Todos escribimos código. Mucho código. Por supuesto, hay errores. A veces es solo un código torcido, y a veces el precio de un error es una
nave espacial explotada. Por supuesto, nadie hace jambas intencionales, todos intentan monitorear la calidad lo mejor que pueden, pero sin las herramientas de análisis estático es casi imposible asegurarse de que todo sea perfecto.
Linters ayudan a llevar el código a un estilo único y evitar errores. Es cierto, solo si está listo para sufrir, y finalmente no descarta "pylint: disable", solo para retrasarlo. Lo que debería ser un linter, y por qué Pylint no puede hacerlo, conoce a Nikita
Sobolevn , que entiende y ama tanto a los
fanáticos que incluso nombró a su compañía para no molestarlos - wemake.services.
A continuación se muestra la versión de texto del informe sobre
Moscow Python Conf ++ sobre linters, cómo hacerlo correctamente y cómo no hacerlo. La presentación tuvo mucha interactividad, en línea y comunicación con la audiencia. El orador, en el camino, realizó encuestas y trató de convencer a la audiencia: observó la tendencia y, como en el debate, trató de igualar la proporción y cambiar la opinión pública. Algunas partes de las encuestas cayeron en descifrado, pero no todas, por lo que se adjunta un video para completar la imagen.
¿Por qué necesitamos linters?
La tarea más importante de linter es
llevar el código a la uniformidad . Hay muchas opciones para escribir lo mismo en Python: ponga una coma aquí o allá, olvide cerrar los corchetes o no lo olvide. Cuando las personas escriben código durante mucho tiempo, se convierte en una colcha de retazos de piezas dispares cosidas en diferentes momentos. Es desagradable trabajar con una manta de este tipo, desalienta la lectura del código, lo cual es muy malo.
Linters hacen la vida más fácil en una revisión . Llego a la revisión del código y pienso: “¡No quiero hacer esto! ¡Ahora habrá espacios adicionales y otras tonterías! ” Me gustaría que alguien más preparara un buen código, y después de eso apreciaré las grandes cosas conceptuales.
A veces miro el código y pienso que todo está bien, y luego veo en alguna función demasiadas variables o un error al que no le presté atención. La automatización encontraría este error, pero miré. Para no caer en tales situaciones, utilizo el
linter ,
encuentra todo lo que está oculto y es difícil de encontrar.¿Qué son las linters?
Los más simples verifican solo el estilo , por ejemplo,
Flake8 . Hasta cierto punto, también negro, pero más bien es un autoformer-linter.
Linters prueba la semántica más difícil , y no solo la estilística: lo que haces, por qué y te
pega en las manos si escribes con errores. Un buen ejemplo es
Pylint , que todos conocemos, usamos y amamos. Llamo a estos linters -
Mejores prácticas . El tercer tipo es la
verificación de tipo , estos linter están un poco alejados. La comprobación de tipos en Python es nueva, ahora está siendo realizada por dos plataformas de la competencia:
Mypy y
Pyre .
¿Cómo usar linter?
No pretendo que linter sea una panacea y un reemplazo para todo. Esto no es asi. Linter: el primer paso de la pirámide, mediante el cual el código entra en producción.
Hay tres pasos en la pirámide:
- Lanzar linter . Es muy rápido y no necesita nada más que el código fuente: sin infraestructura, sin configuración. Verificación: se aprobó la primera verificación de cordura ; todo está bien, estamos trabajando.
- Etapa de prueba Este proceso es más complicado y más largo debido a errores que no son de código. Ya necesitaremos la configuración correcta y completa de toda la aplicación.
- Revisión de escenario .
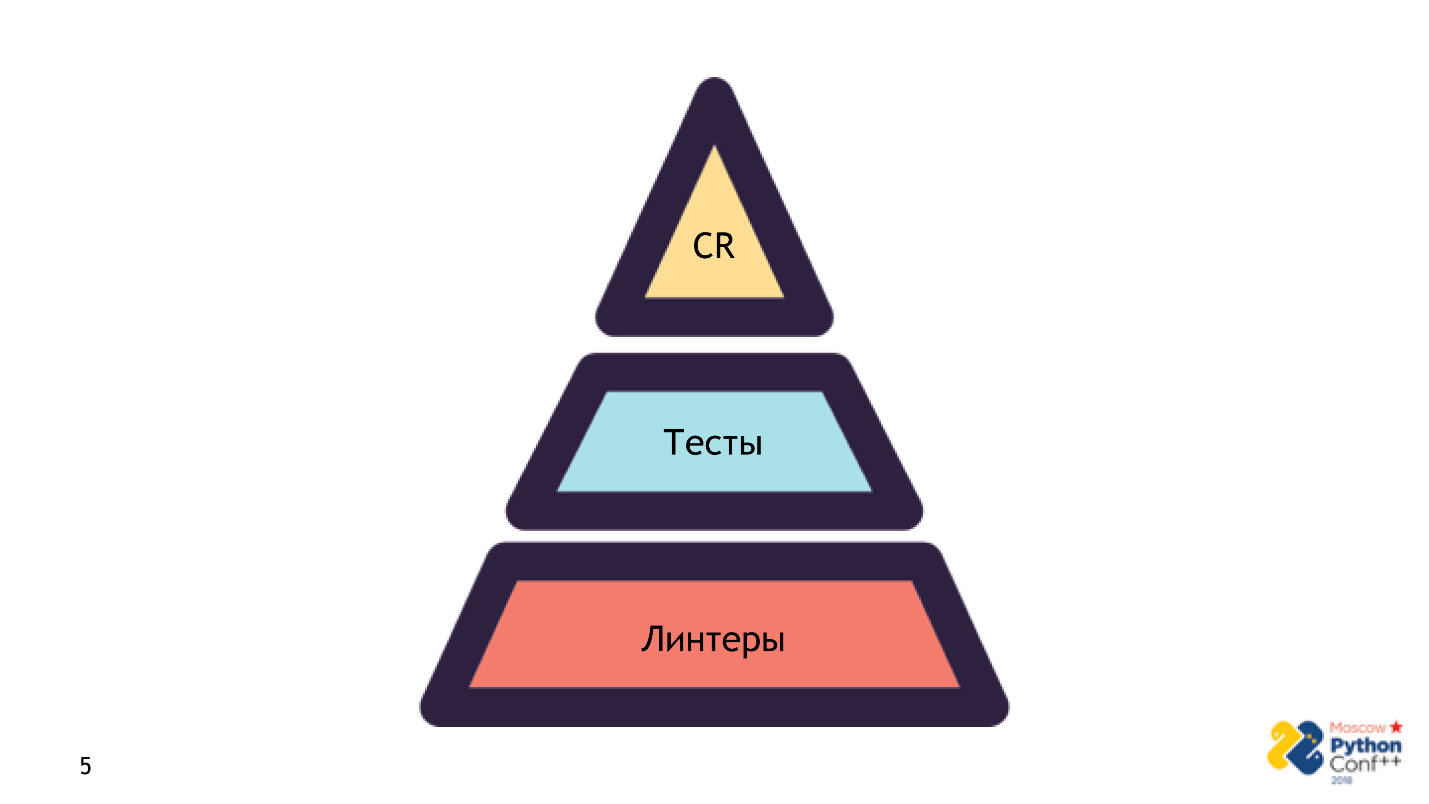 Estos son los pasos necesarios
Estos son los pasos necesarios para que el código entre en producción. Si no realizó un paso, olvidó algo o el revisor dijo que no funcionaría, verá la inscripción: falló: el código incorrecto no entra en producción.
¿Utilizas un linter en el trabajo?
Si le preguntas a los desarrolladores de una empresa difícil, en la que trabajan los 7 días de la semana, si usan un linter, entonces resulta que al menos un tercio de ellos usan linters de manera muy estricta:
CI cae, las verificaciones son severas . El resto aplica aproximadamente linter
al estilo de prueba ,
nunca y como un
sistema de informes : inician el linter, generan un informe y ven lo mal que está todo. Se usan linters, y eso es bueno. En nuestra empresa, todo se construyó con dureza: enlaces duros, muchas verificaciones, revisión de código doble.
Revisión de código
Los problemas surgen justo en esta etapa. Este es el paso superior y más difícil de la pirámide: la revisión del código no puede automatizarse y, si es posible, conducirá a la automatización de la escritura del código. Entonces los programadores no serán necesarios.
El proceso estándar tiene este aspecto: el código se revisa, encuentro errores y no quiero volver a cometerlos. Por ejemplo, vi que el desarrollador captó BaseException: “No hagas eso. ¡Por favor no atrapes! " Después de 10 días, lo mismo. Te recuerdo de nuevo:
-
No capturamos BaseException."
Bien, lo entiendo".Pasa un año, el mismo error. Llega un nuevo hombre, el mismo error. Pienso: ¿cómo podemos automatizar todo para que la situación no vuelva a suceder y solo se me ocurra: “
Vamos a cortar nuestra pelusa? »Creemos un paquete abierto, coloquemos allí todas las reglas que usamos en el trabajo y automaticemos la verificación de reglas para que cada vez no escribamos a mano. ¡Automatizamos todo bien y de inmediato!
Naturalmente, usted puede decir: "
Ya existen linters confeccionados, funcionan, todos los usan, ¿por qué hacer los suyos?", Y tendrá toda la razón, porque realmente hay linters. Veamos cuáles y qué hacen.
Pylint
En el encabezado "
¿Por qué no Pylint?" "He escuchado esta pregunta muchas veces. Le responderé más suavemente. Pylint es una gran herramienta de estrella de rock para el código Python, pero tiene características que no quiero ver en mi linter.
Mezcla todo: controles estilísticos, mejores prácticas y controles de tipo . La comprobación de tipo de Pylint está poco desarrollada porque no hay información de tipo: intenta mostrarla de alguna manera, pero no funciona muy bien. Por lo tanto, a menudo cuando escribo
model_name.some_property en Django, puedo ver el error: "Lo siento, no existe esa propiedad, ¡no puede usarla!" Recuerdo que hay un complemento, lo instalo, luego uso Celery, también comienza algún tipo de problema, instalo el complemento para Celery, uso otra biblioteca mágica y, como resultado, escribo en todas partes: "pylint: disable" ... No es eso lo que quiero obtener de linter.
Otra característica oculta para el usuario es
que Pylint tiene su propia implementación del árbol de sintaxis abstracta en Python . Así es como se ve el código cuando lo analiza y obtiene información sobre el árbol de nodos que conforman el código. Realmente no confío en mis propias implementaciones, porque siempre están equivocadas.
Además de Pylint, hay otras linters que también hacen su trabajo.
Sonarquube
Una herramienta maravillosa, pero separada, que vive en algún lugar cercano a su proyecto.
- SonarQube no podrá ejecutarse con frecuencia : debe implementarse en algún lugar, mirar, monitorear, configurar.
- Está escrito en Java . Si quieres arreglar tu linter para Python, escribirás código en Java. Creo que, conceptualmente, esto está mal: un desarrollador que pueda escribir en Python debería poder escribir código para probar Python.
La compañía que desarrolla SonarQube analiza específicamente el concepto de desarrollo de productos. Esto puede ser un problema.
La ventaja de SonarQube es que tiene controles muy interesantes que muestran complejidad, posibles errores ocultos y errores. Me gustan los cheques, los dejaría y cambiaría la plataforma.
Flake8
Un linter maravilloso es muy simple, pero con un problema:
hay pocas reglas por las cuales verifica qué tan bien está escrito el código. Al mismo tiempo, Flake8 tiene muchos complementos muy simples: el complemento mínimo son 2 métodos que deben implementarse. Pensé: tomemos Flake8 como base y escribamos complementos, pero con nuestra comprensión de los beneficios para la empresa. Y así lo hicimos.
El linter más estricto del mundo.
Creamos una herramienta en la que recopilamos todo lo que creemos que es adecuado para Python y lo llamamos
wemake-python-styleguide . El complemento se publicó públicamente, ya que creo que
Open Source por defecto es una buena práctica . Estoy profundamente convencido de que muchas herramientas se beneficiarán si se cargan en Open Source. Para nuestro instrumento, se nos ocurrió el eslogan:
"¡El linter más estricto del mundo!"La palabra clave en nuestro lenguaje es estricta, lo que significa dolor y sufrimiento.
Si usas el linter, y no te hace sufrir, así que te aferras a la cabeza: "¿Por qué no te gusta, maldita sea?", Entonces este es un mal linter. Omite errores, no supervisa suficientemente la calidad del código y no lo necesitamos. Necesitamos los más estrictos del mundo, lo cual es muy importante. Ahora tenemos alrededor de
250 pruebas diferentes en ambas categorías : estilísticas y mejores prácticas, pero sin verificación de tipo. Mypy está involucrado en eso, no le preocupamos de ninguna manera.
Nuestro linter
no tiene
compromiso . No tenemos reglas de la categoría "No quisiera hacer esto, pero si realmente quieres, puedes hacerlo". No, siempre hablamos con dureza, no lo hacemos porque es malo. Entonces la gente viene y dice: "¡Hay 2.5 casos de uso en los que esto es posible en principio!". Si hay tales casos, escriba claramente que esta línea es permisible para que la interfaz la ignore, pero explique por qué. Debe ser un comentario sobre por qué permitiste alguna práctica extraña y por qué lo estás haciendo. Este enfoque también es útil para documentar el código.
El linter más estricto
no requiere configuración (WIP) . Todavía tenemos configuraciones, pero queremos deshacernos de ellas: al tener libertad, el usuario seguramente configurará para que el linter no funcione correctamente.
Una buena herramienta no necesita configuración, tiene buenos valores predeterminados.
Con este enfoque, el código será coherente y funcionará igual para todos, al menos en teoría. Todavía estamos trabajando en esto, y aunque hay configuraciones, puede usar nuestra herramienta y personalizarla usted mismo.
¿De quién dependemos?
De una gran cantidad de herramientas.
- Escama 8 .
- Eradicate es un complemento genial que encuentra fragmentos comentados en el código y hace que los elimine, porque almacenar código muerto en un proyecto es malo. No se nos permite hacerlo.
- Isort es una herramienta que te obliga a ordenar las importaciones correctamente: en orden, sangría, comillas hermosas.
- Bandit es una gran herramienta para verificar la seguridad del código de forma estática. Encuentra contraseñas cableadas, uso torpe de
assert en el código, llama a Popen , sys.exit y dice que no se puede usar todo esto, pero si lo desea, le pide que escriba el motivo. - Y más de 20 complementos que verifican corchetes, comillas y comillas.
¿Qué estamos comprobando?
Hay 4 grupos de reglas que usamos y aplicamos.
La complejidad es el mayor problema. No sabemos qué es la complejidad y no lo vemos en el código. Observamos el código con el que trabajamos todos los días y parece que no es complicado: tómalo, léelo, todo funciona. Esto no es asi. El código simple es un código familiar. La complejidad tiene criterios claros que probamos. Sobre los criterios mismos, más adelante. Si el código viola los criterios, entonces decimos: "El código es complejo, ¡reescribe!"
Los nombres de las variables son un problema de programación no resuelto. Quién leerá cuándo y en qué contexto no está claro. Intentamos que los nombres sean lo más coherentes y comprensibles posible, pero aunque lo intentamos, el problema aún no se ha resuelto por completo.
Por
coherencia , tenemos una regla simple: escribir lo mismo en todas partes. Si hay algún enfoque aprobado, úselo en todas partes. No importa si te gusta o no, la consistencia es más importante.
Intentamos utilizar solo las
mejores prácticas. Si sabemos que alguna práctica no es muy buena, entonces prohibimos su uso. Si el desarrollador quiere usar prácticas prohibidas, entonces esperamos argumentos de él: por qué y por qué aplicar. Quizás, durante el proceso de descripción, se entenderá por qué es malo.
¿Qué es la complejidad?
La complejidad tiene métricas específicas que puede ver y decir si es difícil o no. Hay muchos de ellos.
Complejidad ciclomática: la complejidad ciclomática favorita de todos. Encuentra en el código una gran cantidad de estructuras anidadas
if ,
for ejemplo, e indica demasiadas ramificaciones del código y dificultades en la lectura. Todo está mal con el código incrustado: lees, lees, lees, volviste, leíste, leíste, saltaste y luego saltaste a otro ciclo. Es imposible pasar de manera segura dicho código de arriba a abajo.
Argumentos, declaraciones y devoluciones. Estas son métricas cuantitativas: cuántos argumentos hay en la función o en el método, cuántos están dentro del cuerpo de esta función o el método de declaraciones y retornos.
La cohesión y el acoplamiento son métricas populares de OOP.
La cohesión muestra la conexión de la clase interior. Por ejemplo, hay una clase, y en el interior utilizas todos los métodos y propiedades, todo lo que declaraste. Esta es una buena clase con alta conectividad en el interior.
El acoplamiento es cuánto están conectadas las diferentes partes del sistema: módulos y clases. Queremos lograr la máxima conectividad dentro de la clase y una conectividad mínima afuera. Entonces el sistema se mantiene fácilmente y funciona bien.
Complejidad de Jones : tomé prestada esta métrica, ¡pero solo porque es una bomba! La complejidad de Jones determina la complejidad de una línea: cuanto más compleja es la línea, más difícil es de entender, porque la memoria humana a corto plazo no puede procesar más de 5-9 objetos a la vez. Esta es la llamada
billetera de Miller .
Observamos estas métricas importantes y algunas otras, que son mucho más grandes, y determinamos si el código es adecuado o no. A nuestro entender, la
complejidad es una cascada .
Dificultad de la cascada
La dificultad comienza con el hecho de que escribimos la línea, y aún es buena. Pero luego viene el negocio y dice que los precios se han duplicado, y multiplicamos por 2. En este punto, Jones Complexity se vuelve loco y dice que ahora la línea es demasiado complicada, hay demasiada lógica.
Bueno, comenzamos una nueva variable, y el analizador de complejidad de funciones dice:
-
No, eso no es así, ahora hay demasiadas variables dentro de la función.Haré un nuevo
método y le pasaré argumentos. Ahora, comprobar el número de argumentos de función, o el número de métodos dentro de la
clase, dice que esto también es imposible: la clase es demasiado compleja y debe dividirse en dos partes. Se estrelló al resaltar otra clase. Ahora hay más clases y todo está bien, pero al verificar la complejidad del
módulo se informa que el módulo ahora es demasiado complejo y necesita ser refactorizado. ¿Por qué?
Esto se llama sufrimiento. Por eso digo que una pelusa debería hacerte sufrir. Comenzamos multiplicando por 2 en una línea, y terminamos
refactorizando todo el sistema . Agregar un pequeño fragmento de código conduce a la refactorización de módulos completos, porque la complejidad se extiende como una cascada y cubre todo lo que es posible.
"Necesita refactorizar" : esto hace que refactorice el código. No puede simplemente sentarse: "No toco este código, parece funcionar". No, un día cambiará el código en otro lugar, y una cascada de complejidad inundará el módulo que no tocó y tendrá que refactorizarlo. Creo que la refactorización es buena, y cuanto más lo sea, más estable y mejor funcionará su sistema.
¡Y todo lo demás es subjetivo!Ahora hablemos de gustos. ¡Esta es una parte holística e interactiva!
Holivar
Apoyemos, los comentarios están abiertos. Primero, permíteme recordarte que los nombres son un problema complejo y no resuelto. Puede luchar sobre cómo nombrar una variable, pero tenemos algunos enfoques que ayudan al menos a no cometer errores obvios.
Nombres
¿Qué le parece:
var, value, item, obj, data, result ? ¿Qué son los
datos ? Algunos datos ¿Cuál es el
resultado ? Algún tipo de resultado. A menudo veo la variable
resultado y una llamada a algún método infernal en una clase incomprensible, y pienso: “¿Cuál es este resultado? ¿Por qué está él aquí?
Hay muchos desarrolladores que no están de acuerdo conmigo y dicen que el
valor es un nombre de variable perfectamente normal:
-
¡Siempre uso clave y valor!-
¿Por qué no usar clave y valor, pero decir que la clave es el nombre y el valor es el apellido? Por qué es imposible nombrar first_name y last_name, ahora hay un contexto.Generalmente la gente está de acuerdo, pero discuten de todos modos. Esto es algo muy holístico: al menos 3 personas pasaron una hora de su vida conmigo para discutir sobre esto conmigo.
¿Está bien nombrar variables con una letra?
Por ejemplo,
q ? Todos conocemos el caso clásico:
for i in some_iterable: Que es
yo En C, esta es una práctica estándar, y todo proviene de ella. Pero en Python, colecciones e iteradores. Las colecciones contienen elementos que tienen nombres, llamémoslos de alguna manera diferente.
La mitad de los desarrolladores piensan que llamar a las variables i, x, y, z es normal.
Creo que no puedes nombrar nombres con una letra. Quiero más contexto y es bueno que la segunda mitad de los desarrolladores estén de acuerdo conmigo. Si en C esto todavía está permitido de alguna manera debido al patrimonio histórico, entonces en Python este es un problema muy grande y no es necesario que lo haga.
Consistencia
Simplemente escojamos una salida de entre muchas y digamos: "Hagámoslo". Si es bueno o malo, ya no importa, es simplemente consistente.
Solo estamos hablando de Python 3, Legacy no se considera en absoluto.
Tengo un argumento: cuando heredamos de algo, deberíamos saber de qué: sería bueno ver el nombre del padre. Lo curioso es que generalmente vemos el nombre del padre, excepto cuando se trata de un
objeto . Por lo tanto, formulé una regla para mí: cuando escribo una clase, heredo de algo, siempre escribo el nombre del padre. No importa lo que será: modelo, objeto u otra cosa.
Si hay una opción para escribir
Class Some(object) o
class Some , entonces elegiré el primero. Por un lado, muestra que claramente siempre escribimos lo que heredamos. Por otro lado, no hay una particular
verbosidad en él : no perdemos nada de unas pocas pulsaciones de teclas adicionales.
Dos tercios de los desarrolladores están más familiarizados con la segunda opción, e incluso sé por qué. Mi hipótesis: todo porque hemos migrado durante mucho tiempo de la segunda versión de Python a la tercera, y ahora mostramos que estamos escribiendo en la tercera Python. No sé cómo es correcta la hipótesis, pero me parece que es así.
¿Las líneas F son terribles?
Opciones de respuesta:
- Sí: pierden contexto, ponen lógica en la plantilla y no dejan pelusa - (38%).
- No! Son un milagro! - (62%).
Existe la hipótesis de que las líneas f son terribles. ¡Empujan cualquier cosa en ellos! Las líneas f no son lo mismo que
.format , las diferencias son dramáticas. Cuando declaramos una plantilla y luego la formateamos, realizamos dos acciones por separado: primero definimos la plantilla y luego la formateamos. Cuando declaramos una línea f, realizamos dos acciones simultáneamente: declaramos inmediatamente la plantilla y la formateamos en el mismo momento.
Hay dos problemas con las líneas f. Declaramos una plantilla para la línea f y todo funciona. Y luego decidimos mover la plantilla 2 líneas hacia arriba o moverla a otra función, y todo se rompe.
Ahora no hay contexto que nos permita formatear cadenas , y no podemos procesarlas correctamente. El segundo gran problema con las líneas f: le permiten hacer lo terrible:
pegar la lógica en la plantilla . Supongamos que hay una línea en la que simplemente insertamos el nombre de usuario y la palabra "Hola", esto es normal. No hay nada particularmente terrible, pero luego vemos que el nombre de usuario viene en mayúsculas, decidimos traducirlo a un caso de Título y escribir directamente en la plantilla
username.title() . Luego, las condiciones, ciclos, importaciones aparecen en la plantilla. Y todas las otras partes de php.
Todos estos problemas me hacen decir que
las líneas f son un mal tema , no las usamos. Lo curioso es que no tenemos un caso en el que solo las líneas f sean adecuadas para nosotros. Por lo general, cualquier formato es adecuado, pero elegimos
.format , todo lo demás es imposible, ni
% ni líneas f. El trabajo de
.format también
.format incluido, porque dentro de él puedes poner comillas rizadas y escribir el nombre de la variable o su orden.
Durante el informe, el número de oponentes de la línea f aumentó del 33 al 38%; esta es una victoria pequeña pero pequeña.
Los numeros
¿Te gustan números como este:
final_score = 69 * previous result / 3.14 . Esto parece una línea de código estándar, pero ¿qué es 69? Tales preguntas a menudo surgen cuando miro el código que escribí hace algún tiempo, y el gerente en ese momento dice:
-
Multiplica por 147.-
¿Por qué a los 147?-
Tenemos tales aranceles.Me multipliqué y olvidé, o durante mucho tiempo recogí algún valor del coeficiente para que todo funcionara, y luego olvidé cómo lo recogí y por qué. Resulta que un importante trabajo de investigación permaneció oculto detrás de un número sin título. Ni siquiera sé cuál es este número, pero solo puedo encontrarlo, recuperarlo y restaurarlo de alguna manera comprometiéndome más tarde.
¿Por qué no hacerlo de manera diferente: coloque todos los números complejos en su propia variable con el nombre y la documentación? Por ejemplo, para el número 69, escriba que este es el indicador promedio en el mercado, y ahora la constante tiene un nombre y contexto. Escribiré un comentario de que tomé la constante en el sitio de dicho estudio. Si la investigación cambia en el futuro, vendré y actualizaré los datos.
Por lo tanto, garantizamos que ningún número mágico atravesará nuestro código y lo complicará desde adentro. Se abren paso verificando la complejidad de cada línea y dicen: "Aquí está el número 4766. ¡Qué es, no sé, resuélvelo tú mismo!" Este fue un gran descubrimiento para mí.
Como resultado, nos dimos cuenta de que debemos seguir esto, y no perdemos ningún número mágico en el código. Es bueno que casi el 100% de nuestros colegas estén de acuerdo con nosotros, y tampoco usan esos números.
Pero hay excepciones: estos son números del 10 al 10, números 100, 1000 y similares, simplemente porque a menudo se encuentran y sin ellos es difícil.
Somos duros, pero no sádicos y pensamos un poco.
¿Usas '@staticmethod'?
Pensemos en qué
es el método estático . ¿Alguna vez te has preguntado por qué está en Python? Yo no Tenía una hermosa Pylint que decía:
-
Mira, no estás usando self ,
cls - ¡
haz un método estático!-
De acuerdo, Pylint, haré un método estático.Luego enseñé Python a principiantes, y me preguntaron qué es el método estático y por qué es necesario. No sabía la respuesta y pensé si es posible escribir lo mismo con una función, o no usar
self en una función regular, simplemente porque es una clase así y algo está sucediendo. ¿Por qué necesitamos una construcción de método estático?
Busqué en Google la pregunta, y resultó ser tan profunda como una madriguera de conejo. Hay muchos otros lenguajes de programación en los que el método estático tampoco es del agrado. Y bien razonado: el método estático rompe el modelo de objetos. Como resultado, me di cuenta de que el
método estático no es el lugar aquí , y lo cortamos. Ahora, si usamos el decorador de métodos estáticos, la interfaz dirá: "No, lo siento, refactorizar".
La mayoría de los desarrolladores no están de acuerdo conmigo, pero aproximadamente la mitad todavía piensa que es mejor escribir métodos regulares o funciones regulares en lugar del método estático.
Lógica en __init __. Ru: ¿buena o mala?
Este es mi tema favorito. Seguramente, cuando crea un nuevo paquete y de alguna manera lo llama, crea __init __. Ru y se pregunta qué poner en él. ¿Qué poner en __init __. Ru, y qué - en archivos uno al lado del otro? Para mí, esta era una pregunta no trivial, y siempre estaba perdido: ¿probablemente algo más importante? Entonces pensé: no, por el contrario, pondré lo más importante en el contexto más comprensible. Si pone algo en __init __. Ru, y luego lo importa todo, resulta que las importaciones cíclicas también son malas.
Miré varias bibliotecas populares, subí su __init __. Ru, y noté que básicamente hay basura o compatibilidad con versiones anteriores. Para mí, esta pregunta surgió bruscamente cuando comencé a crear paquetes grandes con muchos subpaquetes: te pierdes. , . Python, , , __init__. , 90% .
— , API, , - , , ? , , . API . , __init__. - : , , .
,
I_CONTROL_CODE — . , . , , __init__. — . , , , - , .
hasattr ?
hasattr ? , , Python — . hasattr , ().
, , hasattr , , . , hasattr, , . - , Python -, hasattr . , .
getattr « , ». hasattr — getattr,
exception .
50 50 — , , .
,
layer-linter . ? : , , , . , - . - . .
cohesion . , . Cohesion , . False Positive , — , , .
vulture Python . - , Python , . ohesion.
Radon , :
Halstead ,
Maintainability Index , . , — .
Final type
Final- Python. Typing Extensions, , . , - , — , . , - - , ? No es necesario . - — , , , .
Gratis
, .

, .
, . , . , Python- , .
, Moscow Python Conf++ , . , , Python-.
. . , , , .