Buenas tardes
Desde nuestro curso
"C ++ Developer" le ofrecemos un pequeño e interesante estudio sobre algoritmos paralelos.
Vamos
Con la llegada de los algoritmos paralelos en C ++ 17, puede actualizar fácilmente su código de "computación" y beneficiarse de la ejecución paralela. En este artículo, quiero considerar el algoritmo STL, que naturalmente revela la idea de la informática independiente. ¿Podemos esperar una aceleración 10x con un procesador de 10 núcleos? O tal vez más? O menos? Hablemos de eso.
Introducción a los algoritmos paralelos
C ++ 17 ofrece una configuración de política de ejecución para la mayoría de los algoritmos:
- sequenced_policy - tipo de política de ejecución, utilizada como un tipo único para eliminar la sobrecarga del algoritmo paralelo y el requisito de que la paralelización de la ejecución del algoritmo paralelo sea imposible: el objeto global correspondiente es
std::execution::seq ; - paralelo_política: tipo de política de ejecución utilizada como un tipo único para eliminar la sobrecarga del algoritmo paralelo e indicar que es posible la paralelización de la ejecución del algoritmo paralelo: el objeto global correspondiente es
std::execution::par ; - parallel_unsequenced_policy: un tipo de política de ejecución utilizada como un tipo único para eliminar la sobrecarga del algoritmo paralelo e indicar que la paralelización y la vectorización de la ejecución del algoritmo paralelo son posibles: el objeto global correspondiente es
std::execution::par_unseq ;
Brevemente:
- use
std::execution::seq para la ejecución secuencial del algoritmo; - use
std::execution::par execute std::execution::par para ejecutar el algoritmo en paralelo (generalmente usando alguna implementación de Thread Pool (grupo de hilos)); - use
std::execution::par_unseq para la ejecución paralela del algoritmo con la capacidad de usar comandos vectoriales (por ejemplo, SSE, AVX).
Como ejemplo rápido, llame a
std::sort en paralelo:
std::sort(std::execution::par, myVec.begin(), myVec.end());
¡Tenga en cuenta lo fácil que es agregar un parámetro de ejecución paralela al algoritmo! ¿Pero se logrará una mejora significativa en el rendimiento? ¿Aumentará la velocidad? ¿O hay alguna desaceleración?
Paralelo std::transformEn este artículo, quiero prestar atención al algoritmo
std::transform , que podría ser la base de otros métodos paralelos (junto con
std::transform_reduce ,
for_each ,
scan ,
sort ...).
Nuestro código de prueba se construirá de acuerdo con la siguiente plantilla:
std::transform(execution_policy,
Suponga que la función
ElementOperation no tiene métodos de sincronización, en cuyo caso el código tiene el potencial de ejecución paralela o incluso vectorización. El cálculo de cada elemento es independiente, el orden no importa, por lo que una implementación puede generar múltiples hilos (posiblemente en un grupo de hilos) para el procesamiento independiente de elementos.
Me gustaría experimentar con las siguientes cosas:
- el tamaño del campo vectorial es grande o pequeño;
- una conversión simple que pasa la mayor parte del tiempo accediendo a la memoria;
- más operaciones aritméticas (ALU);
- ALU en un escenario más realista.
Como puede ver, no solo quiero probar la cantidad de elementos que son "buenos" para usar el algoritmo paralelo, sino también las operaciones de ALU que ocupan el procesador.
Otros algoritmos, como la clasificación, la acumulación (en forma de std :: reduce) también ofrecen ejecución paralela, pero también requieren más trabajo para calcular los resultados. Por lo tanto, los consideraremos candidatos para otro artículo.
Nota de referencia
Para mis pruebas, uso Visual Studio 2017, 15.8, ya que esta es la única implementación en la implementación del compilador popular / STL en este momento (noviembre de 2018) (¡GCC en camino!). Además, me concentré solo en
execution::par , ya que
execution::par_unseq no
execution::par_unseq disponible en MSVC (funciona de manera similar a
execution::par ).
Hay dos computadoras:
- i7 8700 - PC, Windows 10, i7 8700 - 3.2 GHz, 6 núcleos / 12 hilos (Hyperthreading);
- i7 4720 - Laptop, Windows 10, i7 4720, 2.6 GHz, 4 núcleos / 8 hilos (Hyperthreading).
El código se compila en x64, publica más, la auto-vectorización está habilitada por defecto, también incluí un conjunto extendido de comandos (SSE2) y OpenMP (2.0).
El código está en mi github:
github / fenbf / ParSTLTests / TransformTests / TransformTests.cppPara OpenMP (2.0), uso paralelismo solo para bucles:
#pragma omp parallel for for (int i = 0; ...)
Ejecuto el código 5 veces y miro los resultados mínimos.
Advertencia : Los resultados reflejan solo observaciones aproximadas; verifique su sistema / configuración antes de usarlo en producción. Sus requisitos y alrededores pueden diferir de los míos.Puede leer más sobre la implementación de MSVC en
esta publicación . Y
aquí está el último
informe de Bill O'Neill con CppCon 2018 (Bill implementó Parallel STL en MSVC).
Bueno, ¡comencemos con ejemplos simples!
Conversión simpleConsidere el caso cuando aplica una operación muy simple a un vector de entrada. Puede ser copia o multiplicación de elementos.
Por ejemplo:
std::transform(std::execution::par, vec.begin(), vec.end(), out.begin(), [](double v) { return v * 2.0; } );
Mi computadora tiene 6 o 4 núcleos ... ¿puedo esperar una ejecución secuencial 4..6 veces más rápida? Aquí están mis resultados (tiempo en milisegundos):
| Operación | Tamaño del vector | i7 4720 (4 núcleos) | i7 8700 (6 núcleos) |
|---|
| ejecución :: seq | 10k | 0.002763 | 0.001924 |
| ejecución :: par | 10k | 0.009869 | 0.008983 |
| openmp paralelo para | 10k | 0.003158 | 0.002246 |
| ejecución :: seq | 100k | 0,051318 | 0,028872 |
| ejecución :: par | 100k | 0.043028 | 0,025664 |
| openmp paralelo para | 100k | 0,022501 | 0.009624 |
| ejecución :: seq | 1000k | 1.69508 | 0.52419 |
| ejecución :: par | 1000k | 1.65561 | 0.359619 |
| openmp paralelo para | 1000k | 1.50678 | 0.344863 |
En una máquina más rápida, podemos ver que tomará aproximadamente 1 millón de elementos para notar una mejora en el rendimiento. Por otro lado, en mi computadora portátil todas las implementaciones paralelas fueron más lentas.
Por lo tanto, es difícil notar una mejora significativa en el rendimiento utilizando tales transformaciones, incluso con un aumento en el número de elementos.
Por qué
Dado que las operaciones son elementales, los núcleos del procesador pueden llamarlo casi instantáneamente, usando solo unos pocos ciclos. Sin embargo, los núcleos de procesador pasan más tiempo esperando la memoria principal. Entonces, en este caso, en su mayor parte esperarán, no harán cálculos.
La lectura y escritura de una variable en la memoria demora aproximadamente 2-3 ciclos si se almacena en caché y varios cientos de ciclos si no se almacena en caché.https://www.agner.org/optimize/optimizing_cpp.pdfPuede notar aproximadamente que si su algoritmo depende de la memoria, entonces no debe esperar mejoras de rendimiento con la computación paralela.
Más cálculosDado que el ancho de banda de la memoria es crucial y puede afectar la velocidad de las cosas ... aumentemos la cantidad de cálculo que afecta a cada elemento.
La idea es que es mejor usar ciclos de procesador en lugar de perder el tiempo esperando memoria.
Para empezar, uso funciones trigonométricas, por ejemplo,
sqrt(sin*cos) (estos son cálculos condicionales en forma no óptima, solo para ocupar el procesador).
Usamos
sqrt ,
sin y
cos , que pueden tomar ~ 20 por
sqrt y ~ 100 por función trigonométrica. Esta cantidad de cálculo puede cubrir el retraso de acceso a la memoria.
Para obtener más información sobre los retrasos del equipo, consulte la excelente
Guía de perf de Agner Fogh .
Aquí está el código de referencia:
std::transform(std::execution::par, vec.begin(), vec.end(), out.begin(), [](double v) { return std::sqrt(std::sin(v)*std::cos(v)); } );
¿Y ahora que? ¿Podemos contar con una mejora del rendimiento con respecto al intento anterior?
Aquí hay algunos resultados (tiempo en milisegundos):
| Operación | Tamaño del vector | i7 4720 (4 núcleos) | i7 8700 (6 núcleos) |
|---|
| ejecución :: seq | 10k | 0.105005 | 0,070577 |
| ejecución :: par | 10k | 0,055661 | 0,03176 |
| openmp paralelo para | 10k | 0.096321 | 0.024702 |
| ejecución :: seq | 100k | 1.08755 | 0.707048 |
| ejecución :: par | 100k | 0.259354 | 0.17195 |
| openmp paralelo para | 100k | 0.898465 | 0.189915 |
| ejecución :: seq | 1000k | 10.5159 | 7.16254 |
| ejecución :: par | 1000k | 2.44472 | 1.10099 |
| openmp paralelo para | 1000k | 4.78681 | 1.89017 |
Finalmente, vemos buenos números :)
Para 1000 elementos (no mostrados aquí), los tiempos de cálculo paralelos y secuenciales fueron similares, por lo tanto, para más de 1000 elementos vemos una mejora en la versión paralela.
Para 100 mil elementos, el resultado en una computadora más rápida es casi 9 veces mejor que la versión en serie (de manera similar para la versión OpenMP).
En la versión más grande de un millón de elementos, el resultado es 5 u 8 veces más rápido.
Para tales cálculos, logré una aceleración "lineal", dependiendo de la cantidad de núcleos de procesador. Lo cual era de esperarse.
Fresnel y vectores tridimensionalesEn la sección anterior, utilicé cálculos "inventados", pero ¿qué pasa con el código real?
Resolvamos las ecuaciones de Fresnel que describen la reflexión y la curvatura de la luz desde una superficie lisa y plana. Este es un método popular para generar iluminación realista en juegos 3D.
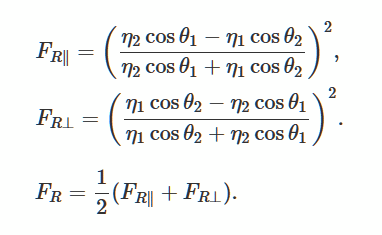
 Foto de Wikimedia
Foto de WikimediaComo buen ejemplo, encontré
esta descripción e implementación .
Acerca del uso de la biblioteca GLMEn lugar de crear mi propia implementación, utilicé
la biblioteca glm . A menudo lo uso en mis proyectos OpenGl.
Es fácil acceder a la biblioteca a través del
Administrador de paquetes de Conan , por lo que también la usaré.
Enlace al paquete.
Archivo Conan:
[requires] glm/0.9.9.1@g-truc/stable [generators] visual_studio
y la línea de comando para instalar la biblioteca (genera archivos de accesorios que puedo usar en un proyecto de Visual Studio):
conan install . -s build_type=Release -if build_release_x64 -s arch=x86_64
La biblioteca consta de un encabezado, por lo que puede descargarla manualmente si lo desea.
Código real y punto de referenciaAdapte el código para glm de
scratchapixel.com :
El código usa varias instrucciones matemáticas, producto escalar, multiplicación, división, por lo que el procesador tiene algo que hacer. En lugar del vector doble, usamos un vector de 4 elementos para aumentar la cantidad de memoria utilizada.
Benchmark:
std::transform(std::execution::par, vec.begin(), vec.end(), vecNormals.begin(),
Y aquí están los resultados (tiempo en milisegundos):
| Operación | Tamaño del vector | i7 4720 (4 núcleos) | i7 8700 (6 núcleos) |
|---|
| ejecución :: seq | 1k | 0,032764 | 0,016361 |
| ejecución :: par | 1k | 0,031186 | 0,028551 |
| openmp paralelo para | 1k | 0.005526 | 0.007699 |
| ejecución :: seq | 10k | 0.246722 | 0.169383 |
| ejecución :: par | 10k | 0,090794 | 0.067048 |
| openmp paralelo para | 10k | 0,049739 | 0,029835 |
| ejecución :: seq | 100k | 2.49722 | 1.69768 |
| ejecución :: par | 100k | 0.530157 | 0.283268 |
| openmp paralelo para | 100k | 0.495024 | 0.291609 |
| ejecución :: seq | 1000k | 25/08/28 | 16.9457 |
| ejecución :: par | 1000k | 5.15235 | 2.33768 |
| openmp paralelo para | 1000k | 5.11801 | 2.95908 |
Con la computación "real", vemos que los algoritmos paralelos proporcionan un buen rendimiento. Para tales operaciones en mis dos máquinas con Windows, logré una aceleración con una dependencia casi lineal del número de núcleos.
Para todas las pruebas, también mostré resultados de OpenMP y dos implementaciones: MSVC y OpenMP funcionan de manera similar.
ConclusiónEn este artículo, analicé tres casos de uso de computación paralela y algoritmos paralelos. Reemplazar algoritmos estándar con la versión std :: execute :: par puede parecer muy tentador, ¡pero no siempre vale la pena hacerlo! Cada operación que use dentro del algoritmo puede funcionar de manera diferente y depender más del procesador o la memoria. Por lo tanto, considere cada cambio por separado.
Cosas para recordar:
- la ejecución paralela, por lo general, hace más que secuencial, ya que la biblioteca debe prepararse para la ejecución paralela;
- no solo es importante la cantidad de elementos, sino también la cantidad de instrucciones con las que está ocupado el procesador;
- es mejor tomar tareas que son independientes entre sí y de otros recursos compartidos;
- Los algoritmos paralelos ofrecen una manera fácil de dividir el trabajo en hilos separados;
- si sus operaciones dependen de la memoria, no debe esperar mejoras de rendimiento y, en algunos casos, los algoritmos pueden ser más lentos;
- Para obtener una mejora decente en el rendimiento, mida siempre los tiempos de cada problema, en algunos casos los resultados pueden ser completamente diferentes.
¡Un agradecimiento especial a JFT por ayudarme con este artículo!
También preste atención a mis otras fuentes sobre algoritmos paralelos:
Eche un vistazo a otro artículo relacionado con Algoritmos paralelos:
cómo mejorar el rendimiento con Intel Parallel STL y Algoritmos paralelos C ++ 17El fin
Estamos esperando comentarios y preguntas que puede dejar aquí o en nuestro
maestro en
la puerta abierta .