Estás aquí si quieres saber cómo domar un marco que es ampliamente conocido en los círculos de desarrolladores de Python llamado Celery. E incluso si Celery ejecuta con confianza comandos básicos en su proyecto, entonces la experiencia fintech puede abrir lados desconocidos para usted. Porque fintech siempre es Big Data, y con ello la necesidad de tareas en segundo plano, procesamiento por lotes, API asíncrona, etc.

La belleza de la historia de Oleg Churkin sobre el apio en
Moscú Python Conf ++, además de instrucciones detalladas sobre cómo configurar el apio bajo carga y cómo monitorearlo, es que puede tomar prestadas ideas útiles.
Sobre el orador y el proyecto: Oleg Churkin (
Bahusss ) ha estado desarrollando proyectos de Python de diversa complejidad durante 8 años, ha trabajado en muchas compañías conocidas: Yandex, Rambler, RBC, Kaspersky Lab. Ahora techlide en el inicio fintech-StatusPoney.
El proyecto funciona con una gran cantidad de datos financieros de los usuarios (1,5 terabytes): cuentas, transacciones, comerciantes, etc. Ejecuta hasta un millón de tareas todos los días. Tal vez este número no le parecerá muy grande a alguien, pero para una pequeña empresa con capacidades modestas esta es una cantidad significativa de datos, y los desarrolladores tuvieron que enfrentar varios problemas en el camino hacia un proceso estable.
Oleg habló sobre los puntos clave de trabajo:
- ¿Qué tareas quería resolver con el marco, por qué eligió Celery?
- Cómo ayudó el apio.
- Cómo configurar el apio bajo carga.
- Cómo monitorear el estado del apio.
Y compartió un par de utilidades de diseño que implementan la funcionalidad que falta en Celery. Como resultó, en 2018, y esto puede ser. La siguiente es una versión de texto del informe en primera persona.
Problema
Fue necesario para resolver las siguientes tareas:
- Ejecute tareas en segundo plano separadas .
- Realice el procesamiento por lotes de tareas , es decir, ejecute muchas tareas a la vez.
- Incrustar el proceso Extraer, Transformar, Cargar .
- Implemente la API asincrónica . Resulta que la API asincrónica se puede implementar no solo usando marcos asincrónicos, sino también completamente sincrónicos;
- Realizar tareas periódicas . Ningún proyecto puede prescindir de tareas periódicas; para algunos, se puede prescindir de Cron, pero también hay herramientas más convenientes.
- Cree una arquitectura de desencadenante : para desencadenar un desencadenador, ejecute una tarea que actualice los datos. Esto se hace para compensar la falta de potencia de tiempo de ejecución calculando previamente los datos en segundo plano.
Las tareas en segundo plano incluyen cualquier tipo de notificación: correo electrónico, inserción, escritorio: todo esto se envía en tareas en segundo plano mediante un disparador. Del mismo modo, se inicia una actualización periódica de datos financieros.
En segundo plano, se realizan varias comprobaciones específicas, por ejemplo, la comprobación de un usuario por fraude. En las startups financieras, se
presta mucho esfuerzo y atención específicamente a la seguridad de los datos , ya que permitimos a los usuarios agregar sus cuentas bancarias a nuestro sistema, y podemos ver todas sus transacciones. Los estafadores pueden intentar usar nuestro servicio para algo malo, por ejemplo, para verificar el saldo de una cuenta robada.
La última categoría de tareas en segundo plano son
las tareas de mantenimiento : ajustar algo, ver, arreglar, monitorear, etc.
Para notificaciones masivas,
se utiliza el procesamiento por lotes . Una gran cantidad de datos que recibimos de nuestros usuarios debe calcularse y procesarse de cierta manera, incluyendo en modo por lotes.
El mismo concepto incluye el clásico
Extraer, Transformar, Cargar :
- cargar datos de fuentes externas (API externa);
- mantener sin procesar;
- ejecutar tareas que leen y procesan datos;
- guardamos los datos procesados en el lugar correcto en el formato correcto, para que luego sea conveniente usarlos en la interfaz de usuario, por ejemplo.
No es ningún secreto que la API asincrónica se puede hacer mediante solicitudes de sondeo simples: el front-end inicia el proceso en el back-end, el back-end inicia una tarea que se inicia periódicamente, "vierte" los resultados y actualiza el estado en la base de datos. La interfaz muestra al usuario este estado interactivo: el estado está cambiando. Esto le permite:
- ejecutar tareas de sondeo desde otras tareas;
- ejecutar diferentes tareas según las condiciones.
En nuestro servicio, esto es suficiente por ahora, pero en el futuro probablemente tendremos que reescribir algo más.
Requerimientos de herramientas
Para implementar estas tareas, teníamos los siguientes requisitos para las herramientas:
- Funcionalidad necesaria para realizar nuestras ambiciones.
- Escalabilidad sin muletas.
- Monitoreo del sistema para entender cómo funciona. Utilizamos informes de errores, por lo que la integración con Sentry no estará fuera de lugar, con Django también.
- Rendimiento , porque tenemos muchas tareas.
- La madurez, la fiabilidad y el desarrollo activo son cosas obvias. Estábamos buscando una herramienta que sea compatible y desarrollada.
- Adecuación de la documentación: no hay documentación en ningún lado .
¿Qué herramienta elegir?
¿Cuáles son las opciones en el mercado en 2018 para resolver estos problemas?
Érase una vez para tareas menos ambiciosas, escribí una
biblioteca útil que todavía se usa en algunos proyectos. Es fácil de operar y realiza tareas en segundo plano. Pero al mismo tiempo, no se necesitan corredores (ni Celery, ni otros), solo el servidor de aplicaciones
uwsgi , que tiene una cola de impresión, es algo que comienza como un trabajador independiente. Esta es una solución muy simple: todas las tareas se almacenan condicionalmente en archivos. Para proyectos simples, esto es suficiente, pero para los nuestros no fue suficiente.
De alguna manera consideramos:
- Apio (10K estrellas en GitHub);
- RQ (5K estrellas en GitHub);
- Huey (2K estrellas en GitHub);
- Dramatiq (1K estrellas en GitHub);
- Tasktiger (0.5K estrellas en GitHub);
- Flujo de aire? Luigi
Candidato prometedor 2018
Ahora me gustaría llamar su atención sobre
Dramatiq . Esta es una biblioteca del experto Apio, que conocía todas las desventajas de Apio y decidió reescribir todo, solo que muy bien. Beneficios de Dramatiq:
- Un conjunto de todas las características necesarias.
- Afilado de la productividad.
- Soporte centinela y métrico para Prometheus listo para usar
- Una base de código pequeña y claramente escrita, carga automática de código.
Hace algún tiempo, Dramatiq tuvo problemas con las licencias: primero hubo AGPL, luego fue reemplazado por LGPL. Pero ahora puedes intentarlo.
Pero en 2016, además del apio, no había nada especial que tomar. Nos gustó su rica funcionalidad, y luego se adaptaba perfectamente a nuestras tareas, porque incluso entonces era maduro y funcional:
- tenía tareas periódicas fuera de la caja;
- apoyó a varios corredores;
- Integrado con Django y Sentry.
Características del proyecto
Te contaré sobre nuestro contexto, para que la historia adicional sea más clara.
Usamos
Redis como agente de mensajes . He escuchado muchas historias y rumores de que Redis está perdiendo mensajes, que no está adaptado para ser un agente de mensajes. En la experiencia de producción, esto no está confirmado, pero, como resultado, Redis ahora funciona de manera más eficiente que RabbitMQ (es con Celery, al menos, aparentemente, el problema está en el código de integración con los corredores). En la versión 4, se corrigió el agente de Redis, realmente dejó de perder tareas durante los reinicios y funciona de manera bastante estable. En 2016, Celery iba a abandonar Redis y centrarse en la integración con RabbitMQ, pero, afortunadamente, esto no sucedió.
En caso de problemas con Redis, si necesitamos una alta disponibilidad seria, nosotros, debido a que usamos el poder de Amazon, cambiaremos a Amazon SQS o Amazon MQ.
No
utilizamos el backend de resultados para almacenar los resultados , porque preferimos almacenar los resultados nosotros mismos donde queremos y verificarlos de la manera que queramos. No queremos que Celery haga esto por nosotros.
Utilizamos un
grupo de pefork , es decir, trabajadores de procesos que crean bifurcaciones separadas de procesos para concurrencia adicional.
Unidad de trabajo
Discutiremos los elementos básicos para actualizar a aquellos que no han probado el apio, pero que solo lo harán.
La unidad de trabajo para el apio es un desafío . Daré un ejemplo de una tarea simple que envía un correo electrónico.
Función simple y decorador:
@current_app.task def send_email(email: str): print(f'Sending email to email={email}')
El inicio de la tarea es simple: llamamos a la función y la tarea se ejecutará en tiempo de ejecución (send_email (email = "python@example.com")) o en el trabajador, es decir, el efecto mismo de la tarea en segundo plano:
send_email.delay(email="python@example.com") send_email.apply_async( kwargs={email: "python@example.com"} )
Durante dos años de trabajo con apio bajo cargas elevadas, hemos ideado las reglas de buena forma. Hubo muchos rastrillos, aprendimos cómo sortearlos y compartiré cómo.
Diseño de código
La tarea puede contener una lógica diferente. En general, Celery le ayuda a mantener tareas en archivos o paquetes, o importarlas desde algún lugar. A veces obtienes un montón de lógica de negocios en un módulo. En nuestra opinión, el enfoque correcto desde el punto de vista de la modularidad de la aplicación es mantener un
mínimo de lógica en la tarea . Usamos rompecabezas solo como "disparadores" del código. Es decir, la tarea no lleva lógica en sí misma, sino que desencadena el lanzamiento de código en segundo plano.
@celery_app.task(queue='...') def run_regular_update(provider_account_id, *args, **kwargs): """...""" flow = flows.RegularSyncProviderAccountFlow(provider_account_id) return flow.run(*args, **kwargs)
Ponemos todo el código en clases externas que usan algunas otras clases. Todas las tareas consisten esencialmente en dos líneas.
Objetos simples en parámetros
En el ejemplo anterior, se pasa una determinada identificación a la tarea. En todas las tareas que utilizamos,
transferimos solo datos escalares pequeños , id. No serializamos modelos Django para transmitirlos. Incluso en ETL, cuando un gran blob de datos proviene de un servicio externo, primero lo guardamos y luego ejecutamos una tarea que lee todo este blob por id y lo procesa.
Si no hace esto, vimos una gran mezcla de memoria consumida en Redis. El mensaje comienza a ocupar más memoria, la red está muy cargada, la cantidad de tareas procesadas (rendimiento) disminuye. Mientras el objeto llegue a su fin, las tareas se vuelven irrelevantes, el objeto ya ha sido eliminado. Los datos debían ser serializados; no todo está bien serializado en JSON en Python. Cuando volvimos a intentar las tareas, necesitábamos la oportunidad de decidir rápidamente qué hacer con estos datos, obtenerlos nuevamente y realizar algunas verificaciones.
Si transfieres datos grandes en parámetros, ¡piénsalo de nuevo! Es mejor transferir un escalar pequeño con una pequeña cantidad de información sobre el problema, y de esta información en la tarea para obtener todo lo que necesita.
Problemas idempotentes
Los propios desarrolladores de apio recomiendan este enfoque. Cuando se repite la sección del código, no deben producirse efectos secundarios, el resultado debe ser el mismo. Esto no siempre es fácil de lograr, especialmente si hay una interacción con muchos servicios o compromisos de dos fases.
Pero cuando hace todo localmente, siempre puede verificar que los datos entrantes existan y sean relevantes, realmente puede trabajar en ellos y usar transacciones. Si hay muchas consultas en la base de datos para una tarea y algo puede salir mal en el tiempo de ejecución, use las transacciones para revertir los cambios innecesarios.
Compatibilidad con versiones anteriores
Tuvimos algunos efectos secundarios interesantes cuando implementamos la aplicación. No importa qué tipo de implementación use (azul + verde o actualización continua), siempre habrá una situación en la que el código de servicio anterior crea mensajes para el nuevo código de trabajador, y viceversa, el antiguo trabajador recibe mensajes del nuevo código de servicio, porque se implementó "primero" y allí se fue el tráfico.
Detectamos errores y perdimos tareas hasta que aprendimos cómo mantener la
compatibilidad con versiones anteriores . La compatibilidad con versiones anteriores es que entre las versiones las tareas deberían funcionar de manera segura, sin importar qué parámetros entren en esta tarea. Por lo tanto, en todas las tareas ahora estamos haciendo una firma "de goma" (** kwargs). Cuando necesite agregar un nuevo parámetro en la próxima versión, lo tomará de ** kwargs en la nueva versión, pero no lo tomará en el anterior, nada se romperá. Tan pronto como la firma cambia, y Celery no lo sabe, se bloquea y da un error de que no hay tal parámetro en la tarea.
Una forma más rigurosa de evitar tales problemas es versionar las colas de tareas entre versiones, pero es bastante difícil de implementar y lo dejamos en el trabajo pendiente por ahora.
Tiempos de espera
Pueden surgir problemas debido a números insuficientes o tiempos de espera incorrectos.
No establecer un tiempo de espera para una tarea es malo. Esto significa que no comprende lo que está sucediendo en la tarea, cómo debería funcionar la lógica empresarial.
Por lo tanto, todas nuestras tareas están colgadas con tiempos de espera, incluidos los globales para todas las tareas, y también se establecen tiempos de espera para cada tarea específica.
Debe colocarse: soft_limit_timeout y
caduca.Expira es cuánto puede vivir una tarea en línea. Es necesario que las tareas no se acumulen en las colas en caso de problemas. Por ejemplo, si ahora queremos informar algo al usuario, pero sucedió algo y la tarea se puede completar solo mañana, esto no tiene sentido, mañana el mensaje ya no será relevante. Por lo tanto, para las notificaciones tenemos un vencimiento bastante pequeño.
Tenga en cuenta el uso de
eta (cuenta atrás) + visibilidad _timeout . Las preguntas frecuentes describen tal problema con Redis: el llamado tiempo de espera de visibilidad del agente de Redis. Por defecto, su valor es de una hora: si después de una hora el trabajador ve que nadie ha llevado la tarea a ejecución, la vuelve a agregar a la cola. Por lo tanto, si la cuenta regresiva es de dos horas, después de una hora, el corredor descubrirá que esta tarea aún no se ha completado y creará otra de la misma. Y en dos horas, se completarán dos tareas idénticas.
Si el tiempo estimado o la cuenta regresiva excede 1 hora, lo más probable es que el uso de Redis dé como resultado la duplicación de tareas, a menos, por supuesto, que haya cambiado el valor de visibilidad_tiempo de espera en la configuración para conectarse al corredor.
Política de reintento
Para aquellas tareas que pueden repetirse o que pueden fallar, utilizamos la política Reintentar. Pero lo usamos con cuidado para no abrumar los servicios externos. Si repite rápidamente las tareas sin especificar un retroceso exponencial, entonces un servicio externo, o quizás uno interno, simplemente no lo soportará.
Sería bueno especificar explícitamente los parámetros
retry_backoff ,
retry_jitter y
max_retries , especialmente max_retries. retry_jitter: un parámetro que le permite generar un poco de caos para que las tareas no comiencen a repetirse al mismo tiempo.
Fugas de memoria
Desafortunadamente, las pérdidas de memoria son muy fáciles, y encontrarlas y solucionarlas es difícil.
En general, trabajar con memoria en Python es muy controvertido. Pasará mucho tiempo y nervios para comprender por qué ocurre la fuga, y luego resulta que ni siquiera está en su código. Por lo tanto, siempre, al iniciar un proyecto, ponga un
límite de memoria en el trabajador : worker_max_memory_per_child.
Esto asegura que OOM Killer no venga un día, no mate a todos los trabajadores y no pierda todas las tareas. El apio reiniciará a los trabajadores cuando sea necesario.
Tareas prioritarias
Siempre hay tareas que deben completarse antes que los demás, más rápido que nadie: ¡deben completarse ahora mismo! Hay tareas que no son tan importantes: deje que se completen durante el día. Para esto, la tarea tiene un parámetro de
prioridad. En Redis, funciona bastante interesante: se crea una nueva cola con un nombre en el que se agrega prioridad.
Utilizamos un enfoque diferente:
trabajadores separados para las prioridades , es decir a la antigua usanza, creamos trabajadores de apio con diferente "importancia":
celery multi start high_priority low_priority -c:high_priority 2 -c:low_priority 6 -Q:high_priority urgent_notifications -Q:low_priority emails,urgent_notifications
Celery multi start es un ayudante que lo ayuda a ejecutar toda la configuración de Celery en una máquina y desde la misma línea de comando. En este ejemplo, creamos nodos (o trabajadores): high_priority y low_priority, 2 y 6 son concurrencia.
Dos trabajadores de alta prioridad procesan constantemente la cola de notificaciones urgentes. Nadie más tomará estos trabajadores, solo leerán tareas importantes de la cola de notificaciones urgentes.
Para tareas sin importancia hay una cola de baja prioridad. Hay 6 trabajadores que reciben mensajes de todas las demás colas. También suscribimos a los trabajadores de baja prioridad a notificaciones urgentes para que puedan ayudar si los trabajadores de alta prioridad no pueden hacer frente.
Utilizamos este esquema clásico para priorizar tareas.
Extraer, transformar, cargar
Muy a menudo, ETL parece una cadena de tareas, cada una de las cuales recibe información de la tarea anterior.
@task def download_account_data(account_id) … return account_id @task def process_account_data(account_id, processing_type) … return account_data @task def store_account_data(account_data) …
El ejemplo tiene tres tareas. Apio tiene un enfoque para el procesamiento distribuido y varias utilidades útiles, incluida la función de
cadena , que hace que una de cada tres tareas:
chain( download_account_data.s(account_id), process_account_data.s(processing_type='fast'), store_account_data.s() ).delay()
Apio desarmará la tubería, realizará la primera tarea en orden, luego transferirá los datos recibidos a la segunda y transferirá los datos que la segunda tarea devuelve a la tercera. Así es como implementamos tuberías ETL simples.
Para cadenas más complejas, debe conectar lógica adicional. Pero es importante tener en cuenta que si surge un problema en esta cadena en una tarea, entonces
toda la cadena se vendrá abajo . Si no desea este comportamiento, maneje la excepción y continúe la ejecución, o detenga toda la cadena por excepción.
De hecho, esta cadena en el interior parece una gran tarea, que contiene todas las tareas con todos los parámetros. Por lo tanto, si abusa de la cantidad de tareas en la cadena, obtendrá un consumo de memoria muy alto y una desaceleración del proceso general.
Crear cadenas de miles de tareas es una mala idea.Procesamiento de tareas por lotes
Ahora lo más interesante: qué sucede cuando necesita enviar un correo electrónico a dos millones de usuarios.
Escribes una función para evitar a todos los usuarios:
@task def send_report_emails_to_users(): for user_id in User.get_active_ids(): send_report_email.delay(user_id=user_id)
Sin embargo, la mayoría de las veces la función recibirá no solo la identificación del usuario, sino que también eliminará toda la tabla de usuarios en general. Cada usuario tendrá su propia tarea.
Hay varios problemas en esta tarea:
- Las tareas se inician secuencialmente, es decir, la última tarea (dos millones de usuarios) comenzará en 20 minutos y tal vez para este tiempo de espera ya funcione.
- Todos los ID de usuario se cargan primero en la memoria de la aplicación y luego en la cola: delay () realizará 2 millones de tareas.
Lo llamé Tarea de inundación, el gráfico se parece a esto.
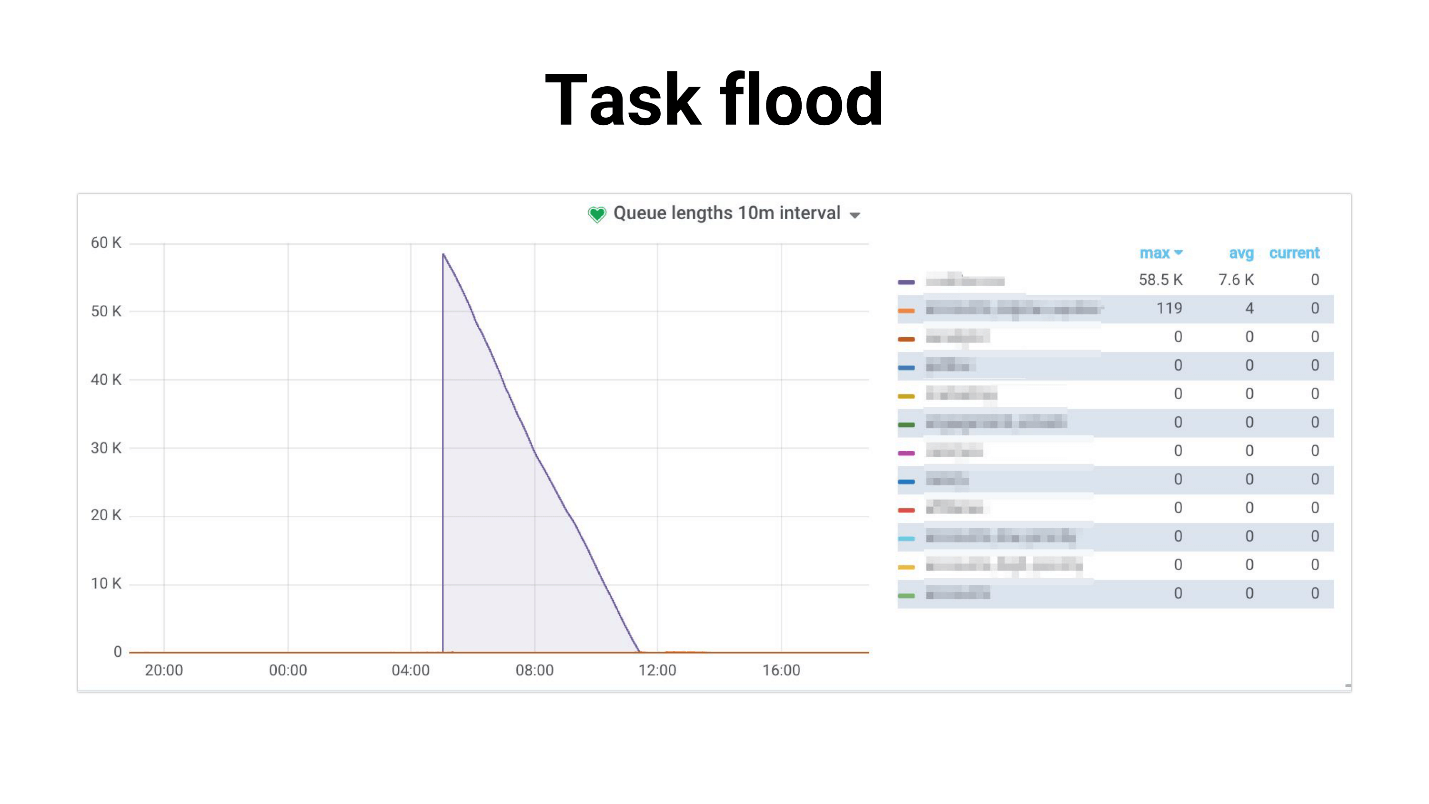
Hay una afluencia de tareas que los trabajadores comienzan a procesar lentamente. Lo siguiente sucede si las tareas usan una réplica maestra, todo el proyecto comienza a resquebrajarse, nada funciona. A continuación se muestra un ejemplo de nuestra práctica, donde el uso de la CPU de la base de datos fue del 100% durante varias horas, para ser honesto, logramos asustarnos.

El problema es que el sistema está muy degradado con un aumento en el número de usuarios. La tarea que se ocupa de la programación:
- requiere más y más memoria;
- corre más tiempo y puede ser "asesinado" por tiempo de espera.
Se produce una inundación de tareas: las tareas se acumulan en colas y crean una gran carga no solo en los servicios internos, sino también en los externos.
Intentamos
reducir la competitividad de los trabajadores , esto ayuda en cierto sentido: se reduce la carga del servicio. O puede
escalar los servicios internos . Pero esto no resolverá el problema del problema del generador, que todavía tiene mucho. Y de ninguna manera afecta la dependencia del desempeño de los servicios externos.
Generación de tareas
Decidimos tomar un camino diferente. Con mucha frecuencia, no necesitamos ejecutar los 2 millones de tareas en este momento. Es normal que el envío de notificaciones a todos los usuarios demore, por ejemplo, 4 horas si estas cartas no son tan importantes.
Primero intentamos usar
Celery.chunks :
send_report_email.chunks( ({'user_id': user.id} for user in User.objects.active()), n=100 ).apply_async()
Esto no cambió la situación, porque, a pesar del iterador, todo user_id se cargará en la memoria. Y todos los trabajadores obtienen una cadena de tareas, y aunque los trabajadores se relajarán un poco, al final no quedamos satisfechos con esta decisión.
Intentamos establecer
rate_limit a los trabajadores para que solo procesen un cierto número de tareas por segundo, y descubrimos que en realidad rate_limit especificado para la tarea es rate_limit para el trabajador. Es decir, si especifica rate_limit para la tarea, esto no significa que la tarea se realizará 70 veces por segundo. Esto significa que el trabajador lo ejecutará 70 veces por segundo, y dependiendo de lo que tenga con los trabajadores, este límite puede cambiar dinámicamente, es decir. límite real rate_limit * len (trabajadores).
Si el trabajador comienza o se detiene, entonces el límite de velocidad total cambia. Además, si sus tareas son lentas, toda la captación previa en la cola que llena al trabajador se obstruirá con estas tareas lentas. El trabajador mira: “Oh, tengo esta tarea en rate_limit, ya no puedo realizarla. Y todas las siguientes tareas en la cola son exactamente las mismas: ¡déjenlas colgar! - Y esperando.
Chunkificator
Al final, decidimos que escribiríamos la nuestra, e hicimos una pequeña biblioteca, que se llamaba Chunkificator.
@task @chunkify_task(sleep_timeout=...l initial_chunk=...) def send_report_emails_to_users(chunk: Chunk): for user_id in User.get_active_ids(chunk=chunk): send_report_email.delay(user_id=user_id)
Toma sleep_timeout e initial_chunk, y se llama a sí mismo con un nuevo fragmento. Chunk es una abstracción sobre listas enteras o sobre listas de fecha o fecha y hora. Pasamos un fragmento a una función que recibe a los usuarios solo con este fragmento y ejecuta tareas solo para ese fragmento.
Por lo tanto, el generador de tareas ejecuta solo la cantidad de tareas que se necesitan y no consume mucha memoria. La imagen se ha vuelto así.

Lo más destacado es que usamos un fragmento disperso, es decir, utilizamos instancias en la base de datos como identificación del fragmento (algunos de ellos pueden omitirse, por lo que puede haber menos tareas). Como resultado, la carga resultó ser más uniforme, el proceso se hizo más largo, pero todos están vivos y bien, la base no se esfuerza.
La biblioteca está implementada para Python 3.6+ y está disponible en GitHub. Hay un matiz que planeo arreglar, pero por ahora datetime-chunk necesita un serializador de pepinillos, muchos no podrán hacerlo.
Un par de preguntas retóricas: ¿de dónde vino toda esta información? ¿Cómo descubrimos que teníamos problemas? ¿Cómo sabe que un problema pronto se volverá crítico y necesita comenzar a resolverlo?
La respuesta es, por supuesto, el monitoreo.
Monitoreo
Realmente me gusta monitorear, me gusta monitorear todo y mantener mi dedo en el pulso. Si no mantiene el dedo en el pulso, pisará constantemente el rastrillo.
Preguntas de monitoreo estándar:
- ¿La configuración actual de trabajador / concurrencia maneja la carga?
- ¿Cuál es la degradación del tiempo de ejecución de la tarea?
- ¿Cuánto tiempo duran las tareas en línea? De repente, la línea ya está llena?
Intentamos varias opciones. El apio tiene una interfaz
CLI , es bastante rico y ofrece:
- inspeccionar - información sobre el sistema;
- control: administra la configuración del sistema;
- purga - colas claras (fuerza mayor);
- eventos: interfaz de usuario de la consola para mostrar información sobre las tareas que se realizan.
Pero es difícil realmente monitorear algo. Es más adecuado para volantes locales, o si desea cambiar algún rate_limit en tiempo de ejecución.
NB: necesita acceso al agente de producción para usar la interfaz CLI.
Celery Flower le permite hacer lo mismo que la CLI, solo a través de la interfaz web, y eso no es todo. Pero crea algunos gráficos simples y le permite cambiar la configuración sobre la marcha.
En general, Celery Flower es adecuada para ver cómo funciona todo en configuraciones pequeñas. Además, admite la API HTTP, que es conveniente si está escribiendo automatización.
Pero nos
instalamos en Prometeo. Se llevaron al
exportador actual: reparó pérdidas de memoria; métricas agregadas para tipos de excepción; métricas agregadas para la cantidad de mensajes en las colas; Integrado con alertas en Grafana y regocijo. También está publicado en GitHub, puedes verlo
aquí .
Ejemplos en Grafana

Estadísticas anteriores para todas las excepciones: qué excepciones para qué tareas. A continuación se muestra el tiempo para completar las tareas.

¿Qué falta en el apio?
Este es un marco frondoso, tiene muchas cosas, ¡pero nos falta! No hay suficientes características pequeñas, como:
- Recarga automática de código durante el desarrollo , no es compatible con este Celery, reinicie.
- Las métricas para Prometheus están listas para usar , pero Dramatiq sí.
- Soporte para el bloqueo de tareas , de modo que solo se ejecute una tarea a la vez. Puede hacerlo usted mismo, pero Dramatiq y Tasktiger tienen un decorador conveniente que garantiza que todas las demás tareas similares se bloqueen.
- Rate_limit para una tarea , no para el trabajador.
Conclusiones
A pesar de que el apio es un marco que muchos usan en la producción, consta de 3 bibliotecas: apio, kombu y billar. Las tres bibliotecas están desarrolladas por co-desarrolladores, y pueden liberar una dependencia y romper su ensamblaje.
Por lo tanto, espero que ya lo haya resuelto de alguna manera y haya hecho que sus asambleas sean deterministas.
De hecho, las conclusiones no son tan tristes.
El apio hace frente a sus tareas en nuestro proyecto fintech bajo nuestra carga. Hemos adquirido experiencia que compartí con usted, y puede aplicar nuestras soluciones o refinarlas y también superar todas sus dificultades.
No olvide que el
monitoreo debe ser una parte esencial de su proyecto . Solo a través del monitoreo puede descubrir dónde tiene algo mal, qué necesita ser reparado, agregado, reparado.
Ponente de contacto Oleg Churkin :
Bahusss ,
facebook y
github .
La próxima gran Python Conf ++ de Moscú se celebrará en Moscú el 5 de abril . Este año intentaremos ajustar todos los beneficios en un día en modo experimental. No habrá menos informes, asignaremos una secuencia completa a desarrolladores extranjeros de bibliotecas y productos conocidos. Además, el viernes es un día ideal para fiestas posteriores, que, como saben, es una parte integral de la conferencia sobre comunicación.
Únase a nuestra conferencia profesional de Python: envíe su informe aquí , reserve su boleto aquí . Mientras tanto, los preparativos están en marcha, los artículos sobre Moscow Python Conf ++ 2018 aparecerán aquí.