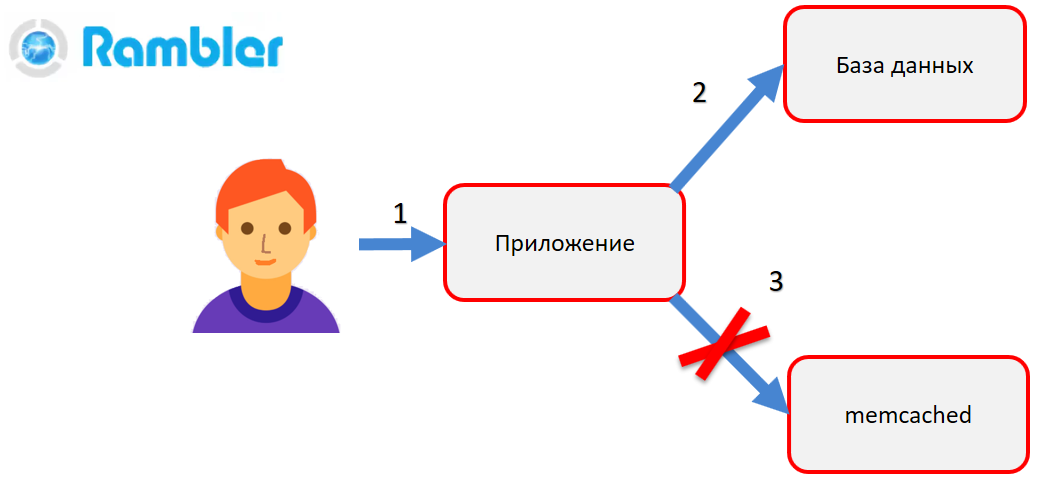
Cuando necesita cambiar los datos, la aplicación primero realiza una corrección en la base de datos (2), crea un nuevo objeto y luego intenta colocarlo en memcached (3). Es decir, el viejo objeto debe ser reemplazado por uno nuevo. Imagine que en este momento sucede algo terrible: la conexión entre la aplicación y memcached se rompe, el servidor memcached o incluso la aplicación en sí se bloquea. Entonces, la aplicación no pudo actualizar los datos en memcached. Como resultado, el usuario irá a la página del sitio (por ejemplo, su perfil), verá los datos antiguos y no entenderá por qué sucedió esto.
¿Podría detectarse este error durante las pruebas funcionales o las pruebas de rendimiento? Creo que, muy probablemente, no lo encontraríamos. Para buscar tales errores hay un tipo especial de prueba: inyección de fallas.
Por lo general, durante la prueba de inyección de fallas, hay errores que popularmente se llaman
flotantes . Aparecen bajo carga, cuando más de un usuario está trabajando en el sistema, cuando ocurren situaciones anormales: mal funcionamiento del equipo, corte de electricidad, mal funcionamiento de la red, etc.
Nuevo sistema informático de Sberbank
Hace unos años, Sberbank comenzó a construir un nuevo sistema de TI. Por qué Aquí están las estadísticas del sitio web del Banco Central:
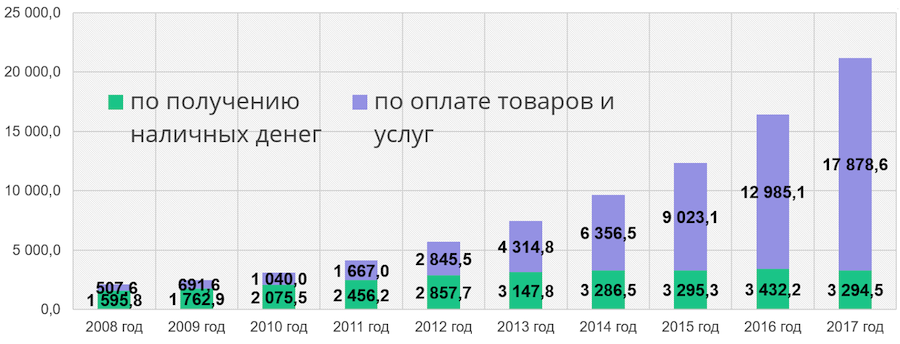
La parte verde de la columna es el número de retiros de efectivo en cajeros automáticos, la parte azul es el número de operaciones para pagar bienes y servicios. Vemos que el número de transacciones sin efectivo está creciendo de año en año. En unos pocos años, tendremos que ser capaces de manejar la creciente carga de trabajo y continuar ofreciendo a nuestros clientes nuevos servicios. Esta es una de las razones para crear un nuevo sistema de TI de Sberbank. Además, nos gustaría reducir nuestra dependencia de las tecnologías occidentales y los mainframes caros, que cuestan millones de dólares, y cambiar a tecnologías de código abierto y servidores de gama baja.
Inicialmente, sentamos las bases de la tecnología Apache Ignite en el corazón de la nueva arquitectura Sberbank. Más precisamente, usamos el complemento de pago Gridgain. La tecnología tiene una funcionalidad bastante rica: combina las propiedades de una base de datos relacional (hay soporte para consultas SQL), NoSQL, procesamiento distribuido y almacenamiento de datos en RAM. Además, cuando reinicia, los datos que estaban en la RAM no se perderán en ninguna parte. A partir de la versión 2.1, Apache Ignite ha distribuido Apache Ignite Persistent Data Store con soporte de SQL.
Enumeraré algunas características de esta tecnología:
- Almacenamiento y procesamiento de datos en RAM
- Almacenamiento en disco
- Soporte SQL
- Ejecución distribuida de tareas
- Escala horizontal
La tecnología es relativamente nueva, por lo que requiere atención especial.
El nuevo sistema de TI de Sberbank consiste físicamente en muchos servidores relativamente pequeños ensamblados en un solo clúster en la nube. Todos los nodos son idénticos en estructura, de igual a igual, realizan la función de almacenar y procesar datos.
Dentro del grupo se divide en las llamadas células. Una celda es de 8 nodos. Cada centro de datos tiene 4 nodos.
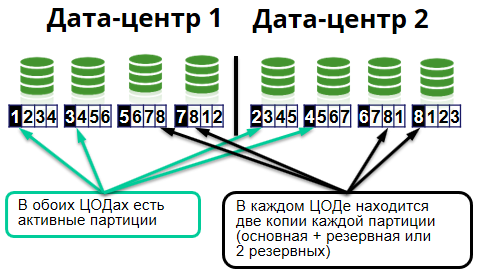
Como utilizamos Apache Ignite, la cuadrícula de datos en memoria, entonces, en consecuencia, todo esto se almacena en cachés distribuidos por el servidor. Además, los cachés, a su vez, se dividen en piezas idénticas: particiones. En los servidores, se representan como archivos. Las particiones del mismo caché se pueden almacenar en diferentes servidores. Para cada partición en el clúster, hay nodos primarios y nodos de respaldo.
Los nodos principales almacenan las particiones principales y procesan las solicitudes para ellas, replican los datos en los nodos de respaldo (nodo de respaldo), donde se almacenan las particiones de respaldo.
Al diseñar la nueva arquitectura de Sberbank, llegamos a la conclusión de que los componentes del sistema pueden fallar. Supongamos que si tiene un clúster de 1000 servidores de gama baja de hierro, de vez en cuando experimentará fallas de hardware. Las tiras de RAM, las tarjetas de red y los discos duros, etc. fallarán. Consideraremos que este comportamiento es un comportamiento del sistema completamente normal. Tales situaciones deben manejarse correctamente y nuestros clientes no deben notarlas.
Pero no es suficiente diseñar la resistencia del sistema a fallas; es imperativo probar los sistemas durante estas fallas. Como dice Caitie McCaffrey de Microsoft Research, una conocida investigadora de sistemas distribuidos: "Nunca sabrá cómo se comporta el sistema durante una falla de contingencia hasta que reproduzca la falla".
Actualizaciones perdidas
Tomemos un ejemplo simple, una aplicación bancaria que simula transferencias de dinero. La aplicación constará de dos partes: el servidor Apache Ignite y el cliente Apache Ignite. El lado del servidor es un almacén de datos.
La aplicación cliente se conecta al servidor Apache Ignite. Crea un caché donde la clave es la ID de la cuenta y el valor es el objeto de la cuenta. En total, diez de estos objetos se almacenarán en la memoria caché. En este caso, inicialmente pondremos $ 100 en cada cuenta (para que haya algo que transferir). En consecuencia, el saldo total en todas las cuentas será igual a $ 1,000.
CacheConfiguration<Integer, Account> cfg = new CacheConfiguration<>(CACHE_NAME); cfg.setAtomicityMode(CacheAtomicityMode.ATOMIC); try (IgniteCache<Integer, Account> cache = ignite.getOrCreateCache(cfg)) { for (int i = 1; i <= ENTRIES_COUNT; i++) cache.put(i, new Account(i, 100)); System.out.println("Accounts before transfers"); printAccounts(cache); printTotalBalance(cache); for (int i = 1; i <= 100; i++) { int pairOfAccounts[] = getPairOfRandomAccounts(); transferMoney(cache, pairOfAccounts[0], pairOfAccounts[1]); } } ... private static void transferMoney(IgniteCache<Integer, Account> cache, int fromAccountId, int toAccountId) { Account fromAccount = cache.get(fromAccountId); Account toAccount = cache.get(toAccountId); int amount = getRandomAmount(fromAccount.balance); if (amount < 1) { return; } fromAccount.withdraw(amount); toAccount.deposit(amount); cache.put(fromAccountId, fromAccount); cache.put(toAccountId, toAccount); }
Luego hacemos 100 transferencias de dinero al azar entre estas 10 cuentas. Por ejemplo, $ 50 se transfieren de la cuenta A a otra cuenta B. Esquemáticamente, este proceso se puede representar de la siguiente manera:

El sistema está cerrado, las transferencias se realizan solo internamente, es decir el saldo total debe permanecer igual a $ 1000.
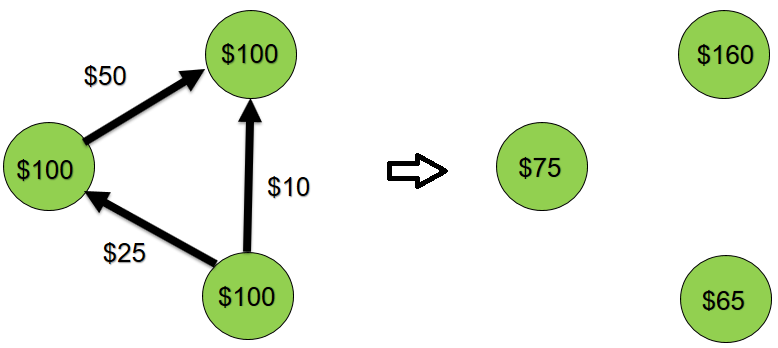
Inicia la aplicación.
Obtuvimos el valor esperado del saldo total: $ 1000. Ahora, vamos a complicar un poco nuestra aplicación, hagámosla multitarea. En realidad, varias aplicaciones cliente pueden funcionar simultáneamente con la misma cuenta. Ejecute dos tareas que simultáneamente harán transferencias de dinero entre diez cuentas.
CacheConfiguration<Integer, Account> cfg = new CacheConfiguration<>(CACHE_NAME); cfg.setAtomicityMode(CacheAtomicityMode.ATOMIC); cfg.setCacheMode(CacheMode.PARTITIONED); cfg.setIndexedTypes(Integer.class, Account.class); try (IgniteCache<Integer, Account> cache = ignite.getOrCreateCache(cfg)) {
El saldo total es de $ 1296. Los clientes se alegran, el banco sufre pérdidas. ¿Por qué sucedió esto?

Aquí vemos cómo dos tareas cambian simultáneamente el estado de la cuenta A. Pero la segunda tarea logra registrar sus cambios antes que la primera. Luego, la primera tarea registra sus cambios, y todos los cambios realizados por la segunda tarea desaparecen inmediatamente. Esta anomalía se llama el problema de las actualizaciones perdidas.
Para que la aplicación funcione como debería, nuestra base de datos debe admitir transacciones ACID y nuestro código debe tener esto en cuenta.
Echemos un vistazo a las propiedades ACID de nuestra aplicación para comprender por qué esto es tan importante.

- A - Atomicidad, atomicidad. O todos los cambios propuestos se realizarán en la base de datos o no se hará nada. Es decir, si tuvimos una falla entre los pasos 3 y 6, los cambios no deberían estar en la base de datos
- C - Consistencia, Integridad. Una vez completada la transacción, la base de datos debe permanecer en un estado coherente. En nuestro ejemplo, esto significa que la suma de A y B siempre debe ser la misma, el saldo total es de $ 1000.
- I - Aislamiento, aislamiento. Las transacciones no deberían afectarse entre sí. Si una transacción realiza una transferencia y la otra recibe el valor de la cuenta A y B después del paso 3 y hasta el paso 6, cree que el sistema tiene menos dinero del necesario. Aquí hay matices en los que me centraré más adelante.
- D - Durabilidad Una vez que la transacción ha realizado cambios en la base de datos, estos cambios no deben perderse como resultado de fallas.
Entonces, en el método transferMoney, haremos una transferencia de dinero dentro de la transacción.
private void transferMoney(int fromAccountId, int toAccountId) { try (Transaction tx = ignite.transactions().txStart()) { Account fromAccount = cache.get(fromAccountId); Account toAccount = cache.get(toAccountId); int amount = getRandomAmount(fromAccount.balance); if (amount < 1) { return; } int fromAccountBalanceBeforeTransfer = fromAccount.balance; int toAccountBalanceBeforeTransfer = toAccount.balance; fromAccount.withdraw(amount); toAccount.deposit(amount); cache.put(fromAccountId, fromAccount); cache.put(toAccountId, toAccount); tx.commit(); } catch (Exception e){ e.printStackTrace(); } }
Inicia la aplicación.
Hm. Las transacciones no ayudaron. ¡El saldo total es de $ 6951! ¿Cuál es el problema con el comportamiento de esta aplicación?
Primero, eligieron el tipo de caché ATOMIC, es decir sin soporte de transacciones ACID:
CacheConfiguration<Integer, Account> cfg = new CacheConfiguration<>(CACHE_NAME); cfg.setAtomicityMode(CacheAtomicityMode.TOMIC);
En segundo lugar, el método txStart tiene dos parámetros importantes del tipo de enumeración que sería bueno especificar: el método de bloqueo (modo de concurrencia en Apache Ignite) y el nivel de aislamiento. Dependiendo de los valores de estos parámetros, una transacción puede leer y escribir datos de diferentes maneras. En Apache Ignite, estos parámetros se establecen de la siguiente manera:
try (Transaction tx = ignite.transactions().txStart( , )) { Account fromAccount = cache.get(fromAccountId); Account toAccount = cache.get(toAccountId); ... tx.commit(); }
Puede usar PESSIMISTIC (bloqueo pesimista) u OPTIMISTIC (bloqueo optimista) como el valor del parámetro LOCK METHOD. Difieren en el instante del bloqueo. Cuando se utiliza PESSIMISTIC, el bloqueo se impone en la primera lectura / escritura y se mantiene hasta que se confirma la transacción. Por ejemplo, cuando una transacción con un bloqueo pesimista realiza una transferencia de la cuenta A a la cuenta B, otras transacciones no podrán leer ni escribir los valores de estas cuentas hasta que se confirme la transacción que realiza la transferencia. Está claro que si otras transacciones desean acceder a las cuentas A y B, se ven obligadas a esperar a que se complete la transacción, lo que tiene un impacto negativo en el rendimiento general de la aplicación. El bloqueo optimista no restringe el acceso a los datos para otras transacciones, sin embargo, durante la fase de preparación de la transacción para la confirmación (fase de preparación, Apache Ignite usa el protocolo 2PC), se realizará una verificación: ¿cambiaron los datos con otras transacciones? Y si se produjeron cambios, la transacción se cancelará. En términos de rendimiento, OPTIMISTIC se ejecutará más rápido, pero es más adecuado para aplicaciones donde no hay competencia con los datos.
El parámetro NIVEL DE AISLAMIENTO determina el grado de aislamiento de las transacciones entre sí. El estándar SQL ANSI / ISO define 4 tipos de aislamiento, y para cada nivel de aislamiento, el mismo escenario de transacción puede conducir a resultados diferentes.
- READ_UNCOMMITED es el nivel de aislamiento más bajo. Las transacciones pueden ver datos no comprometidos "sucios".
- READ_COMMITTED: cuando una transacción ve dentro de sí solo datos confidenciales
- REPEATABLE_READ: significa que si se realiza una lectura dentro de la transacción, esta lectura debe ser repetible.
- SERIALIZABLE: este nivel supone el grado máximo de aislamiento de la transacción, como si no hubiera otros usuarios en el sistema. El resultado de las transacciones paralelas será como si se ejecutaran en orden (en orden). Pero junto con un alto grado de aislamiento, obtenemos una reducción en el rendimiento. Por lo tanto, debe abordar cuidadosamente la elección de este nivel de aislamiento.
Para muchos DBMS modernos (Microsoft SQL Server, PostgreSQL y Oracle), el nivel de aislamiento predeterminado es READ_COMMITTED. Para nuestro ejemplo, esto sería fatal, ya que no nos protegerá de las actualizaciones perdidas. El resultado será el mismo que si no hubiéramos utilizado transacciones en absoluto.

De la
documentación de la transacción Apache Ignite , es adecuado para nosotros usar una combinación del método de bloqueo y el nivel de aislamiento:
- PESSIMISTIC REPEATABLE_READ : el bloqueo se impone en la primera lectura o escritura de datos y se mantiene hasta que se completa.
- PESSIMISTIC SERIALIZABLE : funciona de forma similar a PESSIMISTIC REPEATABLE_READ
- SERIALIZABLE OPTIMISTA : se recuerda la versión de los datos obtenidos después de la primera lectura, y si esta versión es diferente durante la fase de preparación para la confirmación (los datos fueron modificados por otra transacción), la transacción se cancelará. Probemos esta opción.
private void transferMoney(int fromAccountId, int toAccountId) { try (Transaction tx = ignite.transactions().txStart(OPTIMISTIC, SERIALIZABLE)) { Account fromAccount = cache.get(fromAccountId); Account toAccount = cache.get(toAccountId); int amount = getRandomAmount(fromAccount.balance); if (amount < 1) { return; } int fromAccountBalanceBeforeTransfer = fromAccount.balance; int toAccountBalanceBeforeTransfer = toAccount.balance; fromAccount.withdraw(amount); toAccount.deposit(amount); cache.put(fromAccountId, fromAccount); cache.put(toAccountId, toAccount); tx.commit(); } catch (Exception e){ e.printStackTrace(); } }
Hurra, recibió $ 1,000, como se esperaba. En el tercer intento.
Prueba bajo carga
Ahora haremos que nuestra prueba sea más realista, probaremos bajo carga. Y agregue un nodo de servidor adicional. Existen muchas herramientas para realizar pruebas de estrés, en Sberbank utilizamos el Centro de rendimiento de HP. Esta es una herramienta bastante poderosa, admite más de 50 protocolos, está diseñada para equipos grandes y cuesta mucho dinero. Escribí mi ejemplo en JMeter: es gratis y resuelve nuestro problema al 100%. No me gustaría volver a escribir el código en Java, por lo que utilizaré el muestreador JSR223.
Crearemos un archivo JAR a partir de las clases de nuestra aplicación y lo cargaremos en el plan de prueba. Para crear y llenar el caché, ejecute la clase CreateCache. Después de inicializar el caché, puede ejecutar el script JMeter.
Todo está bien, tengo $ 1,000.
Apagado de emergencia del nodo del clúster
Ahora seremos más destructivos: durante la operación del clúster, bloquearemos uno de los dos nodos del servidor. A través de la utilidad Visor, que se incluye con el paquete Gridgain, podemos monitorear el clúster Apache Ignite y hacer diferentes muestras de datos. En la pestaña SQL Viewer, ejecute una consulta SQL para obtener el saldo general de todas las cuentas.
Que es 553 dolares. Los clientes están aterrorizados, el banco sufre pérdidas de reputación. ¿Qué hemos hecho mal esta vez?
Resulta que hay tipos de caché en Apache Ignite:
- particionado: una o varias copias de seguridad se almacenan dentro del clúster
- cachés replicados: todas las particiones (todas las partes del caché) se almacenan en un servidor. Tales cachés son adecuados principalmente para libros de referencia, algo que rara vez cambia y que a menudo se lee.
- local: todo en un nodo

A menudo cambiaremos nuestros datos, por lo que seleccionaremos un caché particionado y le agregaremos una copia de seguridad adicional. Es decir, tendremos dos copias de los datos: la principal y la de respaldo.
CacheConfiguration<Integer, Account> cfg = new CacheConfiguration<>(CACHE_NAME); cfg.setAtomicityMode(CacheAtomicityMode.TRANSACTIONAL); cfg.setCacheMode(CacheMode.PARTITIONED); cfg.setBackups(1);
Lanzamos la aplicación. Les recuerdo que antes de las transferencias tenemos $ 1000. Comenzamos y durante la operación "extinguimos" uno de los nodos
En la utilidad Visor, realizamos una consulta SQL para obtener un saldo total de $ 1000. ¡Todo salió genial!
Casos de confiabilidad
Hace dos años, estábamos comenzando a probar el nuevo sistema de TI de Sberbank. De alguna manera fuimos a nuestros ingenieros de escolta y les preguntamos: ¿qué podría romperse en absoluto? Nos respondieron: ¡todo puede romperse, probar todo! Por supuesto, esta respuesta no nos vino bien. Nos sentamos juntos, analizamos las estadísticas de fallas y nos dimos cuenta de que el caso más probable que podemos encontrar es una falla de nodo.
Además, esto puede suceder por razones completamente diferentes. Por ejemplo, una aplicación puede bloquearse, un bloqueo de JVM, un bloqueo del sistema operativo o una falla de hardware.
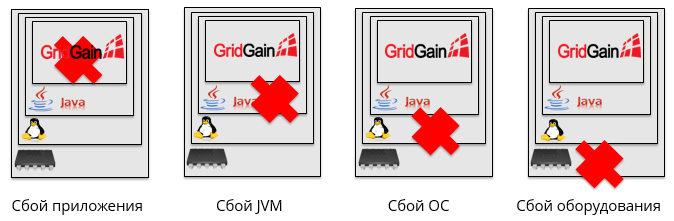
Dividimos todos los posibles casos de fallas en 4 grupos:
- Equipo
- Red
- Software
- Otros
Se les ocurrieron pruebas para ellos y los llamaron casos de fiabilidad. Un caso típico de confiabilidad consiste en una descripción del estado del sistema antes de las pruebas, los pasos para reproducir la falla y una descripción del comportamiento esperado durante la falla.
Casos de fiabilidad: equipamiento
Este grupo incluye casos como:
- Falla de energía
- Pérdida completa de acceso al disco duro.
- Fallo de una ruta de acceso al disco duro
- CPU, RAM, disco, carga de red
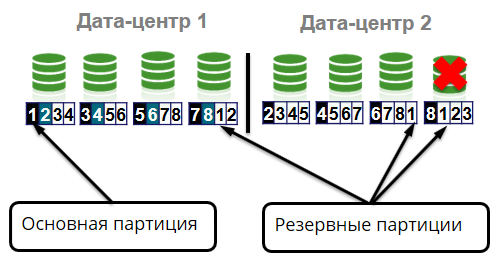
El clúster almacena 4 copias idénticas de cada partición: una partición primaria y tres particiones de respaldo. Supongamos que un nodo abandona un clúster debido a una falla del equipo. En este caso, las particiones principales deberían moverse a otros nodos supervivientes.
¿Qué más podría pasar? Pérdida de estante en la celda.
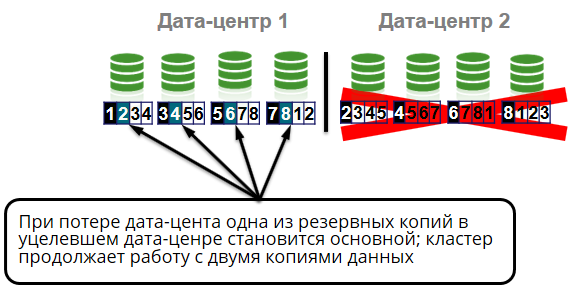
Todos los nodos de la celda están en diferentes bastidores. Es decir la salida del bastidor no provocará fallas del clúster o pérdida de datos. Tendremos tres copias de cuatro. Pero incluso si perdemos todo el centro de datos, tampoco será un gran problema para nosotros, porque Todavía tenemos dos copias más de los datos de cuatro.
Algunos casos se llevan a cabo directamente en el centro de datos con la asistencia de ingenieros de soporte. Por ejemplo, apagar el disco duro, apagar el servidor o el rack.
Casos de fiabilidad: red
Para probar casos relacionados con la fragmentación de la red, utilizamos iptables. Y usando la utilidad NetEm emulamos:
- retrasos en la red con diferentes funciones de distribución
- pérdida de paquetes
- reintento de paquetes
- reordenando paquetes
- distorsión de paquete
Otro caso de red interesante que estamos probando es el cerebro dividido. Esto es cuando todos los nodos del clúster están vivos, pero debido a la segmentación de la red no pueden comunicarse entre sí. El término proviene de la medicina y significa que el cerebro está dividido en dos hemisferios, cada uno de los cuales se considera único. Lo mismo puede suceder con un clúster.
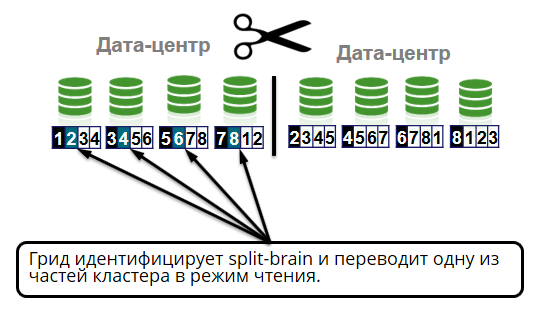
Sucede que entre los centros de datos la conexión desaparece. Por ejemplo, el año pasado, debido a daños en el cable de fibra óptica por una excavadora, un cliente de los bancos de los bancos Tochka, Otkrytie y Rocketbank no realizó transacciones por Internet durante varias horas, los terminales no aceptaron tarjetas y los cajeros automáticos no funcionaron. Mucho se ha escrito sobre este accidente en Twitter.
En nuestro caso, la situación del cerebro dividido debe manejarse correctamente. Una cuadrícula identifica un cerebro dividido, que divide un grupo en dos partes. La mitad entra en modo de lectura. Esta es la mitad donde hay más nodos vivos o el coordinador está ubicado (el nodo más antiguo en el clúster).
Casos de fiabilidad: software
Estos son casos relacionados con la falla de varios subsistemas:
- DPL ORM: módulo de acceso a datos, como Hibernate ORM
- Transporte intermodular: mensajería entre módulos (microservicios)
- Sistema de registro
- Sistema de acceso
- Apache Ignite Cluster
- ...
Dado que la mayoría del software está escrito en Java, somos propensos a todos los problemas inherentes a las aplicaciones Java. Prueba varias configuraciones del recolector de basura. Ejecución de pruebas con un bloqueo de máquina virtual java.
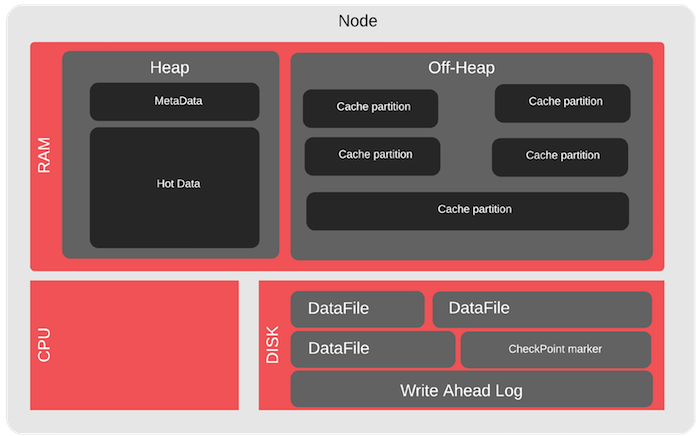
Para el clúster Apache Ignite, hay casos especiales para fuera del montón: esta es el área de memoria que controla Apache Ignite. Es mucho más grande que el montón de Java y está diseñado para almacenar datos e índices. Aquí puede, por ejemplo, probar el desbordamiento. Nos desbordamos del montón y vemos cómo funciona el clúster cuando algunos de los datos no caben en la RAM, es decir Leer desde el disco.
Otros casos
Estos son casos que no están incluidos en los primeros tres grupos. Estos incluyen utilidades que permiten la recuperación de datos en caso de un accidente grave o cuando los datos se migran a otro clúster.
- La utilidad para crear instantáneas (copia de seguridad) de datos: prueba de instantáneas completas e incrementales.
- Recuperación a un punto específico en el tiempo: mecanismo PITR (punto de recuperación en el tiempo).
Utilidades para inyección de fallas
Recuerdo el
enlace a ejemplos de mi informe. Puede descargar la distribución de Apache Ignite desde el sitio oficial:
Descargas de Apache Ignite . Y ahora compartiré las utilidades que utilizamos en Sberbank, si de repente te interesa el tema.
Marcos
Gestión de configuración:
Utilidades de Linux:
Herramientas de prueba de carga:
Tanto en el mundo moderno como en Sberbank, todos los cambios son dinámicos y es difícil predecir qué tecnologías se utilizarán en los próximos años. Pero estoy seguro de que utilizaremos el método de inyección de fallas. El método es universal: es adecuado para probar cualquier tecnología, realmente funciona, ayuda a detectar muchos errores y a mejorar los productos que desarrollamos.