Probablemente, cualquier servicio que generalmente tiene una búsqueda, tarde o temprano, llega a la necesidad de aprender cómo corregir errores en las consultas de los usuarios. Errare humanum est; los usuarios están constantemente sellados y equivocados, y la calidad de la búsqueda inevitablemente se ve afectada por esto, y con ello la experiencia del usuario.
Además, cada servicio tiene sus propios detalles, su propio vocabulario, que debería ser capaz de operar el corrector tipográfico, lo que complica enormemente el uso de las soluciones existentes. Por ejemplo, tales solicitudes tuvieron que aprender a editar nuestro tutor:
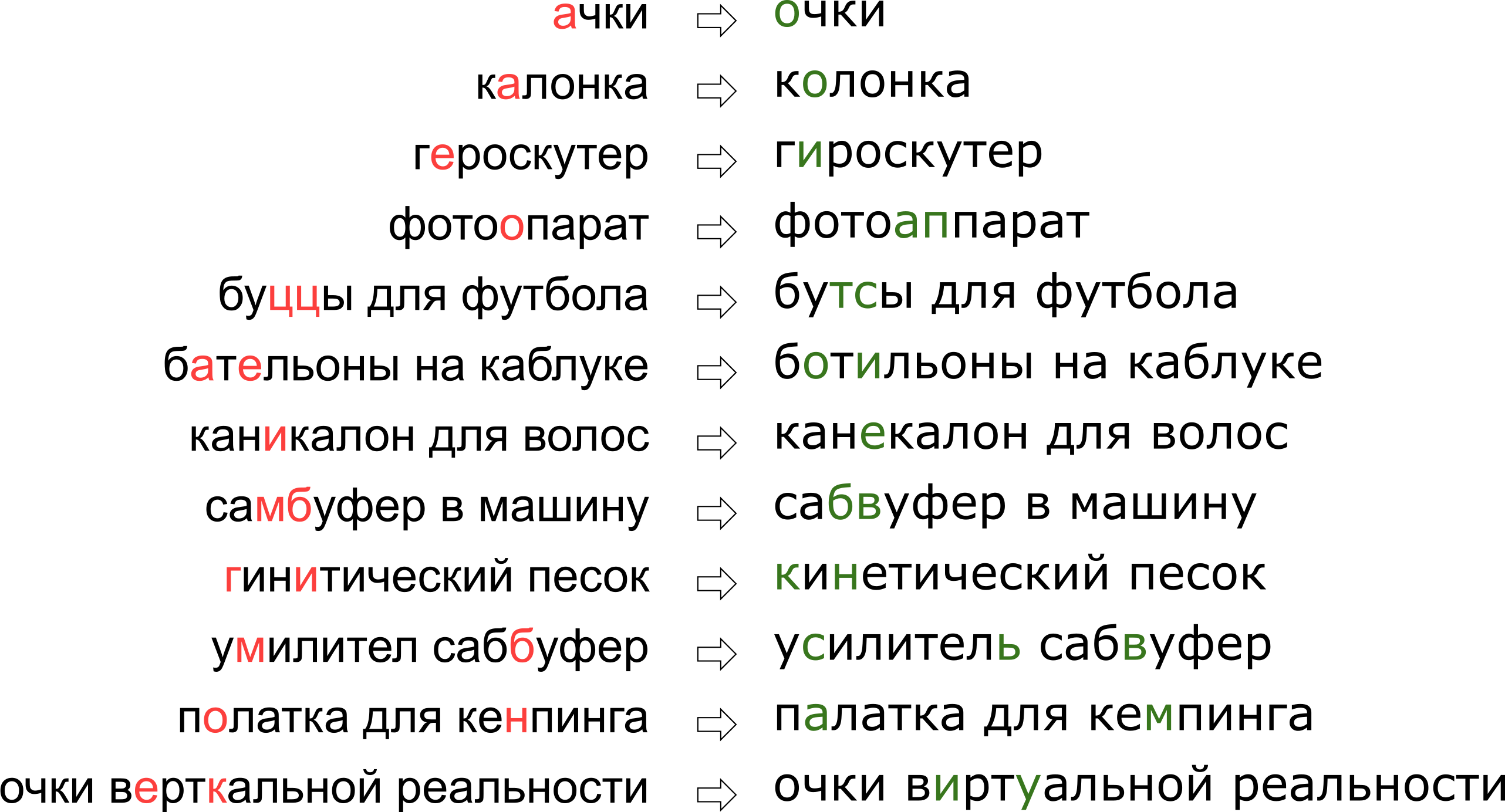 Puede parecer que le negamos al usuario su sueño de la realidad vertical, pero de hecho, la letra K simplemente se encuentra en el teclado junto a la letra U.
Puede parecer que le negamos al usuario su sueño de la realidad vertical, pero de hecho, la letra K simplemente se encuentra en el teclado junto a la letra U.En este artículo, analizaremos uno de los enfoques clásicos para la corrección de errores tipográficos, desde construir un modelo hasta escribir código en Python y Go. Y como beneficio adicional, un video de mi informe "
Gafas de realidad vertical": corregimos
errores tipográficos en las consultas de búsqueda "en Highload ++.
Declaración del problema.
Por lo tanto, recibimos una solicitud sellada y tenemos que solucionarla. Por lo general, el problema se plantea matemáticamente de la siguiente manera:
- dada la palabra s transmitido a nosotros con errores;
- tener un diccionario S i g m a las palabras correctas
- para todas las palabras w en el diccionario hay probabilidades condicionales P ( w | s ) que significaba la palabra w siempre que tengamos la palabra s ;
- necesitas encontrar la palabra w del diccionario con la máxima probabilidad P ( w | s ) .
Esta declaración, la más elemental, sugiere que si recibimos una solicitud de varias palabras, entonces corregimos cada palabra individualmente. En realidad, por supuesto, querremos corregir la frase completa como un todo, dada la compatibilidad de las palabras adyacentes; Hablaré de esto más adelante en la sección "Cómo corregir frases".
Hay dos momentos poco claros: dónde obtener el diccionario y cómo contar
P ( w | s ) . La primera pregunta se considera simple. En 1990 [1], el diccionario se compiló de la base de datos de la utilidad de
hechizos y de los diccionarios disponibles electrónicamente; en 2009, Google [4] lo hizo más fácil y simplemente tomó la parte superior de las palabras más populares en Internet (junto con errores ortográficos populares). Tomé este enfoque para construir mi tutor.
La segunda pregunta es más complicada. ¡Aunque solo sea porque su decisión generalmente comienza con la aplicación de la fórmula de Bayes!
P ( w | s ) = m a t h r m c o n s t c d o t P ( s | w ) c d o t P ( w )
Ahora, en lugar de la probabilidad incomprensible inicial, necesitamos evaluar dos nuevos, un poco más comprensibles:
P ( s | w ) - la probabilidad de que al escribir una palabra
w puede ser sellado y obtener
s y
P ( w ) - en principio, la probabilidad de que el usuario use la palabra
w .
Cómo calificar
P ( s | w ) ? Obviamente, es más probable que el usuario confunda A con O que b con S. Y si corregimos el texto reconocido del documento escaneado, entonces hay una alta probabilidad de confusión entre rn ym. De una forma u otra, necesitamos algún tipo de modelo que describa los errores y sus probabilidades.
Tal modelo se llama el modelo de canal ruidoso (el modelo de canal ruidoso; en nuestro caso, el canal ruidoso comienza en algún lugar en el
centro del Brock del usuario y termina en el otro lado de su teclado) o, más brevemente, el modelo de error es el modelo de error. Este modelo, que se analiza en una sección separada a continuación, será responsable de tener en cuenta los errores ortográficos y, de hecho, los errores tipográficos.
Califica la probabilidad de usar la palabra
P ( w ) - Es posible de diferentes maneras. La opción más simple es tomar la frecuencia con la que la palabra aparece en algunos corpus de textos grandes. Para nuestro tutor, teniendo en cuenta el contexto de la frase, por supuesto, se requiere algo más complicado: otro modelo. Este modelo se llama modelo de lenguaje, un modelo de lenguaje.
Modelo de error
Se consideraron los primeros modelos de error.
P ( s | w ) , contando las probabilidades de sustituciones elementales en el conjunto de entrenamiento: cuántas veces en lugar de E escribieron AND, cuántas veces en lugar de T escribieron T, en lugar de T - T, etc. [1]. El resultado fue un modelo con una pequeña cantidad de parámetros que podrían aprender algunos efectos locales (por ejemplo, que las personas a menudo confunden E e I).
En nuestra investigación, nos decidimos por un modelo de error más desarrollado propuesto en 2000 por Brill y Moore [2] y reutilizado más tarde (por ejemplo, por expertos de Google [4]). Imagine que los usuarios no piensan en caracteres separados (confunden E e I, presionan K en lugar de Y, omiten un signo suave), pero pueden cambiar partes arbitrarias de una palabra a otras, por ejemplo, reemplazar TSYA con TYSYA, Y con K, SHA con SHCHYA, SS a C y así sucesivamente. La probabilidad de que el usuario esté sellado y en lugar de que TSYA haya escrito THY, denotamos
P( textmil rightarrow textmil) Es un parámetro de nuestro modelo. Si para todos los fragmentos posibles
alpha, beta podemos contar
P( alpha rightarrow beta) , entonces la probabilidad deseada
P(s|w) Se puede obtener un conjunto de palabras s cuando se intenta escribir la palabra w en el modelo Brill and Moore de la siguiente manera: separamos las palabras wys en fragmentos más cortos de todas las formas posibles para que haya el mismo número de fragmentos en dos palabras. Para cada partición, calculamos el producto de las probabilidades de todos los fragmentos w para convertirlos en los fragmentos correspondientes s. El máximo para todas estas particiones se tomará como el valor de
P(s|w) :
P(s|w)= maxs= alpha1 alpha2 ldots alphak,w= beta1 beta2 ldots betakP( alpha1 rightarrow beta1) cdotP( alpha2 rightarrow beta2) cdot ldots cdotP( alphak rightarrow betak) ,.
Veamos un ejemplo de la partición que ocurre al calcular la probabilidad de imprimir "accesorio" en lugar de "accesorio":
\ begin {matrix} \ text {ak} & \ text {cec} & \ text {sou} & \ text {a} & \ text {p} \\ \ downarrow & \ downarrow & \ downarrow & \ downarrow & \ downarrow \\ \ text {a} & \ text {cc} & \ text {e} & \ text {soua} & \ text {p} \ end {matrix}
Como probablemente haya notado, este es un ejemplo de una partición no muy exitosa: está claro que partes de las palabras no se ubicaron entre sí tan exitosamente como pudieron. Si las cantidades
P( textak rightarrow texta) y
P( textp rightarrow textp) todavía no es tan malo entonces
P( textsou rightarrow texte) y
P( texta rightarrow textsoua) lo más probable es que hagan que la "puntuación" final de esta partición sea completamente triste. Una partición más exitosa se parece a esto:
\ begin {matrix} \ text {ak} & \ text {ce} & \ text {ss} & \ text {y} & \ text {ar} \\ \ downarrow & \ downarrow & \ downarrow & \ downarrow & \ downarrow \\ \ text {ak} & \ text {ce} & \ text {c} & \ text {y} & \ text {ar} \ end {matrix}
Aquí, todo encajó inmediatamente, y está claro que la probabilidad final estará determinada principalmente por el valor
P( textss rightarrow texts) .
Como calcular P(s|w)
A pesar del hecho de que hay órdenes de posibles particiones para dos palabras
O(2|s|+|w|) utilizando algoritmo de cálculo de programación dinámica
P(s|w) puede hacerse bastante rápido, por
O(|s|2|w|2) . El algoritmo en sí se parecerá mucho
al algoritmo de Wagner-Fisher para calcular la
distancia de Levenshtein .
Crearemos una tabla rectangular, cuyas filas corresponderán a las letras de la palabra correcta, y las columnas a la sellada. La celda en la intersección de la fila i y la columna j al final del algoritmo tendrá exactamente la probabilidad de obtener
s[:j] cuando intente imprimir
w[:i] . Para calcularlo, es suficiente calcular los valores de todas las celdas en las filas y columnas anteriores y repasarlas, multiplicando por el correspondiente
P( alpha rightarrow beta) . Por ejemplo, si tenemos una mesa llena
, luego para llenar la celda en la cuarta fila y la tercera columna (gris) debe tomar el máximo de
0.8 cdotP( textcc rightarrow textc) y
0.16 c d o t P ( t e x t c r i g h t a r r o w t e x t k ) . Al mismo tiempo, revisamos todas las celdas resaltadas en la imagen verde. Si también consideramos modificaciones del formulario
P( alpha rightarrow textlíneavacía) y
P( textlíneavacía rightarrow beta) , luego debe pasar por las celdas resaltadas en amarillo.
La complejidad de este algoritmo, como mencioné anteriormente, es
O(|s|2|w|2) : rellenamos la tabla
|s| times|w| , y para llenar la celda (i, j) necesitas
O(i cdotj) operaciones Sin embargo, si restringimos nuestra consideración a fragmentos de no más de una longitud limitada
L (por ejemplo, no más de dos letras, como en [4]), la complejidad disminuirá a
O(|s| cdot|w| cdotL2) . Para el idioma ruso en mis experimentos tomé
L=3 .
¿Cómo maximizar P(s|w)
Aprendimos a encontrar
P(s|w) para el tiempo polinomial es bueno. Pero necesitamos aprender a encontrar rápidamente las mejores palabras en todo el diccionario. Y los mejores no son
P(s|w) pero
P(w|s) ! De hecho, es suficiente para nosotros obtener algunas palabras superiores razonables (por ejemplo, las mejores 20) para
P(s|w) , que luego enviaremos al modelo de idioma para seleccionar las correcciones más apropiadas (más sobre esto a continuación).
Para aprender cómo revisar rápidamente todo el diccionario, observamos que la tabla presentada anteriormente tendrá mucho en común para dos palabras con prefijos comunes. De hecho, si nosotros, corrigiendo la palabra "accesorio", tratamos de completarlo con las dos palabras de vocabulario "accesorio" y "accesorios", ¡notaremos que las primeras nueve líneas en ellos no difieren en absoluto! Si podemos organizar un pase de diccionario para que las siguientes dos palabras tengan prefijos comunes lo suficientemente largos, podemos guardar muchos cálculos.
Y nosotros podemos. Tomemos las palabras del vocabulario y hagámoslas
trie . Al recorrerlo en profundidad, obtenemos la propiedad deseada: la mayoría de los pasos son pasos desde el nodo hasta su descendiente, cuando la tabla necesita completar las últimas filas.
Este algoritmo, con algunas optimizaciones adicionales, nos permite clasificar un diccionario de un idioma europeo típico en 50-100 mil palabras en cien milisegundos [2]. Y el almacenamiento en caché de los resultados hará que el proceso sea aún más rápido.
Como llegar P( alpha rightarrow beta)
Calculo
P( alpha rightarrow beta) para todos los fragmentos bajo consideración, la parte más interesante y no trivial de construir un modelo de error. De estas cantidades dependerá su calidad.
El enfoque utilizado en [2, 4] es relativamente simple. Encontremos muchas parejas
(si,wi) donde
wi Es la palabra correcta del diccionario, y
si - Su versión sellada. (Cómo encontrarlos exactamente es un poco más bajo). Ahora necesitamos extraer de estos pares las probabilidades de errores tipográficos específicos (reemplazando un fragmento por otro).
Para cada par tomamos sus componentes
w y
s y construir una correspondencia entre sus letras, minimizando la distancia de Levenshtein:
\ begin {matrix} \ text {} & \ text {} & \ text {} & \ text {} & \ text {} & \ text {} & \ text {} & \ text {a} & \ text {p} \\ \ text {a} & \ text {k} & \ text {c} & \ text {e} & \ text {c} & \ text {} & \ text {y } & \ text {a} & \ text {p} \ end {matrix}
Ahora vemos inmediatamente las sustituciones: a → a, e → y, c → c, c → una cadena vacía y así sucesivamente. También vemos reemplazos de dos o más caracteres: ak → ak, ce → si, ec → is, ss → s, ses → sis, ess → is y otros, y así sucesivamente. Todos estos reemplazos deben contarse, y cada uno tantas veces como aparece la palabra s en el corpus (si tomamos las palabras del corpus, lo cual es muy probable).
Después de pasar en todos los pares
(si,wi) por probabilidad
P( alpha rightarrow beta) se acepta el número de sustituciones α → β que ocurrieron en nuestros pares (teniendo en cuenta la aparición de las palabras correspondientes) dividido por el número de repeticiones del fragmento α.
¿Cómo encontrar parejas
(si,wi) ? En [4], se propuso este enfoque. Tome el gran cuerpo de contenido generado por el usuario (UGC). En el caso de Google, eran solo los textos de cientos de millones de páginas web; La nuestra tiene millones de búsquedas y reseñas de usuarios. Se supone que, por lo general, la palabra correcta se encuentra en el corpus con más frecuencia que cualquiera de las variantes erróneas. Entonces, busquemos palabras para cada palabra cercana de Levenshtein del corpus, que son mucho menos populares (por ejemplo, diez veces). Tomar popular
w , menos popular - para
s . Así que tenemos un par de pares ruidosos, pero bastante grandes para entrenar.
Este algoritmo de emparejamiento de pares deja mucho margen de mejora. En [4], solo un filtro por ocurrencia (
w diez veces más popular que
s ), pero los autores de este artículo están tratando de hacer chismes, sin utilizar ningún conocimiento a priori del idioma. Si consideramos solo el idioma ruso, podemos, por ejemplo, tomar un
conjunto de diccionarios de formas de palabras rusas y dejar solo pares con la palabra
w encontrado en el diccionario (no es una buena idea, porque el diccionario probablemente no tendrá vocabulario específico para el servicio) o, por el contrario, descarte los pares con la palabra s que se encuentra en el diccionario (es decir, es casi seguro que no se sellará).
Para mejorar la calidad de los pares recibidos, escribí una función simple que determina si los usuarios usan dos palabras como sinónimos. La lógica es simple: si las palabras w y s a menudo se encuentran rodeadas de las mismas palabras, entonces probablemente sean sinónimos, lo que, a la luz de su cercanía según Levenshtein, significa que una palabra menos popular es probablemente una versión errónea de una más popular. Para estos cálculos, utilicé las estadísticas de la aparición de trigramas (frases de tres palabras) creadas para el modelo de lenguaje a continuación.
Modelo de idioma
Entonces, ahora para una palabra de diccionario dada w, necesitamos calcular
P(w) - la probabilidad de su uso por parte del usuario. La solución más simple es tomar la aparición de una palabra en algún tipo de caso grande. En general, probablemente, cualquier modelo de lenguaje comienza con la recopilación de un gran corpus de textos y contando la aparición de palabras en él. Pero no debemos limitarnos a esto: de hecho, al calcular P (w), también podemos tener en cuenta la frase en la que intentamos corregir la palabra y cualquier otro contexto externo. La tarea se convierte en una tarea de cálculo.
P(w1w2 ldotswk) donde uno de
wi - la palabra en la que corregimos el error tipográfico y para el que ahora estamos contando
P(w) y el resto
wi - Las palabras que rodean la palabra corregida en la solicitud del usuario.
Para aprender a tenerlos en cuenta, vale la pena revisar el corpus nuevamente y compilar estadísticas de n-gramos, secuencias de palabras. Suelen tomar secuencias de longitud limitada; Me limité a los trigramas para no inflar el índice, pero todo depende de su fortaleza mental (y del tamaño del caso; en un caso pequeño, incluso las estadísticas sobre los trigramas serán demasiado ruidosas).
El modelo de lenguaje tradicional de n-gramas se ve así. Por la frase
w1w2 ldotswk su probabilidad se calcula mediante la fórmula
P(w1w2 ldotswk)=P(w1) cdotP(w2|w1) cdotP(w3|w1w2)P(wk|w1w2wk−1) ,,
donde
P(w1) - directamente la frecuencia de la palabra, y
P(w3|w1w2) - probabilidad de palabra
w3 siempre que antes de irse
w1w2 - nada más que la relación de la frecuencia de trigrama
w1w2w3 a la frecuencia bigram
w1w2 . (Tenga en cuenta que esta fórmula es simplemente el resultado del uso repetido de la fórmula de Bayes).
En otras palabras, si queremos calcular
P( textmarcodejabóndemamá) , que denota la frecuencia de un n-gram arbitrario en
f obtenemos la fórmula
P( textmamájabonmarco)=f( textmamá) cdot fracf( textmamájabón)f( textmamá) cdot fracf( textmarcodejabóndemamá)f( textjabóndemamá)=f( textmarcodejabóndemamá).$
¿Es lógico? Es lógico. Sin embargo, las dificultades comienzan cuando las frases se hacen más largas. ¿Qué sucede si un usuario ingresó una consulta de búsqueda de diez palabras con detalles impresionantes? No queremos mantener estadísticas para todos los 10 gramos; esto es costoso y es probable que los datos sean ruidosos y no indicativos. Queremos salir adelante con n-gramos de cierta longitud limitada, por ejemplo, la longitud 3 ya propuesta anteriormente.
Aquí es donde la fórmula anterior es útil. Supongamos que la probabilidad de que aparezca una palabra al final de una frase se ve significativamente afectada solo por unas pocas palabras inmediatamente delante de ella, es decir,
P(wk|w1w2 ldotswk−1) aprox.P(wk|wk−L+1 ldotswk−1).$
Poner
L=3 , para una frase más larga obtenemos la fórmula
P( textcarlrobócoralesdeClara) aproxf( textcarl) cdot fracf( textcarl)f( textcarl) cdot fracf( textcarlfromclara)f( textcarlfrom) cdot fracf( textstolefromclara)f( textfromclara) cdot fracf( textclairestolecoral)f( textclairestole).$Nota: la frase consta de cinco palabras, pero en la fórmula aparecen n-gramos de no más de tres. Esto es exactamente lo que buscamos.
Quedaba un breve momento. ¿Qué pasa si el usuario ingresó una frase muy extraña y los n-gramas correspondientes en nuestras estadísticas y nada en absoluto? Sería fácil para n-gramos desconocidos poner
f=0 si no fuera necesario dividir por este valor. Aquí viene la ayuda de suavizado (suavizado), que se puede hacer de diferentes maneras; sin embargo, una discusión detallada de los enfoques serios de anti-aliasing como el suavizado de
Kneser-Ney está más allá del alcance de este artículo.
Cómo corregir frases
Discutimos el último punto sutil antes de pasar a la implementación. El enunciado del problema que describí anteriormente implicaba que hay una palabra y que debe corregirse. Luego aclaramos que esta palabra puede estar en el medio de una frase entre otras palabras y también deben tenerse en cuenta, eligiendo la mejor corrección. Pero en realidad, los usuarios simplemente nos envían frases sin especificar qué palabra se deletrea; a menudo algunas palabras o incluso todas necesitan ser corregidas.
Puede haber muchos enfoques. Por ejemplo, puede tener en cuenta solo el contexto izquierdo de la palabra en la frase. Luego, siguiendo las palabras de izquierda a derecha y corrigiéndolas según sea necesario, obtendremos una nueva frase de cierta calidad. La calidad será pobre si, por ejemplo, la primera palabra resulta ser como varias palabras populares y elegimos la opción incorrecta. Ajustamos toda la frase restante (posiblemente inicialmente completamente libre de errores) a la primera palabra incorrecta y podemos obtener el texto que es completamente irrelevante para el original.
Puede considerar las palabras individualmente y aplicar un determinado clasificador para comprender si la palabra dada está sellada o no, como se sugiere en [4]. El clasificador está capacitado en las probabilidades que ya sabemos contar y en una serie de otras características. Si el clasificador dice lo que necesita ser reparado, lo estamos corrigiendo, dado el contexto existente. Nuevamente, si varias palabras se escriben incorrectamente, deberá tomar una decisión sobre la primera de ellas en función del contexto con los errores, lo que puede conducir a problemas de calidad.
En la implementación de nuestro tutor, utilizamos este enfoque. Vamos por cada palabra
si En nuestra frase, usando el modelo de error, encontramos las palabras del diccionario N-top que podrían significar, las concatenamos en frases de todas las formas posibles y para cada uno de
NK frases resultantes donde
K - la cantidad de palabras en la frase original, honestamente calcule el valor
P(s1|w1) cdotP(sK|wK) cdotP(sK|wK) cdotP(w1w2 ldotswK) lambda.$
Aqui
si - palabras introducidas por el usuario,
wi - correcciones seleccionadas para ellos (que ahora estamos clasificando), y
lambda - coeficiente determinado por la calidad comparativa del modelo de error y el modelo de lenguaje (coeficiente grande - confiamos más en el modelo de lenguaje, coeficiente pequeño - confiamos más en el modelo de error), propuesto en [4]. En total, para cada frase, multiplicamos las probabilidades de que las palabras individuales se corrijan en las variantes de diccionario correspondientes, y también multiplicamos esto por la probabilidad de la frase completa en nuestro idioma. El resultado del algoritmo es una frase de las palabras del diccionario que maximiza este valor.
¿Entonces para qué? Fuerza bruta
NK frases?
Afortunadamente, debido al hecho de que hemos limitado la longitud de n-gramos, es posible encontrar un máximo en todas las frases mucho más rápido. Recuerde: arriba simplificamos la fórmula para
P(w1w2 ldotswK) de modo que comenzó a depender solo de frecuencias de n-gramos de longitud no superior a tres:
P(w1w2 ldotswK)=P(w1) cdotP(w2|w1) cdotP(w3|w1w2) cdot ldots cdotP(wK|wK−2wK−1).$
Si multiplicamos este valor por
P(si|wi) e intentar maximizar
wK , veremos que es suficiente resolver todo tipo de
wK−2 y
wK−1 y resolver el problema para ellos, es decir, para frases
w1w2 ldotswK−2wK−1 . En total, el problema se resuelve mediante programación dinámica en
O(KN3) .
Implementación
Armar el estuche y contar n-gramos
Haré una reserva de inmediato: no había tantos datos a mi disposición para iniciar un MapReduce complejo. Así que acabo de recopilar todos los textos de revisiones, comentarios y consultas de búsqueda en ruso (las descripciones de los productos, por desgracia, vienen en inglés, y el uso de los resultados de la traducción automática empeoró en lugar de mejorar los resultados) de nuestro servicio en un archivo de texto y configuré el servidor para que la noche cuente trigramas con un simple script de Python.
Como diccionario, tomé las principales palabras en frecuencia para obtener alrededor de cien mil palabras. Se excluyeron palabras demasiado largas (más de 20 caracteres) y demasiado cortas (menos de tres caracteres, excepto palabras rusas bien conocidas y codificadas). Por separado ahorró las palabras en la regularidad
r"^[a-z0-9]{2}$" - para que las versiones de iPhones y otros identificadores interesantes de longitud 2 sobrevivieran.
Al contar bigramas y trigramas en una frase, puede aparecer una palabra que no sea de diccionario. En este caso, descarté esta palabra y batí la frase completa en dos partes (antes y después de esta palabra), con las que trabajé por separado. Entonces, para la frase "
¿Sabes qué es" abyrvalg "? Esto es ... EL CABEZAL, colega "tendrá en cuenta los trigramas" Sabes "," sabes qué "," sabe qué es "y" este es el colega jefe de pescadores "(a menos que, por supuesto, la palabra" jefe "caiga en el diccionario ...).
Entrenamos el modelo de error
Además realicé todo el procesamiento de datos en Jupyter. Las estadísticas sobre n-gramas se cargan desde JSON, el procesamiento posterior se realiza para encontrar rápidamente palabras cercanas entre sí según Levenshtein, y para los pares en el bucle, se llama a una función (bastante engorrosa) que organiza palabras y extrae ediciones cortas de la forma ss → c (debajo del spoiler).
Código de Python def generate_modifications(intended_word, misspelled_word, max_l=2):
El cálculo de las ediciones en sí parece elemental, aunque puede llevar mucho tiempo.
Aplicar modelo de error
Esta parte se implementa como un micro servicio en Go, conectado con el backend principal a través de gRPC. Se implementó el algoritmo descrito por Brill y Moore [2], con optimizaciones menores. Como resultado, funciona para mí, aproximadamente el doble de lento que los autores afirmaron; No pretendo juzgar si está en Go o en mí. Pero en el curso de la elaboración de perfiles, aprendí un poco sobre Go.
- No use
math.Max para contar el máximo. ¡Esto es aproximadamente tres veces más lento que if a > b { b = a } ! Solo mire la implementación de esta función :
A menos que de repente necesite que +0 sea necesariamente mayor que -0, no use math.Max .
- No use una tabla hash si puede usar una matriz. Esto, por supuesto, es un consejo bastante obvio. Tuve que renumerar los caracteres Unicode en números al comienzo del programa para usarlos como índices en la matriz de descendientes del nodo trie (tal búsqueda era una operación muy común).
- Las devoluciones de llamada en Go no son baratas. Durante la refactorización durante la revisión del código, algunos de mis intentos de desacoplar desaceleraron significativamente el programa a pesar del hecho de que el algoritmo no cambió formalmente. Desde entonces, he opinado que el compilador de optimización Go tiene espacio para crecer.
Aplicar un modelo de lenguaje
Aquí, sin sorpresas, se implementó el algoritmo de programación dinámica descrito en la sección anterior. Este componente tuvo el menor trabajo: la parte más lenta es la aplicación del modelo de error.
Por lo tanto, entre estas dos capas, el almacenamiento en caché de los resultados del modelo de error en Redis también fue atornillado.Resultados
Con base en los resultados de este trabajo (que tomó aproximadamente un mes), realizamos una prueba de protección A / B en nuestros usuarios. En lugar del 10% de los resultados de búsqueda vacíos entre todas las consultas de búsqueda que teníamos antes de la introducción del tutor, había un 5% de ellas; Básicamente, las solicitudes restantes son para productos que simplemente no tenemos en la plataforma. El número de sesiones sin una segunda consulta de búsqueda también ha aumentado (y varias métricas más de este tipo relacionadas con UX). Sin embargo, las métricas relacionadas con el dinero no cambiaron significativamente; esto fue inesperado y nos llevó a un análisis exhaustivo y una verificación cruzada de otras métricas.Conclusión
A Stephen Hawking le dijeron una vez que cada fórmula que incluía en el libro reduciría a la mitad el número de lectores. Bueno, en este artículo hay unos cincuenta, los felicito, uno de los10−10 ¡Lectores que llegan a este lugar!Bono
Referencias
[1] MD Kernighan, Iglesia KW, WA Gale. Un programa de corrección ortográfica basado en un modelo de canal ruidoso . Actas de la 13ª conferencia sobre lingüística computacional - Volumen 2, 1990.[2] E.Brill, RC Moore. Un modelo de error mejorado para la corrección ortográfica del canal ruidoso . Actas de la 38ª Reunión Anual sobre la Asociación de Lingüística Computacional, 2000.[3] T. Brants, AC Popat, P. Xu, FJ Och, J. Dean. Grandes modelos de lenguaje en la traducción automática . Actas de la Conferencia de 2007 sobre métodos empíricos en el procesamiento del lenguaje natural.[4] C. Whitelaw, B. Hutchinson, GY Chung, G. Ellis. Uso de la Web para el corrector ortográfico y la corrección automática del lenguaje. Actas de la Conferencia de 2009 sobre métodos empíricos en el procesamiento del lenguaje natural: Volumen 2.