Varios ayudantes en la escritura de código genial simplemente nos rodean, linter, typekchera, utilidad para encontrar vulnerabilidades, todo con nosotros. Estamos acostumbrados y lo usamos sin entrar en detalles como una "caja negra". Por ejemplo, pocas personas entienden los principios de Pylint, una de esas herramientas indispensables para optimizar y mejorar el código Python.
Pero
Maxim Mazaev sabe lo importante que es comprender sus herramientas, y nos lo dijo en
Moscow Python Conf ++ . Utilizando ejemplos de la vida real, mostró cómo el conocimiento del dispositivo interno de Pylint y sus complementos ayudó a reducir el tiempo de revisión del código, mejorar la calidad del código y, en general, mejorar la eficiencia del desarrollo. A continuación se muestra una instrucción de descifrado.

¿Por qué necesitamos Pylint?
Si ya lo usa, puede surgir la pregunta: "¿Por qué saber qué hay dentro de Pylint, cómo puede ayudar este conocimiento?"
Por lo general, los desarrolladores escriben código, inician la interfaz, reciben mensajes sobre qué mejorar, cómo hacer que el código sea más hermoso y hacer los cambios propuestos. Ahora el código es más fácil de leer y no se avergüenza de mostrar a sus colegas.
Durante mucho tiempo, trabajaron exactamente de la misma manera con Pylint en el Instituto Cyan, con pequeñas adiciones: cambiaron las configuraciones, eliminaron reglas innecesarias y aumentaron la longitud máxima de la cadena.
Pero en algún momento se encontraron con un problema, por lo que tuve que profundizar en Pylint y descubrir cómo funciona. ¿Cuál es este problema y cómo resolverlo? Siga leyendo.
Sobre el orador: Maxim Mazaev (
barra invertida ), 5 años en desarrollo, trabaja en CIAN. Aprende profundamente Python, asincronía y programación funcional.
Acerca de cian
La mayoría cree que CIAN es una agencia de bienes raíces con agentes inmobiliarios y se sorprenden mucho cuando descubren que en lugar de agentes inmobiliarios tenemos programadores.
Somos una empresa técnica en la que no hay agentes inmobiliarios, pero hay muchos programadores.
- 1 millón de usuarios únicos por día.
- El mayor tablón de anuncios para la venta y alquiler de bienes inmuebles en Moscú y San Petersburgo. En 2018, ingresaron al nivel federal y trabajaron en toda Rusia.
- Casi 100 personas en el equipo de desarrollo, de las cuales 30 escriben código Python diariamente.
Todos los días, cientos y miles de líneas de código nuevo entran en producción. Los requisitos para el código son bastante simples:
- Código de calidad decente.
- Homogeneidad estilística. Todos los desarrolladores deben escribir un código similar, sin "vinagreta" en los repositorios.
Para lograr esto, por supuesto, necesita una revisión de código.
Revisión de código
La revisión del código en CIAN se lleva a cabo en dos etapas:
- La primera etapa es automatizada . El robot Jenkins ejecuta las pruebas, ejecuta Pylint y verifica la consistencia de la API entre microservicios, ya que usamos microservicios. Si en esta etapa las pruebas fallan o el linter muestra algo extraño, entonces esta es una ocasión para rechazar la solicitud de extracción y enviar el código para su revisión.
- Si la primera etapa fue exitosa, entonces viene la segunda: aprobación de dos desarrolladores . Pueden evaluar qué tan bueno es el código en términos de lógica empresarial, aprobar una solicitud de extracción o devolver el código para su revisión.
Problemas de revisión de código
La solicitud de extracción no puede pasar la revisión del código debido a:
- errores en la lógica empresarial cuando un desarrollador ha resuelto un problema de manera ineficaz o incorrecta;
- problemas de estilo de código.
¿Cuáles podrían ser los problemas de estilo si la interfaz comprueba el código?
Todos los que escriben en Python saben que hay una guía para escribir código
PEP-8 . Como cualquier estándar, PEP-8 es bastante general y para nosotros, como desarrolladores, esto no es suficiente. Quiero especificar el estándar en algunos lugares y expandirlo en otros.
Por lo tanto, se nos ocurrieron nuestros arreglos internos sobre cómo debería verse y funcionar el código, y los llamamos
"Rechazar propuestas cian" .
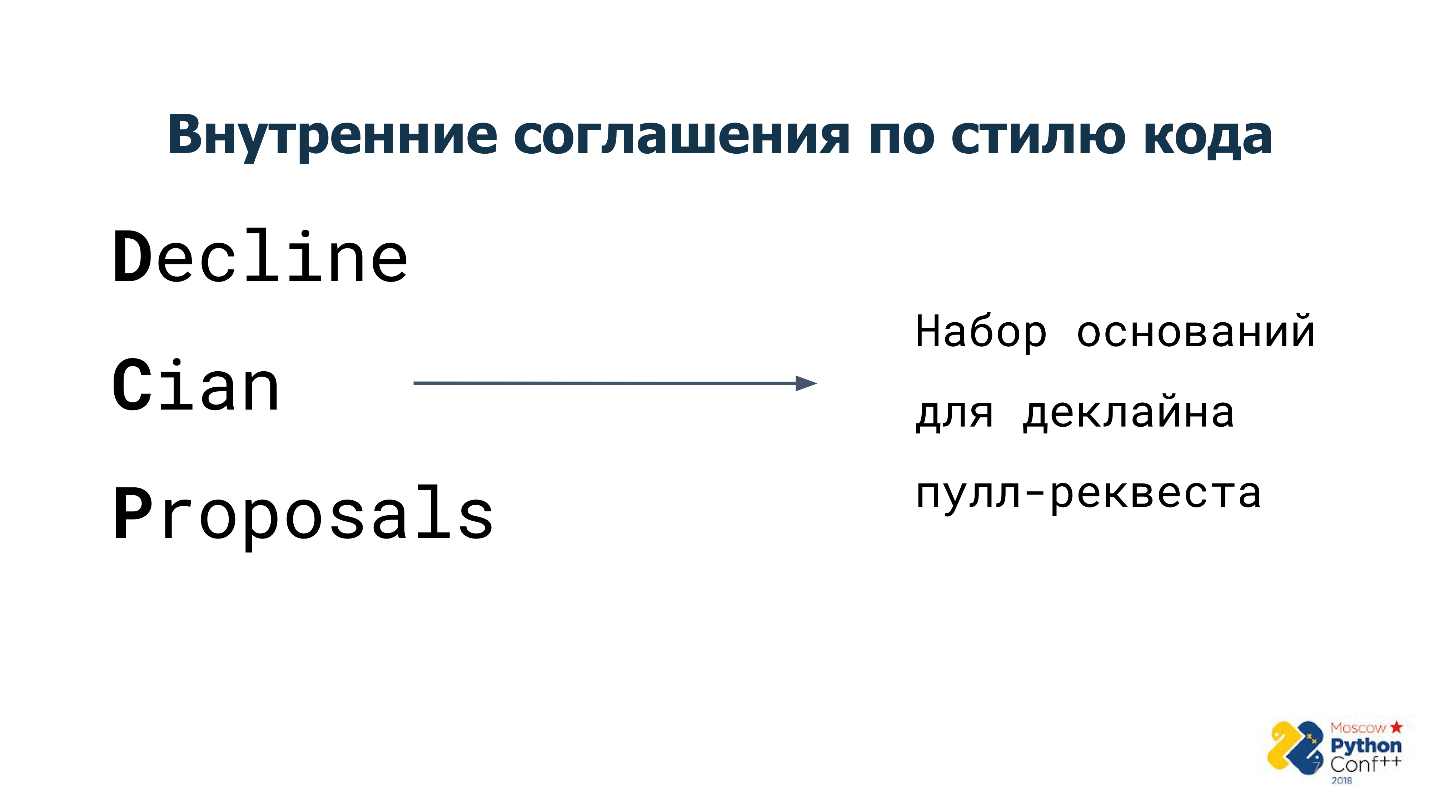
“Rechazar propuestas de Cian”: un conjunto de reglas, ahora hay alrededor de 15. Cada una de estas reglas es la base para que la solicitud de extracción sea rechazada y enviada para su revisión.
¿Qué dificulta una revisión productiva del código?
Hay un problema con nuestras reglas internas: el linter no las conoce y sería extraño que lo supiera, son internas.
El desarrollador que realiza la tarea siempre debe recordar y tener en cuenta las reglas. Si olvida una de las reglas, en el proceso de revisión del código, los revisores señalarán el problema, la tarea irá a revisión y el tiempo de liberación de la tarea aumentará. Después del refinamiento y corrección de errores, los evaluadores deben recordar lo que estaba en la tarea, para cambiar el contexto.
Esto crea un problema tanto para el desarrollador como para los revisores. Como resultado, la velocidad de revisión de código se reduce críticamente. En lugar de analizar la lógica del código, los evaluadores comienzan a analizar el estilo visual, es decir, realizan el trabajo de la interfaz: escanean el código línea por línea y buscan inconsistencias en la sangría en el formato de importación.
Nos gustaría deshacernos de este problema.
Pero no nos escribas tu linter?
Parece que el problema se resolverá con una herramienta que conocerá todos los acuerdos internos y podrá verificar el código para su implementación. Entonces, ¿necesitamos nuestro propio linter?
En realidad no La idea es estúpida, porque ya usamos Pylint. Este es un enlace conveniente, que le gusta a los desarrolladores y está integrado en todos los procesos: se ejecuta en Jenkins, genera informes hermosos que están completamente satisfechos y en forma de comentarios llegan a la solicitud de extracción. Todo está bien,
no se necesita un
segundo linter .
Entonces, ¿cómo resolver el problema si no queremos escribir nuestro propio linter?
Escribir un complemento de Pylint
Puede escribir complementos para Pylint, se llaman correctores. Bajo cada regla interna, puede escribir su propio corrector, que lo revisará.
Considere dos ejemplos de tales damas.
Ejemplo no 1
En algún momento, resultó que el código contiene muchos comentarios de la forma "TODO": promete refactorizar, eliminar código innecesario o reescribirlo maravillosamente, pero no ahora, sino más tarde. Hay un problema con tales comentarios: no te obligan a nada.
El problema
El desarrollador escribió una promesa, exhaló y fue con tranquilidad para hacer la siguiente tarea.
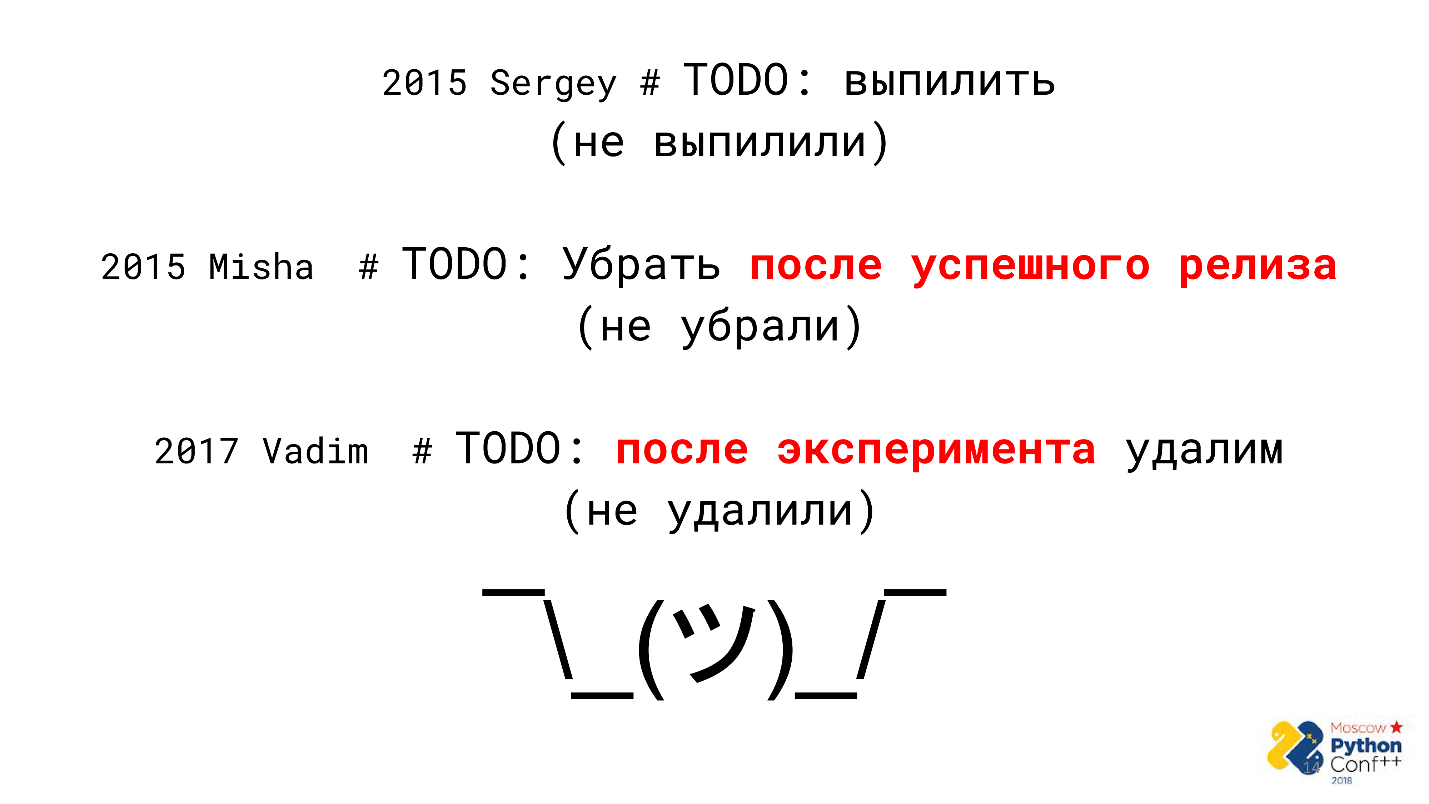
En resumen:
- los comentarios con promesas se ciernen a lo largo de los años y no se siguen;
- el código está lleno de basura;
- La deuda técnica se ha ido acumulando durante años.
Por ejemplo, un desarrollador hace 3 años prometió eliminar algo después de un lanzamiento exitoso, pero ¿ocurrió el lanzamiento en 3 años? Quizás si. ¿Debo eliminar el código en este caso? Esta es una gran pregunta, pero muy probablemente no.
Solución: escriba su corrector para Pylint
No puede prohibir a los desarrolladores que escriban tales comentarios, pero puede hacer que hagan un trabajo adicional: cree una tarea en el rastreador para finalizar la promesa. Entonces definitivamente no nos olvidaremos de ella.
Necesitamos encontrar todos los comentarios del formulario TODO y asegurarnos de que cada uno de ellos tenga un enlace a una tarea en Jira. Vamos a escribir
¿Qué es un corrector en términos de Pylint? Esta es una clase que hereda de la clase base del verificador e implementa una determinada interfaz.
class TodoIssueChecker(BaseChecker): _ _implements_ _ = IRawChecker
En nuestro caso, se trata de
IRawChecker , el llamado verificador "sin procesar".
Un verificador sin procesar itera sobre las líneas de un archivo y puede realizar una determinada acción en una línea. En nuestro caso, en cada línea, el verificador buscará algo similar a un comentario y un enlace a una tarea.
Para el verificador, debe determinar la lista de mensajes que emitirá:
msgs = { '9999': (' TODO ', issue-code-in-todo', ' ')}
El mensaje tiene:
- la descripción es corta y larga;
- código corrector y un nombre mnemotécnico corto que determina qué tipo de mensaje es.
El código del mensaje tiene la forma "C1234", en la cual:
- La primera letra está claramente estandarizada para diferentes tipos de mensajes: [C] invención; [W] arning; [E] yog; [F] atal; [R] efactorización. Gracias a la carta, el informe muestra de inmediato lo que está sucediendo: un recordatorio de los acuerdos o problemas fatales que deben abordarse con urgencia.
- 4 números aleatorios únicos de Pylint.
El código es necesario para deshabilitar la verificación si se vuelve innecesario. Puede escribir Pylint: deshabilitar y un código alfanumérico corto o nombre mnemotécnico:
Los autores de Pylint recomiendan abandonar el código alfanumérico y usar el mnemotécnico, es más visual.
El siguiente paso es definir un método llamado
process_module .

El nombre es muy importante. El método debería llamarse así, porque Pylint lo llamará.
El parámetro del
nodo se pasa al módulo. En este caso, no importa qué sea o de qué tipo sea, solo es importante recordar que el nodo tiene un método de
flujo que devuelve un archivo línea por línea.
Puede revisar el archivo y, para cada línea, verifique si hay comentarios y enlaces a la tarea. Si hay un comentario, pero no hay un enlace, arroje una advertencia del formulario
'issue-code-in-todo' con el código del verificador y el número de línea. El algoritmo es bastante simple.
Registre el corrector para que Pylint lo sepa. Esto se hace mediante la función de
registro :
def register(linter: Pylinter) -> None: linter. register_checker ( TodoIssueChecker(linter) )
- Una instancia de Pylint entra en la función.
- Llama al método register_checker.
- Pasamos el corrector al método.
Un punto importante: el módulo de verificación debe estar en PYTHONPATH para que Pylint pueda importarlo más tarde.
Un verificador registrado es verificado por un archivo de prueba con comentarios sin enlaces a tareas.
$ cat work.
Para la prueba, ejecute Pylint, pase el módulo, use el parámetro
load-plugins para pasar el verificador y, dentro de la interfaz, ejecute dos fases.
Fase 1. Inicialización del complemento
- Todos los módulos con complementos son importados. Pylint tiene inspectores internos y externos. Todos se unen y son importados.
- Nos registramos - module.register (self) . Para cada verificador, se llama a la función de registro, donde se pasa la instancia de Pylint.
- Se realizan verificaciones: por la validez de los parámetros, por la presencia de mensajes, opciones e informes en el formato correcto.
Fase 2. Analiza el grupo de damas
Después de la fase 1, queda una lista completa de diferentes tipos de fichas:
- Corrector AST;
- Corrector sin procesar;
- Comprobador de tokens.

De la lista seleccionamos aquellos que se relacionan con la interfaz del verificador sin procesar: observamos qué verificadores implementan la interfaz IRawChecker y los tomamos para nosotros mismos.
Para cada verificador seleccionado, llame al
método checker.process_module (módulo) y ejecute el cheque.
Resultado
Ejecute el verificador en el archivo de prueba nuevamente:
$ cat work.
Aparecerá un mensaje que indica que hay un comentario con TODO y ningún enlace a la tarea.
El problema está resuelto y ahora, en el proceso de revisión del código, los desarrolladores no necesitan escanear el código con los ojos, buscar comentarios, escribir un recordatorio al autor del código de que hay un acuerdo y es aconsejable dejar un enlace. Todo sucede automáticamente y la revisión de código es un poco más rápida.
Ejemplo No. 2. argumentos de palabras clave
Hay funciones que toman argumentos posicionales. Si hay muchos argumentos, cuando llaman a la función, no está muy claro dónde está el argumento y por qué es necesario.
El problema
Por ejemplo, tenemos una función:
get_offer_by_cian_id( "sale", rue, 859483, )
El código tiene
venta y
True, y no está claro lo que significan. Es mucho más conveniente cuando las funciones en las que hay muchos argumentos se llamarían solo con argumentos con nombre:
get_offer_by_cian_id( deal_type="sale", truncate=True, cian_id=859483, )
Este es un buen código, en el que queda claro de inmediato dónde está el parámetro y no confundiremos su secuencia. Intentemos escribir un corrector que verifique tales casos.
El verificador "en bruto" utilizado en el ejemplo anterior es muy difícil de escribir para tal caso. Puede agregar expresiones regulares súper complejas, pero dicho código es difícil de leer. Es bueno que Pylint permita escribir otro tipo de corrector basado en el árbol de sintaxis abstracta
AST , y lo usaremos.
Letras sobre AST
Un árbol de sintaxis abstracta o AST es una representación en árbol del código, donde el vértice son los operandos y las hojas son operadores.
Por ejemplo, una llamada de función, donde hay un argumento posicional y dos argumentos nombrados, se transforma en un árbol abstracto:

Hay un vértice con tipo
Call y tiene:
- atributos de función llamados func;
- una lista de argumentos posicionales args, donde hay un nodo con tipo Const y un valor de 112;
- lista de argumentos nombrados Palabras clave.
La tarea en este caso:
- Encuentre en el módulo todos los nodos con tipo Call (llamada a función).
- Calcule el número total de argumentos que toma la función.
- Si hay más de 2 argumentos, asegúrese de que no haya argumentos posicionales en el nodo.
- Si hay argumentos posicionales, muestre una advertencia.
ll( func=Name(name='get_offer'), args=[Const(value=1298880)], keywords=[ … ]))]
Desde el punto de vista de Pylint, un corrector basado en AST es una clase que hereda de la clase de corrector base e implementa la interfaz
IAstroidChecker :
class NonKeywordArgsChecker(BaseChecker): -_ _implements_ _ = IAstroidChecker
Como en el primer ejemplo, la descripción del verificador, el código del mensaje, el nombre mnemotécnico corto se indican en la lista de mensajes:
msgs = { '9191': (' ', keyword-only-args', ' ')}
El siguiente paso es definir el método
visit_call :
def visit_call(self, node: Call) …
El método no tiene que llamarse así. Lo más importante es el prefijo visit_, y luego viene el nombre del vértice que nos interesa, con una letra minúscula.
- El analizador AST recorre el árbol y, para cada vértice, busca si el verificador tiene definida la interfaz visit_ <Nombre>.
- Si es así, entonces llámalo.
- Recursivamente pasa por todos sus hijos.
- Al salir de un nodo, llama al método leave_ <Nombre>.
En este ejemplo, el método visit_call recibirá un nodo de tipo Llamada como entrada y verá si tiene más de dos argumentos y si existen argumentos posicionales para lanzar una advertencia y pasar el código al propio nodo.
def visit_call(self, n): if node.args and len(node.args + node.keywords) > 2: self.add_message( 'keyword-only-args', node=node )
Registramos el verificador, como en el ejemplo anterior: transferimos la instancia de Pylint, llamamos a register_checker, pasamos el verificador y lo iniciamos.
def register(linter: Pylinter) -> None: linter.register_checker( TodoIssueChecker(linter) )
Este es un ejemplo de una llamada de función de prueba donde hay 3 argumentos y solo se nombra uno de ellos:
$ cat work. get_offers(1, True, deal_type="sale") $ Pylint work.py --load-plugins non_kwargs_checker …
Esta es una función que potencialmente se llama incorrectamente desde nuestro punto de vista. Lanzamiento de Pylint.
La fase 1 de inicialización del complemento se repite completamente, como en el ejemplo anterior.
Fase 2. Análisis del módulo en AST
El código se analiza en un árbol AST. El análisis lo realiza
la biblioteca Astroid .
Por qué Astroid, no AST (stdlib)
Astroid no utiliza internamente el módulo AST Python estándar, sino el
analizador AST typed_ast , caracterizado porque es compatible con las
sugerencias de tipo PEP
484. Typed_ast es una rama de AST, una bifurcación que se desarrolla en paralelo. Curiosamente, hay los mismos errores que están en AST y se reparan en paralelo.
from module import Entity def foo(bar):
Anteriormente, Astroid usaba el módulo AST estándar, en el cual uno podía encontrar el problema de usar los taiphints definidos en los comentarios usados en el segundo Python. Si verifica este código a través de Pylint, hasta cierto punto juraría una importación no utilizada, porque la clase de entidad importada solo está presente en el comentario.
En algún momento en GitHub, Guido Van Rossum llegó a Astroid y dijo: “Chicos, tienen a Pylint que jura en tales casos, y tenemos un analizador AST mecanografiado que respalda todo esto. ¡Seamos amigos!
¡El trabajo ha comenzado a hervir! Pasaron 2 años, esta primavera Pylint cambió a un analizador AST mecanografiado y dejó de maldecir por esas cosas. Las importaciones de taiphints ya no se marcan como no utilizadas.
Astroid usa un analizador AST para analizar el código en un árbol, y luego hace algunas cosas interesantes al construirlo. Por ejemplo, si usa
import * , importa todo con un asterisco y lo agrega a los locales para evitar errores con las importaciones no utilizadas.
Los complementos de transformación se usan en casos en los que hay algunos modelos complejos basados en metaclases, cuando todos los atributos se generan dinámicamente. En este caso, Astroid es muy difícil de entender lo que significa. Al verificar, Pylint jurará que los modelos no tienen dicho atributo cuando se accede, y usando los complementos Transformar puede resolver el problema:
- Ayuda a Astroid a modificar el árbol abstracto y comprender la naturaleza dinámica de Python.
- Suplemento AST con información útil.
Un ejemplo típico es
pylint-django . Cuando se trabaja con modelos django complejos, el linter a menudo jura atributos desconocidos. Pylint-django simplemente resuelve este problema.
Fase 3. Analiza el grupo de damas
Regresamos al verificador. Nuevamente tenemos una lista de verificadores, de los cuales encontramos aquellos que implementan la interfaz del verificador AST.
Fase 4. Analizar los verificadores por tipos de nodos
A continuación, encontramos métodos para cada verificador, pueden ser de dos tipos:
- visita_ <Nombre de nodo>
- leev_ <nombre de nodo>.
Sería bueno saber qué nodos necesita llamar para un nodo mientras camina en un árbol. Por lo tanto, entienden el diccionario, donde la clave es el nombre del nodo, el valor es una lista de los verificadores que están interesados en el hecho de acceder a este nodo.
_visit_methods = dict( < > : [checker1, checker2 ... checkerN] )
Lo mismo con los métodos de licencia: una clave en forma de nombre de nodo, una lista de verificadores que están interesados en el hecho de salir de este nodo.
_leave_methods = dict( < >: [checker1, checker2 ... checkerN] )
Lanzamiento de Pylint. Muestra una advertencia de que tenemos una función donde hay más de dos argumentos y hay un argumento posicional en ella:
$ cat work. get_offers(1, True, deal_type="sale") $ Pylint work.py --load-plugins non_kwargs_checker C: 0, 0: c >2 (keyword-only-args)
El problema está resuelto. Ahora, los programadores de revisión de código no necesitan leer los argumentos de la función; el linter lo hará por ellos.
Ahorramos nuestro tiempo , tiempo para la revisión del código y las tareas van más rápido en la producción.
¿Y para escribir pruebas?
Pylint le permite realizar pruebas unitarias de las fichas y es muy simple. Desde el punto de vista del linter, el verificador de prueba parece una clase que hereda del
CheckerTestCase abstracto. Es necesario indicar el verificador que se está verificando en él.
class TestNonKwArgsChecker(CheckerTestCase): CHECKER_CLASS = NonKeywordArgsChecker
Paso 1. Creamos un nodo AST de prueba a partir de la parte del código que estamos verificando.
node = astroid.extract_node( "get_offers(3, 'magic', 'args')" )
Paso 2. Verifique que el verificador, al ingresar al nodo, arroje o no arroje el mensaje correspondiente:
with self.assertAddsMessages(message): self.checker.visit_call(node)
Tokenchecker
Hay otro tipo de corrector llamado
TokenChecker . Funciona según el principio de un analizador léxico. Python tiene un módulo de
tokenize que hace el trabajo de un escáner léxico y divide el código en una lista de tokens. Puede verse más o menos así:

Los nombres de variables, los nombres de funciones y las palabras clave se convierten en tokens de tipo NAME, y los delimitadores, corchetes y dos puntos se convierten en tokens de tipo OP. Además, hay tokens separados para sangría, avance de línea y traducción inversa.
Cómo funciona Pylint con TokenChecker:
- El módulo bajo prueba está tokenizado.
- Se pasa una gran lista de tokens a todos los verificadores que implementan ITokenChecker y se llama al método process_tokens (tokens).
No hemos encontrado el uso de TokenChecker, pero hay algunos ejemplos que utiliza Pylint:
- Corrector ortográfico . Por ejemplo, puede tomar todos los tokens con texto de tipo y ver alfabetización léxica, verificar palabras de listas de palabras vacías, etc.
- Comprobar sangrías , espacios.
- Trabajar con cuerdas . Por ejemplo, puede verificar que Python 3 no use literales Unicode, o verificar que solo los caracteres ASCI estén presentes en la cadena de bytes.
Conclusiones
Tuvimos un problema con la revisión del código. Los desarrolladores realizaron el trabajo de la interfaz, dedicaron su tiempo a escanear códigos sin sentido e informaron al autor sobre los errores. Con Pylint nosotros:
- Comprobaciones rutinarias transferidas al linter, implementado acuerdos internos en él.
- Mayor velocidad y revisión de código de calidad.
- Se redujo el número de solicitudes de extracción rechazadas, y el tiempo para pasar tareas en producción se ha reducido.
Un corrector simple se escribe en media hora y uno complejo en pocas horas. El verificador ahorra mucho más tiempo del que toma para escribir y lucha por varias solicitudes de extracción no rechazadas.
Puede obtener más información sobre Pylint y cómo escribir fichas en la
documentación oficial , pero en términos de escribir fichas es bastante pobre. Por ejemplo, sobre TokenChecker solo hay una mención allí, pero no sobre cómo escribir el corrector en sí. Hay más información disponible
en las fuentes de Pylint en GitHub . Puedes ver qué fichas están en el paquete estándar e inspirarte para escribir el tuyo.
El conocimiento del diseño interno de Pylint ahorra horas hombre, simplifica
rendimiento y mejora el código. Ahorre tiempo, escriba un buen código y
use linter.La próxima conferencia de Moscú Python Conf ++ se llevará a cabo el 5 de abril de 2019 y ya puede reservar un boleto anticipado de birf ahora. Es aún mejor reunir sus pensamientos y solicitar un informe, luego la visita será gratuita y se ofrecerán bonitos panecillos como bonificación, incluido el asesoramiento sobre la preparación del informe.
Nuestra conferencia es una plataforma para reunirse con personas de ideas afines, motores de la industria, para comunicar y discutir cosas que los desarrolladores de Python adoran: backend y web, recopilación y procesamiento de datos, AI / ML, pruebas, IoT. Cómo fue en el otoño, mire el informe de video en nuestro canal de Python y suscríbase al canal; pronto publicaremos los mejores informes de la conferencia para acceso gratuito.