Cabe señalar de inmediato que este artículo es solo una reflexión subjetiva sobre cómo puede verse e implementarse el comportamiento de los elementos de la interfaz que saben lo que está haciendo el usuario en un momento particular. Sin embargo, los pensamientos están respaldados por un poco de investigación e implementación. Vamos
En los albores de Internet, los sitios no buscaban individualidad al diseñar elementos de interfaz básicos. La variabilidad era pequeña, por lo que las páginas eran bastante uniformes en sus componentes.
Cada enlace parecía un enlace, un botón como un botón y una casilla de verificación como una casilla de verificación. El usuario sabía a qué conduciría su acción, porque tenía una idea clara del principio de funcionamiento de cada elemento.
El enlace debe enviarse a otra página, sin importar de dónde provenga, desde el menú de navegación o desde el texto en la descripción. El botón cambiará el contenido de la página actual, posiblemente enviando una solicitud al servidor. El estado de la casilla de verificación, muy probablemente, no afectará el contenido de ninguna manera, hasta que presionemos el botón para alguna acción que use este estado. Por lo tanto, fue suficiente que el usuario mirara el elemento de la interfaz para comprender con un alto grado de probabilidad cómo interactuar con él y a qué conduciría.
Los sitios modernos proporcionan al usuario una cantidad mucho mayor de rompecabezas. Todos los enlaces se ven completamente diferentes, los botones no se ven como botones, etc. Para comprender si una línea es un enlace, el usuario debe pasar el cursor sobre ella para ver el cambio de color a uno más contrastante. Para entender si un elemento es un botón, también colocamos el mouse para ver el cambio en el tono de relleno. Con los elementos de varios menús, todo también es complicado, algunos de ellos probablemente ampliarán un submenú adicional y otros no, aunque externamente son idénticos.
Sin embargo, nos acostumbramos rápidamente a las interfaces que usamos regularmente y ya no estamos confundidos en la funcionalidad de los elementos. La continuidad general de las interfaces juega un papel importante. Mirando la página de arriba, lo más probable es que nos demos cuenta de inmediato de que la flecha amarilla con las palabras "Buscar" no es solo un elemento decorativo, sino un botón, aunque en absoluto se parece a un botón HTML estándar. Entonces, en términos de previsibilidad y personalidad, la mayoría de los recursos han llegado a un consenso estable aceptado por los usuarios.
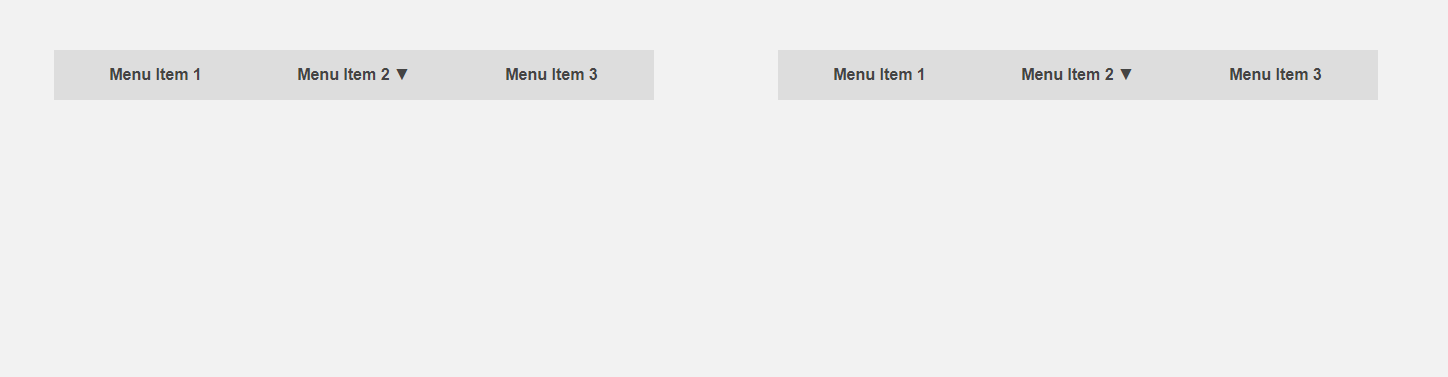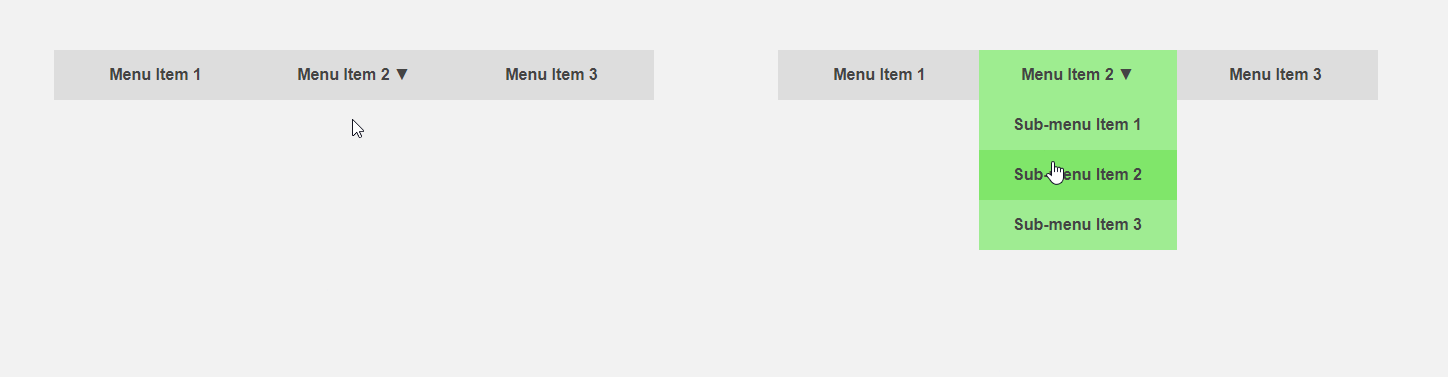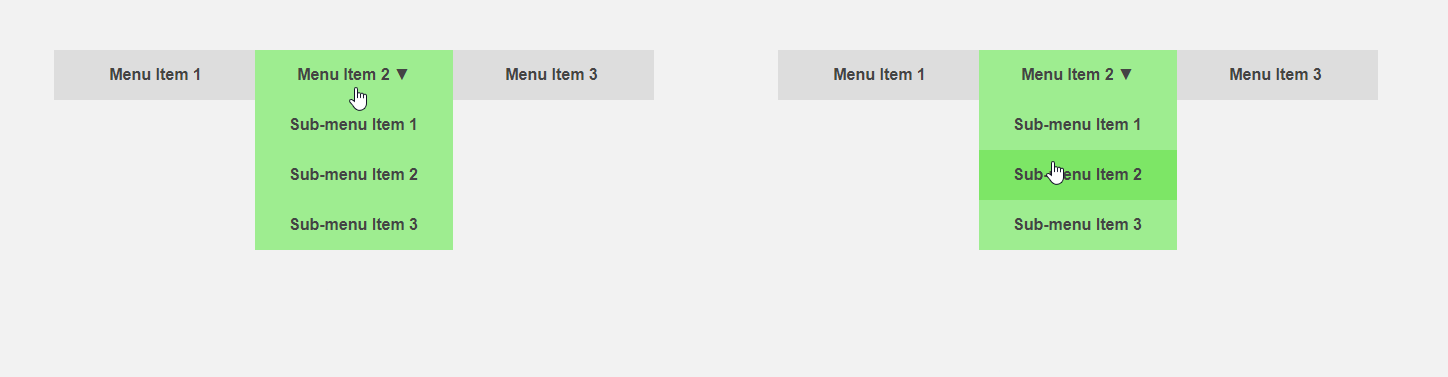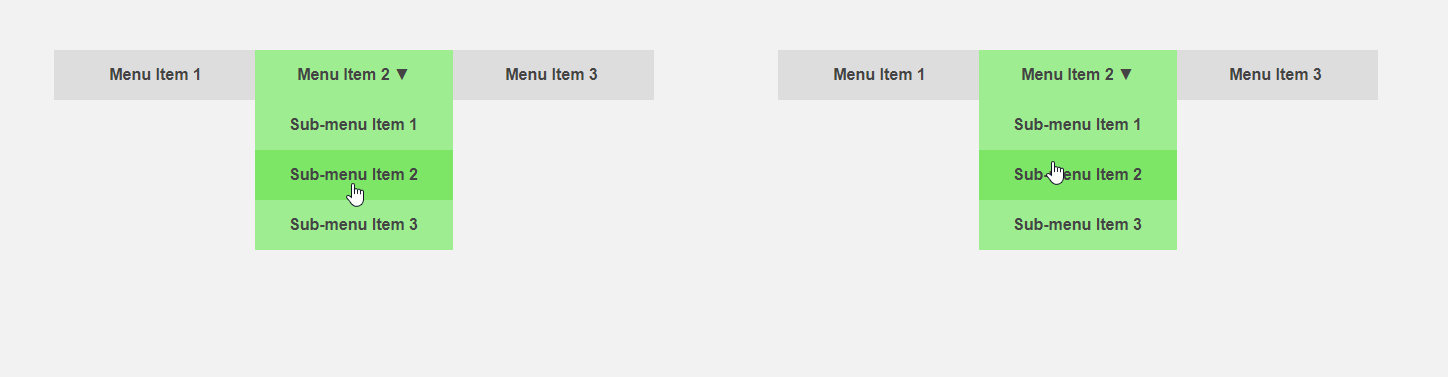
Por otro lado, sería interesante obtener una interfaz que le diga al usuario de antemano acerca de los detalles de un elemento o que haga parte del trabajo de rutina para él. El cursor se mueve hacia el elemento del menú: puede expandir el submenú de antemano, acelerando así la interacción con la interfaz, el usuario mueve el cursor al botón; puede cargar contenido adicional que se requiere solo después de hacer clic. El encabezado del artículo compara la interfaz estándar (izquierda) y la predictiva.
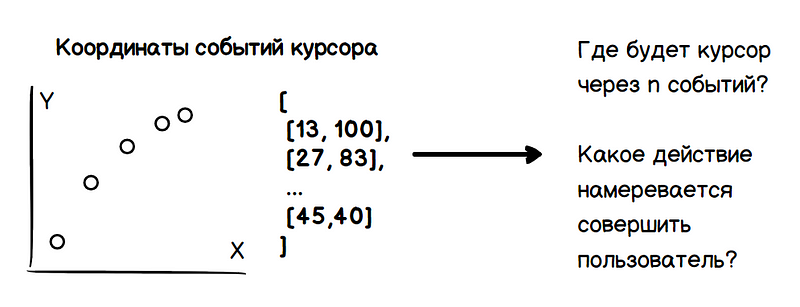
Una simple prueba visual muestra que al analizar la velocidad del cursor y sus derivadas, es posible predecir la dirección del movimiento y las coordenadas de la parada en un cierto número de pasos. Dado que los eventos de movimiento se activan con una frecuencia constante en relación con la magnitud de la aceleración, la velocidad disminuye al acercarse al objetivo. Por lo tanto, puede averiguar la acción planificada por el usuario con anticipación, lo que conduce a los beneficios ya anunciados.

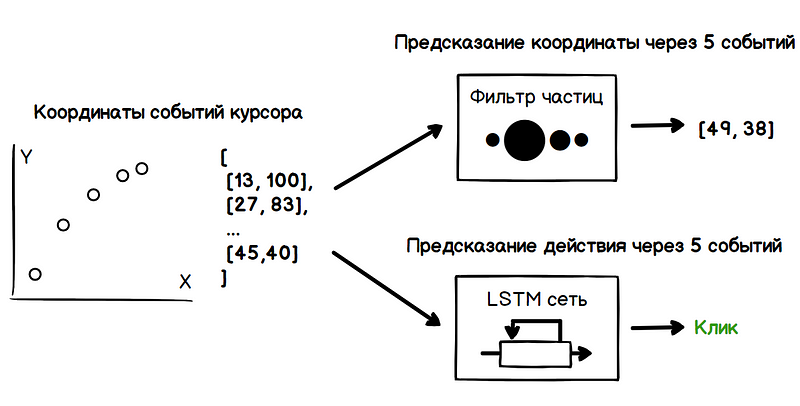
Por lo tanto, el problema incluye dos tareas: determinar las coordenadas futuras del cursor y determinar las intenciones del usuario (desplazarse, hacer clic, resaltar, etc.). Todos estos datos deben obtenerse solo sobre la base del análisis de los valores anteriores de las coordenadas del cursor.
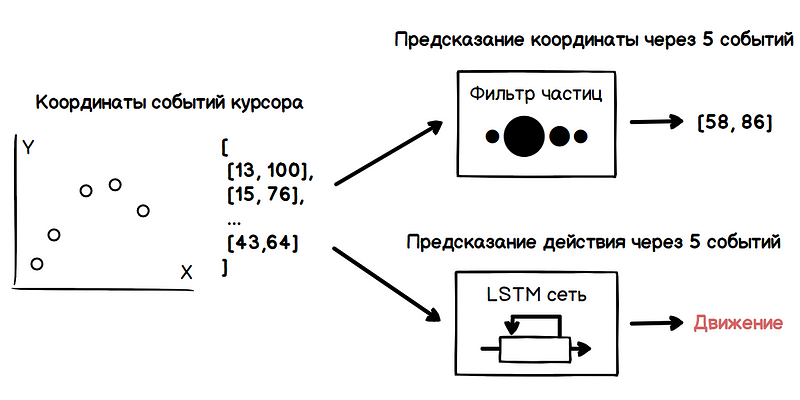
La tarea principal es evaluar la dirección del movimiento del cursor en lugar de predecir el momento de detención, que es un problema más complejo. Como una estimación de los parámetros de una cantidad ruidosa, el problema de calcular la dirección del movimiento puede resolverse mediante una masa de métodos conocidos.
La primera opción que viene a la mente es un filtro de
media móvil . Promediando la velocidad en momentos anteriores, puede obtener su valor en lo siguiente. Los valores anteriores se pueden ponderar de acuerdo con una determinada ley (lineal, exponencial, exponencial) para mejorar la influencia de los estados más cercanos, reduciendo la contribución de valores más distantes.
Otra opción es usar un algoritmo recursivo, como
un filtro de partículas . Para evaluar la velocidad del cursor, el filtro crea muchas hipótesis sobre el valor actual de la velocidad, también llamadas partículas. En el momento inicial, estas hipótesis son absolutamente aleatorias, pero más adelante, el filtro elimina las hipótesis inválidas y periódicamente en la etapa de redistribución genera nuevas basadas en las confiables. Por lo tanto, a partir del conjunto de hipótesis como resultado, solo quedan los más cercanos al verdadero valor de la velocidad.
En el siguiente ejemplo, al mover el cursor de cada partícula para visualización, el valor del radio es directamente proporcional a su peso. Por lo tanto, la región con la mayor concentración de partículas pesadas caracteriza la dirección más probable del movimiento del cursor.
Sin embargo, la dirección de movimiento obtenida no es suficiente para determinar las intenciones del usuario. Con una alta densidad de elementos de interfaz, la ruta del cursor puede estar sobre muchos de ellos, lo que conducirá a una masa de falsos positivos del algoritmo de predicción. Aquí los métodos de aprendizaje automático vienen al rescate, a saber, las redes neuronales recurrentes.
Las coordenadas del cursor son una secuencia de valores fuertemente correlacionados. Cuando el movimiento se ralentiza, la diferencia entre las coordenadas de las posiciones vecinas en la línea de tiempo disminuye de un evento a otro. La tendencia inversa es notable al comienzo del movimiento: los intervalos de coordenadas aumentan. Probablemente, con una precisión aceptable, este problema también puede resolverse analíticamente examinando los valores de las derivadas en diferentes partes de la ruta y codificando el umbral de respuesta en función del comportamiento de estos valores. Pero por su naturaleza, la secuencia de coordenadas de las posiciones del cursor parece un conjunto de datos que se ajusta bien con los principios de funcionamiento de las redes de memoria a corto plazo a largo plazo.
Las redes
LSTM son un tipo específico de arquitectura de redes neuronales recurrentes, adaptadas para el entrenamiento de dependencias a largo plazo. Esto se ve facilitado por la capacidad de almacenar información de los módulos de red en varios estados. Por lo tanto, la red puede detectar signos basados, por ejemplo, en cuánto tiempo se desaceleró el cursor, qué lo precedió, cómo cambió la velocidad del cursor al comienzo de la desaceleración, etc. Estos signos caracterizan patrones específicos de comportamiento del usuario durante ciertas acciones, por ejemplo, al hacer clic en un botón.
Por lo tanto, al analizar continuamente los datos obtenidos a la salida del filtro de partículas y la red neuronal, obtenemos un momento en el que, por ejemplo, puede mostrar un menú desplegable, mientras el usuario mueve el cursor hacia él para abrirlo en el siguiente segundo. Al realizar este análisis para cada evento del mouse, es difícil perderse el momento correcto.
El entrenamiento de la red LSTM se puede llevar a cabo en un conjunto de datos obtenido en el proceso de análisis del comportamiento del usuario, realizando una serie de tareas diseñadas para identificar sus características al interactuar con la interfaz: haga clic en un botón, mueva el cursor sobre un enlace, abra el menú, etc. El siguiente es un ejemplo de activación de una matriz de elementos predictivos basada solo en un filtro de partículas, sin análisis de redes neuronales.

Las animaciones a continuación demuestran la contribución de la red neuronal al proceso de predicción del comportamiento del usuario. Los falsos positivos se vuelven mucho menos.

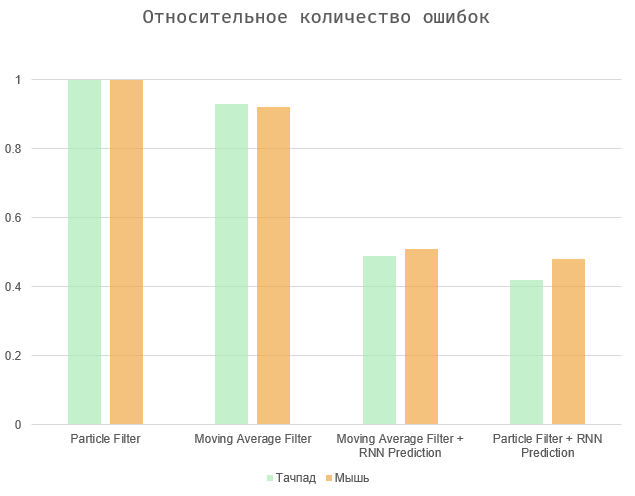
En general, la tarea se reduce a un equilibrio entre dos cantidades: el período de tiempo entre la acción y su predicción y el número de errores (falsos positivos y omisiones). Dos casos extremos son seleccionar todos los elementos en la página (el período de predicción máximo, una gran cantidad de errores), o hacer que el algoritmo funcione inmediatamente cuando el usuario actúa (período de predicción cero y errores faltantes).
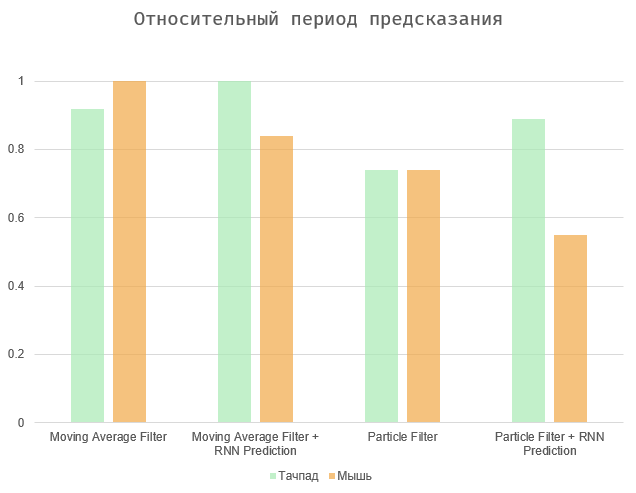
Los diagramas muestran los resultados normalizados a valores máximos, ya que la velocidad del usuario es puramente individual, y la cantidad de errores depende de la interfaz en cuestión. La media móvil y los algoritmos de filtro de partículas muestran resultados más o menos similares. El segundo es un poco más preciso, especialmente en el caso de usar el panel táctil. En última instancia, todas estas opciones pueden depender en gran medida del usuario y dispositivo específicos.
En conclusión, una pequeña demostración del comportamiento predictivo de los elementos HTML, lejos de ser ideal, pero un poco revelador.
Por supuesto, en tales tareas es fundamental lograr un equilibrio entre funcionalidad y previsibilidad. Si el comportamiento resultante no es claro para el usuario, la irritación causada anulará todos los esfuerzos. Es difícil hablar sobre si es posible hacer que el proceso de aprendizaje del algoritmo sea invisible para el usuario, por ejemplo, en las primeras sesiones de su comunicación con la interfaz de la página, de modo que, utilizando los algoritmos entrenados, los elementos de la interfaz se comporten de manera predictiva. En cualquier caso, será necesaria capacitación adicional debido a las características individuales de cada persona y este es el tema de una investigación adicional.